 Khi lớn lên, tôi yêu thích các trò chơi kiểm tra trí nhớ và kỹ năng khớp mẫu. Một vài người bạn của tôi có Simon, trong khi tôi có một người bị đánh cắp tên là Einstein. Những người khác có Atari Touch Me, thậm chí hồi đó tôi biết đó là một quyết định đặt tên có vấn đề. Ngày nay, đối sánh mẫu có ý nghĩa khác biệt với tôi và có thể là một phần đắt giá trong các truy vấn cơ sở dữ liệu hàng ngày.
Khi lớn lên, tôi yêu thích các trò chơi kiểm tra trí nhớ và kỹ năng khớp mẫu. Một vài người bạn của tôi có Simon, trong khi tôi có một người bị đánh cắp tên là Einstein. Những người khác có Atari Touch Me, thậm chí hồi đó tôi biết đó là một quyết định đặt tên có vấn đề. Ngày nay, đối sánh mẫu có ý nghĩa khác biệt với tôi và có thể là một phần đắt giá trong các truy vấn cơ sở dữ liệu hàng ngày.
Gần đây, tôi đã gặp một vài nhận xét trên Stack Overflow trong đó một người dùng đã nói rằng, như thể sự thật, rằng CHARINDEX hoạt động tốt hơn LEFT hoặc LIKE . Trong một trường hợp, người đó đã trích dẫn một bài báo của David Lozinski, "SQL:LIKE vs SUBSTRING vs LEFT / RIGHT vs CHARINDEX." Có, bài viết cho thấy rằng, trong ví dụ tiếp theo, CHARINDEX thực hiện tốt nhất. Tuy nhiên, vì tôi luôn nghi ngờ về các tuyên bố chung chung như vậy và không thể nghĩ ra lý do hợp lý tại sao một hàm chuỗi lại luôn luôn hoạt động tốt hơn người khác, với tất cả những thứ khác đều bình đẳng , Tôi đã chạy các bài kiểm tra của anh ấy. Chắc chắn, tôi đã có kết quả khác nhau lặp lại trên máy của mình (bấm để phóng to):
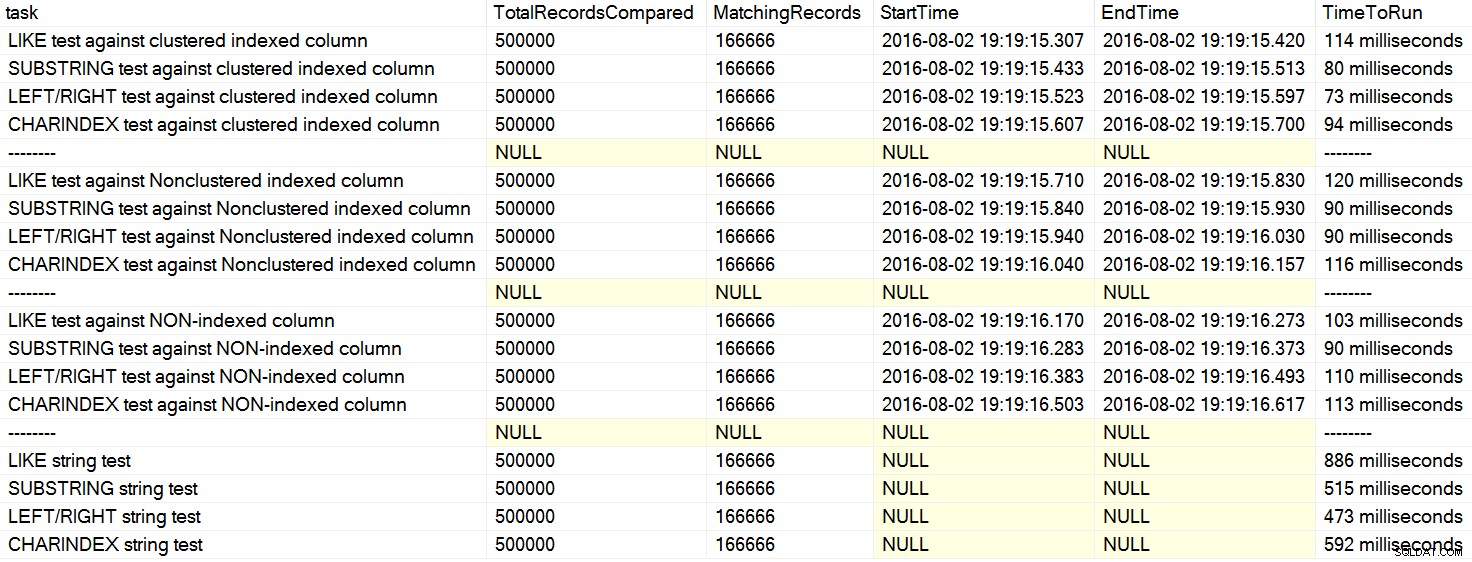 Trên máy của tôi, CHARINDEX chậm hơn hơn LEFT / RIGHT / SUBSTRING.
