Một định nghĩa đơn giản về giá trị trung bình là:
Giá trị trung bình là giá trị giữa trong danh sách các số đã được sắp xếpĐể làm rõ điều đó một chút, chúng ta có thể tìm giá trị trung bình của danh sách các số bằng cách sử dụng quy trình sau:
- Sắp xếp các số (theo thứ tự tăng dần hoặc giảm dần, không quan trọng).
- Số ở giữa (theo vị trí) trong danh sách đã sắp xếp là số trung vị.
- Nếu có hai số "ở giữa bằng nhau" thì trung vị là giá trị trung bình của hai giá trị ở giữa.
Aaron Bertrand trước đây đã kiểm tra hiệu suất một số cách để tính giá trị trung bình trong SQL Server:
- Cách nhanh nhất để tính số trung vị là gì?
- Các phương pháp tốt nhất cho giá trị trung bình được nhóm theo nhóm
Rob Farley gần đây đã thêm một cách tiếp cận khác nhằm vào các bản cài đặt trước năm 2012:
- Medians trước SQL 2012
Bài viết này giới thiệu một phương pháp mới sử dụng con trỏ động.
Phương pháp OFFSET-FETCH 2012
Chúng tôi sẽ bắt đầu bằng cách xem xét triển khai hoạt động hiệu quả nhất, được tạo bởi Peter Larsson. Nó sử dụng SQL Server 2012 OFFSET phần mở rộng cho ORDER BY để định vị một cách hiệu quả một hoặc hai hàng giữa cần thiết để tính giá trị trung bình.
OFFSET Trung vị Đơn
Bài báo đầu tiên của Aaron đã thử nghiệm tính toán một giá trị trung bình duy nhất trên một bảng mười triệu hàng:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
Giải pháp của Peter Larsson sử dụng OFFSET phần mở rộng là:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Đoạn mã trên mã hóa kết quả của việc đếm các hàng trong bảng. Tất cả các phương pháp đã thử nghiệm để tính toán giá trị trung bình đều cần số lượng này để tính số hàng trung bình, do đó, nó là một chi phí không đổi. Bỏ thao tác đếm hàng ra khỏi thời gian sẽ tránh được một nguồn biến thể có thể xảy ra.
Kế hoạch thực thi cho OFFSET giải pháp được hiển thị bên dưới:

Toán tử Hàng đầu nhanh chóng bỏ qua các hàng không cần thiết, chỉ chuyển một hoặc hai hàng cần thiết để tính giá trị trung bình vào Tổng hợp luồng. Khi chạy với bộ nhớ cache ấm và bộ sưu tập kế hoạch thực thi bị tắt, truy vấn này sẽ chạy trong 910 mili giây trung bình trên máy tính xách tay của tôi. Đây là máy có bộ xử lý Intel i7 740QM chạy ở tốc độ 1,73 GHz với Turbo bị tắt (để nhất quán).
OFFSET Trung bình được nhóm theo nhóm
Bài báo thứ hai của Aaron đã kiểm tra hiệu suất của việc tính giá trị trung bình cho mỗi nhóm, sử dụng bảng Bán hàng một triệu hàng với mười nghìn mục nhập cho mỗi một trăm người bán hàng:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
Một lần nữa, giải pháp hoạt động tốt nhất sử dụng OFFSET :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK)
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Phần quan trọng của kế hoạch thực hiện được trình bày dưới đây:

Hàng trên cùng của kế hoạch liên quan đến việc tìm số hàng trong nhóm cho mỗi người bán hàng. Hàng dưới sử dụng các phần tử kế hoạch giống nhau được thấy cho giải pháp trung bình của một nhóm để tính giá trị trung bình cho từng người bán hàng. Khi chạy với bộ nhớ cache ấm và các kế hoạch thực thi bị tắt, truy vấn này sẽ thực thi trong 320 mili giây trung bình trên máy tính xách tay của tôi.
