[Phần 1 | Phần 2 | Phần 3 | Phần 4]
Nhiều năm qua đã được viết về cách hiểu và tối ưu hóa SELECT truy vấn, nhưng ít hơn về sửa đổi dữ liệu. Loạt bài đăng này xem xét một vấn đề cụ thể đối với INSERT , UPDATE , DELETE và MERGE truy vấn - Vấn đề Halloween.
Cụm từ “Sự cố Halloween” ban đầu được đặt ra với tham chiếu đến UPDATE trong SQL truy vấn được cho là sẽ tăng 10% cho mỗi nhân viên kiếm được ít hơn 25.000 đô la. Vấn đề là truy vấn tiếp tục tăng 10% cho đến khi mọi người kiếm được ít nhất 25.000 đô la. Chúng ta sẽ thấy ở phần sau của loạt bài này rằng vấn đề cơ bản cũng áp dụng cho INSERT , DELETE và MERGE nhưng đối với mục nhập đầu tiên này, sẽ rất hữu ích khi kiểm tra UPDATE vấn đề một chút chi tiết.
Bối cảnh
Ngôn ngữ SQL cung cấp một cách để người dùng chỉ định các thay đổi cơ sở dữ liệu bằng cách sử dụng UPDATE nhưng cú pháp không nói gì về cách thức cơ sở dữ liệu sẽ thực hiện các thay đổi. Mặt khác, tiêu chuẩn SQL chỉ định rằng kết quả của một UPDATE phải giống như thể nó đã được thực hiện trong ba giai đoạn riêng biệt và không chồng chéo:
- Tìm kiếm chỉ đọc xác định các bản ghi sẽ được thay đổi và các giá trị cột mới
- Các thay đổi được áp dụng cho các bản ghi bị ảnh hưởng
- Các ràng buộc về tính nhất quán của cơ sở dữ liệu đã được xác minh
Thực hiện ba giai đoạn này theo nghĩa đen trong một công cụ cơ sở dữ liệu sẽ tạo ra kết quả chính xác, nhưng hiệu suất có thể không tốt lắm. Kết quả trung gian ở mỗi giai đoạn sẽ yêu cầu bộ nhớ hệ thống, giảm số lượng truy vấn mà hệ thống có thể thực hiện đồng thời. Bộ nhớ cần thiết cũng có thể vượt quá bộ nhớ khả dụng, yêu cầu ít nhất một phần của bộ cập nhật được ghi vào bộ nhớ đĩa và đọc lại sau này. Cuối cùng nhưng không kém phần quan trọng, mỗi hàng trong bảng cần được chạm nhiều lần theo mô hình thực thi này.
Một chiến lược thay thế là xử lý UPDATE một hàng tại một thời điểm. Điều này có lợi thế là chỉ chạm vào mỗi hàng một lần và thường không yêu cầu bộ nhớ để lưu trữ (mặc dù một số hoạt động, như sắp xếp đầy đủ, phải xử lý toàn bộ đầu vào trước khi tạo ra hàng đầu tiên). Mô hình lặp lại này là mô hình được sử dụng bởi công cụ thực thi truy vấn SQL Server.
Thách thức đối với trình tối ưu hóa truy vấn là tìm một kế hoạch thực thi lặp đi lặp lại (từng hàng) đáp ứng UPDATE ngữ nghĩa theo yêu cầu của tiêu chuẩn SQL, trong khi vẫn giữ được hiệu suất và lợi ích đồng thời của việc thực thi pipelined.
