Nói chung, loại Sắp xếp tốt nhất là loại được tránh hoàn toàn. Với việc lập chỉ mục cẩn thận và đôi khi viết một số truy vấn sáng tạo, chúng ta thường có thể loại bỏ sự cần thiết của toán tử Sắp xếp khỏi các kế hoạch thực thi. Khi dữ liệu được sắp xếp lớn, việc tránh kiểu Sắp xếp này có thể tạo ra những cải thiện hiệu suất rất đáng kể.
Loại Sắp xếp tốt nhất thứ hai là loại mà chúng ta không thể tránh khỏi, nhưng là loại dự trữ một lượng bộ nhớ thích hợp và sử dụng tất cả hoặc phần lớn bộ nhớ để làm điều gì đó đáng giá. Là đáng giá có thể có nhiều dạng. Đôi khi, một Sắp xếp có thể tự trả giá bằng cách cho phép hoạt động sau này hoạt động hiệu quả hơn nhiều trên đầu vào được sắp xếp. Trong những trường hợp khác, Sắp xếp chỉ đơn giản là cần thiết và chúng tôi chỉ cần làm cho nó hiệu quả nhất có thể.
Sau đó, hãy đến những Loại mà chúng ta thường muốn tránh:những loại dự trữ nhiều bộ nhớ hơn mức chúng cần và những loại dự trữ quá ít. Trường hợp thứ hai là trường hợp mà mọi người chú trọng nhất. Với bộ nhớ không đủ dự trữ (hoặc khả dụng) để hoàn thành thao tác sắp xếp bắt buộc trong bộ nhớ, toán tử Sắp xếp, với một số ngoại lệ, sẽ tràn các hàng dữ liệu vào tempdb . Trong thực tế, điều này hầu như luôn luôn có nghĩa là ghi các trang sắp xếp vào bộ nhớ vật lý (và tất nhiên là đọc lại chúng sau này).
Trong các phiên bản hiện đại của SQL Server, Sắp xếp tràn dẫn đến biểu tượng cảnh báo trong các kế hoạch sau khi thực thi, có thể bao gồm các chi tiết liên quan đến lượng dữ liệu đã bị tràn, bao nhiêu luồng liên quan và mức tràn.
Bối cảnh:Mức độ tràn
Hãy xem xét nhiệm vụ sắp xếp 4000MB dữ liệu, khi chúng ta chỉ có 500MB bộ nhớ khả dụng. Rõ ràng, chúng ta không thể sắp xếp toàn bộ tập hợp trong bộ nhớ cùng một lúc, nhưng chúng ta có thể chia nhỏ nhiệm vụ:
Đầu tiên chúng tôi đọc 500MB dữ liệu, sắp xếp tập hợp đó trong bộ nhớ, sau đó ghi kết quả vào đĩa. Thực hiện điều này tổng cộng 8 lần sẽ tiêu tốn toàn bộ 4000MB đầu vào, dẫn đến 8 bộ dữ liệu đã sắp xếp có kích thước 500MB. Bước thứ hai là thực hiện hợp nhất 8 chiều của các tập dữ liệu đã được sắp xếp. Lưu ý rằng một hợp nhất là bắt buộc, không phải là sự ghép nối đơn giản của các tập hợp vì dữ liệu chỉ được đảm bảo được sắp xếp theo yêu cầu trong một tập hợp 500MB cụ thể ở giai đoạn trung gian.
Về nguyên tắc, chúng ta có thể đọc và hợp nhất từng hàng một từ mỗi lần trong số tám lần chạy sắp xếp, nhưng điều này sẽ không hiệu quả lắm. Thay vào đó, chúng tôi đọc phần đầu tiên của mỗi loại chạy trở lại bộ nhớ, chẳng hạn 60MB. Điều này tiêu tốn 8 x 60MB =480MB trong số 500MB mà chúng tôi có sẵn. Sau đó, chúng tôi có thể thực hiện hợp nhất 8 chiều trong bộ nhớ một cách hiệu quả trong một thời gian, đệm đầu ra được sắp xếp cuối cùng với bộ nhớ 20MB vẫn còn trống. Khi mỗi bộ đệm bộ nhớ chạy sắp xếp trống, chúng tôi đọc một phần mới của loại đó chạy vào bộ nhớ. Khi tất cả các lần sắp xếp đã được sử dụng, việc sắp xếp đã hoàn tất.
Chúng tôi có thể bao gồm một số chi tiết và tối ưu hóa bổ sung, nhưng đó là phác thảo cơ bản của tràn Cấp 1, còn được gọi là tràn một lần. Cần thêm một lần chuyển dữ liệu để tạo ra đầu ra được sắp xếp cuối cùng.
