Chịu trách nhiệm về hiệu suất của SQL Server có thể là một nhiệm vụ khó khăn. Có rất nhiều lĩnh vực mà chúng tôi phải theo dõi và hiểu rõ. Chúng tôi cũng được kỳ vọng có thể cập nhật tất cả các chỉ số đó và luôn biết điều gì đang xảy ra trên máy chủ của chúng tôi. Tôi muốn hỏi các DBA điều đầu tiên mà họ nghĩ đến khi nghe cụm từ “điều chỉnh SQL Server;” phản hồi áp đảo mà tôi nhận được là “điều chỉnh truy vấn”. Tôi đồng ý rằng việc điều chỉnh các truy vấn là rất quan trọng và là nhiệm vụ không bao giờ kết thúc mà chúng tôi phải đối mặt vì khối lượng công việc liên tục thay đổi.
Tuy nhiên, có nhiều khía cạnh khác cần xem xét khi nghĩ về hiệu suất của SQL Server. Có rất nhiều cài đặt cấp phiên bản, hệ điều hành và cơ sở dữ liệu cần được tinh chỉnh từ các cài đặt mặc định. Trở thành một nhà tư vấn cho phép tôi làm việc trong nhiều lĩnh vực kinh doanh khác nhau và tiếp xúc với tất cả các loại vấn đề về hiệu suất. Khi làm việc với một khách hàng mới, tôi cố gắng luôn thực hiện kiểm tra tình trạng của máy chủ để biết những gì tôi đang xử lý. Trong khi thực hiện các kiểm tra này, một trong những điều mà tôi đã nhiều lần nhận thấy là độ trễ đọc và ghi quá mức trên các đĩa nơi chứa dữ liệu SQL Server và tệp nhật ký.
Độ trễ đọc / ghi
Để xem độ trễ đĩa của bạn trong SQL Server, bạn có thể nhanh chóng và dễ dàng truy vấn DMV sys.dm_io_virtual_file_stats . DMV này chấp nhận hai tham số: database_id và file_id . Điều tuyệt vời là bạn có thể vượt qua NULL dưới dạng cả hai giá trị và trả về độ trễ cho tất cả các tệp cho tất cả cơ sở dữ liệu. Các cột đầu ra bao gồm:
- database_id
- file_id
- sample_ms
- num_of_reads
- num_of_bytes_read
- io_stall_read_ms
- num_of_writes
- num_of_bytes_written
- io_stall_write_ms
- io_stall
- size_on_disk_bytes
- file_handle
Như bạn có thể thấy từ danh sách cột, có thông tin thực sự hữu ích mà DMV này truy xuất, tuy nhiên chỉ cần chạy SELECT * FROM sys.dm_io_virtual_file_stats (NULL, NULL); không giúp được gì nhiều trừ khi bạn đã ghi nhớ database_ids của mình và có thể làm một số phép toán trong đầu.
Khi tôi truy vấn thống kê tệp, tôi sử dụng truy vấn từ bài đăng trên blog của Paul Randal, “Cách kiểm tra độ trễ hệ thống con IO từ bên trong SQL Server”. Tập lệnh này giúp tên cột dễ đọc hơn, bao gồm ổ đĩa chứa tệp, tên cơ sở dữ liệu và đường dẫn đến tệp.
Bằng cách truy vấn DMV này, bạn có thể dễ dàng biết vị trí các điểm truy cập I / O cho các tệp của bạn. Bạn có thể xem đâu là độ trễ ghi và đọc cao nhất và cơ sở dữ liệu nào là thủ phạm. Biết được điều này sẽ cho phép bạn bắt đầu xem xét các cơ hội điều chỉnh cho các cơ sở dữ liệu cụ thể đó. Điều này có thể bao gồm điều chỉnh chỉ mục, kiểm tra xem vùng đệm có bị áp lực bộ nhớ hay không, có thể di chuyển cơ sở dữ liệu sang một phần nhanh hơn của hệ thống con I / O hoặc có thể phân vùng cơ sở dữ liệu và trải rộng các nhóm tệp trên các LUN khác.
Vì vậy, bạn chạy truy vấn và nó trả về rất nhiều giá trị tính bằng mili giây cho độ trễ - giá trị nào ổn và giá trị nào xấu?
Giá trị nào là tốt hay xấu?
