Mọi người tự hỏi liệu họ có nên cố gắng hết sức để ngăn chặn các trường hợp ngoại lệ hay chỉ để hệ thống xử lý chúng. Tôi đã thấy một số cuộc thảo luận trong đó mọi người tranh luận về việc liệu họ có nên làm bất cứ điều gì có thể để ngăn chặn một ngoại lệ hay không, bởi vì việc xử lý lỗi rất "tốn kém". Không có nghi ngờ gì về việc xử lý lỗi không miễn phí, nhưng tôi dự đoán rằng vi phạm ràng buộc ít nhất cũng hiệu quả như việc kiểm tra vi phạm tiềm ẩn trước. Ví dụ:điều này có thể khác đối với vi phạm chính so với vi phạm ràng buộc tĩnh, nhưng trong bài đăng này, tôi sẽ tập trung vào vi phạm trước đây.
Các phương pháp tiếp cận chính mà mọi người sử dụng để đối phó với các trường hợp ngoại lệ là:
- Chỉ cần để bộ máy xử lý và chuyển bất kỳ ngoại lệ nào trở lại người gọi.
- Sử dụng
BEGIN TRANSACTIONvàROLLBACKnếu@@ERROR <> 0. - Sử dụng
TRY/CATCHvớiROLLBACKtrongCATCHkhối (SQL Server 2005+).
Và nhiều người thực hiện cách tiếp cận mà họ nên kiểm tra xem liệu họ có vi phạm hay không trước, vì việc tự xử lý bản sao có vẻ dễ dàng hơn là buộc động cơ làm điều đó. Lý thuyết của tôi là bạn nên tin tưởng nhưng hãy xác minh; ví dụ:hãy xem xét cách tiếp cận này (chủ yếu là mã giả):
IF NOT EXISTS ([row that would incur a violation])
BEGIN
BEGIN TRY
BEGIN TRANSACTION;
INSERT ()...
COMMIT TRANSACTION;
END TRY
BEGIN CATCH
-- well, we incurred a violation anyway;
-- I guess a new row was inserted or
-- updated since we performed the check
ROLLBACK TRANSACTION;
END CATCH
END
Chúng tôi biết rằng IF NOT EXISTS kiểm tra không đảm bảo rằng người khác sẽ không chèn hàng vào thời điểm chúng tôi đến INSERT (trừ khi chúng tôi đặt các ổ khóa mạnh mẽ trên bàn và / hoặc sử dụng SERIALIZABLE ), nhưng việc kiểm tra bên ngoài không ngăn chúng tôi cố gắng thực hiện một thất bại và sau đó phải quay trở lại. Chúng tôi tránh toàn bộ TRY/CATCH nếu chúng ta đã biết rằng INSERT sẽ không thành công và sẽ là hợp lý khi giả định rằng - ít nhất trong một số trường hợp - điều này sẽ hiệu quả hơn việc nhập TRY/CATCH cấu trúc một cách vô điều kiện. Điều này không có ý nghĩa gì trong một INSERT duy nhất nhưng hãy tưởng tượng một trường hợp có nhiều thứ xảy ra hơn trong TRY đó chặn (và nhiều vi phạm tiềm ẩn hơn mà bạn có thể kiểm tra trước, nghĩa là thậm chí nhiều công việc hơn mà bạn có thể phải thực hiện và sau đó quay lại nếu vi phạm sau này xảy ra).
Bây giờ, sẽ rất thú vị khi xem điều gì sẽ xảy ra nếu bạn sử dụng mức cô lập không mặc định (điều gì đó tôi sẽ xử lý trong một bài đăng trong tương lai), đặc biệt là với đồng thời. Tuy nhiên, đối với bài đăng này, tôi muốn bắt đầu từ từ và kiểm tra các khía cạnh này với một người dùng duy nhất. Tôi đã tạo một bảng có tên dbo.[Objects] , một bảng rất đơn giản:
CREATE TABLE dbo.[Objects] ( ObjectID INT IDENTITY(1,1), Name NVARCHAR(255) PRIMARY KEY ); GO
Tôi muốn điền vào bảng này 100.000 hàng dữ liệu mẫu. Để làm cho các giá trị trong cột tên là duy nhất (vì PK là ràng buộc tôi muốn vi phạm), tôi đã tạo một hàm trợ giúp nhận một số hàng và một chuỗi tối thiểu. Chuỗi tối thiểu sẽ được sử dụng để đảm bảo rằng (a) tập bắt đầu vượt quá giá trị lớn nhất trong bảng Đối tượng hoặc (b) tập bắt đầu ở giá trị nhỏ nhất trong bảng Đối tượng. (Tôi sẽ chỉ định những điều này theo cách thủ công trong quá trình kiểm tra, được xác minh đơn giản bằng cách kiểm tra dữ liệu, mặc dù tôi có thể đã tích hợp kiểm tra đó vào hàm.)
