Tôi đang trong quá trình dọn dẹp nhà cửa của mình (đã quá muộn vào mùa hè để thử dọn dẹp nhà cửa vào mùa xuân). Bạn biết đấy, dọn dẹp tủ quần áo, xem xét đồ chơi của bọn trẻ và sắp xếp tầng hầm. Đó là một quá trình đau đớn. Khi chúng tôi chuyển đến ngôi nhà của mình 10 năm trước, chúng tôi có rất nhiều chỗ. Giờ đây, tôi cảm thấy dường như có mọi thứ ở khắp mọi nơi và việc tìm kiếm thứ mà tôi thực sự đang tìm kiếm trở nên khó khăn hơn và mất nhiều thời gian hơn để dọn dẹp và sắp xếp.
Điều này có giống với bất kỳ cơ sở dữ liệu nào bạn quản lý không?
Nhiều khách hàng mà tôi đã từng làm việc giải quyết vấn đề xóa dữ liệu như một phương pháp cân nhắc. Lúc thực hiện, ai cũng muốn lưu lại mọi thứ. "Chúng tôi không bao giờ biết khi nào chúng tôi có thể cần nó." Sau một hoặc hai năm, ai đó nhận ra có rất nhiều thứ bổ sung trong cơ sở dữ liệu, nhưng bây giờ mọi người sợ loại bỏ nó. “Chúng tôi cần kiểm tra với Bộ phận pháp lý để xem liệu chúng tôi có thể xóa nó hay không.” Nhưng không ai kiểm tra với Legal, hoặc nếu có ai đó, Legal sẽ quay lại với các chủ doanh nghiệp để hỏi những gì cần giữ, và sau đó dự án tạm dừng. “Chúng tôi không thể đi đến thống nhất về những gì có thể bị xóa.” Dự án bị lãng quên, và sau đó hai hoặc bốn năm trôi qua, cơ sở dữ liệu đột nhiên trở thành một terabyte, khó quản lý và mọi người đổ lỗi cho tất cả các vấn đề về hiệu suất do kích thước cơ sở dữ liệu. Bạn nghe thấy những từ “phân vùng” và “cơ sở dữ liệu lưu trữ” được đưa ra xung quanh và đôi khi bạn chỉ cần xóa một loạt dữ liệu, điều này có vấn đề riêng.
Tốt nhất, bạn nên quyết định chiến lược thanh lọc của mình trước khi thực hiện hoặc trong vòng sáu đến mười hai tháng đầu tiên kể từ khi hoạt động. Nhưng vì chúng ta đã vượt qua giai đoạn đó, hãy xem tác động của dữ liệu bổ sung này.
Phương pháp thử nghiệm
Để thiết lập giai đoạn này, tôi đã lấy một bản sao của cơ sở dữ liệu Tín dụng và khôi phục nó vào phiên bản SQL Server 2012 của tôi. Tôi đã bỏ ba chỉ mục không hợp nhất hiện có và thêm hai chỉ mục của riêng tôi:
USE [master]; GO RESTORE DATABASE [Credit] FROM DISK = N'C:\SQLskills\SampleDatabases\Credit\CreditBackup100.bak' WITH FILE = 1, MOVE N'CreditData' TO N'D:\Databases\SQL2012\CreditData.mdf', MOVE N'CreditLog' TO N'D:\Databases\SQL2012\CreditLog.ldf', STATS = 5; GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditData', SIZE = 14680064KB , FILEGROWTH = 524288KB ); GO ALTER DATABASE [Credit] MODIFY FILE ( NAME = N'CreditLog', SIZE = 2097152KB , FILEGROWTH = 524288KB ); GO USE [Credit]; GO DROP INDEX [dbo].[charge].[charge_category_link]; DROP INDEX [dbo].[charge].[charge_provider_link]; DROP INDEX [dbo].[charge].[charge_statement_link]; CREATE NONCLUSTERED INDEX [charge_chargedate] ON [dbo].[charge] ([charge_dt]); CREATE NONCLUSTERED INDEX [charge_provider] ON [dbo].[charge] ([provider_no]);
Sau đó, tôi đã tăng số hàng trong bảng lên 14,4 triệu, bằng cách chèn lại nhóm hàng ban đầu nhiều lần, sửa đổi ngày một chút:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] - 175, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 2 INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 79, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 2000000; GO 3
Cuối cùng, tôi thiết lập một khai thác thử nghiệm để thực thi một loạt các câu lệnh đối với cơ sở dữ liệu bốn lần mỗi câu. Các câu lệnh dưới đây:
ALTER INDEX ALL ON [dbo].[charge] REBUILD; DBCC CHECKDB (Credit) WITH ALL_ERRORMSGS, NO_INFOMSGS; BACKUP DATABASE [Credit] TO DISK = N'D:\Backups\SQL2012\Credit.bak' WITH NOFORMAT, INIT, NAME = N'Credit-Full Database Backup', STATS = 10; SELECT [charge_no], [member_no], [charge_dt], [charge_amt] FROM [dbo].[charge] WHERE [charge_no] = 841345; DECLARE @StartDate DATETIME = '1999-07-01'; DECLARE @EndDate DATETIME = '1999-07-31'; SELECT [charge_dt], COUNT([charge_dt]) FROM [dbo].[charge] WHERE [charge_dt] BETWEEN @StartDate AND @EndDate GROUP BY [charge_dt]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 475 GROUP BY [provider_no]; SELECT [provider_no], COUNT([provider_no]) FROM [dbo].[charge] WHERE [provider_no] = 140 GROUP BY [provider_no];
Trước mỗi câu lệnh tôi thực hiện
DBCC DROPCLEANBUFFERS; GO
để xóa vùng đệm. Rõ ràng đây không phải là thứ để thực thi đối với môi trường sản xuất. Tôi đã làm điều đó ở đây để cung cấp một điểm khởi đầu nhất quán cho mỗi bài kiểm tra.
