[Phần 1 | Phần 2 | Phần 3 | Phần 4]
Trong phần 3 của loạt bài này, tôi đã chỉ ra hai cách giải quyết để tránh mở rộng IDENTITY cột - một cột chỉ giúp bạn mua thời gian và cột khác bỏ qua IDENTITY hoàn toàn. Cái trước giúp bạn không phải đối phó với những phụ thuộc bên ngoài như khóa ngoại, nhưng cái sau vẫn không giải quyết được vấn đề đó. Trong bài đăng này, tôi muốn trình bày chi tiết cách tiếp cận mà tôi sẽ thực hiện nếu tôi thực sự cần chuyển sang bigint , cần thiết để giảm thiểu thời gian chết và có nhiều thời gian để lập kế hoạch.
Do tất cả các trình chặn tiềm năng và nhu cầu về sự gián đoạn tối thiểu, phương pháp này có thể được coi là hơi phức tạp và nó chỉ trở nên phức tạp hơn nếu các tính năng kỳ lạ bổ sung đang được sử dụng (giả sử, phân vùng, OLTP trong bộ nhớ hoặc sao chép) .
Ở cấp độ rất cao, cách tiếp cận là tạo một tập hợp các bảng bóng, trong đó tất cả các phần chèn đều hướng đến một bản sao mới của bảng (với kiểu dữ liệu lớn hơn) và sự tồn tại của hai tập hợp bảng này càng trong suốt. càng tốt cho ứng dụng và người dùng của nó.
Ở cấp độ chi tiết hơn, tập hợp các bước sẽ như sau:
- Tạo các bản sao ẩn của bảng, với các loại dữ liệu phù hợp.
- Thay đổi các thủ tục được lưu trữ (hoặc mã đặc biệt) để sử dụng bigint cho các tham số. (Điều này có thể yêu cầu sửa đổi ngoài danh sách tham số, chẳng hạn như biến cục bộ, bảng tạm thời, v.v., nhưng đây không phải là trường hợp ở đây.)
- Đổi tên các bảng cũ và tạo các dạng xem bằng những tên kết hợp các bảng cũ và mới.
- Các chế độ xem đó sẽ thay vì có trình kích hoạt để hướng các hoạt động DML đến (các) bảng thích hợp một cách chính xác, do đó, dữ liệu vẫn có thể được sửa đổi trong quá trình di chuyển.
- Điều này cũng yêu cầu bỏ SCHEMABINDING khỏi bất kỳ chế độ xem được lập chỉ mục nào, các chế độ xem hiện có để có sự hợp nhất giữa các bảng mới và cũ, đồng thời sửa đổi các quy trình dựa trên SCOPE_IDENTITY ().
- Di chuyển dữ liệu cũ sang các bảng mới theo từng phần.
- Dọn dẹp, bao gồm:
- Bỏ qua các lượt xem tạm thời (điều này sẽ làm giảm INSTEAD OF kích hoạt).
- Đổi tên các bảng mới thành tên ban đầu.
- Sửa các thủ tục đã lưu trữ để hoàn nguyên về SCOPE_IDENTITY ().
- Loại bỏ các bảng cũ, bây giờ trống.
- Đưa SCHEMABINDING trở lại các chế độ xem đã lập chỉ mục và tạo lại các chỉ mục được nhóm.
Bạn có thể tránh được nhiều chế độ xem và kích hoạt nếu bạn có thể kiểm soát tất cả truy cập dữ liệu thông qua các thủ tục được lưu trữ, nhưng vì trường hợp đó rất hiếm xảy ra (và không thể tin tưởng 100%), tôi sẽ chỉ ra con đường khó hơn.
