Bài viết này sử dụng một truy vấn đơn giản để khám phá một số nội dung sâu liên quan đến các truy vấn cập nhật.
Dữ liệu mẫu và cấu hình
Tập lệnh tạo dữ liệu mẫu bên dưới yêu cầu một bảng số. Nếu bạn chưa có một trong những tập lệnh này, bạn có thể sử dụng tập lệnh dưới đây để tạo một tập lệnh hiệu quả. Bảng số kết quả sẽ chứa một cột số nguyên duy nhất với các số từ một đến một triệu:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Tập lệnh bên dưới tạo một bảng dữ liệu mẫu được phân nhóm với 10.000 ID, với khoảng 100 ngày bắt đầu khác nhau cho mỗi ID. Cột ngày kết thúc ban đầu được đặt thành giá trị cố định '99991231'.
CREATE TABLE dbo.Example
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
EndDate date NOT NULL
);
GO
INSERT dbo.Example WITH (TABLOCKX)
(SomeID, StartDate, EndDate)
SELECT DISTINCT
1 + (N.n % 10000),
DATEADD(DAY, 50000 * RAND(CHECKSUM(NEWID())), '20010101'),
CONVERT(date, '99991231', 112)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX
CX_Example_SomeID_StartDate
ON dbo.Example
(SomeID, StartDate)
WITH (MAXDOP = 1, SORT_IN_TEMPDB = ON); Mặc dù các điểm được đưa ra trong bài viết này áp dụng khá chung cho tất cả các phiên bản SQL Server hiện tại, nhưng thông tin cấu hình bên dưới có thể được sử dụng để đảm bảo bạn thấy các kế hoạch thực thi và hiệu suất tương tự:
- SQL Server 2012 Gói Dịch vụ 3 Phiên bản dành cho nhà phát triển x64
- Bộ nhớ máy chủ tối đa được đặt thành 2048 MB
- Bốn bộ xử lý logic có sẵn cho phiên bản
- Không có cờ theo dõi nào được bật
- Mức cách ly được cam kết đọc mặc định
- Các tùy chọn cơ sở dữ liệu RCSI và SI bị vô hiệu hóa
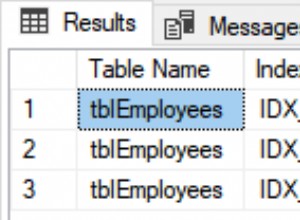
Tràn tổng hợp băm
Nếu bạn chạy tập lệnh tạo dữ liệu ở trên với các kế hoạch thực thi thực tế được bật, tổng hợp băm có thể tràn sang tempdb, tạo ra biểu tượng cảnh báo:

Khi được thực thi trên SQL Server 2012 Gói Dịch vụ 3, thông tin bổ sung về sự cố tràn được hiển thị trong chú giải công cụ:
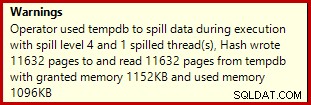
Sự thay đổi này có thể gây ngạc nhiên vì các ước tính hàng đầu vào cho Kết hợp băm là chính xác:
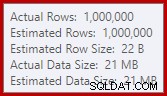
Chúng tôi đã quen với việc so sánh các ước tính trên đầu vào để sắp xếp và tham gia băm (chỉ đầu vào xây dựng), nhưng tổng hợp băm mong muốn thì khác. Tổng hợp băm hoạt động bằng cách tích lũy các hàng kết quả được nhóm trong bảng băm, vì vậy nó là số đầu ra hàng quan trọng:
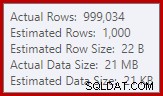
Công cụ ước tính cardinality trong SQL Server 2012 đưa ra một dự đoán khá kém về số lượng các giá trị khác biệt được mong đợi (1.000 so với thực tế là 999.034); hệ quả là tổng hợp băm tràn đệ quy lên mức 4 trong thời gian chạy. Công cụ ước tính bản số 'mới' có sẵn trong SQL Server 2014 trở đi sẽ tạo ra ước tính chính xác hơn cho đầu ra băm trong truy vấn này, vì vậy bạn sẽ không thấy tràn băm trong trường hợp đó:

Số lượng Hàng thực tế có thể hơi khác đối với bạn, với việc sử dụng trình tạo số giả ngẫu nhiên trong tập lệnh. Điểm quan trọng là tràn Tổng hợp băm phụ thuộc vào số lượng giá trị duy nhất đầu ra, không phụ thuộc vào kích thước đầu vào.