Nếu bạn hỏi SQLskills, chúng tôi sẽ cho bạn biết điều gì đó dọc theo dòng:
- Tuyệt vời:<1ms
- Rất tốt:<5ms
- Tốt:5 - 10ms
- Kém:10 - 20 mili giây
- Kém:20 - 100 mili giây
- Thực sự tệ:100 - 500 mili giây
- OMG !:> 500ms
Nếu bạn thực hiện tìm kiếm trên Bing, bạn sẽ tìm thấy các bài báo từ Microsoft đưa ra các đề xuất tương tự như:
- Tốt:<10ms
- Được:10 - 20 mili giây
- Kém:20 - 50 mili giây
- Kém nghiêm trọng:> 50ms
Như bạn có thể thấy, có một số biến thể nhỏ trong các con số, nhưng sự đồng thuận là bất kỳ thứ gì trên 20ms đều có thể bị coi là rắc rối. Như đã nói, độ trễ ghi trung bình của bạn có thể là 20 mili giây và điều đó có thể chấp nhận được 100% đối với tổ chức của bạn và điều đó không sao cả. Bạn cần biết độ trễ I / O chung cho hệ thống của mình để khi mọi thứ trở nên tồi tệ, bạn sẽ biết thế nào là bình thường.
Độ trễ đọc / ghi của tôi không tốt, tôi phải làm gì?
Nếu bạn nhận thấy rằng độ trễ đọc và ghi là không tốt trên máy chủ của mình, có một số nơi bạn có thể bắt đầu tìm kiếm sự cố. Đây không phải là danh sách đầy đủ mà là một số hướng dẫn về nơi bắt đầu.
- Phân tích khối lượng công việc của bạn. Chiến lược lập chỉ mục của bạn có đúng không? Không có các chỉ mục thích hợp sẽ dẫn đến nhiều dữ liệu được đọc từ đĩa. Quét thay vì tìm kiếm.
- Thống kê của bạn có cập nhật không? Số liệu thống kê không hợp lệ có thể tạo ra những lựa chọn không tốt cho các kế hoạch thực hiện.
- Bạn có gặp vấn đề về đánh giá thông số đang gây ra các kế hoạch thực thi kém không?
- Vùng đệm có chịu áp lực về bộ nhớ, chẳng hạn như từ bộ nhớ cache của gói bị cồng kềnh?
- Có vấn đề gì về mạng không? Vải SAN của bạn có hoạt động chính xác không? Yêu cầu kỹ sư lưu trữ của bạn xác thực mạng và mạng.
- Di chuyển các điểm phát sóng sang các mảng lưu trữ khác nhau. Trong một số trường hợp, nó có thể là một cơ sở dữ liệu đơn lẻ hoặc chỉ một vài cơ sở dữ liệu gây ra tất cả các vấn đề. Cách ly chúng vào một bộ đĩa khác hoặc đĩa cao cấp hơn như SSD có thể là giải pháp hợp lý nhất.
- Bạn có thể phân vùng cơ sở dữ liệu để di chuyển các bảng rắc rối sang đĩa khác để phân chia tải không?
Thống kê Chờ
Cũng giống như theo dõi số liệu thống kê về tệp của bạn, theo dõi số liệu thống kê về thời gian chờ của bạn có thể cho bạn biết rất nhiều về những tắc nghẽn trong môi trường của bạn. Chúng tôi may mắn có một DMV tuyệt vời khác ( sys.dm_os_wait_stats ) mà chúng tôi có thể truy vấn sẽ lấy tất cả thông tin chờ có sẵn được thu thập kể từ lần khởi động lại cuối cùng hoặc kể từ lần cuối cùng các lần chờ được đặt lại; cũng có sự chờ đợi liên quan đến hiệu suất đĩa. DMV này sẽ trả lại thông tin quan trọng bao gồm:
- wait_type
- wait_task_count
- wait_time_ms
- max_wait_time_ms
- signal_wait_time_ms
Truy vấn DMV này trên máy SQL Server 2014 của tôi trả về 771 kiểu chờ. SQL Server luôn chờ đợi điều gì đó, nhưng có rất nhiều sự chờ đợi mà chúng ta không nên lo lắng. Vì lý do này, tôi sử dụng một truy vấn khác từ Paul Randal; bài đăng trên blog của anh ấy, “Hãy đợi thống kê, hoặc vui lòng cho tôi biết nó đau ở đâu”, có một kịch bản tuyệt vời loại trừ một loạt các lần chờ đợi mà chúng tôi không thực sự quan tâm. Phao-lô cũng liệt kê ra nhiều sự chờ đợi có vấn đề chung cũng như đưa ra hướng dẫn cho những sự chờ đợi chung.