Trên máy của tôi, CHARINDEX chậm hơn hơn LEFT / RIGHT / SUBSTRING.
Các thử nghiệm của David về cơ bản là so sánh các cấu trúc truy vấn này - tìm kiếm mẫu chuỗi ở đầu hoặc cuối giá trị cột - về thời lượng thô:
WHERE Column LIKE @pattern + '%' OR Column LIKE '%' + @pattern; WHERE SUBSTRING(Column, 1, LEN(@pattern)) = @pattern OR SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)) = @pattern; WHERE LEFT(Column, LEN(@pattern)) = @pattern OR RIGHT(Column, LEN(@pattern)) = @pattern; WHERE CHARINDEX(@pattern, SUBSTRING(Column, 1, LEN(@pattern)), 0) > 0 OR CHARINDEX(@pattern, SUBSTRING(Column, LEN(Column) - LEN(@pattern) + 1, LEN(@pattern)), 0) > 0;
Chỉ cần nhìn vào các mệnh đề này, bạn có thể thấy tại sao CHARINDEX có thể kém hiệu quả hơn - nó tạo ra nhiều lệnh gọi chức năng bổ sung mà các cách tiếp cận khác không phải thực hiện. Tại sao phương pháp này hoạt động tốt nhất trên máy của David, tôi không chắc; có thể anh ấy đã chạy mã chính xác như đã đăng và không thực sự giảm bộ đệm giữa các lần kiểm tra, do đó các lần kiểm tra sau được hưởng lợi từ dữ liệu được lưu trong bộ nhớ cache.
Về lý thuyết, CHARINDEX lẽ ra có thể được diễn đạt đơn giản hơn, ví dụ:
WHERE CHARINDEX(@pattern, Column) = 1 OR CHARINDEX(@pattern, Column) = LEN(Column) - LEN(@pattern) + 1;
(Nhưng điều này thực sự còn tệ hơn trong các bài kiểm tra thông thường của tôi.)
Và tại sao chúng lại là OR điều kiện, tôi không chắc chắn. Thực tế, hầu hết thời gian bạn đang thực hiện một trong hai loại tìm kiếm mẫu: bắt đầu với hoặc chứa (tìm kiếm kết thúc bằng thì ít phổ biến hơn nhiều ). Và trong hầu hết các trường hợp đó, người dùng có xu hướng thông báo trước xem họ có muốn bắt đầu với hoặc chứa , ít nhất là trong mọi ứng dụng mà tôi đã tham gia trong sự nghiệp của mình.