Đặc điểm cập nhật
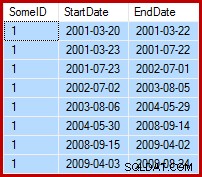
Nhiệm vụ trước mắt là cập nhật dữ liệu mẫu sao cho ngày kết thúc được đặt thành ngày trước ngày bắt đầu sau (theo SomeID). Ví dụ:một vài hàng đầu tiên của dữ liệu mẫu có thể trông giống như thế này trước khi cập nhật (tất cả các ngày kết thúc được đặt thành 9999-12-31):

Sau đó, như thế này sau khi cập nhật:
1. Truy vấn cập nhật đường cơ sở
Một cách tự nhiên hợp lý để thể hiện bản cập nhật được yêu cầu trong T-SQL như sau:
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate =
ISNULL
(
(
SELECT TOP (1)
DATEADD(DAY, -1, E2.StartDate)
FROM dbo.Example AS E2 WITH (TABLOCK)
WHERE
E2.SomeID = dbo.Example.SomeID
AND E2.StartDate > dbo.Example.StartDate
ORDER BY
E2.StartDate ASC
),
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Kế hoạch thực hiện sau khi thực hiện (thực tế) là:
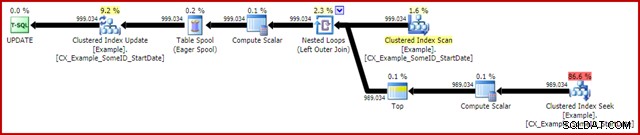
Tính năng đáng chú ý nhất là việc sử dụng Eager Table Spool để cung cấp Bảo vệ Halloween. Điều này là cần thiết để hoạt động chính xác ở đây do sự tự nối của bảng mục tiêu cập nhật. Hiệu quả là mọi thứ ở bên phải của cuộn được chạy đến khi hoàn thành, lưu trữ tất cả thông tin cần thiết để thực hiện các thay đổi trong bảng làm việc tempdb. Sau khi hoàn tất thao tác đọc, nội dung của bảng công việc sẽ được phát lại để áp dụng các thay đổi tại trình lặp Cập nhật chỉ mục theo cụm.
Hiệu suất
Để tập trung vào tiềm năng hiệu suất tối đa của kế hoạch thực thi này, chúng tôi có thể chạy cùng một truy vấn cập nhật nhiều lần. Rõ ràng, chỉ lần chạy đầu tiên sẽ dẫn đến bất kỳ thay đổi nào đối với dữ liệu, nhưng điều này hóa ra chỉ là một cân nhắc nhỏ. Nếu điều này làm phiền bạn, vui lòng đặt lại cột ngày kết thúc trước mỗi lần chạy bằng cách sử dụng mã sau. Những điểm rộng mà tôi sẽ đưa ra không phụ thuộc vào số lượng thay đổi dữ liệu thực sự được thực hiện.
UPDATE dbo.Example WITH (TABLOCKX) SET EndDate = CONVERT(date, '99991231', 112);
Khi bộ sưu tập kế hoạch thực thi bị tắt, tất cả các trang được yêu cầu trong vùng đệm và không đặt lại giá trị ngày kết thúc giữa các lần chạy, truy vấn này thường thực thi trong khoảng 5700ms trên máy tính xách tay của tôi. Đầu ra IO thống kê như sau:(đọc trước lần đọc và bộ đếm LOB bằng 0 và bị bỏ qua vì lý do khoảng trống)
Table 'Example'. Scan count 999035, logical reads 6186219, physical reads 0 Table 'Worktable'. Scan count 1, logical reads 2895875, physical reads 0
Số lần quét thể hiện số lần một hoạt động quét được bắt đầu. Đối với bảng Ví dụ, đây là 1 cho Quét chỉ mục theo cụm và 999,034 cho mỗi lần Tìm kiếm chỉ mục theo cụm tương quan được phục hồi. Bàn làm việc được Eager Spool sử dụng chỉ bắt đầu thao tác quét một lần.
Đọc logic
Thông tin thú vị hơn trong đầu ra IO là số lần đọc logic:hơn 6 triệu cho bảng Ví dụ và gần 3 triệu cho bàn làm việc.
Các lần đọc lôgic của bảng Ví dụ chủ yếu được liên kết với Tìm kiếm và Cập nhật. Seek phải chịu 3 lần đọc logic cho mỗi lần lặp:mỗi lần đọc cho các cấp gốc, trung gian và lá của chỉ mục. Tương tự, bản cập nhật có giá 3 lần đọc mỗi lần hàng được cập nhật, khi công cụ điều hướng xuống cây b để xác định vị trí hàng mục tiêu. Quét chỉ mục theo cụm chỉ chịu trách nhiệm cho một vài nghìn lần đọc, một lần trên mỗi trang đọc.