Lược đồ ban đầu
Với nỗ lực giữ cho cách tiếp cận này đơn giản nhất có thể, trong khi vẫn giải quyết nhiều trình chặn mà tôi đã đề cập trước đó trong loạt bài, hãy giả sử chúng ta có lược đồ này:
CREATE TABLE dbo.Employees
(
EmployeeID int IDENTITY(1,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName ON dbo.Employees(Name);
GO
CREATE VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO
CREATE TABLE dbo.EmployeeFile
(
EmployeeID int NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees(EmployeeID),
Notes nvarchar(max) NULL
);
GO Vì vậy, một bảng nhân sự đơn giản, với một cột IDENTITY được phân nhóm, một chỉ mục không được phân nhóm, một cột được tính toán dựa trên cột IDENTITY, một chế độ xem được lập chỉ mục và một bảng HR / dơ bẩn riêng biệt có khóa ngoại quay lại bảng nhân sự (I không nhất thiết phải khuyến khích thiết kế đó, chỉ sử dụng nó cho ví dụ này). Đây là tất cả những thứ làm cho vấn đề này trở nên phức tạp hơn so với nếu chúng ta có một bảng độc lập, độc lập.
Với lược đồ đó, chúng ta có thể có một số thủ tục được lưu trữ để thực hiện những việc như CRUD. Đây là những thứ vì lợi ích của tài liệu hơn bất cứ điều gì; Tôi sẽ thực hiện các thay đổi đối với lược đồ cơ bản sao cho việc thay đổi các thủ tục này sẽ ở mức tối thiểu. Điều này là để mô phỏng thực tế rằng việc thay đổi SQL đặc biệt từ các ứng dụng của bạn có thể không thực hiện được và có thể không cần thiết (miễn là bạn không sử dụng ORM có thể phát hiện bảng so với chế độ xem).
CREATE PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(),@Notes);
END
GO
CREATE PROCEDURE dbo.Employee_Update
@EmployeeID int,
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Get
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
CREATE PROCEDURE dbo.Employee_Delete
@EmployeeID int
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Bây giờ, hãy thêm 5 hàng dữ liệu vào các bảng ban đầu:
EXEC dbo.Employee_Add @Name = N'Employee1', @Notes = 'Employee #1 is the best'; EXEC dbo.Employee_Add @Name = N'Employee2', @Notes = 'Fewer people like Employee #2'; EXEC dbo.Employee_Add @Name = N'Employee3', @Notes = 'Jury on Employee #3 is out'; EXEC dbo.Employee_Add @Name = N'Employee4', @Notes = '#4 is moving on'; EXEC dbo.Employee_Add @Name = N'Employee5', @Notes = 'I like #5';
Bước 1 - bảng mới
Ở đây, chúng tôi sẽ tạo một cặp bảng mới, sao chép các bảng gốc ngoại trừ kiểu dữ liệu của các cột EmployeeID, hạt giống ban đầu cho cột IDENTITY và một hậu tố tạm thời trên các tên:
CREATE TABLE dbo.Employees_New
(
EmployeeID bigint IDENTITY(2147483648,1) PRIMARY KEY,
Name nvarchar(64) NOT NULL,
LunchGroup AS (CONVERT(tinyint, EmployeeID % 5))
);
GO
CREATE INDEX EmployeeName_New ON dbo.Employees_New(Name);
GO
CREATE TABLE dbo.EmployeeFile_New
(
EmployeeID bigint NOT NULL PRIMARY KEY
FOREIGN KEY REFERENCES dbo.Employees_New(EmployeeID),
Notes nvarchar(max) NULL
); Bước 2 - sửa các thông số thủ tục
Các thủ tục ở đây (và có thể là mã đặc biệt của bạn, trừ khi nó đã sử dụng kiểu số nguyên lớn hơn) sẽ cần một thay đổi rất nhỏ để trong tương lai chúng có thể chấp nhận các giá trị EmployeeID vượt quá giới hạn trên của một số nguyên. Mặc dù bạn có thể tranh luận rằng nếu bạn định thay đổi các quy trình này, bạn có thể chỉ cần hướng chúng vào các bảng mới, tôi đang cố gắng tạo ra trường hợp bạn có thể đạt được mục tiêu cuối cùng với sự xâm nhập * tối thiểu * vào mã.
