Có thể nối tiếp mức độ cách ly cung cấp bảo vệ hoàn toàn từ các hiệu ứng đồng thời có thể đe dọa tính toàn vẹn của dữ liệu và dẫn đến kết quả truy vấn không chính xác. Sử dụng cách ly có thể tuần tự hóa có nghĩa là nếu một giao dịch có thể được hiển thị để tạo ra kết quả chính xác mà không có hoạt động đồng thời, nó sẽ tiếp tục hoạt động chính xác khi cạnh tranh với bất kỳ sự kết hợp nào của các giao dịch đồng thời.
Đây là một đảm bảo mạnh mẽ và một điều có thể phù hợp với kỳ vọng cách ly giao dịch trực quan của nhiều lập trình viên T-SQL (mặc dù trên thực tế, tương đối ít trong số này sẽ thường xuyên sử dụng tính năng cách ly có thể tuần tự hóa trong sản xuất).
Tiêu chuẩn SQL xác định ba mức cách ly bổ sung cung cấp ACID yếu hơn nhiều đảm bảo tính cách ly hơn là có thể nối tiếp hóa, đổi lại khả năng đồng thời cao hơn và ít tác dụng phụ tiềm ẩn hơn như chặn, bế tắc và hủy bỏ thời gian cam kết.
Không giống như cách ly có thể nối tiếp hóa, các mức cách ly khác chỉ được xác định theo các hiện tượng đồng thời nhất định có thể được quan sát thấy. Mức cách ly mạnh nhất tiếp theo trong số các mức cách ly tiêu chuẩn sau khi có thể nối tiếp hóa được đặt tên là đọc có thể lặp lại . Tiêu chuẩn SQL chỉ định rằng các giao dịch ở cấp độ này cho phép một hiện tượng đồng thời duy nhất được gọi là bóng ma .
Cũng như trước đây chúng ta đã thấy những điểm khác biệt quan trọng giữa ý nghĩa trực quan chung của các thuộc tính giao dịch ACID và thực tế, hiện tượng bóng ma bao gồm một loạt các hành vi hơn mức thường được đánh giá cao.
Bài đăng trong loạt bài này xem xét các đảm bảo thực tế được cung cấp bởi bài đọc có thể lặp lại mức độ cô lập và hiển thị một số hành vi liên quan đến bóng ma có thể gặp phải. Để minh họa một số điểm, chúng ta sẽ tham khảo truy vấn ví dụ đơn giản sau, trong đó nhiệm vụ đơn giản là đếm tổng số hàng trong bảng:
SELECT COUNT_BIG(*) FROM dbo.SomeTable;
Đọc lặp lại
Một điều kỳ lạ về mức độ cách ly đọc lặp lại là nó không thực sự đảm bảo rằng các lần đọc có thể lặp lại , ít nhất là theo một nghĩa thường được hiểu. Đây là một ví dụ khác mà chỉ ý nghĩa trực quan có thể gây hiểu lầm. Việc thực thi cùng một truy vấn hai lần trong cùng một giao dịch đọc lặp lại có thể thực sự trả lại các kết quả khác nhau.
Ngoài ra, việc triển khai SQL Server đọc lặp lại có nghĩa là một lần đọc một tập dữ liệu có thể bỏ sót một số hàng về mặt logic cần được xem xét trong kết quả truy vấn. Mặc dù không thể phủ nhận việc triển khai cụ thể, nhưng hành vi này hoàn toàn phù hợp với định nghĩa về đọc lặp lại có trong tiêu chuẩn SQL.
Điều cuối cùng tôi muốn nhanh chóng lưu ý trước khi đi sâu vào chi tiết, đó là tính năng đọc lặp lại trong SQL Server không cung cấp chế độ xem dữ liệu theo thời điểm.
Số lần đọc không lặp lại
Mức cách ly có thể đọc lặp lại cung cấp đảm bảo rằng dữ liệu sẽ không thay đổi trong thời gian tồn tại của giao dịch sau khi giao dịch đã được đọc lần đầu tiên.
Có một vài điều tinh tế trong định nghĩa đó. Đầu tiên, nó cho phép dữ liệu thay đổi sau giao dịch bắt đầu nhưng trước khi dữ liệu là đầu tiên đã truy cập. Thứ hai, không có gì đảm bảo rằng giao dịch sẽ thực sự gặp phải tất cả dữ liệu đủ điều kiện hợp lý. Chúng ta sẽ xem các ví dụ về cả hai điều này ngay sau đây.
Có một điều sơ bộ khác mà chúng ta cần nhanh chóng thoát ra, liên quan đến truy vấn mẫu mà chúng ta sẽ sử dụng. Công bằng mà nói, ngữ nghĩa của truy vấn này hơi mờ. Có nguy cơ nghe có vẻ hơi triết lý, điều đó có nghĩa là gì để đếm số hàng trong bảng? Kết quả có nên phản ánh trạng thái của bảng như nó ở một thời điểm cụ thể nào đó không? Thời điểm này nên bắt đầu hay kết thúc giao dịch hay một cái gì đó khác?