Bảng làm việc Spool cũng được cấu trúc bên trong như một cây b và đếm nhiều lần đọc khi ống định vị vị trí chèn trong khi sử dụng đầu vào của nó. Có lẽ phản trực giác, ống chỉ không đếm số lần đọc hợp lý trong khi nó đang được đọc để thúc đẩy Cập nhật chỉ mục theo cụm. Đây chỉ đơn giản là hệ quả của việc triển khai:một lượt đọc logic được tính bất cứ khi nào mã thực thi BPool ::Get phương pháp. Việc ghi vào ống chỉ gọi phương thức này ở mỗi cấp của chỉ mục; đọc từ cuộn theo một đường dẫn mã khác không gọi BPool ::Get ở tất cả.
Cũng lưu ý rằng đầu ra IO thống kê báo cáo một tổng số duy nhất cho bảng Ví dụ, mặc dù thực tế nó được truy cập bởi ba trình vòng lặp khác nhau trong kế hoạch thực thi (Quét, Tìm kiếm và Cập nhật). Thực tế thứ hai này làm cho khó có thể tương quan các lần đọc logic với trình lặp đã gây ra chúng. Tôi hy vọng hạn chế này được giải quyết trong phiên bản tương lai của sản phẩm.
2. Cập nhật bằng cách sử dụng Số hàng
Một cách khác để thể hiện truy vấn cập nhật liên quan đến việc đánh số các hàng cho mỗi ID và kết hợp:
WITH Numbered AS
(
SELECT
E.SomeID,
E.StartDate,
E.EndDate,
rn = ROW_NUMBER() OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate ASC)
FROM dbo.Example AS E
)
UPDATE This WITH (TABLOCKX)
SET EndDate =
ISNULL
(
DATEADD(DAY, -1, NextRow.StartDate),
CONVERT(date, '99991231', 112)
)
FROM Numbered AS This
LEFT JOIN Numbered AS NextRow WITH (TABLOCK)
ON NextRow.SomeID = This.SomeID
AND NextRow.rn = This.rn + 1
OPTION (MAXDOP 1, MERGE JOIN); Kế hoạch sau khi thực hiện như sau:
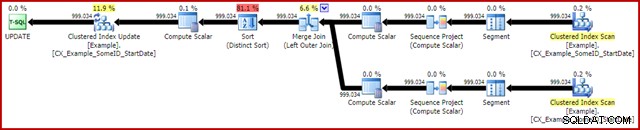
Truy vấn này thường chạy trong 2950ms trên máy tính xách tay của tôi, so sánh thuận lợi với 5700ms (trong cùng trường hợp) được thấy cho tuyên bố cập nhật ban đầu. Đầu ra IO thống kê là:
Table 'Example'. Scan count 2, logical reads 3001808, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Điều này cho thấy hai lần quét được bắt đầu cho bảng Ví dụ (một lần cho mỗi trình lặp Quét Chỉ mục Cụm). Các lần đọc logic một lần nữa là tổng hợp của tất cả các trình vòng lặp truy cập vào bảng này trong kế hoạch truy vấn. Như trước đây, việc thiếu phân tích khiến không thể xác định trình vòng lặp nào (trong số hai chế độ Quét và Cập nhật) chịu trách nhiệm cho 3 triệu lượt đọc.
Tuy nhiên, tôi có thể nói với bạn rằng Số lần quét chỉ mục theo cụm chỉ đếm vài nghìn lần đọc logic mỗi lần. Phần lớn các lần đọc lôgic là do Cập nhật chỉ mục theo cụm điều hướng xuống cây b chỉ mục để tìm vị trí cập nhật cho mỗi hàng mà nó xử lý. Bạn sẽ phải nghe lời tôi cho nó vào lúc này; sẽ có thêm lời giải thích trong thời gian ngắn.
Nhược điểm
Đó là phần cuối của tin tốt cho dạng truy vấn này. Nó hoạt động tốt hơn nhiều so với bản gốc, nhưng nó kém khả quan hơn nhiều vì một số lý do khác. Vấn đề chính là do giới hạn của trình tối ưu hóa gây ra, có nghĩa là nó không nhận ra rằng thao tác đánh số hàng tạo ra một số duy nhất cho mỗi hàng trong phân vùng SomeID.