CREATE FUNCTION dbo.GenerateRows(@n INT, @minString NVARCHAR(32)) RETURNS TABLE AS RETURN ( SELECT TOP (@n) name = name + '_' + RTRIM(rn) FROM ( SELECT a.name, rn = ROW_NUMBER() OVER (PARTITION BY a.name ORDER BY a.name) FROM sys.all_objects AS a CROSS JOIN sys.all_objects AS b WHERE a.name >= @minString AND b.name >= @minString ) AS x ); GO
Điều này áp dụng cho một CROSS JOIN trong tổng số sys.all_objects vào chính nó, thêm một row_number duy nhất vào mỗi tên, vì vậy 10 kết quả đầu tiên sẽ giống như sau:
Việc điền vào bảng có 100.000 hàng thật đơn giản:
INSERT dbo.[Objects](name) SELECT name FROM dbo.GenerateRows(100000, N'') ORDER BY name; GO
Bây giờ, vì chúng tôi sẽ chèn các giá trị duy nhất mới vào bảng, tôi đã tạo một quy trình để thực hiện một số thao tác dọn dẹp ở đầu và cuối mỗi bài kiểm tra - ngoài việc xóa bất kỳ hàng mới nào chúng tôi đã thêm, nó cũng sẽ dọn dẹp bộ đệm và bộ đệm. Tất nhiên, không phải thứ bạn muốn viết mã vào một quy trình trên hệ thống sản xuất của mình, nhưng nó khá tốt để kiểm tra hiệu suất cục bộ.
CREATE PROCEDURE dbo.EH_Cleanup -- P.S. "EH" stands for Error Handling, not "Eh?" AS BEGIN SET NOCOUNT ON; DELETE dbo.[Objects] WHERE ObjectID > 100000; DBCC FREEPROCCACHE; DBCC DROPCLEANBUFFERS; END GO
Tôi cũng đã tạo một bảng nhật ký để theo dõi thời gian bắt đầu và kết thúc cho mỗi bài kiểm tra:
CREATE TABLE dbo.RunTimeLog ( LogID INT IDENTITY(1,1), Spid INT, InsertType VARCHAR(255), ErrorHandlingMethod VARCHAR(255), StartDate DATETIME2(7) NOT NULL DEFAULT SYSUTCDATETIME(), EndDate DATETIME2(7) ); GO
Cuối cùng, thủ tục lưu trữ thử nghiệm xử lý nhiều thứ khác nhau. Chúng tôi có ba phương pháp xử lý lỗi khác nhau, như được mô tả trong các gạch đầu dòng ở trên:"JustInsert", "Rollback" và "TryCatch"; chúng ta cũng có ba kiểu chèn khác nhau:(1) tất cả các lần chèn thành công (tất cả các hàng là duy nhất), (2) tất cả các lần chèn không thành công (tất cả các hàng đều trùng lặp) và (3) một nửa lần chèn thành công (một nửa số hàng là duy nhất và một nửa các hàng trùng lặp). Cùng với điều này là hai cách tiếp cận khác nhau:kiểm tra lỗi vi phạm trước khi thử chèn hoặc chỉ cần tiếp tục và để động cơ xác định xem nó có hợp lệ hay không. Tôi nghĩ rằng điều này sẽ cung cấp một so sánh tốt giữa các kỹ thuật xử lý lỗi khác nhau kết hợp với các khả năng xảy ra va chạm khác nhau để xem liệu tỷ lệ va chạm cao hay thấp sẽ ảnh hưởng đáng kể đến kết quả.
Đối với những thử nghiệm này, tôi đã chọn 40.000 hàng làm tổng số lần chèn và trong quy trình này, tôi thực hiện kết hợp 20.000 hàng duy nhất hoặc không duy nhất với 20.000 hàng duy nhất hoặc không duy nhất khác. Bạn có thể thấy rằng tôi đã mã hóa các chuỗi cắt trong quy trình; xin lưu ý rằng trên hệ thống của bạn, những giới hạn này gần như chắc chắn sẽ xảy ra ở một nơi khác.