Bây giờ, hợp nhất n-way về mặt lý thuyết có thể chứa một loại kích thước bất kỳ, trong bất kỳ dung lượng bộ nhớ nào, chỉ đơn giản bằng cách tăng số lượng các bộ được sắp xếp cục bộ trung gian. Vấn đề là khi 'n' tăng lên, chúng ta kết thúc việc đọc và ghi các phần dữ liệu nhỏ hơn. Ví dụ:sắp xếp 400GB dữ liệu trong 500MB bộ nhớ có nghĩa là hợp nhất 800 chiều, với chỉ khoảng 0,6MB từ mỗi bộ được sắp xếp trung gian trong bộ nhớ tại một thời điểm bất kỳ (800 x 0,6MB =480MB, để lại một số không gian cho một bộ đệm đầu ra).
Nhiều thẻ hợp nhất có thể được sử dụng để giải quyết vấn đề này. Ý tưởng chung là hợp nhất từng phần nhỏ thành những phần lớn hơn, cho đến khi chúng tôi có thể tạo ra luồng đầu ra được sắp xếp cuối cùng một cách hiệu quả. Trong ví dụ, điều này có thể có nghĩa là hợp nhất 40 trong số 800 bộ được sắp xếp theo đường truyền thứ nhất tại một thời điểm, dẫn đến 20 phần lớn hơn, sau đó có thể được hợp nhất lại để tạo thành đầu ra. Với tổng cộng hai lần vượt qua dữ liệu, đây sẽ là lần tràn Cấp 2, v.v. May mắn thay, sự gia tăng tuyến tính về mức tràn cho phép tăng kích thước sắp xếp theo cấp số nhân, do đó, mức tràn sắp xếp sâu hiếm khi cần thiết.
Tràn "Cấp 15.000"
Tại thời điểm này, bạn có thể tự hỏi sự kết hợp giữa cấp bộ nhớ nhỏ và kích thước dữ liệu khổng lồ có thể dẫn đến tràn sắp xếp cấp 15.000. Bạn đang cố gắng sắp xếp toàn bộ Internet trong bộ nhớ 1MB? Có thể, nhưng đó là cách quá khó để demo. Thành thật mà nói, tôi không biết liệu mức tràn thực sự cao như vậy có thể xảy ra trong SQL Server hay không. Mục tiêu ở đây (chắc chắn là gian lận) là để SQL Server báo cáo mức tràn 15.000.
Thành phần quan trọng là phân vùng. Kể từ SQL Server 2012, chúng tôi đã được phép (thuận tiện) tối đa 15.000 phân vùng cho mỗi đối tượng (hỗ trợ 15.000 phân vùng cũng có sẵn trên 2008 SP2 và 2008 R2 SP1, nhưng bạn phải bật nó theo cách thủ công trên mỗi cơ sở dữ liệu và lưu ý tất cả lưu ý).
Điều đầu tiên chúng ta cần là một chức năng phân vùng 15.000 phần tử và một lược đồ phân vùng liên quan. Để tránh khối mã nội tuyến thực sự khổng lồ, tập lệnh sau sử dụng SQL động để tạo các câu lệnh bắt buộc:
DECLARE
@sql nvarchar(max) =
N'
CREATE PARTITION FUNCTION PF (integer)
AS RANGE LEFT
FOR VALUES
(1';
DECLARE @i integer = 2;
WHILE @i < 15000
BEGIN
SET @sql += N',' + CONVERT(nvarchar(5), @i);
SET @i += 1;
END;
SET @sql = @sql + N');';
EXECUTE (@sql);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]); Tập lệnh đủ dễ dàng để sửa đổi thành một số thấp hơn trong trường hợp thiết lập của bạn gặp khó khăn với 15.000 phân vùng (đặc biệt là từ quan điểm bộ nhớ, như chúng ta sẽ thấy ngay sau đây). Các bước tiếp theo là tạo một bảng heap bình thường (không được phân vùng) với một cột số nguyên duy nhất và sau đó điền nó với các số nguyên từ 1 đến 15.000 bao gồm:
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test1 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Quá trình đó sẽ hoàn thành trong 100 mili giây hoặc lâu hơn. Nếu bạn có sẵn một bảng số, hãy sử dụng bảng đó để thay thế để có trải nghiệm dựa trên bộ định sẵn hơn. Cách bảng cơ sở được điền không quan trọng. Để có được 15.000 cấp tràn, tất cả những gì chúng ta cần làm bây giờ là tạo một chỉ mục được phân nhóm được phân vùng trên bảng:
CREATE UNIQUE CLUSTERED INDEX CUQ ON dbo.Test1 (c1) WITH (MAXDOP = 1) ON PS (c1);
Thời gian thực thi phụ thuộc rất nhiều vào hệ thống lưu trữ đang sử dụng. Trên máy tính xách tay của tôi, sử dụng ổ SSD tiêu dùng khá điển hình từ vài năm trước, mất khoảng 20 giây, điều này khá đáng kể khi chúng tôi chỉ xử lý tổng cộng 15.000 hàng. Trên máy ảo Azure có thông số kỹ thuật khá thấp với hiệu suất I / O khá khủng khiếp, thử nghiệm tương tự mất gần 20 phút.
