Với sự ra đời của Cơ sở dữ liệu Azure SQL và bổ sung nhiều chức năng hơn trong v12, các quản trị viên cơ sở dữ liệu bắt đầu thấy tổ chức của họ quan tâm hơn đến việc chuyển cơ sở dữ liệu sang nền tảng này.
Gần đây, tôi đã bắt đầu tìm hiểu sâu hơn về Cơ sở dữ liệu Azure SQL để xem có gì khác biệt đáng kể so với việc hỗ trợ phiên bản hộp trong các trung tâm dữ liệu trên toàn thế giới và Cơ sở dữ liệu Azure SQL. Trong bài viết trước của tôi, "Điều chỉnh:Một nơi tốt để bắt đầu," tôi đã trình bày cách tiếp cận của mình để bắt đầu điều chỉnh SQL Server. Tôi đã quyết định xem xét điều này so với Cơ sở dữ liệu Azure SQL để phát hiện ra những điểm khác biệt chính.
Trong bài viết gốc của tôi, tôi đã bắt đầu với các cài đặt cấp phiên bản chung mà tôi thấy bị bỏ qua hoặc để làm mặc định, cũng như các mục bảo trì. Chúng bao gồm bộ nhớ, maxdop, ngưỡng chi phí cho song song, cho phép tối ưu hóa cho khối lượng công việc đột xuất và định cấu hình tempdb. Với Cơ sở dữ liệu Azure SQL, bạn không chịu trách nhiệm về phiên bản và không thể sửa đổi các cài đặt đó. Cơ sở dữ liệu Azure SQL là Nền tảng dưới dạng Dịch vụ (PaaS), có nghĩa là Microsoft quản lý phiên bản cho bạn; bạn chỉ đơn giản là người thuê với cơ sở dữ liệu hoặc các cơ sở dữ liệu của bạn.
Tuy nhiên, bạn chịu trách nhiệm bảo trì, vì vậy bạn phải cập nhật số liệu thống kê và xử lý phân mảnh chỉ mục giống như bạn làm đối với sản phẩm hộp. Đối với các tác vụ đó, tôi nhận thấy rằng hầu hết các khách hàng quản lý các quy trình đó bằng Azure VM chuyên dụng chạy SQL Server và sử dụng SQL Server Agent với các công việc đã lên lịch.
Theo các bước từ bài viết của tôi, các lĩnh vực tiếp theo mà tôi bắt đầu xem xét là thống kê tệp và chờ và các truy vấn chi phí cao. Nếu bạn đang tự hỏi liệu khía cạnh này trong công việc của bạn với tư cách là một dba sản xuất với cơ sở dữ liệu tại chỗ có thay đổi khi làm việc với Cơ sở dữ liệu Azure SQL hay không, thì câu trả lời là không thực sự . Số liệu thống kê về hồ sơ và chờ đợi vẫn còn đó, nhưng chúng ta phải truy cập chúng theo một cách hơi khác. Nếu bạn đã quen sử dụng các tập lệnh của Paul Randal cho số liệu thống kê tệp và số liệu thống kê chờ (hoặc các truy vấn cho số liệu thống kê tệp trong một khoảng thời gian và số liệu thống kê chờ trong một khoảng thời gian), thì bạn sẽ phải thực hiện một số thay đổi để các tập lệnh đó để hoạt động với Cơ sở dữ liệu Azure SQL.
Khi tôi lần đầu tiên thử tập lệnh thống kê tệp của Paul, nó không thành công do Cơ sở dữ liệu Azure SQL không hỗ trợ sys.master_files :
Tên đối tượng 'sys.master_files' không hợp lệ.
Tôi có thể sửa đổi tập lệnh để sử dụng sys.databases trong phép nối để lấy tên cơ sở dữ liệu và xóa phần script để lấy các tên tệp riêng lẻ vì chúng ta sẽ chỉ xử lý một tệp nhật ký và dữ liệu duy nhất. Bạn có thể thấy những thay đổi tôi phải thực hiện trong hình ảnh sau:
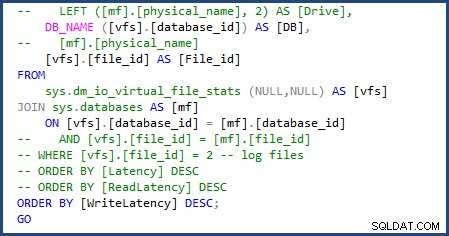
Khi tôi chạy tập lệnh thống kê tệp sau một khoảng thời gian, thực hiện thay đổi tương tự đối với sys.databases và xóa các tham chiếu đến file_id khi tham gia, nó không thành công do Cơ sở dữ liệu Azure SQL v12 không hỗ trợ bảng tạm thời ## chung.