Thực tế đơn giản này dẫn đến một số hệ quả không mong muốn. Đối với một điều, liên kết hợp nhất được định cấu hình để chạy ở chế độ kết hợp nhiều-nhiều. Đây là lý do cho bảng công việc (không sử dụng) trong IO thống kê (hợp nhất nhiều thành nhiều yêu cầu một bảng làm việc cho các tua lại khóa tham gia trùng lặp). Việc mong đợi một phép nối nhiều-nhiều cũng có nghĩa là ước tính bản số cho đầu ra phép nối là sai một cách vô vọng:
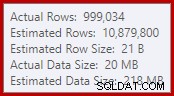
Do đó, Sort yêu cầu cấp quá nhiều bộ nhớ. Các thuộc tính của nút gốc cho thấy Sắp xếp sẽ thích 812,752 KB bộ nhớ, mặc dù nó chỉ được cấp 379,440 KB do cài đặt bộ nhớ máy chủ tối đa bị hạn chế (2048 MB). Loại thực sự đã sử dụng tối đa 58,968 KB trong thời gian chạy:
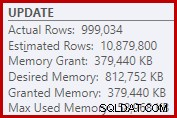
Việc cấp bộ nhớ quá mức sẽ đánh cắp bộ nhớ khỏi các mục đích sử dụng hiệu quả khác và có thể dẫn đến các truy vấn phải đợi cho đến khi bộ nhớ khả dụng. Theo nhiều khía cạnh, việc cấp bộ nhớ quá mức có thể gây ra nhiều vấn đề hơn là đánh giá thấp.
Giới hạn của trình tối ưu hóa cũng giải thích lý do tại sao gợi ý kết hợp hợp nhất lại cần thiết trên truy vấn để có hiệu suất tốt nhất. Nếu không có gợi ý này, trình tối ưu hóa đánh giá không chính xác rằng một phép nối băm sẽ rẻ hơn phép nối nhiều-nhiều. Kế hoạch tham gia băm chạy trung bình trong 3350 mili giây.
Như một hệ quả tiêu cực cuối cùng, hãy lưu ý rằng Sắp xếp trong kế hoạch là Sắp xếp Riêng biệt. Bây giờ, có một số lý do cho việc Sắp xếp đó (đặc biệt là vì nó có thể cung cấp Bảo vệ Halloween cần thiết) nhưng nó chỉ là một Khác biệt Sắp xếp vì trình tối ưu hóa bỏ sót thông tin về tính duy nhất. Nhìn chung, khó có thể thích nhiều về kế hoạch thực thi này ngoài hiệu suất.
3. Cập nhật bằng cách sử dụng Hàm phân tích LEAD
Vì bài viết này chủ yếu nhắm mục tiêu SQL Server 2012 trở lên, chúng tôi có thể thể hiện truy vấn cập nhật khá tự nhiên bằng cách sử dụng hàm phân tích LEAD. Trong một thế giới lý tưởng, chúng ta có thể sử dụng một cú pháp rất nhỏ gọn như:
-- Not allowed
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate = LEAD(StartDate) OVER (
PARTITION BY SomeID ORDER BY StartDate); Thật không may, điều này không hợp pháp. Nó dẫn đến thông báo lỗi 4108, "Các hàm cửa sổ chỉ có thể xuất hiện trong mệnh đề SELECT hoặc ORDER BY". Điều này hơi bực bội vì chúng tôi đã hy vọng vào một kế hoạch thực thi có thể tránh tự tham gia (và bản cập nhật liên quan Halloween Protection).
Tin tốt là chúng ta vẫn có thể tránh tự nối bằng Biểu thức bảng chung hoặc bảng dẫn xuất. Cú pháp dài dòng hơn một chút, nhưng ý tưởng thì khá giống nhau:
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Kế hoạch sau khi thực hiện là:

Điều này thường chạy trong khoảng 3400 mili giây trên máy tính xách tay của tôi, chậm hơn so với giải pháp số hàng (2950ms) nhưng vẫn nhanh hơn nhiều so với giải pháp ban đầu (5700ms). Một điều nổi bật so với kế hoạch thực hiện là sắp xếp tràn (một lần nữa, thông tin tràn bổ sung nhờ những cải tiến trong SP3):
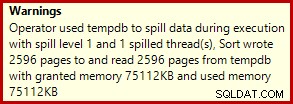
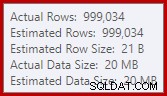
Đây là một sự cố tràn khá nhỏ, nhưng nó vẫn có thể ảnh hưởng đến hiệu suất ở một mức độ nào đó. Điều kỳ lạ là ước tính đầu vào cho Sắp xếp lại chính xác:
May mắn thay, có một "bản sửa lỗi" cho điều kiện cụ thể này trong SQL Server 2012 SP2 CU8 (và các bản phát hành khác - xem bài viết KB để biết chi tiết). Chạy truy vấn với cờ theo dõi sửa chữa và bắt buộc 7470 được bật có nghĩa là Sắp xếp yêu cầu đủ bộ nhớ để đảm bảo nó sẽ không bao giờ tràn ra đĩa nếu kích thước sắp xếp đầu vào ước tính không bị vượt quá.