Tại sao số liệu thống kê về thời gian chờ lại quan trọng?
Theo dõi thời gian chờ đợi cao cho các sự kiện nhất định sẽ cho bạn biết khi nào có sự cố xảy ra. Bạn cần có cơ sở để biết đâu là bình thường và khi nào mọi thứ vượt quá ngưỡng hoặc mức độ đau. Nếu bạn có PAGEIOLATCH_XX thực sự cao thì bạn biết SQL Server đang phải đợi một trang dữ liệu được đọc từ đĩa. Đây có thể là đĩa, bộ nhớ, thay đổi khối lượng công việc hoặc một số vấn đề khác.
Một khách hàng gần đây mà tôi đang làm việc đã thấy một số hành vi rất bất thường. Khi tôi kết nối với máy chủ cơ sở dữ liệu và có thể quan sát máy chủ đang tải công việc, tôi ngay lập tức bắt đầu kiểm tra số liệu thống kê tệp, số liệu thống kê chờ, sử dụng bộ nhớ, sử dụng tempdb, v.v. Một điều nổi bật ngay lập tức là WRITELOG là sự chờ đợi phổ biến nhất. Tôi biết việc chờ đợi này liên quan đến việc lưu nhật ký vào đĩa và khiến tôi nhớ đến loạt bài của Paul về Cắt mỡ trong nhật ký giao dịch. WRITELOG cao Các lần đợi thường có thể được xác định bằng độ trễ ghi cao đối với tệp nhật ký giao dịch. Vì vậy, sau đó tôi đã sử dụng tập lệnh thống kê tệp của mình để xem lại độ trễ đọc và ghi trên đĩa. Sau đó, tôi có thể thấy độ trễ ghi cao trên tệp dữ liệu nhưng không phải tệp nhật ký của tôi. Khi xem WRITELOG đó là một thời gian chờ cao nhưng thời gian chờ tính bằng ms cực kỳ thấp. Tuy nhiên, điều gì đó trong bài đăng thứ hai của loạt bài về Paul vẫn còn trong đầu tôi. Tôi nên xem xét cài đặt tăng trưởng tự động cho cơ sở dữ liệu chỉ để loại trừ "Cái chết của một nghìn vết cắt". Khi xem xét các thuộc tính cơ sở dữ liệu của cơ sở dữ liệu, tôi thấy rằng tệp dữ liệu được đặt thành tự động tăng 1MB và nhật ký giao dịch được đặt thành tự động tăng 10%. Cả hai tệp đều có gần 0 dung lượng chưa sử dụng. Tôi đã chia sẻ với khách hàng những gì tôi tìm thấy và điều này đã giết chết hiệu suất của họ như thế nào. Chúng tôi đã nhanh chóng thực hiện thay đổi thích hợp và quá trình thử nghiệm đã được tiến hành, nhân tiện, tốt hơn nhiều. Đáng buồn thay, đây không phải là lần duy nhất tôi gặp phải vấn đề chính xác này. Một lần khác, một cơ sở dữ liệu có kích thước 66GB, nó đã tăng lên 1MB.
Thu thập dữ liệu của bạn
Nhiều chuyên gia dữ liệu đã tạo ra các quy trình để thu thập số liệu thống kê về tệp và chờ một cách thường xuyên để phân tích. Vì số liệu thống kê chờ là tích lũy, bạn sẽ muốn nắm bắt chúng và so sánh các delta giữa các thời điểm khác nhau trong ngày hoặc trước và sau khi các quy trình nhất định chạy. Điều này không quá phức tạp và có rất nhiều bài đăng trên blog để mọi người chia sẻ cách họ đã hoàn thành việc này. Phần quan trọng là đo lường dữ liệu này để bạn có thể theo dõi nó. Làm thế nào để bạn biết hôm nay mọi thứ tốt hơn hay tệ hơn trên máy chủ cơ sở dữ liệu của bạn trừ khi bạn biết dữ liệu từ ngày hôm qua?
SQL Sentry có thể trợ giúp như thế nào?