Sau mỗi lần thực thi, tôi đã tăng kích thước của bảng dbo.charge bằng cách chèn 14,4 triệu hàng mà tôi đã bắt đầu, nhưng tôi đã tăng charge_dt thêm một năm cho mỗi lần thực thi. Ví dụ:
INSERT INTO [dbo].[charge] ( [member_no], [provider_no], [category_no], [charge_dt], [charge_amt], [statement_no], [charge_code] ) SELECT [member_no], [provider_no], [category_no], [charge_dt] + 365, [charge_amt], [statement_no], [charge_code] FROM [dbo].[charge] WHERE [charge_no] BETWEEN 1 AND 14800000; GO
Sau khi bổ sung 14,4 triệu hàng, tôi chạy lại bộ khai thác thử nghiệm. Tôi lặp lại điều này sáu lần, về cơ bản là thêm sáu “năm” dữ liệu. Bảng dbo.charge bắt đầu với dữ liệu từ năm 1999 và sau khi chèn lặp lại chứa dữ liệu cho đến năm 2005.
Kết quả
Kết quả từ việc thực hiện có thể được xem tại đây:
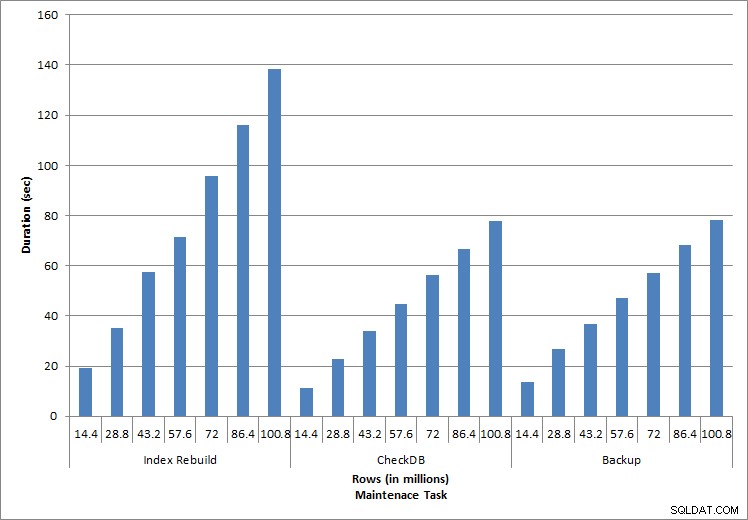
Thời gian thực hiện nhiệm vụ bảo trì
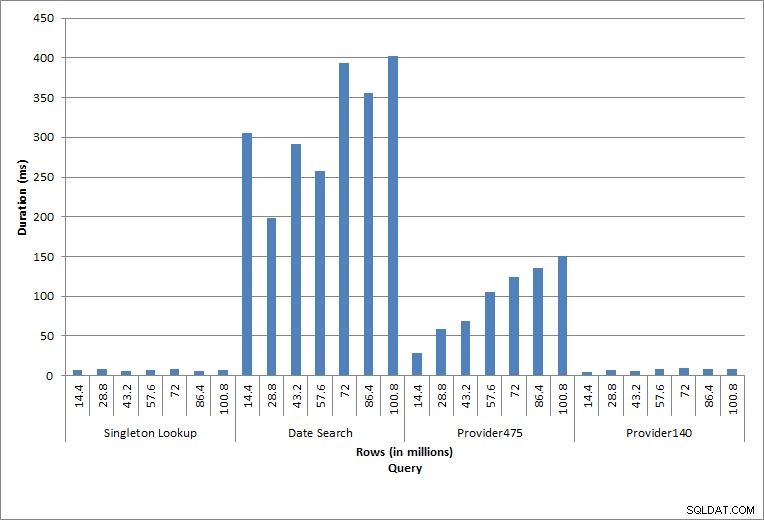
Thời lượng cho các truy vấn
Các câu lệnh riêng lẻ được thực thi phản ánh hoạt động cơ sở dữ liệu điển hình. Xây dựng lại chỉ mục, kiểm tra tính toàn vẹn và sao lưu là một phần của việc bảo trì cơ sở dữ liệu thường xuyên. Các truy vấn đối với bảng phí đại diện cho một tra cứu đơn lẻ cũng như ba biến thể quét phạm vi cụ thể cho dữ liệu trong bảng.