LEAD Cập nhật truy vấn mà không cần sắp xếp tràn
Đối với nhiều loại, truy vấn hỗ trợ sửa lỗi bên dưới sử dụng cú pháp bảng dẫn xuất thay vì CTE:
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate, CONVERT(date, '99991231', 112)
)
FROM
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
) AS CED
OPTION (MAXDOP 1, QUERYTRACEON 7470); Kế hoạch sau khi thực hiện mới là:

Loại bỏ sự cố tràn nhỏ giúp cải thiện hiệu suất từ 3400ms lên 3250ms . Đầu ra IO thống kê là:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Nếu bạn so sánh điều này với số lần đọc logic cho truy vấn được đánh số hàng, bạn sẽ thấy rằng số lần đọc logic đã giảm từ 3,001,808 xuống 2,999.455 - chênh lệch 2,353 lần đọc. Điều này tương ứng chính xác với việc loại bỏ một bản quét chỉ mục theo cụm duy nhất (một lần đọc trên mỗi trang).
Bạn có thể nhớ rằng tôi đã đề cập rằng phần lớn số lần đọc logic cho các truy vấn cập nhật này được liên kết với Cập nhật chỉ mục theo cụm và các lần quét được liên kết với "chỉ vài nghìn lần đọc". Bây giờ chúng ta có thể thấy điều này trực tiếp hơn một chút bằng cách chạy một truy vấn đếm hàng đơn giản dựa trên bảng Ví dụ:
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.Example WITH (TABLOCK); SET STATISTICS IO OFF;
Đầu ra IO hiển thị chính xác chênh lệch đọc lôgic 2.353 giữa số hàng và cập nhật khách hàng tiềm năng:
Table 'Example'. Scan count 1, logical reads 2353, physical reads 0
Cải tiến hơn nữa?
Truy vấn khách hàng tiềm năng cố định tràn (3250ms) vẫn chậm hơn một chút so với truy vấn đánh số hàng kép (2950ms), điều này có thể hơi ngạc nhiên. Theo trực giác, người ta có thể mong đợi một chức năng quét và phân tích đơn lẻ (Window Spool và Stream Aggregate) sẽ nhanh hơn hai lần quét, hai bộ đánh số hàng và một phép nối.
Bất kể điều gì vượt ra khỏi kế hoạch thực thi truy vấn chính là Sắp xếp. Nó cũng xuất hiện trong truy vấn đánh số hàng, nơi nó đóng góp Bảo vệ Halloween cũng như một thứ tự sắp xếp được tối ưu hóa cho Bản cập nhật chỉ mục theo cụm (có bộ thuộc tính DMLRequestSort).
Vấn đề là, Sắp xếp này hoàn toàn không cần thiết trong kế hoạch truy vấn khách hàng tiềm năng. Nó không cần thiết cho Bảo vệ Halloween vì tự tham gia đã hết. Nó cũng không cần thiết cho thứ tự sắp xếp chèn được tối ưu hóa:các hàng đang được đọc theo thứ tự Khóa cụm và không có gì trong kế hoạch làm xáo trộn thứ tự đó. Vấn đề thực sự có thể được nhìn thấy bằng cách xem các thuộc tính Sắp xếp:

Để ý phần Order By ở đó. Sắp xếp được sắp xếp theo SomeID và StartDate (các khóa chỉ mục được phân cụm) nhưng cũng theo [Uniq1002], là trình thống nhất. Đây là hậu quả của việc không khai báo chỉ mục được phân cụm là duy nhất, mặc dù chúng tôi đã thực hiện các bước trong truy vấn tổng hợp dữ liệu để đảm bảo rằng sự kết hợp của SomeID và StartDate trên thực tế sẽ là duy nhất. (Đây là sự cố ý, vì vậy tôi có thể nói về điều này.)
Mặc dù vậy, đây là một hạn chế. Các hàng được đọc từ Chỉ mục được phân nhóm theo thứ tự và tồn tại các đảm bảo nội bộ cần thiết để trình tối ưu hóa có thể tránh Sắp xếp này một cách an toàn. Nó chỉ đơn giản là một sự giám sát mà trình tối ưu hóa không nhận ra rằng luồng đến được sắp xếp theo trình thống nhất cũng như theo SomeID và StartDate. Nó nhận ra rằng thứ tự (SomeID, StartDate) có thể được giữ nguyên, nhưng không (SomeID, StartDate, uniquifier). Một lần nữa, tôi hy vọng vấn đề này sẽ được giải quyết trong một phiên bản trong tương lai.