Phân tích
Kế hoạch thực thi cho việc xây dựng chỉ mục là:
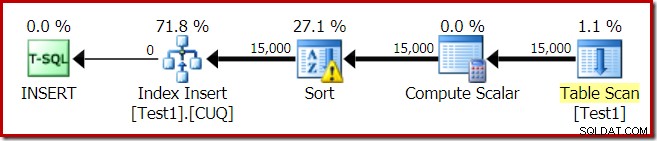
Bảng quét đọc 15.000 hàng từ bảng đống của chúng tôi. Compute Scalar tính số phân vùng chỉ mục đích cho mỗi hàng bằng cách sử dụng hàm nội bộ RangePartitionNew() . Sắp xếp là phần thú vị nhất của kế hoạch, vì vậy chúng ta sẽ xem xét nó chi tiết hơn.
Đầu tiên, Cảnh báo sắp xếp, như được hiển thị trong Plan Explorer:

Một cảnh báo tương tự từ SSMS (lấy từ một lần chạy tập lệnh khác):
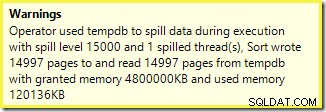
Điều đầu tiên cần lưu ý là báo cáo về mức độ tràn 15.000 loại, như đã hứa. Điều này không hoàn toàn chính xác, nhưng các chi tiết khá thú vị. Sắp xếp trong gói này có Partition ID thuộc tính thường không xuất hiện:
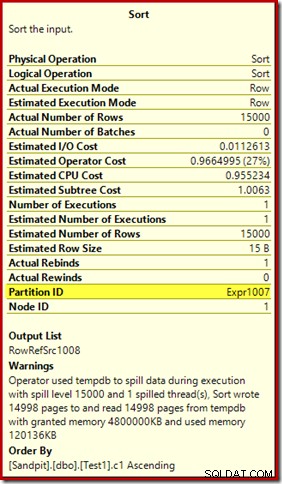
Thuộc tính này được đặt bằng với định nghĩa hàm phân vùng bên trong trong Tính toán vô hướng.
Đây là bản dựng chỉ mục không liên kết , bởi vì nguồn và đích có sự sắp xếp phân vùng khác nhau. Trong trường hợp này, sự khác biệt đó phát sinh do bảng đống nguồn không được phân vùng, nhưng chỉ mục đích thì có. Do đó, 15.000 sắp xếp riêng biệt được tạo trong thời gian chạy:một sắp xếp cho mỗi phân vùng đích không trống. Mỗi loại trong số này tràn đến mức 1 và SQL Server tổng hợp tất cả các lần tràn này để đưa ra mức tràn sắp xếp cuối cùng là 15.000.
15.000 loại riêng biệt giải thích việc cấp bộ nhớ lớn. Mỗi phiên bản sắp xếp có kích thước tối thiểu là 40 trang, là 40 x 8KB =320KB. Do đó, 15.000 loại cần tối thiểu 15.000 x 320KB =4.800.000KB bộ nhớ. Đó chỉ là bộ nhớ RAM 4,6 GB dành riêng cho truy vấn sắp xếp 15.000 hàng chứa một cột số nguyên duy nhất. Và mỗi loại sẽ tràn ra đĩa, mặc dù chỉ nhận được một hàng! Nếu tính song song được sử dụng cho việc xây dựng chỉ mục, thì mức cấp bộ nhớ có thể tăng thêm theo số luồng. Cũng lưu ý rằng hàng đơn được viết trong một trang, giải thích số lượng trang được ghi và đọc từ tempdb. Dường như có một điều kiện chạy đua có nghĩa là số lượng trang được báo cáo thường ít hơn 15.000.