CREATE PROCEDURE dbo.EH_Insert @ErrorHandlingMethod VARCHAR(255), @InsertType VARCHAR(255), @RowSplit INT = 20000 AS BEGIN SET NOCOUNT ON; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; DECLARE @CutoffString1 NVARCHAR(255), @CutoffString2 NVARCHAR(255), @Name NVARCHAR(255), @Continue BIT = 1, @LogID INT; -- generate a new log entry INSERT dbo.RunTimeLog(Spid, InsertType, ErrorHandlingMethod) SELECT @@SPID, @InsertType, @ErrorHandlingMethod; SET @LogID = SCOPE_IDENTITY(); -- if we want everything to succeed, we need a set of data -- that has 40,000 rows that are all unique. So union two -- sets that are each >= 20,000 rows apart, and don't -- already exist in the base table: IF @InsertType = 'AllSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N'dm_clr_properties_1398'; -- if we want them all to fail, then it's easy, we can just -- union two sets that start at the same place as the initial -- population: IF @InsertType = 'AllFail' SELECT @CutoffString1 = N'', @CutoffString2 = N''; -- and if we want half to succeed, we need 20,000 unique -- values, and 20,000 duplicates: IF @InsertType = 'HalfSuccess' SELECT @CutoffString1 = N'database_audit_specifications_1000', @CutoffString2 = N''; DECLARE c CURSOR LOCAL STATIC FORWARD_ONLY READ_ONLY FOR SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString1) UNION ALL SELECT name FROM dbo.GenerateRows(@RowSplit, @CutoffString2); OPEN c; FETCH NEXT FROM c INTO @Name; WHILE @@FETCH_STATUS = 0 BEGIN SET @Continue = 1; -- let's only enter the primary code block if we -- have to check and the check comes back empty -- (in other words, don't try at all if we have -- a duplicate, but only check for a duplicate -- in certain cases: IF @ErrorHandlingMethod LIKE 'Check%' BEGIN IF EXISTS (SELECT 1 FROM dbo.[Objects] WHERE Name = @Name) SET @Continue = 0; END IF @Continue = 1 BEGIN -- just let the engine catch IF @ErrorHandlingMethod LIKE '%Insert' BEGIN INSERT dbo.[Objects](name) SELECT @name; END -- begin a transaction, but let the engine catch IF @ErrorHandlingMethod LIKE '%Rollback' BEGIN BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @name; IF @@ERROR <> 0 BEGIN ROLLBACK TRANSACTION; END ELSE BEGIN COMMIT TRANSACTION; END END -- use try / catch IF @ErrorHandlingMethod LIKE '%TryCatch' BEGIN BEGIN TRY BEGIN TRANSACTION; INSERT dbo.[Objects](name) SELECT @Name; COMMIT TRANSACTION; END TRY BEGIN CATCH ROLLBACK TRANSACTION; END CATCH END END FETCH NEXT FROM c INTO @Name; END CLOSE c; DEALLOCATE c; -- update the log entry UPDATE dbo.RunTimeLog SET EndDate = SYSUTCDATETIME() WHERE LogID = @LogID; -- clean up any new rows and drop buffers/clear proc cache EXEC dbo.EH_Cleanup; END GO