Tôi rất vui vì bạn đã hỏi! SQL Sentry Performance Advisor đưa ra độ trễ và chờ ở phía trước và trung tâm trên bảng điều khiển. Bất kỳ sự bất thường nào cũng dễ dàng phát hiện ra; bạn có thể chuyển sang chế độ lịch sử và xem xu hướng trước đó cũng như so sánh với các giai đoạn trước. Điều này có thể được chứng minh là vô giá khi phân tích những "điều gì đã xảy ra?" khoảnh khắc. Mọi người đã nhận được cuộc gọi đó, "Hôm qua khoảng 3 giờ chiều, hệ thống dường như bị đóng băng, bạn có thể cho chúng tôi biết chuyện gì đã xảy ra không?" Ừm, chắc chắn rồi, hãy để tôi kéo Profiler lên và quay ngược thời gian. Nếu bạn có một công cụ giám sát như Cố vấn Hiệu suất, bạn sẽ có thông tin lịch sử đó trong tầm tay.
Ngoài các biểu đồ và đồ thị trên bảng điều khiển, bạn có khả năng sử dụng các cảnh báo tích hợp sẵn cho các điều kiện như Thời gian chờ trên đĩa cao, Số lượng VLF cao, CPU cao, Thời gian sử dụng trang thấp, v.v. Bạn cũng có khả năng tạo điều kiện tùy chỉnh của riêng mình và bạn có thể học từ các ví dụ trên trang SQL Sentry hoặc thông qua Condition Exchange (Aaron Bertrand đã viết blog về điều này). Tôi đã đề cập đến khía cạnh cảnh báo của điều này trong bài viết cuối cùng của tôi về Cảnh báo tác nhân SQL Server.
Trên tab Dung lượng đĩa của Trình tư vấn hiệu suất, rất dễ dàng thấy những thứ như cài đặt tự động phát triển và số lượng VLF cao. Bạn nên biết, nhưng trong trường hợp không, tự động phát triển thêm 1MB hoặc 10% không phải là cài đặt tốt nhất. Nếu bạn thấy những giá trị này (Cố vấn hiệu suất làm nổi bật chúng cho bạn), bạn có thể nhanh chóng ghi chú và lên lịch thời gian để thực hiện các điều chỉnh thích hợp. Tôi cũng thích cách nó hiển thị Tổng số VLF; quá nhiều VLF có thể rất có vấn đề. Bạn nên đọc bài đăng của Kimberly “VLF trong Nhật ký giao dịch - quá nhiều hay quá ít?” nếu bạn chưa có.
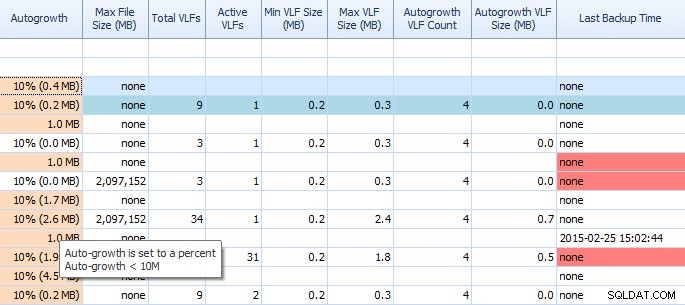 Một phần lưới trên tab Dung lượng đĩa của Cố vấn hiệu suất
Một phần lưới trên tab Dung lượng đĩa của Cố vấn hiệu suất
Một cách khác mà Trình tư vấn hiệu suất có thể trợ giúp là thông qua mô-đun Hoạt động trên đĩa đã được cấp bằng sáng chế của nó. Ở đây bạn có thể thấy rằng tempdb trên F:đang gặp phải độ trễ ghi đáng kể; bạn có thể biết điều này bằng các đường màu đỏ dày bên dưới đồ họa đĩa. Bạn cũng có thể nhận thấy rằng F:là ký tự ổ đĩa duy nhất có đĩa được biểu thị bằng màu đỏ; đây là một dấu hiệu trực quan cho thấy ổ đĩa có phân vùng bị lệch, điều này có thể góp phần gây ra sự cố I / O.