Xây dựng lại chỉ mục, CHECKDB và Sao lưu
Như mong đợi đối với các tác vụ bảo trì, thời lượng và giá trị IO tăng lên khi nhiều hàng hơn được thêm vào cơ sở dữ liệu. Kích thước cơ sở dữ liệu tăng lên 10, và trong khi thời lượng không tăng với tốc độ tương tự, một sự gia tăng nhất quán đã được nhìn thấy. Mỗi nhiệm vụ bảo trì ban đầu mất chưa đến 20 giây để hoàn thành, nhưng khi nhiều hàng được thêm vào, thời lượng cho các nhiệm vụ tăng lên gần 1 phút 20 giây cho 100 triệu hàng (và hơn 2 phút để xây dựng lại chỉ mục). Điều này phản ánh thời gian bổ sung SQL Server cần để hoàn thành tác vụ do dữ liệu bổ sung.
Tra cứu Singleton
Truy vấn đối với dbo.charge cho một charge_no cụ thể luôn tạo ra một hàng - và sẽ tạo ra một hàng bất kể giá trị được sử dụng là bao nhiêu, vì charge_no là một danh tính duy nhất. Có sự thay đổi tối thiểu cho tra cứu này. Khi các hàng liên tục được thêm vào bảng, chỉ mục có thể tăng độ sâu thêm một hoặc hai cấp (nhiều hơn khi bảng trở nên rộng hơn), do đó sẽ thêm một vài IO, nhưng đây là tra cứu đơn lẻ với rất ít IO.
Quét phạm vi
Truy vấn cho phạm vi ngày (charge_dt) đã được sửa đổi sau mỗi lần chèn để tìm kiếm dữ liệu của năm gần đây nhất cho tháng 7 (ví dụ:'2005-07-01' thành '2005-07-01' cho bộ thử nghiệm cuối cùng), nhưng được trả về chỉ hơn 1,2 triệu hàng mỗi lần. Trong trường hợp thực tế, chúng tôi sẽ không mong đợi số hàng giống nhau được trả lại trong cùng một tháng, năm này qua năm khác, cũng như mong đợi số hàng được trả lại như nhau cho mỗi tháng trong năm. Nhưng số lượng hàng có thể nằm trong cùng một phạm vi giữa các tháng, với sự gia tăng nhẹ theo thời gian. Có sự dao động về thời lượng cho truy vấn này, nhưng việc xem xét dữ liệu IO được thu thập từ sys.dm_io_virtual_file_stats cho thấy sự nhất quán về số lần đọc.