Bây giờ chúng ta có thể gọi thủ tục này với các đối số khác nhau để có được các hành vi khác nhau mà chúng ta đang theo đuổi, cố gắng chèn 40.000 giá trị (và tất nhiên, biết bao nhiêu giá trị sẽ thành công hoặc thất bại trong mỗi trường hợp). Đối với mỗi 'phương pháp xử lý lỗi' (chỉ cần thử chèn, sử dụng begin tran / rollback hoặc try / catch) và mỗi kiểu chèn (tất cả đều thành công, thành công một nửa và không thành công), kết hợp với việc kiểm tra xem có vi phạm hay không đầu tiên, điều này cho chúng ta 18 kết hợp:
EXEC dbo.EH_Insert 'JustInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'JustRollback', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckInsert', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckTryCatch', 'AllFail', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'HalfSuccess', 20000; EXEC dbo.EH_Insert 'CheckRollback', 'AllFail', 20000;
Sau khi chúng tôi chạy quá trình này (mất khoảng 8 phút trên hệ thống của tôi), chúng tôi có một số kết quả trong nhật ký của mình. Tôi đã chạy toàn bộ lô năm lần để đảm bảo rằng chúng tôi có được mức trung bình tốt và để giải quyết bất kỳ sự bất thường nào. Đây là kết quả:
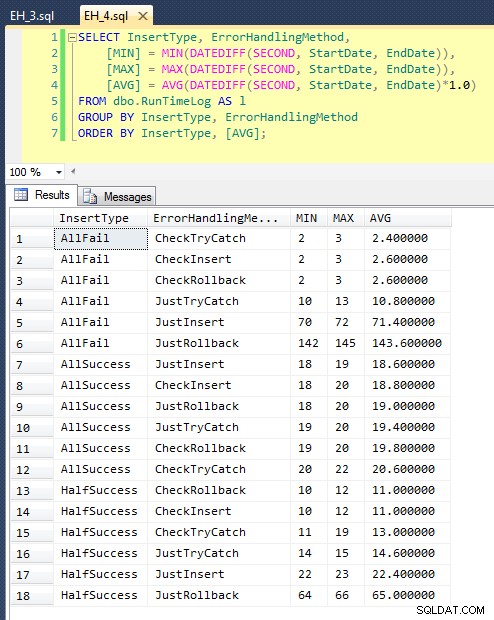
Biểu đồ vẽ tất cả các thời lượng cùng một lúc cho thấy một số ngoại lệ nghiêm trọng:
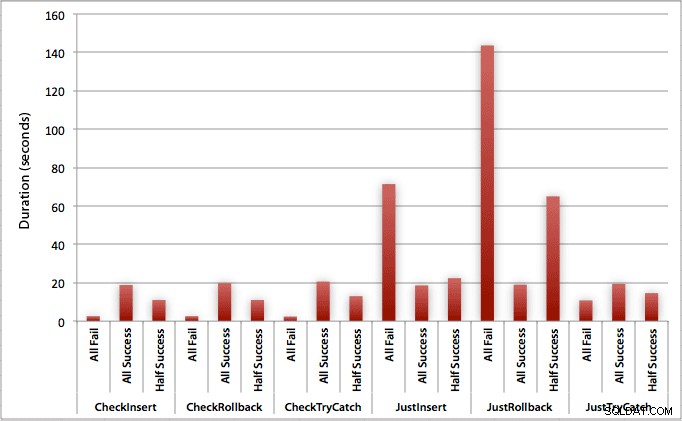
Bạn có thể thấy rằng, trong trường hợp chúng tôi dự đoán tỷ lệ thất bại cao (trong thử nghiệm này là 100%), bắt đầu giao dịch và quay trở lại cho đến nay là cách tiếp cận kém hấp dẫn nhất (3,59 mili giây mỗi lần thử), trong khi chỉ để động cơ tăng lỗi nặng khoảng một nửa (1,785 mili giây mỗi lần thử). Hoạt động tồi tệ nhất tiếp theo là trường hợp chúng tôi bắt đầu một giao dịch sau đó quay trở lại, trong một trường hợp mà chúng tôi cho rằng khoảng một nửa số lần thử không thành công (trung bình 1,625 mili giây mỗi lần thử). 9 trường hợp ở phía bên trái của biểu đồ, nơi chúng tôi đang kiểm tra vi phạm trước tiên, đã không vượt quá 0,515 mili giây mỗi lần thử.
Phải nói rằng, các biểu đồ riêng lẻ cho từng tình huống (% thành công cao,% thất bại cao và 50-50) thực sự thể hiện tác động của từng phương pháp.