Sẽ rất hợp lý khi tách chúng ra dưới dạng các loại truy vấn riêng biệt, thay vì sử dụng HOẶC có điều kiện, vì bắt đầu bằng có thể sử dụng một chỉ mục (nếu một chỉ mục tồn tại đủ phù hợp để tìm kiếm hoặc mỏng hơn chỉ mục được phân nhóm), trong khi kết thúc bằng không thể (và HOẶC điều kiện có xu hướng ném cờ lê vào trình tối ưu hóa nói chung). Nếu tôi có thể tin tưởng, hãy LIKE để sử dụng một chỉ mục khi nó có thể và hoạt động tốt bằng hoặc tốt hơn các giải pháp khác ở trên trong hầu hết hoặc tất cả các trường hợp, thì tôi có thể thực hiện logic này rất dễ dàng. Một thủ tục được lưu trữ có thể nhận hai tham số - mẫu đang được tìm kiếm và loại tìm kiếm để thực hiện (nói chung có bốn loại đối sánh chuỗi - bắt đầu bằng, kết thúc bằng, chứa hoặc đối sánh chính xác).
CREATE PROCEDURE dbo.Search
@pattern nvarchar(100),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
-- latter two are supported but won't be tested here
AS
BEGIN
SET NOCOUNT ON;
SELECT ...
WHERE Column LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
Điều này xử lý từng trường hợp tiềm năng mà không cần sử dụng SQL động; OPTION (RECOMPILE) là ở đó bởi vì bạn sẽ không muốn một kế hoạch được tối ưu hóa cho "kết thúc bằng" (mà gần như chắc chắn sẽ cần phải quét) được sử dụng lại cho truy vấn "bắt đầu với" hoặc ngược lại; nó cũng sẽ đảm bảo rằng các ước tính là chính xác ("bắt đầu bằng S" có thể có bản số khác nhiều so với "bắt đầu bằng QX"). Ngay cả khi bạn gặp trường hợp người dùng chọn một loại tìm kiếm 99% thời gian, bạn có thể sử dụng SQL động ở đây thay vì biên dịch lại, nhưng trong trường hợp đó, bạn vẫn dễ bị đánh cắp tham số. Trong nhiều truy vấn logic có điều kiện, biên dịch lại và / hoặc SQL động đầy đủ thường là cách tiếp cận hợp lý nhất (xem bài đăng của tôi về "Chậu rửa trong bếp").
Các bài kiểm tra
Vì gần đây tôi đã bắt đầu xem xét cơ sở dữ liệu mẫu WideWorldImporters mới, nên tôi quyết định chạy thử nghiệm của riêng mình ở đó. Thật khó tìm được một bảng có kích thước vừa phải mà không có chỉ mục ColumnStore hoặc bảng lịch sử tạm thời, nhưng Sales.Invoices , có 70.510 hàng, có nvarchar(20) đơn giản cột được gọi là CustomerPurchaseOrderNumber mà tôi đã quyết định sử dụng cho các bài kiểm tra. (Tại sao lại là nvarchar(20) khi mọi giá trị đơn lẻ là một số có 5 chữ số, tôi không biết nhưng đối sánh mẫu không thực sự quan tâm nếu các byte bên dưới đại diện cho số hay chuỗi.)
| Sales.Invoices CustomerPurchaseOrderNumber | ||
|---|---|---|
| Mẫu | # hàng | % của Bảng |
| Bắt đầu bằng "1" | 70.505 | 99,993% |
| Bắt đầu bằng "2" | 5 | 0,007% |
| Kết thúc bằng "5" | 6.897 | 9,782% |
| Kết thúc bằng "30" | 749 | 1,062% |
Tôi đã xem xét các giá trị trong bảng để đưa ra nhiều tiêu chí tìm kiếm sẽ tạo ra số lượng hàng rất lớn, hy vọng sẽ tiết lộ bất kỳ hành vi điểm tới hạn nào với một cách tiếp cận nhất định. Ở bên phải là các truy vấn tìm kiếm mà tôi đã truy cập.