Tất nhiên, ví dụ này phản ánh một trường hợp cạnh, nhưng vẫn khó hiểu tại sao mỗi lần sắp xếp lại tràn ra hàng đơn của nó thay vì sắp xếp trong bộ nhớ mà nó đã được cung cấp. Có lẽ đây là do thiết kế của một số lý do, hoặc có thể nó chỉ đơn giản là một lỗi. Dù thế nào đi nữa, vẫn rất thú vị khi thấy một loại dữ liệu vài trăm KB mất nhiều thời gian như vậy với mức bộ nhớ 4,6 GB và mức tràn 15.000. Trừ khi bạn gặp phải nó trong một môi trường sản xuất, có thể. Dù sao, đó là điều cần lưu ý.
Báo cáo tràn mức 15.000 sai lệch khá nhiều đi đến những hạn chế về đại diện trong kết quả chương trình kế hoạch. Vấn đề cơ bản là một cái gì đó phát sinh ở nhiều nơi mà các hành động lặp lại xảy ra, ví dụ như ở phía bên trong của phép nối các vòng lặp lồng nhau. Chắc chắn sẽ rất hữu ích nếu có thể xem một bảng phân tích chính xác hơn thay vì một tổng thể chung trong những trường hợp này. Theo thời gian, khu vực này đã được cải thiện một chút, vì vậy giờ đây chúng tôi có thêm thông tin gói cho mỗi luồng hoặc mỗi phân vùng cho một số hoạt động. Tuy nhiên, vẫn còn một chặng đường dài phía trước.
Vẫn còn ít hữu ích hơn khi 15.000 sự cố tràn cấp độ 1 riêng biệt được báo cáo ở đây như một sự cố tràn cấp 15.000 đơn lẻ.
Các biến thể thử nghiệm
Bài viết này thiên về làm nổi bật các hạn chế về thông tin kế hoạch và khả năng có hiệu suất kém khi sử dụng quá nhiều phân vùng, hơn là về việc làm cho hoạt động ví dụ cụ thể hiệu quả hơn, nhưng có một số biến thể thú vị mà tôi muốn xem xét. .
Trực tuyến, Sắp xếp theo tempdb
Thực hiện thao tác tạo chỉ mục được phân vùng tương tự với ONLINE = ON, SORT_IN_TEMPDB = ON không bị cùng một mức cấp và tràn bộ nhớ khổng lồ:
CREATE TABLE dbo.Test2
(
c1 integer NOT NULL
);
-- Copy the sample data
INSERT dbo.Test2 WITH (TABLOCKX)
(c1)
SELECT
T1.c1
FROM dbo.Test1 AS T1
OPTION (MAXDOP 1);
-- Partitioned clustered index build
CREATE CLUSTERED INDEX CUQ
ON dbo.Test2 (c1)
WITH (MAXDOP = 1, ONLINE = ON, SORT_IN_TEMPDB = ON)
ON PS (c1);
Lưu ý rằng sử dụng ONLINE riêng nó là không đủ. Trên thực tế, điều đó dẫn đến kế hoạch giống như trước đây với tất cả các vấn đề giống nhau, cộng với chi phí bổ sung để xây dựng từng phân vùng chỉ mục trực tuyến. Đối với tôi, điều đó dẫn đến thời gian thực hiện hơn một phút. Lòng tốt biết sẽ mất bao lâu đối với một phiên bản Azure cấu hình thấp với hiệu suất I / O đáng sợ.
Dù sao, kế hoạch thực thi với ONLINE = ON, SORT_IN_TEMPDB = ON là:

Sắp xếp được thực hiện trước khi số phân vùng đích được tính. Nó không có thuộc tính Partition ID, vì vậy nó chỉ là một loại thông thường. Toàn bộ hoạt động chạy trong khoảng mười giây (vẫn còn rất nhiều phân vùng để tạo). Nó dự trữ bộ nhớ dưới 3MB và sử dụng tối đa 816KB. Khá cải thiện hơn 4,6 GB và 15.000 lần đổ.