Sau khi tôi thay đổi tất cả các bảng tạm thời ## toàn cục thành cục bộ, tôi đã gặp phải một vấn đề khác với tập lệnh không thể xóa các bảng tạm thời hiện có đã được sử dụng, vì các bảng #temp cục bộ không thể được tham chiếu trực tiếp bằng tên như cách các bảng tạm thời ## toàn cục có thể, nhưng điều này có thể dễ dàng khắc phục bằng cách thay đổi các kiểm tra như vậy thành OBJECT_ID('tempdb..#SQLskillsStats1') . Tôi đã thực hiện thay đổi tương tự cho bảng tạm thời thứ hai và cập nhật khối mã ở đầu và cuối tập lệnh.
Tôi phải thực hiện một thay đổi nữa và xóa [mf].[type_desc] và LEFT ([mf].[physical_name], 2) AS [Drive] vì chúng phụ thuộc vào sys.master_files . Sau đó, tập lệnh đã hoàn thành và sẵn sàng để sử dụng với Cơ sở dữ liệu Azure SQL.
Tôi thường xuyên sử dụng thống kê tệp theo chu kỳ khi khắc phục sự cố về hiệu suất. Dữ liệu tích lũy có mục đích của nó, nhưng tôi quan tâm nhiều hơn đến các phân đoạn thời gian cụ thể khi khối lượng công việc của người dùng đang được chạy.
Với thống kê tệp, chúng tôi quan tâm đến độ trễ của mỗi tệp cơ sở dữ liệu và cách chúng tôi có thể điều chỉnh để giúp giảm I / O tổng thể. Cách tiếp cận cũng giống như SQL Server, nơi bạn cần điều chỉnh các truy vấn của mình một cách hợp lý và có các chỉ mục chính xác. Nếu khối lượng công việc quá lớn, thì bạn phải chuyển sang tầng cơ sở dữ liệu DTU hoạt động nhanh hơn. Đối với tôi, điều này thật tuyệt:bạn chỉ cần ném phần cứng vào nó; nhưng nó không thực sự là phần cứng theo nghĩa truyền thống. Với Cơ sở dữ liệu Azure SQL, bạn sẽ bắt đầu với cấp và quy mô ít tốn kém hơn khi nhu cầu kinh doanh và I / O của bạn phát triển - về cơ bản chỉ bằng cách bật một công tắc.
Cố gắng tìm ra phương pháp tốt nhất để có được số liệu thống kê về thời gian chờ đã dễ dàng hơn. Tập lệnh chuẩn mà nhiều người trong chúng ta sử dụng vẫn hoạt động, tuy nhiên, nó đang kéo số liệu thống kê chờ cho vùng chứa mà cơ sở dữ liệu của bạn đang chạy. Những lần chờ đó vẫn áp dụng cho hệ thống của bạn, nhưng có thể bao gồm những lần chờ phát sinh bởi các cơ sở dữ liệu khác trong cùng một vùng chứa. Cơ sở dữ liệu Azure SQL chứa một DMV mới, sys.dm_db_wait_stats , bộ lọc đến cơ sở dữ liệu hiện tại. Nếu bạn giống tôi và chủ yếu sử dụng tập lệnh thống kê thời gian chờ của Paul bỏ qua tất cả các lần chờ đợi lành tính, chỉ cần thay đổi sys.dm_os_wait_stats tới sys.dm_db_wait_stats . Thay đổi tương tự cũng hoạt động đối với tập lệnh chờ-qua-một-thời-gian, nhưng bạn cũng phải thực hiện thay đổi từ các biến toàn cục thành cục bộ.