Tôi muốn chứng minh với bản thân rằng quy trình trên không thể phủ nhận về tổng thể tốt hơn cho tất cả các tìm kiếm có thể có so với bất kỳ truy vấn nào sử dụng OR điều kiện, bất kể chúng có sử dụng LIKE hay không , LEFT/RIGHT , SUBSTRING hoặc CHARINDEX . Tôi đã lấy các cấu trúc truy vấn cơ bản của David và đặt chúng vào các thủ tục được lưu trữ (với cảnh báo rằng tôi không thể thực sự kiểm tra "chứa" mà không có đầu vào của anh ấy và tôi phải tạo OR của anh ấy logic linh hoạt hơn một chút để có cùng số hàng), cùng với một phiên bản logic của tôi. Tôi cũng đã lên kế hoạch kiểm tra các quy trình có và không có chỉ mục mà tôi sẽ tạo trên cột tìm kiếm và trong cả bộ đệm nóng và bộ nhớ cache lạnh.
Các thủ tục:
CREATE PROCEDURE dbo.David_LIKE
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CustomerPurchaseOrderNumber LIKE @pattern + N'%')
OR (@option = 'EndsWith'
AND CustomerPurchaseOrderNumber LIKE N'%' + @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OR (@option = 'EndsWith'
AND RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX
@pattern nvarchar(10),
@option varchar(10) -- StartsWith or EndsWith
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE (@option = 'StartsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0)
OR (@option = 'EndsWith'
AND CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0)
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.Aaron_Conditional
@pattern nvarchar(10),
@option varchar(10) -- 'StartsWith', 'EndsWith', 'ExactMatch', 'Contains'
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE
-- if contains or ends with, need a leading wildcard
CASE WHEN @option IN ('Contains','EndsWith')
THEN N'%' ELSE N'' END
+ @pattern +
-- if contains or starts with, need a trailing wildcard
CASE WHEN @option IN ('Contains','StartsWith')
THEN N'%' ELSE N'' END
OPTION (RECOMPILE);
END
GO
Tôi cũng đã tạo các phiên bản của các thủ tục của David đúng với ý định ban đầu của anh ấy, giả sử yêu cầu thực sự là tìm bất kỳ hàng nào có mẫu tìm kiếm ở đầu * hoặc * cuối chuỗi. Tôi đã làm điều này đơn giản để tôi có thể so sánh hiệu suất của các phương pháp tiếp cận khác nhau, chính xác như anh ấy đã viết chúng, để xem liệu trên tập dữ liệu này, kết quả của tôi có khớp với các thử nghiệm của tôi đối với tập lệnh gốc của anh ấy trên hệ thống của tôi hay không. Trong trường hợp này, không có lý do gì để giới thiệu một phiên bản của riêng tôi, vì nó chỉ đơn giản là phù hợp với LIKE % + @pattern OR LIKE @pattern + % của anh ấy biến thể.
CREATE PROCEDURE dbo.David_LIKE_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CustomerPurchaseOrderNumber LIKE @pattern + N'%'
OR CustomerPurchaseOrderNumber LIKE N'%' + @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_SUBSTRING_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)) = @pattern