Xử lý cập nhật
Để minh họa cho vấn đề ban đầu, chúng tôi sẽ áp dụng mức tăng 10% cho mỗi nhân viên có thu nhập dưới 25.000 đô la bằng cách sử dụng Employees bảng bên dưới:

CREATE TABLE dbo.Employees
(
Name nvarchar(50) NOT NULL,
Salary money NOT NULL
);
INSERT dbo.Employees
(Name, Salary)
VALUES
('Brown', $22000),
('Smith', $21000),
('Jones', $25000);
UPDATE e
SET Salary = Salary * $1.1
FROM dbo.Employees AS e
WHERE Salary < $25000; Chiến lược cập nhật ba giai đoạn
Giai đoạn đầu tiên chỉ đọc tìm tất cả các bản ghi đáp ứng WHERE vị ngữ mệnh đề, và lưu đủ thông tin để giai đoạn thứ hai thực hiện công việc của nó. Trên thực tế, điều này có nghĩa là ghi lại một số nhận dạng duy nhất cho mỗi hàng đủ điều kiện (các khóa chỉ mục được phân nhóm hoặc số nhận dạng hàng đống) và giá trị tiền lương mới. Khi giai đoạn một hoàn thành, toàn bộ tập hợp thông tin cập nhật được chuyển sang giai đoạn thứ hai, xác định vị trí mỗi bản ghi sẽ được cập nhật bằng cách sử dụng số nhận dạng duy nhất và thay đổi mức lương thành giá trị mới. Giai đoạn thứ ba sau đó kiểm tra xem không có ràng buộc toàn vẹn cơ sở dữ liệu nào bị vi phạm bởi trạng thái cuối cùng của bảng.
Chiến lược lặp lại
Cách tiếp cận này đọc từng hàng một từ bảng nguồn. Nếu hàng thỏa mãn WHERE vị ngữ mệnh đề, việc tăng lương được áp dụng. Quá trình này lặp lại cho đến khi tất cả các hàng đã được xử lý từ nguồn. Dưới đây là một kế hoạch thực hiện mẫu sử dụng mô hình này:

Như thường lệ đối với đường dẫn hướng theo nhu cầu của SQL Server, việc thực thi bắt đầu ở toán tử ngoài cùng bên trái - UPDATE trong trường hợp này. Nó yêu cầu một hàng từ Cập nhật bảng, yêu cầu một hàng từ Vô hướng tính toán và xuống chuỗi tới Quét bảng:
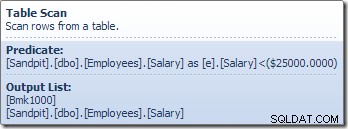
Toán tử Quét bảng đọc từng hàng một từ công cụ lưu trữ, cho đến khi nó tìm thấy hàng thỏa mãn vị từ Lương. Danh sách đầu ra trong hình trên hiển thị toán tử Quét bảng trả về giá trị nhận dạng hàng và giá trị hiện tại của cột Lương cho hàng này. Một hàng duy nhất chứa các tham chiếu đến hai phần thông tin này được chuyển đến Vô hướng tính toán:
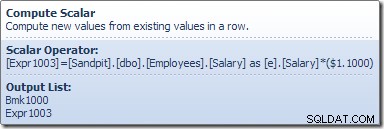
Tính toán Scalar xác định một biểu thức áp dụng mức tăng lương cho hàng hiện tại. Nó trả về một hàng chứa các tham chiếu đến mã định danh hàng và mức lương đã sửa đổi cho Bản cập nhật bảng, thao tác này sẽ gọi công cụ lưu trữ để thực hiện sửa đổi dữ liệu. Quá trình lặp lại này tiếp tục cho đến khi Quét bảng hết hàng. Quy trình cơ bản tương tự được thực hiện nếu bảng có chỉ mục được phân nhóm:
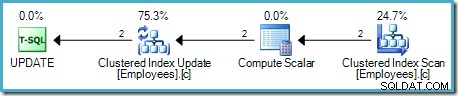
Sự khác biệt chính là (các) khóa chỉ mục được phân nhóm và trình hợp nhất (nếu có) được sử dụng làm mã định danh hàng thay vì RID đống.
Vấn đề
Việc thay đổi từ hoạt động ba pha logic được định nghĩa trong tiêu chuẩn SQL sang mô hình thực thi lặp lại vật lý đã đưa ra một số thay đổi tinh tế, chỉ một trong số đó chúng ta sẽ xem xét hôm nay. Một vấn đề có thể xảy ra trong ví dụ đang chạy của chúng tôi nếu có một chỉ mục không phân biệt trên cột Lương mà trình tối ưu hóa truy vấn quyết định sử dụng để tìm các hàng đủ điều kiện (Lương <25.000 đô la):
CREATE NONCLUSTERED INDEX nc1 ON dbo.Employees (Salary);
Mô hình thực thi từng hàng hiện có thể tạo ra kết quả không chính xác hoặc thậm chí đi vào vòng lặp vô hạn. Hãy xem xét một kế hoạch thực thi lặp đi lặp lại (tưởng tượng) tìm kiếm chỉ số Lương, trả về một hàng tại một thời điểm cho Tính vô hướng và cuối cùng là cho toán tử Cập nhật:

Có thêm một số Phạm vi tính toán trong kế hoạch này do tối ưu hóa bỏ qua việc duy trì chỉ mục không phân biệt nếu giá trị Mức lương không thay đổi (chỉ có thể với mức lương bằng 0 trong trường hợp này).