Để giải quyết vấn đề này, chúng ta có thể làm những gì đáng lẽ phải làm ngay từ đầu:xây dựng chỉ mục được phân nhóm là duy nhất:
CREATE UNIQUE CLUSTERED INDEX CX_Example_SomeID_StartDate ON dbo.Example (SomeID, StartDate) WITH (DROP_EXISTING = ON, MAXDOP = 1);
Tôi sẽ để nó như một bài tập cho người đọc để chỉ ra rằng hai truy vấn đầu tiên (không phải là LEAD) không được hưởng lợi từ sự thay đổi lập chỉ mục này (bị bỏ qua hoàn toàn vì lý do không gian - còn rất nhiều điều cần phải giải quyết).
Biểu mẫu cuối cùng của Truy vấn cập nhật khách hàng tiềm năng
Với sự độc đáo chỉ mục nhóm tại chỗ, cùng một truy vấn LEAD (CTE hoặc bảng dẫn xuất tùy ý bạn) tạo ra kế hoạch ước tính (trước khi thực hiện) mà chúng tôi mong đợi:

Điều này có vẻ khá tối ưu. Một thao tác đọc và ghi đơn lẻ với tối thiểu các toán tử ở giữa. Chắc chắn, nó có vẻ tốt hơn nhiều so với phiên bản trước với Sắp xếp không cần thiết, thực thi trong 3250ms sau khi loại bỏ tràn có thể tránh được (với cái giá là tăng cấp bộ nhớ một chút).
Kế hoạch sau khi thực hiện (thực tế) gần giống hệt như kế hoạch trước khi thực hiện:

Tất cả các ước tính đều chính xác, ngoại trừ đầu ra của Window Spool, bị lệch 2 hàng. Thông tin IO thống kê hoàn toàn giống như trước khi Sắp xếp bị xóa, như bạn mong đợi:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Tóm lại ngắn gọn, sự khác biệt rõ ràng duy nhất giữa kế hoạch mới này và kế hoạch trước đó là Phân loại (với chi phí ước tính đóng góp gần 80%) đã bị loại bỏ.
Sau đó, có thể sẽ ngạc nhiên khi biết rằng truy vấn mới - không có Sắp xếp - thực thi trong 5000 mili giây . Điều này tồi tệ hơn nhiều so với 3250ms với Sắp xếp và gần bằng với truy vấn tham gia vòng lặp ban đầu 5700ms. Giải pháp đánh số hàng đôi vẫn đang dẫn đầu ở mức 2950 mili giây.
Giải thích
Lời giải thích hơi bí truyền và liên quan đến cách xử lý các chốt cho truy vấn mới nhất. Chúng tôi có thể cho thấy hiệu ứng này theo một số cách, nhưng đơn giản nhất có lẽ là xem xét thống kê chờ và chốt bằng DMV:
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1);
SELECT * FROM sys.dm_os_latch_stats AS DOLS
WHERE DOLS.waiting_requests_count > 0
ORDER BY DOLS.latch_class;
SELECT * FROM sys.dm_os_wait_stats AS DOWS
WHERE DOWS.waiting_tasks_count > 0
ORDER BY DOWS.waiting_tasks_count DESC; Khi chỉ mục được phân nhóm không phải là duy nhất và có Sắp xếp trong kế hoạch, không có thời gian chờ đáng kể nào, chỉ cần một vài PAGEIOLATCH_UP chờ và SOS_SCHEDULER_YIELDs dự kiến.
Khi chỉ mục được phân nhóm là duy nhất và Sắp xếp bị loại bỏ, các chờ đợi là:
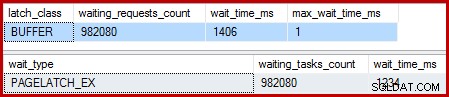
Có 982.080 chốt trang độc quyền ở đó, với thời gian chờ giải thích khá nhiều về thời gian thực thi bổ sung. Để nhấn mạnh, đó là gần như một lần chờ chốt cho mỗi hàng được cập nhật! Chúng tôi có thể mong đợi sự thay đổi chốt trên mỗi hàng, nhưng không phải chốt đợi , đặc biệt khi truy vấn kiểm tra là hoạt động duy nhất trên phiên bản. Thời gian chờ đợi chốt ngắn, nhưng có rất nhiều điều trong số đó.
Chốt lười
Sau khi thực hiện truy vấn với trình gỡ lỗi và trình phân tích được đính kèm, giải thích như sau.