OR SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_LEFTRIGHT_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE LEFT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OR RIGHT(CustomerPurchaseOrderNumber, LEN(@pattern)) = @pattern
OPTION (RECOMPILE);
END
GO
CREATE PROCEDURE dbo.David_CHARINDEX_Original
@pattern nvarchar(10)
AS
BEGIN
SET NOCOUNT ON;
SELECT CustomerPurchaseOrderNumber, OrderID
FROM Sales.Invoices
WHERE CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber, 1,
LEN(@pattern)), 0) > 0
OR CHARINDEX(@pattern, SUBSTRING(CustomerPurchaseOrderNumber,
LEN(CustomerPurchaseOrderNumber) - LEN(@pattern) + 1,
LEN(@pattern)), 0) > 0
OPTION (RECOMPILE);
END
GO Với các thủ tục đã có, tôi có thể tạo mã thử nghiệm - điều này thường thú vị không kém gì vấn đề ban đầu. Đầu tiên, một bảng ghi nhật ký:
DROP TABLE IF EXISTS dbo.LoggingTable; GO SET NOCOUNT ON; CREATE TABLE dbo.LoggingTable ( LogID int IDENTITY(1,1), prc sysname, opt varchar(10), pattern nvarchar(10), frame varchar(11), duration int, LogTime datetime2 NOT NULL DEFAULT SYSUTCDATETIME() );
Sau đó, mã sẽ thực hiện các hoạt động được chọn bằng cách sử dụng các thủ tục và đối số khác nhau:
SET NOCOUNT ON;
;WITH prc(name) AS
(
SELECT name FROM sys.procedures
WHERE LEFT(name,5) IN (N'David', N'Aaron')
),
args(opt,pattern) AS
(
SELECT 'StartsWith', N'1'
UNION ALL SELECT 'StartsWith', N'2'
UNION ALL SELECT 'EndsWith', N'5'
UNION ALL SELECT 'EndsWith', N'30'
),
frame(w) AS
(
SELECT 'BeforeIndex'
UNION ALL SELECT 'AfterIndex'
),
y AS
(
-- comment out lines 2-4 here if we want warm cache
SELECT cmd = 'GO
DBCC FREEPROCCACHE() WITH NO_INFOMSGS;
DBCC DROPCLEANBUFFERS() WITH NO_INFOMSGS;
GO
DECLARE @d datetime2, @delta int;
SET @d = SYSUTCDATETIME();
EXEC dbo.' + prc.name + ' @pattern = N'''
+ args.pattern + '''' + CASE
WHEN prc.name LIKE N'%_Original' THEN ''
ELSE ',@option = ''' + args.opt + '''' END + ';
SET @delta = DATEDIFF(MICROSECOND, @d, SYSUTCDATETIME());
INSERT dbo.LoggingTable(prc,opt,pattern,frame,duration)
SELECT N''' + prc.name + ''',''' + args.opt + ''',N'''
+ args.pattern + ''',''' + frame.w + ''',@delta;
',
*, rn = ROW_NUMBER() OVER
(PARTITION BY frame.w ORDER BY frame.w DESC,
LEN(prc.name), args.opt DESC, args.pattern)
FROM prc CROSS JOIN args CROSS JOIN frame
)
SELECT cmd = cmd + CASE WHEN rn = 36 THEN
CASE WHEN w = 'BeforeIndex'
THEN 'CREATE INDEX testing ON '+
'Sales.Invoices(CustomerPurchaseOrderNumber);
' ELSE 'DROP INDEX Sales.Invoices.testing;' END
ELSE '' END--, name, opt, pattern, w, rn
FROM y
ORDER BY w DESC, rn; Kết quả
Tôi đã chạy các bài kiểm tra này trên một máy ảo, chạy Windows 10 (1511 / 10586.545), SQL Server 2016 (13.0.2149), với 4 CPU và 32 GB RAM. Tôi đã chạy mỗi bộ bài kiểm tra 11 lần; đối với các bài kiểm tra bộ nhớ đệm ấm, tôi đã đưa ra bộ kết quả đầu tiên vì một số trong số đó là các bài kiểm tra bộ đệm lạnh thực sự.