Sử dụng con trỏ động
Có vẻ điên rồ khi nghĩ đến việc sử dụng con trỏ để tính giá trị trung bình. Con trỏ SQL giao dịch có một danh tiếng (hầu hết là xứng đáng) là chậm và kém hiệu quả. Người ta cũng thường cho rằng con trỏ động là loại con trỏ tồi nhất. Những điểm này có giá trị trong một số trường hợp, nhưng không phải lúc nào cũng có hiệu lực.
Các con trỏ SQL giao dịch được giới hạn trong việc xử lý một hàng tại một thời điểm, vì vậy chúng thực sự có thể chậm nếu nhiều hàng cần được tìm nạp và xử lý. Tuy nhiên, đó không phải là trường hợp của phép tính trung bình:tất cả những gì chúng ta cần làm là xác định vị trí và tìm nạp một hoặc hai giá trị giữa một cách hiệu quả . Con trỏ động rất thích hợp cho tác vụ này như chúng ta sẽ thấy.
Con trỏ động trung bình đơn
Giải pháp con trỏ động cho một phép tính trung vị bao gồm các bước sau:
- Tạo một con trỏ động có thể cuộn qua danh sách các mục đã được sắp xếp.
- Tính vị trí của hàng trung vị đầu tiên.
- Đặt lại vị trí con trỏ bằng cách sử dụng
FETCH RELATIVE. - Quyết định xem có cần hàng thứ hai để tính giá trị trung bình hay không.
- Nếu không, hãy trả về giá trị trung bình duy nhất ngay lập tức.
- Nếu không, hãy tìm nạp giá trị thứ hai bằng cách sử dụng
FETCH NEXT. - Tính giá trị trung bình của hai giá trị và trả về.
Lưu ý rằng danh sách đó phản ánh đúng thủ tục đơn giản để tìm giá trị trung bình được đưa ra ở đầu bài viết này như thế nào. Việc triển khai mã Transact SQL hoàn chỉnh được hiển thị bên dưới:
-- Dynamic cursor
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE
@RowCount bigint, -- Total row count
@Row bigint, -- Median row number
@Amount1 integer, -- First amount
@Amount2 integer, -- Second amount
@Median float; -- Calculated median
SET @RowCount = 10000000;
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
DECLARE Median CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
O.val
FROM dbo.obj AS O
ORDER BY
O.val;
OPEN Median;
-- Calculate the position of the first median row
SET @Row = (@RowCount + 1) / 2;
-- Move to the row
FETCH RELATIVE @Row
FROM Median
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value we have
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Median
INTO @Amount2;
-- Calculate the median value from the two values
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
SELECT Median = @Median;
SELECT DynamicCur = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
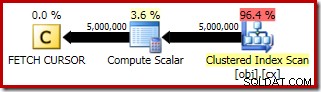
Kế hoạch thực thi cho FETCH RELATIVE câu lệnh hiển thị con trỏ động định vị lại một cách hiệu quả hàng đầu tiên cần thiết cho phép tính trung bình:
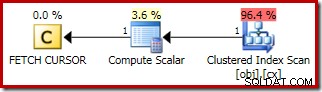
Kế hoạch cho FETCH NEXT (chỉ bắt buộc nếu có hàng giữa thứ hai, như trong các thử nghiệm này) là một hàng đơn lẻ được tìm nạp từ vị trí đã lưu của con trỏ:
Những lợi thế của việc sử dụng con trỏ động ở đây là:
- Nó tránh đi ngang qua toàn bộ tập hợp (việc đọc dừng lại sau khi tìm thấy các hàng ở giữa); và
- Không có bản sao dữ liệu tạm thời nào được tạo trong tempdb , như đối với con trỏ tĩnh hoặc bộ bàn phím.
Lưu ý rằng chúng tôi không thể chỉ định FAST_FORWARD con trỏ ở đây (để lại sự lựa chọn của một kế hoạch giống như tĩnh hoặc giống như động cho trình tối ưu hóa) vì con trỏ cần phải cuộn để hỗ trợ FETCH RELATIVE . Động vẫn là lựa chọn tối ưu ở đây.
