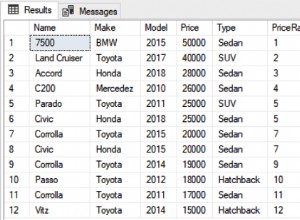
Có rất nhiều bình luận sau bài đăng của tôi tuần trước về việc tách chuỗi. Tôi nghĩ rằng quan điểm của bài viết không rõ ràng như nó có thể xảy ra:rằng việc dành nhiều thời gian và công sức để cố gắng "hoàn thiện" một chức năng phân tách vốn đã chậm chạp dựa trên T-SQL sẽ không có lợi. Kể từ đó, tôi đã thu thập phiên bản mới nhất của hàm tách chuỗi của Jeff Moden và so sánh nó với các phiên bản khác:
ALTER FUNCTION [dbo].[DelimitedSplitN4K]
(@pString NVARCHAR(4000), @pDelimiter NCHAR(1))
RETURNS TABLE WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS (
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
cteTally(N) AS (SELECT TOP (ISNULL(DATALENGTH(@pString)/2,0))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E4),
cteStart(N1) AS (SELECT 1 UNION ALL
SELECT t.N+1 FROM cteTally t WHERE SUBSTRING(@pString,t.N,1) = @pDelimiter
),
cteLen(N1,L1) AS(SELECT s.N1,
ISNULL(NULLIF(CHARINDEX(@pDelimiter,@pString,s.N1),0)-s.N1,4000)
FROM cteStart s
)
SELECT ItemNumber = ROW_NUMBER() OVER(ORDER BY l.N1),
Item = SUBSTRING(@pString, l.N1, l.L1)
FROM cteLen l;
GO (Những thay đổi duy nhất mà tôi đã thực hiện:Tôi đã định dạng nó để hiển thị và tôi đã xóa các nhận xét. Bạn có thể truy xuất nguồn gốc tại đây.)
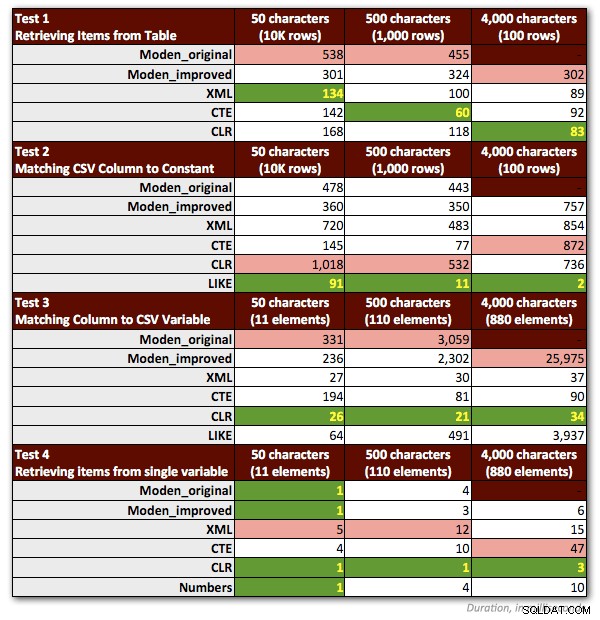
Tôi đã phải thực hiện một vài điều chỉnh đối với các bài kiểm tra của mình để thể hiện một cách công bằng chức năng của Jeff. Quan trọng nhất:Tôi phải loại bỏ tất cả các mẫu liên quan đến bất kỳ chuỗi nào> 4.000 ký tự. Vì vậy, tôi đã thay đổi chuỗi 5.000 ký tự trong bảng dbo.strings thành 4.000 ký tự thay thế và chỉ tập trung vào ba trường hợp đầu tiên không phải MAX (giữ nguyên kết quả trước đó cho hai trường hợp đầu tiên và chạy lại các thử nghiệm thứ ba cho trường hợp mới Độ dài chuỗi 4.000 ký tự). Tôi cũng bỏ bảng Numbers khỏi tất cả trừ một trong các bài kiểm tra, vì rõ ràng là hiệu suất ở đó luôn kém hơn với hệ số ít nhất là 10. Biểu đồ sau đây cho thấy hiệu suất của các chức năng trong mỗi bài kiểm tra trong số bốn bài kiểm tra, một lần nữa trung bình hơn 10 lần chạy và luôn có bộ đệm lạnh và bộ đệm sạch.
Vì vậy, đây là các phương pháp ưu tiên đã được sửa đổi một chút của tôi, cho từng loại nhiệm vụ:
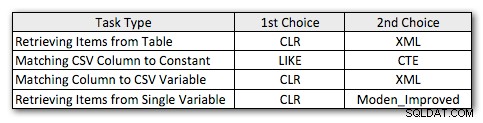
Bạn sẽ nhận thấy rằng CLR vẫn là phương pháp tôi lựa chọn, ngoại trừ một trường hợp mà việc phân tách không có ý nghĩa. Và trong trường hợp CLR không phải là một tùy chọn, thì các phương pháp XML và CTE thường hiệu quả hơn, ngoại trừ trường hợp tách biến đơn lẻ, trong đó hàm của Jeff rất có thể là lựa chọn tốt nhất. Nhưng do tôi có thể cần hỗ trợ hơn 4.000 ký tự, giải pháp bảng Numbers chỉ có thể đưa nó trở lại danh sách của tôi trong các tình huống cụ thể mà tôi không được phép sử dụng CLR.
Tôi hứa rằng bài đăng tiếp theo của tôi liên quan đến danh sách sẽ không nói về việc tách, thông qua T-SQL hoặc CLR và sẽ trình bày cách đơn giản hóa vấn đề này bất kể kiểu dữ liệu.
Ngoài ra, tôi nhận thấy nhận xét này trong một trong các phiên bản hàm của Jeff đã được đăng trong phần nhận xét:Tôi cũng cảm ơn ai đã viết bài báo đầu tiên mà tôi từng thấy trên “bảng số” nằm ở URL sau và gửi tới Adam Machanic vì đã dẫn tôi đến nó nhiều năm trước.https://web.archive.org/web/20150411042510/https://sqlserver2000.databases.aspfaq.com/why-should-i-consider-using-an -auxcular-number-table.html
Bài đó do mình viết năm 2004. Nên bạn nào thêm comment vào chức năng thì cứ tự nhiên nhé. :-)