Tôi đấu tranh với cách vẽ biểu đồ kết quả để hiển thị các mẫu, chủ yếu là vì đơn giản là không có mẫu. Gần như mọi phương pháp đều là tốt nhất trong một kịch bản này và tệ nhất trong một kịch bản khác. Trong các bảng sau, tôi đã đánh dấu quy trình hoạt động tốt nhất và kém nhất cho từng cột và bạn có thể thấy rằng kết quả còn lâu mới kết luận được:
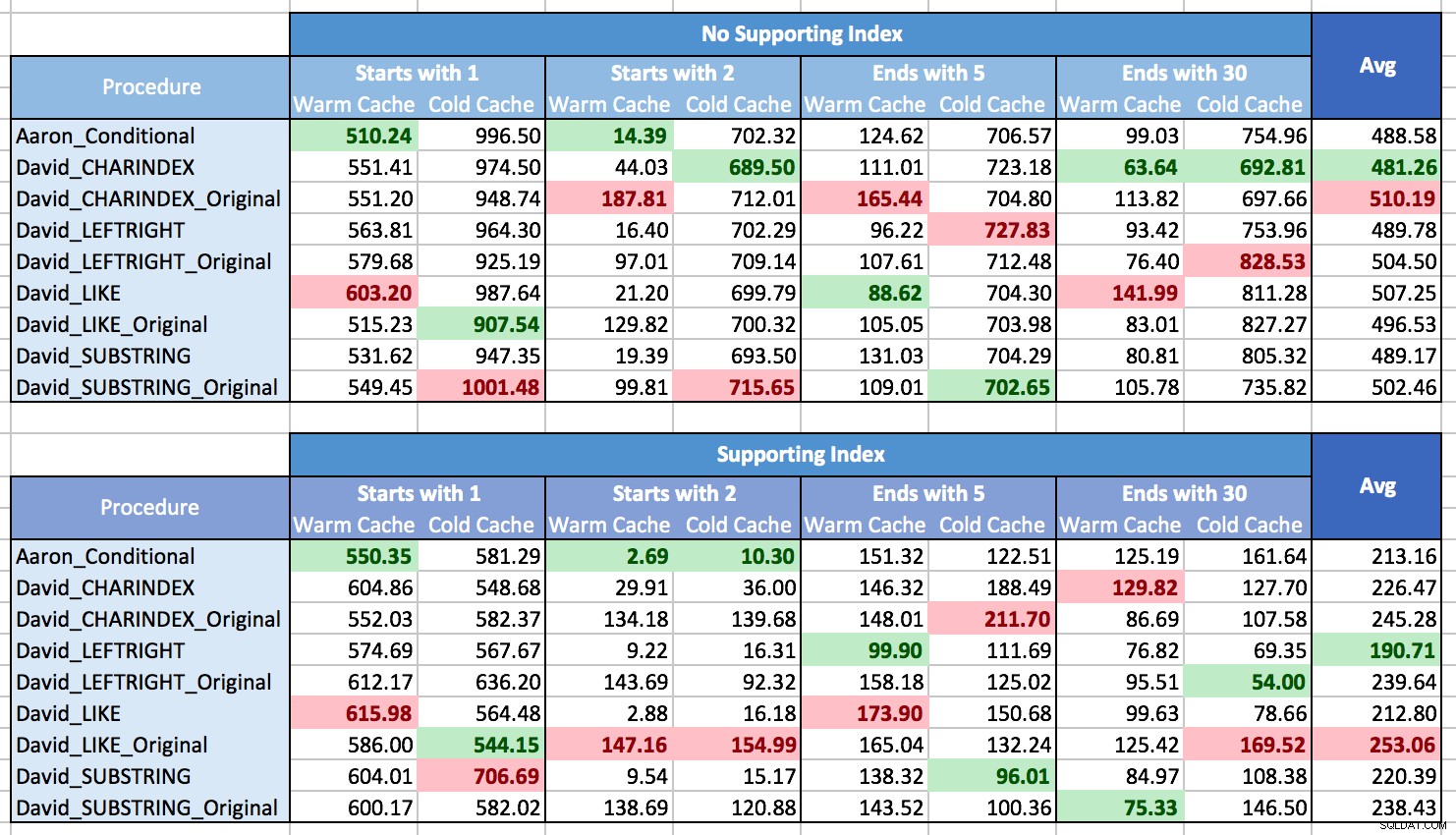 Trong các bài kiểm tra này, đôi khi CHARINDEX thắng và đôi khi thì không.
Trong các bài kiểm tra này, đôi khi CHARINDEX thắng và đôi khi thì không.