Khi chạy với bộ nhớ cache ấm và bộ sưu tập kế hoạch thực thi bị tắt, truy vấn này chạy trong 930 mili giây trung bình trên máy thử nghiệm của tôi. Điều này chậm hơn một chút so với 910 mili giây cho OFFSET giải pháp, nhưng con trỏ động nhanh hơn đáng kể so với các phương pháp khác mà Aaron và Rob đã thử nghiệm và nó không yêu cầu SQL Server 2012 (hoặc mới hơn).
Tôi sẽ không lặp lại thử nghiệm các phương pháp khác trước năm 2012 ở đây, nhưng để làm ví dụ về kích thước của khoảng cách hiệu suất, giải pháp đánh số hàng sau mất 1550 mili giây trung bình (chậm hơn 70%):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK)
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT RowNumber = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());

Kiểm tra con trỏ động trung bình được nhóm
Thật đơn giản để mở rộng giải pháp con trỏ động trung bình duy nhất để tính toán các phương tiện được nhóm lại. Vì lợi ích của sự nhất quán, tôi sẽ sử dụng các con trỏ lồng nhau (vâng, thực sự):
- Mở con trỏ tĩnh trên những người bán hàng và số lượng hàng.
- Mỗi lần tính toán giá trị trung bình cho mỗi người bằng cách sử dụng một con trỏ động mới.
- Lưu từng kết quả vào một biến bảng khi chúng ta tiếp tục.
Đoạn mã được hiển thị bên dưới:
-- Timing
DECLARE @s datetime2 = SYSUTCDATETIME();
-- Holds results
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
-- Variables
DECLARE
@SalesPerson integer, -- Current sales person
@RowCount bigint, -- Current row count
@Row bigint, -- Median row number
@Amount1 float, -- First amount
@Amount2 float, -- Second amount
@Median float; -- Calculated median
-- Row counts per sales person
DECLARE SalesPersonCounts
CURSOR
LOCAL
FORWARD_ONLY
STATIC
READ_ONLY
FOR
SELECT
SalesPerson,
COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
ORDER BY SalesPerson;
OPEN SalesPersonCounts;
-- First person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Records for the current person
-- Note dynamic cursor
DECLARE Person CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
S.Amount
FROM dbo.Sales AS S
WHERE
S.SalesPerson = @SalesPerson
ORDER BY
S.Amount;
OPEN Person;
-- Calculate median row 1
SET @Row = (@RowCount + 1) / 2;
-- Move to median row 1
FETCH RELATIVE @Row
FROM Person
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Person
INTO @Amount2;
-- Calculate the median value
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
-- Add the result row
INSERT @Result (SalesPerson, Median)
VALUES (@SalesPerson, @Median);
-- Finished with the person cursor
CLOSE Person;
DEALLOCATE Person;
-- Next person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
END;
---- Results
--SELECT
-- R.SalesPerson,
-- R.Median
--FROM @Result AS R;
-- Tidy up
CLOSE SalesPersonCounts;
DEALLOCATE SalesPersonCounts;
-- Show elapsed time
SELECT NestedCur = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Con trỏ bên ngoài cố tình tĩnh vì tất cả các hàng trong tập hợp đó sẽ được chạm vào (ngoài ra, con trỏ động không khả dụng do hoạt động nhóm trong truy vấn bên dưới). Không có gì đặc biệt mới hoặc thú vị để xem trong các kế hoạch thực hiện vào khoảng thời gian này.