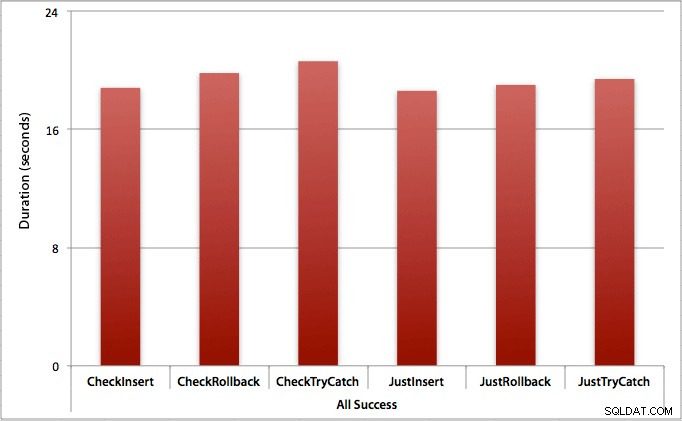
Nơi tất cả các lần chèn thành công
Trong trường hợp này, chúng tôi thấy rằng chi phí kiểm tra vi phạm đầu tiên là không đáng kể, với sự khác biệt trung bình là 0,7 giây trong toàn bộ lô (hoặc 125 micro giây cho mỗi lần chèn):
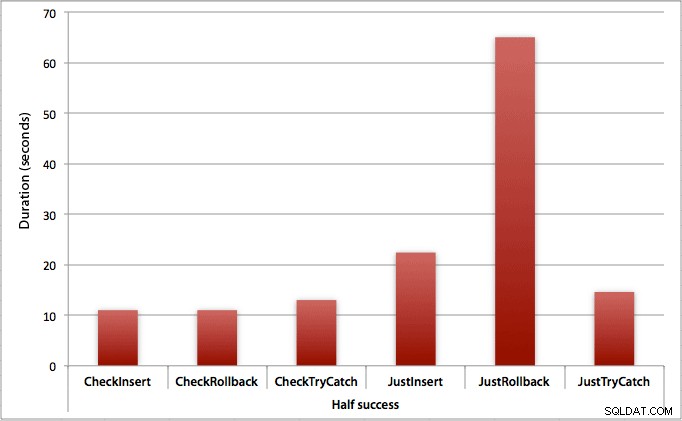
Chỉ một nửa số lần chèn thành công
Khi một nửa số lần chèn không thành công, chúng ta thấy một bước nhảy vọt về thời lượng đối với các phương thức chèn / khôi phục. Kịch bản trong đó chúng tôi bắt đầu một giao dịch và khôi phục nó chậm hơn khoảng 6 lần trong toàn bộ lô khi so sánh với lần kiểm tra đầu tiên (1,625 mili giây mỗi lần thử so với 0,275 mili giây mỗi lần thử). Ngay cả phương pháp TRY / CATCH cũng nhanh hơn 11% khi chúng tôi kiểm tra trước:
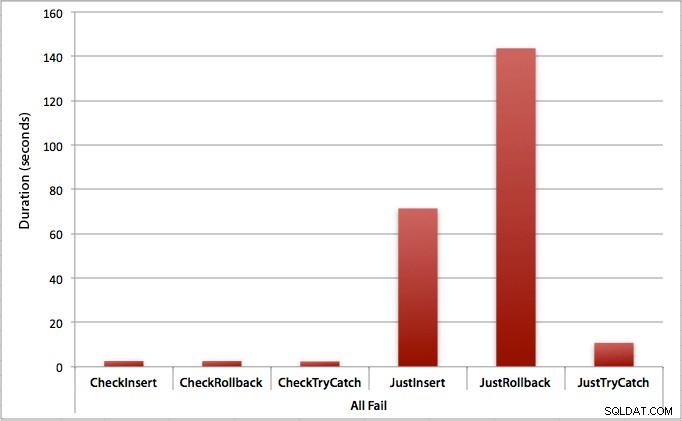
Trường hợp tất cả các lần chèn đều không thành công
Như bạn có thể mong đợi, điều này cho thấy tác động rõ rệt nhất của việc xử lý lỗi và những lợi ích rõ ràng nhất của việc kiểm tra trước. Trong trường hợp này, phương pháp khôi phục chậm hơn gần 70 lần khi chúng tôi không kiểm tra so với khi chúng tôi thực hiện (3,59 mili giây mỗi lần thử so với 0,065 mili giây mỗi lần thử):
Điều này cho chúng ta biết điều gì? Nếu chúng ta nghĩ rằng chúng ta sẽ có tỷ lệ hỏng hóc cao hoặc không biết tỷ lệ hỏng hóc tiềm ẩn của chúng ta là bao nhiêu, thì việc kiểm tra trước để tránh các vi phạm trong động cơ sẽ rất đáng để chúng ta thực hiện. Ngay cả trong trường hợp lần nào chúng tôi cũng chèn thành công, thì chi phí kiểm tra đầu tiên là thấp và dễ dàng biện minh bằng chi phí xử lý lỗi sau này (trừ khi tỷ lệ thất bại dự đoán của bạn chính xác là 0%).
Vì vậy, hiện tại tôi nghĩ tôi sẽ bám sát lý thuyết của mình rằng, trong những trường hợp đơn giản, việc kiểm tra khả năng vi phạm trước khi yêu cầu SQL Server cứ tiếp tục và chèn là rất hợp lý. Trong một bài đăng trong tương lai, tôi sẽ xem xét tác động hiệu suất của các mức cách ly khác nhau, sự đồng thời và thậm chí có thể là một vài kỹ thuật xử lý lỗi khác.
[Bỏ qua một bên, tôi đã viết một phiên bản cô đọng của bài đăng này như một mẹo cho mssqltips.com vào tháng Hai.]