Những gì tôi đã học được là, về tổng thể, nếu bạn phải đối mặt với nhiều tình huống khác nhau (các kiểu đối sánh mẫu khác nhau, có chỉ mục hỗ trợ hoặc không, dữ liệu không phải lúc nào cũng có trong bộ nhớ), thì thực sự không có rõ ràng người chiến thắng và phạm vi hiệu suất trung bình là khá nhỏ (trên thực tế, vì bộ nhớ cache ấm không phải lúc nào cũng hữu ích, tôi sẽ nghi ngờ kết quả bị ảnh hưởng bởi chi phí hiển thị kết quả hơn là truy xuất chúng). Đối với các tình huống riêng lẻ, đừng dựa vào các thử nghiệm của tôi; tự chạy một số điểm chuẩn dựa trên phần cứng, cấu hình, dữ liệu và cách sử dụng của bạn.
Lưu ý
Một số điều tôi đã không xem xét cho các thử nghiệm này:
- Được phân nhóm so với không phân nhóm . Vì không chắc chỉ mục được phân nhóm của bạn sẽ nằm trên cột nơi bạn đang thực hiện tìm kiếm đối sánh mẫu so với đầu hoặc cuối chuỗi và vì tìm kiếm sẽ phần lớn giống nhau trong cả hai trường hợp (và sự khác biệt giữa các lần quét sẽ phần lớn là chức năng của chiều rộng chỉ mục so với chiều rộng bảng), tôi chỉ kiểm tra hiệu suất bằng cách sử dụng chỉ mục không phân cụm. Nếu bạn có bất kỳ tình huống cụ thể nào trong đó chỉ riêng sự khác biệt này đã tạo ra sự khác biệt sâu sắc về đối sánh mẫu, vui lòng cho tôi biết.
- MAX loại . Nếu bạn đang tìm kiếm các chuỗi trong
varchar(max)/nvarchar(max), chúng không thể được lập chỉ mục, vì vậy trừ khi bạn sử dụng các cột được tính toán để thể hiện các phần của giá trị, thì việc quét sẽ được yêu cầu - cho dù bạn đang tìm kiếm bắt đầu bằng, kết thúc bằng hay chứa. Cho dù chi phí hoạt động tương quan với kích thước của chuỗi hay chi phí bổ sung được giới thiệu chỉ đơn giản là do loại, tôi đã không kiểm tra.
- Tìm kiếm toàn văn bản . Tôi đã chơi với tính năng này ở đây và tehre, và tôi có thể đánh vần nó, nhưng nếu sự hiểu biết của tôi là đúng, điều này chỉ có thể hữu ích nếu bạn đang tìm kiếm toàn bộ các từ không ngừng và không quan tâm đến vị trí của chúng trong chuỗi. tìm. Sẽ không hữu ích nếu bạn đang lưu trữ các đoạn văn bản và muốn tìm tất cả những đoạn văn bản bắt đầu bằng "Y", chứa từ "the" hoặc kết thúc bằng dấu chấm hỏi.
Tóm tắt
Tuyên bố chung duy nhất mà tôi có thể đưa ra từ bài kiểm tra này là không có tuyên bố chung nào về cách hiệu quả nhất để thực hiện đối sánh mẫu chuỗi. Mặc dù tôi thiên về cách tiếp cận có điều kiện về tính linh hoạt và khả năng bảo trì, nhưng nó không phải là người chiến thắng về hiệu suất trong tất cả các tình huống. Đối với tôi, trừ khi tôi đang gặp phải một điểm nghẽn về hiệu suất và tôi đang theo đuổi tất cả các con đường, tôi sẽ tiếp tục sử dụng cách tiếp cận của mình để đạt được sự nhất quán. Như tôi đã đề xuất ở trên, nếu bạn có một tình huống rất hẹp và rất nhạy cảm với những khác biệt nhỏ về thời lượng, bạn sẽ muốn chạy thử nghiệm của riêng mình để xác định phương pháp nào luôn hoạt động tốt nhất cho bạn.