Quét chỉ mục theo cụm sử dụng chốt lười - một tối ưu hóa có nghĩa là các chốt chỉ được phát hành khi một chủ đề khác yêu cầu quyền truy cập vào trang. Thông thường, chốt được nhả ngay sau khi đọc hoặc viết. Chốt lười tối ưu hóa trường hợp quét toàn bộ trang sẽ thu được và phát hành chốt trang giống nhau cho mọi hàng. Khi sử dụng chốt lười mà không có tranh cãi, chỉ một chốt duy nhất được thực hiện cho toàn bộ trang.
Vấn đề là bản chất pipelined của kế hoạch thực thi (không có toán tử chặn) có nghĩa là đọc trùng lặp với ghi. Khi Cập nhật chỉ mục theo cụm cố gắng lấy chốt EX để sửa đổi một hàng, hầu như luôn luôn thấy rằng trang đã được chốt SH (chốt lười do Quét chỉ mục theo cụm lấy). Tình huống này dẫn đến việc chờ chốt.
Là một phần của việc chuẩn bị đợi và chuyển sang mục có thể chạy tiếp theo trên bộ lập lịch, mã cẩn thận phát hành bất kỳ chốt lười nào. Việc nhả chốt lười báo hiệu người phục vụ đủ điều kiện đầu tiên, đó là chính họ. Vì vậy, chúng ta có một tình huống kỳ lạ khi một luồng tự khóa, nhả chốt lười biếng của nó, sau đó tự báo hiệu rằng nó có thể chạy lại được. Luồng bắt đầu trở lại và tiếp tục, nhưng chỉ sau khi tất cả các công việc tạm dừng và chuyển đổi lãng phí đó, tín hiệu và tiếp tục công việc đã được thực hiện. Như tôi đã nói trước đây, thời gian chờ đợi là ngắn, nhưng có rất nhiều.
Đối với tất cả những gì tôi biết, chuỗi sự kiện kỳ quặc này là do thiết kế và vì những lý do nội bộ chính đáng. Mặc dù vậy, không tránh khỏi thực tế rằng nó có ảnh hưởng khá lớn đến hiệu suất ở đây. Tôi sẽ thực hiện một số yêu cầu về điều này và cập nhật bài viết nếu có một tuyên bố công khai. Trong khi đó, quá nhiều thời gian chờ tự chốt có thể là điều cần chú ý đối với các truy vấn cập nhật liên tục, mặc dù không rõ nên làm gì với điều đó theo quan điểm của người viết truy vấn.
Điều này có nghĩa là phương pháp đánh số hàng kép là cách tốt nhất mà chúng tôi có thể làm cho truy vấn này? Không hoàn toàn.
4. Bảo vệ Halloween thủ công
Tùy chọn cuối cùng này có thể nghe có vẻ hơi điên rồ. Ý tưởng chung là viết tất cả thông tin cần thiết để thực hiện các thay đổi đối với biến bảng, sau đó thực hiện cập nhật như một bước riêng biệt.
Để có mô tả tốt hơn, tôi gọi đây là cách tiếp cận "HP thủ công" vì nó tương tự về mặt khái niệm với việc ghi tất cả thông tin thay đổi vào Bộ đệm bảng Eager (như đã thấy trong truy vấn đầu tiên) trước khi điều khiển Cập nhật từ Bộ đệm đó.
Dù sao, mã như sau:
DECLARE @U AS table
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
NewEndDate date NULL,
PRIMARY KEY CLUSTERED (SomeID, StartDate)
);
INSERT @U
(SomeID, StartDate, NewEndDate)
SELECT
E.SomeID,
E.StartDate,
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E WITH (TABLOCK)
OPTION (MAXDOP 1);
UPDATE E WITH (TABLOCKX)
SET E.EndDate =
ISNULL
(
U.NewEndDate, CONVERT(date, '99991231', 112)
)
FROM dbo.Example AS E
JOIN @U AS U
ON U.SomeID = E.SomeID
AND U.StartDate = E.StartDate
OPTION (MAXDOP 1, MERGE JOIN); Mã đó cố tình sử dụng một biến bảng để tránh chi phí thống kê được tạo tự động mà việc sử dụng bảng tạm thời sẽ phải chịu. Điều này là ổn ở đây vì tôi biết hình dạng kế hoạch mà tôi muốn và nó không phụ thuộc vào ước tính chi phí hoặc thông tin thống kê.
Nhược điểm duy nhất của biến bảng (không có cờ theo dõi) là trình tối ưu hóa thường ước tính một hàng và chọn các vòng lồng nhau cho bản cập nhật. Để ngăn chặn điều này, tôi đã sử dụng gợi ý kết hợp hợp nhất. Một lần nữa, điều này được thúc đẩy bằng cách biết chính xác hình dạng kế hoạch cần đạt được.