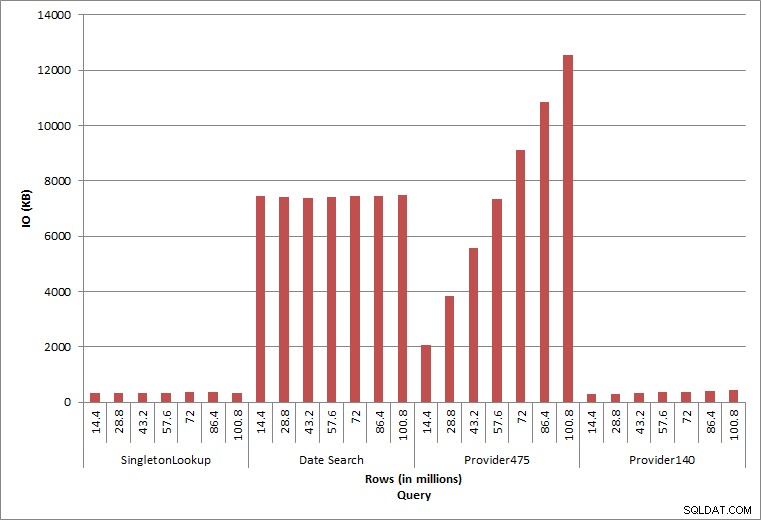
Truy vấn IO
Hai truy vấn cuối cùng, cho hai giá trị provider_no khác nhau, cho thấy tác dụng thực sự của việc lưu giữ dữ liệu. Trong bảng dbo.charge ban đầu, provider_no 475 có hơn 126.000 hàng và provider_no 140 có hơn 1700 hàng. Đối với mỗi 14,4 triệu hàng đã được thêm vào, số lượng hàng gần như giống nhau cho mỗi cung cấp_không được thêm vào. Trong môi trường sản xuất, kiểu phân phối dữ liệu này không phải là hiếm và các truy vấn cho dữ liệu này có thể hoạt động tốt trong những năm đầu tiên của giải pháp, nhưng có thể suy giảm theo thời gian khi nhiều hàng được thêm vào. Thời lượng truy vấn tăng thêm năm (từ 31 mili giây đến 153 mili giây) giữa lần thực thi đầu tiên và cuối cùng đối với provider_no 475. Mặc dù tác động này có vẻ không đáng kể, hãy lưu ý sự gia tăng song song trong IO (ở trên). Nếu đây là một truy vấn được thực thi với tần suất cao và / hoặc có những truy vấn tương tự được thực thi với tần suất thường xuyên, thì tải bổ sung có thể tăng lên và ảnh hưởng đến việc sử dụng tài nguyên tổng thể. Ngoài ra, hãy xem xét tác động khi bạn làm việc với các bảng có hàng tỷ hàng và được sử dụng trong các truy vấn có phép nối phức tạp và tác động đến các nhiệm vụ bảo trì thường xuyên - và cực kỳ quan trọng - của bạn. Cuối cùng, hãy tính đến thời gian khôi phục. Kế hoạch khôi phục sau thảm họa của bạn phải dựa trên thời gian khôi phục và khi kích thước cơ sở dữ liệu tăng lên, cơ sở dữ liệu sẽ mất nhiều thời gian hơn để khôi phục toàn bộ. Nếu bạn không thường xuyên kiểm tra và xác định thời gian khôi phục, thì quá trình khôi phục sau thảm họa có thể mất nhiều thời gian hơn bạn nghĩ.
Tóm tắt
Các ví dụ được hiển thị ở đây là minh họa đơn giản về những gì có thể xảy ra khi chiến lược lưu trữ dữ liệu không được xác định trong quá trình triển khai cơ sở dữ liệu và có nhiều tình huống khác để khám phá và kiểm tra. Dữ liệu cũ hiếm khi được truy cập ảnh hưởng nhiều hơn đến dung lượng trên đĩa. Nó có thể ảnh hưởng đến hiệu suất truy vấn và thời gian của các tác vụ bảo trì. Là một DBA quản lý nhiều cơ sở dữ liệu trên một phiên bản, một cơ sở dữ liệu lưu giữ dữ liệu lịch sử có thể ảnh hưởng đến hiệu suất và nhiệm vụ bảo trì của các cơ sở dữ liệu khác. Hơn nữa, nếu báo cáo thực thi dựa trên dữ liệu lịch sử, điều này có thể tàn phá môi trường OLTP vốn đã bận rộn.
Ngay từ đầu, điều quan trọng là tuổi thọ của dữ liệu trong cơ sở dữ liệu được xác định và đưa ra kế hoạch hành động. Đối với một số giải pháp, yêu cầu giữ tất cả dữ liệu mãi mãi. Trong trường hợp này, hãy sử dụng các chiến lược để giữ cho kích thước cơ sở dữ liệu có thể quản lý được, ví dụ:lưu trữ dữ liệu vào một bảng riêng biệt hoặc cơ sở dữ liệu riêng biệt một cách thường xuyên. Trong trường hợp dữ liệu không cần phải được lưu trữ trong nhiều năm, hãy thực hiện chiến lược thanh lọc loại bỏ dữ liệu một cách thường xuyên. Bằng cách này, bạn có thể vứt bỏ những món đồ chơi không còn dùng để chơi, quần áo không còn vừa vặn và những thứ rác rưởi ngẫu nhiên mà bạn không sử dụng ba tháng một lần… thay vì cứ 10 năm một lần.