Bỏ qua điều đó, tính năng quan trọng của kế hoạch này là bây giờ chúng ta có một quá trình quét chỉ mục từng phần có thứ tự chuyển một hàng tại một thời điểm đến một toán tử sửa đổi cùng một chỉ mục (điểm đánh dấu màu xanh lá cây trong đồ họa SQL Sentry Plan Explorer ở trên giúp rõ ràng Clustered Toán tử Cập nhật chỉ mục duy trì cả bảng cơ sở và chỉ mục không phân biệt).
Dù sao, vấn đề là bằng cách xử lý từng hàng một, Bản cập nhật có thể di chuyển hàng hiện tại lên trước vị trí quét được sử dụng bởi Index Seek để xác định vị trí các hàng cần thay đổi. Làm việc qua ví dụ sẽ làm cho tuyên bố đó rõ ràng hơn một chút:
Chỉ số không phân biệt được khóa và sắp xếp tăng dần theo giá trị tiền lương. Chỉ mục cũng chứa một con trỏ đến hàng mẹ trong bảng cơ sở (hoặc là RID đống hoặc các khóa chỉ mục được phân cụm cộng với trình thống nhất nếu cần). Để làm cho ví dụ dễ theo dõi hơn, giả sử bảng cơ sở hiện có một chỉ mục nhóm duy nhất trên cột Tên, vì vậy nội dung chỉ mục không phân nhóm khi bắt đầu xử lý cập nhật là:
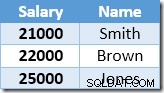
Hàng đầu tiên mà Index Seek trả về là mức lương 21.000 đô la cho Smith. Giá trị này được cập nhật thành $ 23,100 trong bảng cơ sở và chỉ mục không phân biệt bởi toán tử Clustered Index. Chỉ mục không hợp nhất hiện chứa:
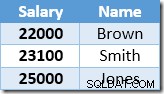
Hàng tiếp theo do Index Seek trả về sẽ là mục nhập $ 22.000 cho Brown được cập nhật lên $ 24.200:
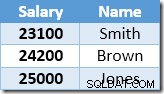
Giờ đây, Index Seek tìm thấy giá trị $ 23,100 cho Smith, giá trị này được cập nhật lại , đến 25.410 đô la. Quá trình này tiếp tục cho đến khi tất cả nhân viên có mức lương ít nhất là 25.000 đô la - đây không phải là kết quả chính xác cho UPDATE đã cho truy vấn. Tác động tương tự trong các trường hợp khác có thể dẫn đến bản cập nhật đang chạy chỉ kết thúc khi máy chủ hết dung lượng nhật ký hoặc xảy ra lỗi tràn (có thể xảy ra trong trường hợp này nếu ai đó có mức lương bằng không). Đây là Sự cố Halloween vì nó áp dụng cho các bản cập nhật.
Tránh vấn đề Halloween để cập nhật
Những độc giả có đôi mắt đại bàng sẽ nhận thấy rằng tỷ lệ phần trăm chi phí ước tính trong kế hoạch Tìm kiếm Chỉ mục tưởng tượng không tăng lên đến 100%. Đây không phải là vấn đề với Plan Explorer - Tôi đã cố tình xóa toán tử chính khỏi kế hoạch:

Trình tối ưu hóa truy vấn nhận ra rằng kế hoạch cập nhật xuyên suốt này dễ bị ảnh hưởng bởi Sự cố Halloween và giới thiệu Bộ đệm Bảng Háo hức để ngăn điều đó xảy ra. Không có gợi ý hoặc cờ theo dõi để ngăn chặn việc đưa ống vào kế hoạch thực thi này vì nó được yêu cầu về tính đúng đắn.