Điều thú vị là màn trình diễn. Mặc dù lặp đi lặp lại việc tạo và định vị con trỏ động bên trong, giải pháp này hoạt động thực sự tốt trên tập dữ liệu thử nghiệm. Khi tắt bộ nhớ đệm ấm và các kế hoạch thực thi, tập lệnh con trỏ sẽ hoàn thành sau 330 mili giây trung bình trên máy thử nghiệm của tôi. Điều này lại chậm hơn một chút so với 320 mili giây được ghi lại bởi OFFSET nhóm trung bình, nhưng Nó đánh bại các giải pháp tiêu chuẩn khác được liệt kê trong các bài báo của Aaron và Rob bởi một biên độ lớn.
Một lần nữa, như một ví dụ về khoảng cách hiệu suất so với các phương pháp không phải của năm 2012, giải pháp đánh số hàng sau chạy trong 485 mili giây trung bình trên giàn thử nghiệm của tôi (kém hơn 50%):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median numeric(38, 6) NOT NULL
);
INSERT @Result
SELECT
S.SalesPerson,
CA.Median
FROM
(
SELECT
SalesPerson,
NumRows = COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
) AS S
CROSS APPLY
(
SELECT AVG(1.0 * SQ1.Amount) FROM
(
SELECT
S2.Amount,
rn = ROW_NUMBER() OVER (
ORDER BY S2.Amount)
FROM dbo.Sales AS S2 WITH (PAGLOCK)
WHERE
S2.SalesPerson = S.SalesPerson
) AS SQ1
WHERE
SQ1.rn BETWEEN (S.NumRows + 1)/2 AND (S.NumRows + 2)/2
) AS CA (Median);
SELECT RowNumber = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());

Tóm tắt kết quả
Trong thử nghiệm trung vị duy nhất, con trỏ động đã chạy trong 930 mili giây so với 910 mili giây cho OFFSET .
Trong thử nghiệm trung vị được nhóm, con trỏ lồng nhau chạy trong 330 mili giây so với 320 mili giây cho OFFSET .
Trong cả hai trường hợp, phương thức con trỏ nhanh hơn đáng kể so với phương thức không phải OFFSET khác các phương pháp. Nếu bạn cần tính toán giá trị trung bình của một nhóm hoặc đơn lẻ trên phiên bản trước năm 2012, con trỏ động hoặc con trỏ lồng nhau thực sự có thể là lựa chọn tối ưu.
Hiệu suất cache lạnh
Một số bạn có thể thắc mắc về hiệu suất bộ đệm lạnh. Chạy phần sau trước mỗi bài kiểm tra:
CHECKPOINT; DBCC DROPCLEANBUFFERS;
Đây là các kết quả cho thử nghiệm trung vị duy nhất:
OFFSET phương pháp: 940 mili giây
Con trỏ động: 955 mili giây
Đối với trung vị được nhóm lại:
OFFSET phương pháp: 380 mili giây
Con trỏ lồng nhau: 385 mili giây
Lời kết
Các giải pháp con trỏ động thực sự nhanh hơn đáng kể so với các giải pháp không phải OFFSET phương pháp cho cả phương tiện đơn và phương tiện nhóm, ít nhất là với các tập dữ liệu mẫu này. Tôi đã cố tình chọn sử dụng lại dữ liệu thử nghiệm của Aaron để các tập dữ liệu không bị lệch về phía con trỏ động một cách cố ý. Có có thể là các bản phân phối dữ liệu khác mà con trỏ động không phải là một lựa chọn tốt. Tuy nhiên, nó cho thấy rằng vẫn có những lúc con trỏ có thể là một giải pháp nhanh chóng và hiệu quả cho đúng loại vấn đề. Ngay cả con trỏ động và con trỏ lồng nhau.
Người đọc có đôi mắt đại bàng có thể đã nhận thấy PAGLOCK gợi ý trong OFFSET kiểm tra trung vị nhóm. Điều này là cần thiết để có hiệu suất tốt nhất, vì những lý do tôi sẽ đề cập trong bài viết tiếp theo của mình. Nếu không có nó, giải pháp 2012 thực sự thua con trỏ lồng nhau một lề khá tốt ( 590ms so với 330ms ).