ALTER PROCEDURE dbo.Employee_Update
@EmployeeID bigint, -- only change
@Name nvarchar(64),
@Notes nvarchar(max)
AS
BEGIN
SET NOCOUNT ON;
UPDATE dbo.Employees
SET Name = @Name
WHERE EmployeeID = @EmployeeID;
UPDATE dbo.EmployeeFile
SET Notes = @Notes
WHERE EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Get
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
SELECT e.EmployeeID, e.Name, e.LunchGroup, ed.Notes
FROM dbo.Employees AS e
INNER JOIN dbo.EmployeeFile AS ed
ON e.EmployeeID = ed.EmployeeID
WHERE e.EmployeeID = @EmployeeID;
END
GO
ALTER PROCEDURE dbo.Employee_Delete
@EmployeeID bigint -- only change
AS
BEGIN
SET NOCOUNT ON;
DELETE dbo.EmployeeFile WHERE EmployeeID = @EmployeeID;
DELETE dbo.Employees WHERE EmployeeID = @EmployeeID;
END
GO Bước 3 - lượt xem và trình kích hoạt
Thật không may, điều này không thể * tất cả * được thực hiện một cách âm thầm. Chúng ta có thể thực hiện hầu hết các thao tác song song và không ảnh hưởng đến việc sử dụng đồng thời, nhưng do SCHEMABINDING, chế độ xem được lập chỉ mục phải được thay đổi và chỉ mục sau đó được tạo lại.
Điều này đúng với bất kỳ đối tượng nào khác sử dụng SCHEMABINDING và tham chiếu một trong hai bảng của chúng tôi. Tôi khuyên bạn nên thay đổi nó thành chế độ xem không được lập chỉ mục khi bắt đầu hoạt động và chỉ xây dựng lại chỉ mục một lần sau khi tất cả dữ liệu đã được di chuyển, thay vì nhiều lần trong quá trình này (vì các bảng sẽ được đổi tên nhiều lần). Trên thực tế, những gì tôi sẽ làm là thay đổi chế độ xem để kết hợp các phiên bản mới và cũ của bảng Nhân viên trong suốt quá trình.
Một điều khác chúng ta cần làm là tạm thời thay đổi thủ tục lưu trữ Employee_Add để sử dụng @@ IDENTITY thay vì SCOPE_IDENTITY (). Điều này là do trình kích hoạt INSTEAD OF sẽ xử lý các cập nhật mới cho "Nhân viên" sẽ không hiển thị giá trị SCOPE_IDENTITY (). Tất nhiên, điều này giả định rằng các bảng không có sau các trình kích hoạt sẽ ảnh hưởng đến @@ IDENTITY. Hy vọng rằng bạn có thể thay đổi các truy vấn này bên trong một thủ tục được lưu trữ (nơi bạn có thể chỉ cần trỏ CHÈN vào bảng mới) hoặc mã ứng dụng của bạn không cần phải dựa vào SCOPE_IDENTITY () ngay từ đầu.