Như tên gọi của nó cho thấy, ống chỉ tiêu thụ tất cả các hàng từ toán tử con của nó (Tìm kiếm chỉ mục) trước khi trả về một hàng về Vô hướng tính toán cha của nó. Hiệu quả của việc này là giới thiệu tính năng tách pha hoàn toàn - tất cả các hàng đủ điều kiện được đọc và lưu vào bộ nhớ tạm thời trước khi thực hiện bất kỳ cập nhật nào.
Điều này đưa chúng ta đến gần hơn với ngữ nghĩa logic ba giai đoạn của tiêu chuẩn SQL, mặc dù xin lưu ý rằng việc thực thi kế hoạch về cơ bản vẫn là lặp đi lặp lại, với các toán tử ở bên phải của ống tạo thành con trỏ đọc và các toán tử ở bên trái tạo thành con trỏ ghi . Nội dung của cuộn vẫn được đọc và xử lý theo từng hàng (nó không được chuyển en masse vì so sánh với tiêu chuẩn SQL có thể khiến bạn tin tưởng).
Những hạn chế của việc tách pha cũng giống như đã đề cập trước đó. Table Spool tiêu thụ tempdb không gian (các trang trong vùng đệm) và có thể yêu cầu đọc và ghi vật lý vào đĩa dưới áp lực bộ nhớ. Trình tối ưu hóa truy vấn chỉ định chi phí ước tính cho cuộn (tùy thuộc vào tất cả các cảnh báo thông thường về ước tính) và sẽ chọn giữa các kế hoạch yêu cầu bảo vệ chống lại Vấn đề Halloween so với các kế hoạch không dựa trên chi phí ước tính như bình thường. Đương nhiên, trình tối ưu hóa có thể chọn không chính xác giữa các tùy chọn vì bất kỳ lý do bình thường nào.
Trong trường hợp này, sự cân bằng giữa việc tăng hiệu quả bằng cách tìm kiếm trực tiếp các hồ sơ đủ điều kiện (những người có mức lương <25.000 đô la) so với chi phí ước tính của ống chỉ cần thiết để tránh Vấn đề Halloween. Một kế hoạch thay thế (trong trường hợp cụ thể này) là quét toàn bộ chỉ mục nhóm (hoặc đống). Chiến lược này không yêu cầu cùng một Bảo vệ Halloween vì các khóa của chỉ mục được phân nhóm không được sửa đổi:

Bởi vì các khóa chỉ mục ổn định, các hàng không thể di chuyển vị trí trong chỉ mục giữa các lần lặp lại, tránh được Vấn đề Halloween trong trường hợp hiện tại. Tùy thuộc vào chi phí thời gian chạy của Quét chỉ mục theo cụm so với kết hợp Tìm kiếm chỉ mục cộng với Bộ đệm bảng háo hức đã thấy trước đây, một kế hoạch có thể thực thi nhanh hơn kế hoạch kia. Một cân nhắc khác là kế hoạch với Bảo vệ Halloween sẽ nhận được nhiều ổ khóa hơn so với kế hoạch hoàn chỉnh và các ổ khóa sẽ được giữ lâu hơn.
Lời kết
Hiểu được Vấn đề Halloween và những ảnh hưởng mà nó có thể gây ra đối với các kế hoạch truy vấn sửa đổi dữ liệu sẽ giúp bạn phân tích các kế hoạch thực thi thay đổi dữ liệu và có thể mang lại cơ hội để tránh các chi phí và tác dụng phụ của việc bảo vệ không cần thiết khi có phương án thay thế.
Có một số dạng của Vấn đề Halloween, không phải tất cả đều là do đọc và ghi vào các khóa của một chỉ mục chung. Vấn đề Halloween cũng không giới hạn ở UPDATE truy vấn. Trình tối ưu hóa truy vấn có nhiều thủ thuật hơn để tránh Sự cố Halloween ngoài việc phân tách giai đoạn bạo lực bằng cách sử dụng Bộ đệm bảng Eager. Những điểm này (và hơn thế nữa) sẽ được khám phá trong các phần tiếp theo của loạt bài này.
[Phần 1 | Phần 2 | Phần 3 | Phần 4]