Kế hoạch sau khi thực thi cho chèn biến bảng trông giống hệt như truy vấn có vấn đề với chốt chờ:

Ưu điểm của kế hoạch này là nó không thay đổi cùng một bảng mà nó đang đọc. Không cần Bảo vệ Halloween và không có khả năng bị can thiệp vào chốt. Ngoài ra, có các tối ưu hóa nội bộ đáng kể cho các đối tượng tempdb (khóa và ghi nhật ký) và các tối ưu hóa tải hàng loạt bình thường khác cũng được áp dụng. Hãy nhớ rằng tối ưu hóa hàng loạt chỉ có sẵn cho các lần chèn, không phải cập nhật hoặc xóa.
Kế hoạch sau thực thi cho câu lệnh cập nhật là:
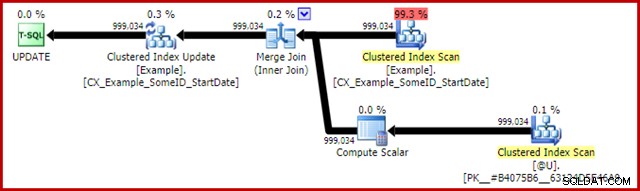
Hợp nhất Tham gia ở đây là kiểu một-nhiều hiệu quả. Hơn nữa, kế hoạch này đủ điều kiện cho một tối ưu hóa đặc biệt có nghĩa là Quét chỉ mục theo cụm và Cập nhật chỉ mục theo cụm chia sẻ cùng một bộ hàng. Hệ quả quan trọng là Bản cập nhật không còn phải xác định vị trí hàng để cập nhật - hàng đã được định vị chính xác bởi đọc. Điều này giúp tiết kiệm rất nhiều lượt đọc logic (và hoạt động khác) tại Bản cập nhật.
Không có gì trong các kế hoạch thực thi thông thường để hiển thị nơi áp dụng tối ưu hóa Tập hợp được chia sẻ này, nhưng việc bật cờ theo dõi không có tài liệu 8666 sẽ hiển thị các thuộc tính bổ sung trên Cập nhật và Quét cho thấy chia sẻ tập hợp hàng đang được sử dụng và các bước được thực hiện để đảm bảo cập nhật an toàn từ Vấn đề Halloween.
Đầu ra IO thống kê cho hai truy vấn như sau:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0 Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 (999034 row(s) affected) Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 Table '#B9C034B8'. Scan count 1, logical reads 2353, physical reads 0
Cả hai lần đọc bảng Ví dụ đều liên quan đến một lần quét và một lần đọc lôgic trên mỗi trang (xem truy vấn đếm hàng đơn giản trước đây). Bảng # B9C034B8 là tên của đối tượng tempdb bên trong hỗ trợ biến bảng. Tổng số lần đọc logic cho cả hai truy vấn là 3 * 2353 =7,059. Bảng làm việc là bộ nhớ trong bộ nhớ trong được Window Spool sử dụng.
Thời gian thực thi điển hình cho truy vấn này là 2300ms . Cuối cùng, chúng tôi có một thứ gì đó đánh bại truy vấn đánh số hàng kép (2950ms), ít có khả năng xảy ra.
Lời kết
Có thể có nhiều cách tốt hơn để viết bản cập nhật này hoạt động tốt hơn cả giải pháp "HP thủ công" ở trên. Kết quả hiệu suất thậm chí có thể khác nhau trên phần cứng và cấu hình SQL Server của bạn, nhưng cả hai đều không phải là điểm chính của bài viết này. Điều đó không có nghĩa là tôi không quan tâm đến việc xem các truy vấn tốt hơn hoặc so sánh hiệu suất - chính là tôi.
Vấn đề là có nhiều điều khủng khiếp đang diễn ra bên trong SQL Server hơn là được hiển thị trong các kế hoạch thực thi. Hy vọng rằng một số chi tiết được thảo luận trong bài viết khá dài này sẽ thú vị hoặc thậm chí hữu ích đối với một số người.
Thật tốt khi có những kỳ vọng về hiệu suất và biết những hình dạng và đặc tính của kế hoạch nói chung là có lợi. Loại kinh nghiệm và kiến thức đó sẽ phục vụ bạn tốt cho 99% hoặc nhiều hơn các truy vấn mà bạn sẽ được yêu cầu điều chỉnh. Tuy nhiên, đôi khi, tốt nhất là bạn nên thử điều gì đó kỳ lạ hoặc bất thường một chút chỉ để xem điều gì xảy ra và xác thực những kỳ vọng đó.