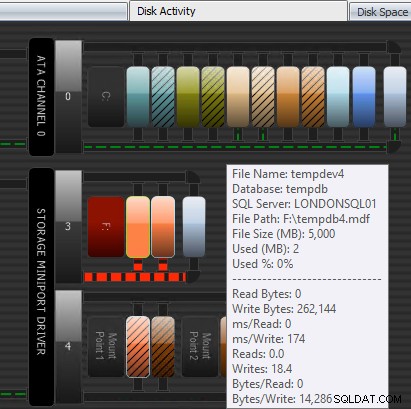 Mô-đun Hoạt động trên đĩa của Cố vấn Hiệu suất
Mô-đun Hoạt động trên đĩa của Cố vấn Hiệu suất
Và bạn có thể tương quan thông tin này trong các lưới bên dưới - các vấn đề cũng được đánh dấu trong các lưới ở đó, và hãy xem ms / Write cột:
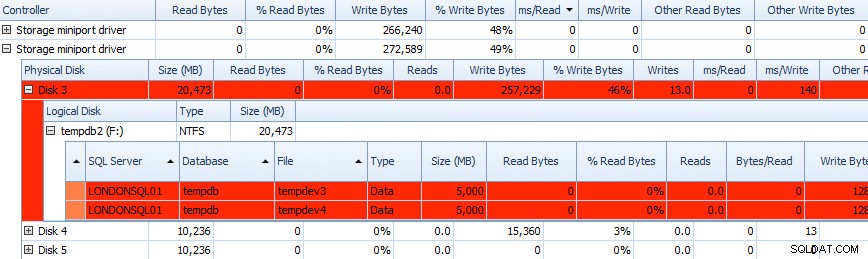 Một phần lưới dữ liệu Hoạt động trên đĩa của Trình tư vấn hiệu suất
Một phần lưới dữ liệu Hoạt động trên đĩa của Trình tư vấn hiệu suất
Bạn cũng có thể xem thông tin này theo cách hồi tố; nếu ai đó phàn nàn về sự cố tắc nghẽn ổ đĩa vào chiều hôm qua hoặc thứ Ba tuần trước, bạn chỉ cần quay lại bằng cách sử dụng bộ chọn ngày trong thanh công cụ và xem thông lượng và độ trễ trung bình cho bất kỳ phạm vi nào. Để biết thêm thông tin về mô-đun Hoạt động trên đĩa, hãy xem Hướng dẫn sử dụng.
Trình cố vấn hiệu suất cũng có rất nhiều báo cáo tích hợp trong các danh mục Hiệu suất, Chặn, SQL hàng đầu, Dung lượng đĩa / tệp và bế tắc. Hình ảnh bên dưới cho bạn thấy cách truy cập báo cáo Dung lượng đĩa / Tệp. Việc có các báo cáo chỉ bằng một vài cú nhấp chuột là rất có giá trị để có thể tìm hiểu ngay lập tức và xem những gì đang (hoặc đã) đang xảy ra trên máy chủ của bạn.
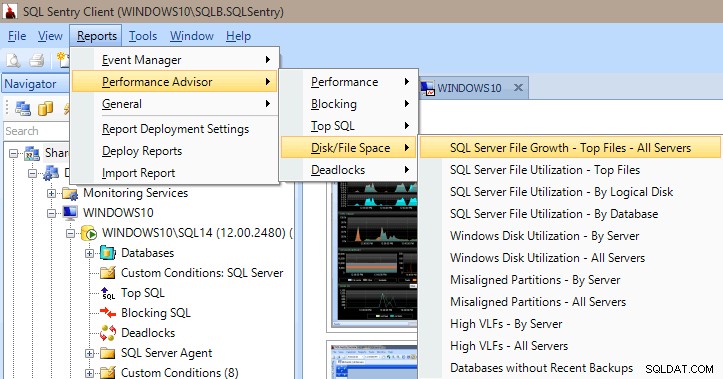 Báo cáo của Cố vấn Hiệu suất
Báo cáo của Cố vấn Hiệu suất
Tóm tắt
Điều quan trọng rút ra từ bài đăng này là biết các chỉ số hiệu suất của bạn. Một tuyên bố phổ biến giữa các chuyên gia dữ liệu là đĩa là nút cổ chai số 1 của chúng tôi. Biết được số liệu thống kê tệp của máy chủ của bạn sẽ giúp bạn hiểu được những điểm khó khăn trên máy chủ của bạn. Cùng với số liệu thống kê về tệp, số liệu thống kê về thời gian chờ của bạn cũng là một nơi tuyệt vời để xem xét. Nhiều người, bao gồm cả tôi, bắt đầu ở đó. Có một công cụ như SQL Sentry Performance Advisor có thể giúp bạn khắc phục sự cố một cách đáng kể và tìm ra các vấn đề về hiệu suất trước khi chúng trở nên quá rắc rối; tuy nhiên, nếu bạn không có công cụ này, hãy làm quen với sys.dm_os_wait_stats và sys.dm_io_virtual_file_stats sẽ phục vụ bạn tốt để bắt đầu điều chỉnh máy chủ của bạn.