Điều này có vẻ hơi khó hiểu, nhưng câu hỏi là một câu hỏi hợp lệ trong bất kỳ cơ sở dữ liệu nào hỗ trợ đọc và sửa đổi dữ liệu đồng thời. Việc thực thi truy vấn mẫu của chúng tôi có thể mất một khoảng thời gian dài tùy ý (ví dụ như bảng đủ lớn hoặc các hạn chế về tài nguyên) vì vậy các thay đổi đồng thời không chỉ có thể xảy ra mà chúng có thể không thể tránh khỏi .
Vấn đề cơ bản ở đây là khả năng xảy ra hiện tượng đồng thời được gọi là bóng ma trong tiêu chuẩn SQL. Trong khi chúng tôi đang đếm các hàng trong bảng, một giao dịch đồng thời khác có thể chèn hàng mới ở một nơi mà chúng tôi đã kiểm tra hoặc thay đổi một hàng mà chúng tôi chưa kiểm tra theo cách mà nó di chuyển đến vị trí mà chúng tôi đã xem xét. Mọi người thường nghĩ về bóng ma là những hàng có thể xuất hiện một cách kỳ diệu khi đọc lần thứ hai, trong một câu lệnh riêng biệt, nhưng hiệu ứng có thể tinh tế hơn thế nhiều.
Ví dụ về chèn đồng thời
Ví dụ đầu tiên này cho thấy cách chèn đồng thời có thể tạo ra không thể lặp lại đọc và / hoặc dẫn đến các hàng bị bỏ qua. Hãy tưởng tượng rằng bảng thử nghiệm của chúng tôi ban đầu chứa năm hàng với các giá trị được hiển thị bên dưới:

Bây giờ chúng tôi đặt mức cô lập thành đọc có thể lặp lại, bắt đầu giao dịch và chạy truy vấn đếm của chúng tôi. Như bạn mong đợi, kết quả là năm . Không có bí ẩn lớn cho đến nay.
Vẫn đang thực thi bên trong cùng một giao dịch đọc có thể lặp lại , chúng tôi chạy lại truy vấn đếm, nhưng lần này trong khi giao dịch đồng thời thứ hai đang chèn các hàng mới vào cùng một bảng. Biểu đồ bên dưới cho thấy chuỗi sự kiện, với giao dịch thứ hai thêm các hàng có giá trị 2 và 6 (bạn có thể nhận thấy những giá trị này dễ thấy bởi sự vắng mặt của chúng ngay phía trên):
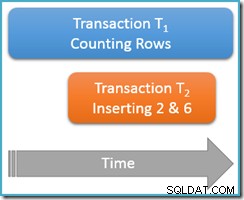
Nếu truy vấn đếm của chúng tôi đang chạy ở serializable mức cô lập, nó sẽ được đảm bảo đếm cả năm hoặc bảy hàng (xem bài viết trước trong loạt bài này nếu bạn cần cập nhật về lý do tại sao lại như vậy). Làm thế nào để chạy ở ít bị cô lập hơn mức độ đọc lặp lại có ảnh hưởng đến mọi thứ không?
Chà, có thể đọc lại sự cô lập đảm bảo rằng lần chạy thứ hai của truy vấn đếm sẽ thấy tất cả các hàng đã đọc trước đó và chúng sẽ ở trạng thái giống như trước đó. Điểm nổi bật là tính năng cô lập đọc lặp lại cho biết không có gì về cách giao dịch sẽ xử lý các hàng mới (các bóng ma).
Hãy tưởng tượng rằng giao dịch đếm hàng của chúng ta (T 1 ) có một chiến lược thực thi vật lý trong đó các hàng được tìm kiếm theo thứ tự chỉ mục tăng dần. Đây là một trường hợp phổ biến, chẳng hạn khi quét chỉ mục b-tree theo thứ tự chuyển tiếp được sử dụng bởi công cụ thực thi. Bây giờ, chỉ sau giao dịch T 1 đếm hàng 1 và 3 theo thứ tự tăng dần, giao dịch T 2 có thể lẻn vào, chèn hàng mới 2 và 6, sau đó thực hiện giao dịch của nó.
Mặc dù chúng tôi chủ yếu nghĩ về các hành vi logic tại thời điểm này, tôi nên đề cập rằng không có gì trong việc triển khai SQL Server khóa việc đọc lặp lại để ngăn chặn giao dịch T 2 từ việc này. Các khóa dùng chung được thực hiện bởi giao dịch T 1 trên các hàng đã đọc trước đó ngăn những hàng đó bị thay đổi, nhưng chúng không ngăn hàng mới từ việc được chèn vào dải giá trị được kiểm tra bởi truy vấn đếm của chúng tôi (không giống như các khóa dải khóa trong khóa cách ly có thể nối tiếp hóa sẽ khóa).