Lập chỉ mục trước, sau đó đến dữ liệu
Có thể thu được các kết quả tương tự bằng cách ghi dữ liệu vào bảng heap trước:
-- Heap source
CREATE TABLE dbo.SourceData
(
c1 integer NOT NULL
);
-- Add data
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.SourceData (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Tiếp theo, tạo một bảng nhóm được phân vùng trống và chèn dữ liệu từ heap:
-- Destination table
CREATE TABLE dbo.Test3
(
c1 integer NOT NULL
)
ON PS (c1); -- Optional
-- Partitioned Clustered Index
CREATE CLUSTERED INDEX CUQ
ON dbo.Test3 (c1)
ON PS (c1);
-- Add data
INSERT dbo.Test3 WITH (TABLOCKX)
(c1)
SELECT
SD.c1
FROM dbo.SourceData AS SD
OPTION (MAXDOP 1);
-- Clean up
DROP TABLE dbo.SourceData; Quá trình này mất khoảng 10 giây với bộ nhớ 2MB được cấp và không bị tràn:
Tất nhiên, cũng có thể tránh hoàn toàn việc sắp xếp bằng cách lập chỉ mục bảng nguồn (không phân vùng) và chèn dữ liệu theo thứ tự chỉ mục (hãy nhớ rằng cách sắp xếp tốt nhất là không có sự sắp xếp nào cả).
heap được phân vùng, sau đó là dữ liệu, rồi lập chỉ mục
Đối với biến thể cuối cùng này, trước tiên, chúng tôi tạo một heap được phân vùng và tải 15.000 hàng thử nghiệm:
CREATE TABLE dbo.Test4
(
c1 integer NOT NULL
)
ON PS (c1);
SET STATISTICS XML OFF;
SET NOCOUNT ON;
DECLARE @i integer = 1;
BEGIN TRANSACTION;
WHILE @i <= 15000
BEGIN
INSERT dbo.Test4 (c1) VALUES (@i);
SET @i += 1;
END;
COMMIT TRANSACTION;
SET NOCOUNT OFF; Tập lệnh đó chạy trong một hoặc hai giây, điều này khá tốt. Bước cuối cùng là tạo chỉ mục nhóm được phân vùng:
CREATE CLUSTERED INDEX CUQ ON dbo.Test4 (c1) WITH (MAXDOP = 1) ON PS (c1);
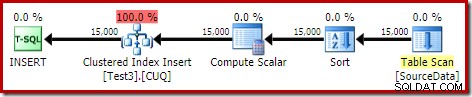
Đó là một thảm họa hoàn toàn, cả từ quan điểm hiệu suất và từ quan điểm thông tin kế hoạch chương trình. Hoạt động tự chạy trong vòng chỉ dưới một phút, với kế hoạch thực thi sau:

Đây là một kế hoạch chèn theo vị trí. Quét liên tục chứa một hàng cho mỗi id phân vùng. Mặt trong của vòng lặp tìm kiếm phân vùng hiện tại của heap (vâng, tìm kiếm trên heap). Sắp xếp có thuộc tính id phân vùng (mặc dù điều này là không đổi trên mỗi lần lặp vòng lặp) vì vậy có một sắp xếp trên mỗi phân vùng và hành vi tràn không mong muốn. Cảnh báo thống kê trên bảng heap là giả mạo.
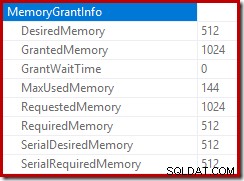
Gốc của gói chèn cho biết rằng bộ nhớ cấp 1MB đã được dự trữ, với tối đa 144KB được sử dụng:
Toán tử sắp xếp không báo cáo tràn mức 15.000, nhưng ngược lại sẽ tạo ra một mớ hỗn độn hoàn chỉnh của các phép toán lặp mỗi vòng liên quan:

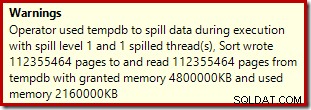
Theo dõi bộ nhớ cấp DMV trong quá trình thực thi cho thấy rằng truy vấn này thực sự chỉ dự trữ 1MB, với tối đa 144KB được sử dụng trên mỗi lần lặp lại của vòng lặp. (Ngược lại, bộ nhớ 4,6GB đặt trước trong lần thử nghiệm đầu tiên là hoàn toàn chính hãng.) Tất nhiên, điều này rất khó hiểu.
Vấn đề (như đã đề cập trước đó) là SQL Server bị nhầm lẫn về cách tốt nhất để báo cáo về những gì đã xảy ra qua nhiều lần lặp lại. Có thể không thực tế khi bao gồm thông tin hiệu suất kế hoạch cho mỗi phân vùng mỗi lần lặp, nhưng không tránh khỏi thực tế là cách sắp xếp hiện tại đôi khi tạo ra kết quả khó hiểu. Chúng tôi chỉ có thể hy vọng rằng một ngày nào đó có thể tìm ra cách tốt hơn để báo cáo loại thông tin này, theo một định dạng nhất quán hơn.