Chúng tôi sẽ thực hiện điều này trong SERIALIZABLE để không có giao dịch nào cố gắng lẻn vào trong khi các đối tượng đang hoạt động. Đây là một tập hợp phần lớn các hoạt động chỉ siêu dữ liệu, vì vậy nó sẽ nhanh chóng.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
GO
-- first, remove schemabinding from the view so we can change the base table
ALTER VIEW dbo.LunchGroupCount
--WITH SCHEMABINDING -- this will silently drop the index
-- and will temp. affect performance
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- rename the tables
EXEC sys.sp_rename N'dbo.Employees', N'Employees_Old', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile', N'EmployeeFile_Old', N'OBJECT';
GO
-- the view above will be broken for about a millisecond
-- until the following union view is created:
CREATE VIEW dbo.Employees
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Name, LunchGroup
FROM dbo.Employees_Old
UNION ALL
SELECT EmployeeID, Name, LunchGroup
FROM dbo.Employees_New;
GO
-- now the view will work again (but it will be slower)
CREATE VIEW dbo.EmployeeFile
WITH SCHEMABINDING
AS
SELECT EmployeeID = CONVERT(bigint, EmployeeID), Notes
FROM dbo.EmployeeFile_Old
UNION ALL
SELECT EmployeeID, Notes
FROM dbo.EmployeeFile_New;
GO
CREATE TRIGGER dbo.Employees_InsteadOfInsert
ON dbo.Employees
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
-- just needs to insert the row(s) into the new copy of the table
INSERT dbo.Employees_New(Name) SELECT Name FROM inserted;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfUpdate
ON dbo.Employees
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- need to cover multi-row updates, and the possibility
-- that any row may have been migrated already
UPDATE o SET Name = i.Name
FROM dbo.Employees_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Name = i.Name
FROM dbo.Employees_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.Employees_InsteadOfDelete
ON dbo.Employees
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
-- a row may have been migrated already, maybe not
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.Employees_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfInsert
ON dbo.EmployeeFile
INSTEAD OF INSERT
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT EmployeeID, Notes FROM inserted;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfUpdate
ON dbo.EmployeeFile
INSTEAD OF UPDATE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE o SET Notes = i.Notes
FROM dbo.EmployeeFile_Old AS o
INNER JOIN inserted AS i
ON o.EmployeeID = i.EmployeeID;
UPDATE n SET Notes = i.Notes
FROM dbo.EmployeeFile_New AS n
INNER JOIN inserted AS i
ON n.EmployeeID = i.EmployeeID;
COMMIT TRANSACTION;
END
GO
CREATE TRIGGER dbo.EmployeeFile_InsteadOfDelete
ON dbo.EmployeeFile
INSTEAD OF DELETE
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN deleted AS d
ON o.EmployeeID = d.EmployeeID;
DELETE n FROM dbo.EmployeeFile_New AS n
INNER JOIN deleted AS d
ON n.EmployeeID = d.EmployeeID;
COMMIT TRANSACTION;
END
GO
-- the insert stored procedure also has to be updated, temporarily
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(@@IDENTITY, @Notes);
-------^^^^^^^^^^------ change here
END
GO
COMMIT TRANSACTION; Bước 4 - Di chuyển dữ liệu cũ sang bảng mới
Chúng tôi sẽ di chuyển dữ liệu theo từng phần để giảm thiểu tác động lên cả đồng thời và nhật ký giao dịch, mượn kỹ thuật cơ bản từ một bài đăng cũ của tôi, "Chia các hoạt động xóa lớn thành nhiều phần." Chúng tôi cũng sẽ thực thi các lô này trong SERIALIZABLE, có nghĩa là bạn sẽ muốn cẩn thận với kích thước lô và tôi đã bỏ qua việc xử lý lỗi cho ngắn gọn.