Dù sao, với hai hàng mới được cam kết, giao dịch T 1 tiếp tục tìm kiếm theo thứ tự tăng dần, cuối cùng gặp hàng 4, 5, 6 và 7. Lưu ý rằng T 1 thấy hàng 6 mới trong trường hợp này, nhưng không hàng mới 2 (do tìm kiếm theo thứ tự và vị trí của nó khi chèn diễn ra).
Kết quả là lượt đọc có thể lặp lại đếm các báo cáo truy vấn rằng bảng chứa sáu hàng (giá trị 1, 3, 4, 5, 6 và 7). Kết quả này không phù hợp với kết quả trước đó của năm hàng có được bên trong cùng một giao dịch . Lần đọc thứ hai đếm được hàng ma 6 nhưng bỏ sót hàng ảo 2. Quá nhiều cho ý nghĩa trực quan của một lần đọc có thể lặp lại!
Ví dụ về cập nhật đồng thời
Một tình huống tương tự có thể phát sinh với một bản cập nhật đồng thời thay vì một phụ trang. Hãy tưởng tượng bảng thử nghiệm của chúng tôi được đặt lại để chứa cùng năm hàng như trước:

Lần này, chúng tôi sẽ chỉ chạy truy vấn đếm của mình một lần ở đọc có thể lặp lại mức cô lập, trong khi giao dịch đồng thời thứ hai cập nhật hàng có giá trị 5 để có giá trị là 2:
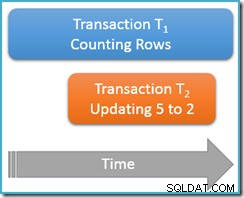
Giao dịch T 1 lại bắt đầu đếm các hàng, (theo thứ tự tăng dần) gặp hàng 1 và 3 trước tiên. Bây giờ, giao dịch T2 trượt vào, thay đổi giá trị của hàng 5 thành 2 và cam kết:

Tôi đã hiển thị hàng được cập nhật ở cùng một vị trí như trước để làm rõ ràng thay đổi, nhưng chỉ mục b-tree mà chúng tôi đang quét duy trì dữ liệu theo thứ tự logic, vì vậy hình ảnh thực tế gần với điều này hơn:

Vấn đề là giao dịch T 1 đang đồng thời quét cùng một cấu trúc này theo thứ tự chuyển tiếp, hiện đang được định vị chỉ sau mục nhập cho giá trị 3. Truy vấn đếm tiếp tục quét về phía trước từ thời điểm đó, tìm hàng 4 và 7 (tất nhiên là không phải hàng 5).
Tóm lại, truy vấn đếm có các hàng 1, 3, 4 và 7 trong trường hợp này. Nó báo cáo số lượng bốn hàng - thật lạ, vì bảng dường như có năm hàng xuyên suốt!
Lần chạy thứ hai của truy vấn đếm trong cùng một giao dịch đọc có thể lặp lại sẽ báo cáo năm hàng, vì những lý do tương tự như trước đây. Lưu ý cuối cùng, trong trường hợp bạn đang thắc mắc, việc xóa đồng thời không tạo cơ hội cho sự bất thường dựa trên bóng ma trong điều kiện cách ly đọc lặp lại.
Lời kết
Cả hai ví dụ trước đều sử dụng tính năng quét theo thứ tự tăng dần của cấu trúc chỉ mục để trình bày một cái nhìn đơn giản về loại hiệu ứng mà các phantoms có thể có trên có thể đọc được lặp lại truy vấn. Điều quan trọng là phải hiểu rằng những hình minh họa này không dựa trên bất kỳ cách quan trọng nào vào hướng quét hoặc thực tế là chỉ mục b-tree đã được sử dụng. Vui lòng không hình thành quan điểm rằng việc quét theo thứ tự có trách nhiệm bằng cách nào đó và do đó cần phải tránh!
Các hiệu ứng đồng thời tương tự có thể được nhìn thấy khi quét cấu trúc chỉ mục theo thứ tự giảm dần hoặc trong nhiều tình huống truy cập dữ liệu vật lý khác. Điểm chung là các hiện tượng bóng ma được tiêu chuẩn SQL cho phép cụ thể (mặc dù không bắt buộc) đối với các giao dịch ở cấp độ cô lập đọc lặp lại.
Không phải tất cả các giao dịch đều yêu cầu đảm bảo cách ly hoàn toàn được cung cấp bởi cách ly có thể nối tiếp hóa và không nhiều hệ thống có thể chịu đựng được các tác dụng phụ nếu chúng xảy ra. Tuy nhiên, bạn phải hiểu rõ về chính xác điều gì đảm bảo cung cấp các mức cách ly khác nhau.
Lần tới
Phần tiếp theo của loạt bài này xem xét các đảm bảo cách ly thậm chí còn yếu hơn được cung cấp bởi mức cách ly mặc định của SQL Server, đọc cam kết .
[Xem chỉ mục cho toàn bộ chuỗi]