Khi nói đến việc tìm kiếm các truy vấn chi phí cao, một trong những tập lệnh yêu thích của tôi để chạy là tìm các kế hoạch thực thi được sử dụng nhiều nhất. Theo kinh nghiệm của tôi, việc điều chỉnh một truy vấn được gọi là 100.000 lần mỗi ngày thường là một chiến thắng lớn hơn so với việc điều chỉnh một truy vấn có IO cao nhất nhưng chỉ được chạy một lần mỗi tuần. Truy vấn sau là những gì tôi sử dụng để tìm các kế hoạch được sử dụng nhiều nhất:
CHỌN usecounts, cacheobjtype, objtype, [text] FROM sys.dm_exec_cached_plans CROSS ÁP DỤNG sys.dm_exec_sql_text (plan_handle) WHERE usecounts> 1 AND objtype IN (N'Adhoc ', N'Prepared') ORDER BY usecount trước>Khi sử dụng truy vấn này trong các bản trình diễn, tôi luôn xóa bộ nhớ cache kế hoạch của mình để đặt lại các giá trị. Khi tôi thử chạy
DBCC FREEPROCCACHEtrong Cơ sở dữ liệu Azure SQL, tôi đã gặp lỗi sau:Hóa ra là
SQL Azure hiện không hỗ trợ DBCC FREEPROCCACHE (Transact-SQL), vì vậy bạn không thể xóa thủ công kế hoạch thực thi khỏi bộ đệm. Tuy nhiên, nếu bạn thực hiện các thay đổi đối với bảng hoặc chế độ xem được tham chiếu bởi truy vấn (ALTER TABLE và ALTER VIEW), kế hoạch sẽ bị xóa khỏi bộ nhớ cache.DBCC FREEPROCCACHEkhông được hỗ trợ trong Cơ sở dữ liệu Azure SQL. Điều này gây rắc rối cho tôi, điều gì sẽ xảy ra nếu tôi đang trong quá trình sản xuất và có một số kế hoạch không tốt và muốn xóa bộ đệm thủ tục như tôi có thể làm với phiên bản hộp. Một chút nghiên cứu về Google / Bing giúp tôi tìm thấy bài viết của Microsoft, "Hiểu về bộ đệm thủ tục trên SQL Azure", trong đó nêu rõ:Khi thảo luận điều này với Kimberly Tripp sau khi không thấy hành vi được mô tả đó, nó không xóa kế hoạch khỏi bộ nhớ cache, nhưng nó làm mất hiệu lực của kế hoạch (và sau đó kế hoạch cuối cùng sẽ bị xóa khỏi bộ nhớ cache). Mặc dù điều này hữu ích trong một số tình huống nhất định, nhưng đây không phải là thứ tôi cần. Đối với bản demo của mình, tôi muốn đặt lại các bộ đếm trong sys.dm_exec_cached_plans. Tạo một kế hoạch mới sẽ không mang lại cho tôi kết quả mong muốn. Tôi đã liên hệ với nhóm của mình và Glenn Berry bảo tôi hãy thử tập lệnh sau:
AL SAU CƠ SỞ DỮ LIỆU ĐƯỢC PHỤC VỤ CẤU HÌNH RÕ RÀNG PROCEDURE_CACHE;Lệnh này đã hoạt động; Tôi đã có thể xóa bộ đệm thủ tục cho cơ sở dữ liệu cụ thể. Cấu hình phạm vi cơ sở dữ liệu là một tính năng mới được thêm vào SQL Server 2016 RC0; Glenn đã viết blog về nó tại đây:Sử dụng CẤU HÌNH CƠ SỞ DỮ LIỆU ALTER trong SQL Server 2016.
Tôi rất vui khi chuyển một số cơ sở dữ liệu của riêng mình sang Cơ sở dữ liệu Azure SQL và tiếp tục tìm hiểu về các tính năng mới và các tùy chọn khả năng mở rộng. Tôi cũng rất mong được làm việc với SentryOne DB Sentry, một phần bổ sung gần đây cho Nền tảng SentryOne. Tôi quan tâm nhất đến việc thử nghiệm trang tổng quan Sử dụng DTU mà Mike Wood đã mô tả trong bài đăng gần đây của anh ấy.