CREATE TABLE #batches(EmployeeID int);
DECLARE @BatchSize int = 1; -- for this demo only
-- your optimal batch size will hopefully be larger
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
WHILE 1 = 1
BEGIN
INSERT #batches(EmployeeID)
SELECT TOP (@BatchSize) EmployeeID
FROM dbo.Employees_Old
WHERE EmployeeID NOT IN (SELECT EmployeeID FROM dbo.Employees_New)
ORDER BY EmployeeID;
IF @@ROWCOUNT = 0
BREAK;
BEGIN TRANSACTION;
SET IDENTITY_INSERT dbo.Employees_New ON;
INSERT dbo.Employees_New(EmployeeID, Name)
SELECT o.EmployeeID, o.Name
FROM #batches AS b
INNER JOIN dbo.Employees_Old AS o
ON b.EmployeeID = o.EmployeeID;
SET IDENTITY_INSERT dbo.Employees_New OFF;
INSERT dbo.EmployeeFile_New(EmployeeID, Notes)
SELECT o.EmployeeID, o.Notes
FROM #batches AS b
INNER JOIN dbo.EmployeeFile_Old AS o
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.EmployeeFile_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
DELETE o FROM dbo.Employees_Old AS o
INNER JOIN #batches AS b
ON b.EmployeeID = o.EmployeeID;
COMMIT TRANSACTION;
TRUNCATE TABLE #batches;
-- monitor progress
SELECT total = (SELECT COUNT(*) FROM dbo.Employees),
original = (SELECT COUNT(*) FROM dbo.Employees_Old),
new = (SELECT COUNT(*) FROM dbo.Employees_New);
-- checkpoint / backup log etc.
END
DROP TABLE #batches; Kết quả:
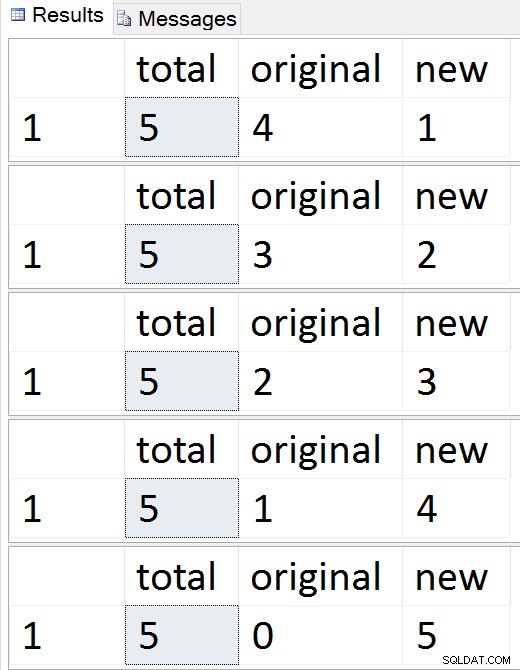 Xem các hàng di chuyển từng hàng một
Xem các hàng di chuyển từng hàng một
Tại bất kỳ thời điểm nào trong trình tự đó, bạn có thể kiểm tra các thao tác chèn, cập nhật và xóa và chúng phải được xử lý thích hợp. Sau khi quá trình di chuyển hoàn tất, bạn có thể chuyển sang phần còn lại của quá trình.
Bước 5 - Dọn dẹp
Một loạt các bước được yêu cầu để dọn dẹp các đối tượng đã được tạo tạm thời và khôi phục Nhân viên / EmployeeFile như những công dân hạng nhất thích hợp. Phần lớn các lệnh này chỉ đơn giản là các thao tác siêu dữ liệu - ngoại trừ việc tạo chỉ mục nhóm trên chế độ xem được lập chỉ mục, tất cả các lệnh này phải ngay lập tức.
SET TRANSACTION ISOLATION LEVEL SERIALIZABLE;
BEGIN TRANSACTION;
-- drop views and restore name of new tables
DROP VIEW dbo.EmployeeFile; --v
DROP VIEW dbo.Employees; -- this will drop the instead of triggers
EXEC sys.sp_rename N'dbo.Employees_New', N'Employees', N'OBJECT';
EXEC sys.sp_rename N'dbo.EmployeeFile_New', N'EmployeeFile', N'OBJECT';
GO
-- put schemabinding back on the view, and remove the union
ALTER VIEW dbo.LunchGroupCount
WITH SCHEMABINDING
AS
SELECT LunchGroup, MemberCount = COUNT_BIG(*)
FROM dbo.Employees
GROUP BY LunchGroup;
GO
-- change the procedure back to SCOPE_IDENTITY()
ALTER PROCEDURE dbo.Employee_Add
@Name nvarchar(64),
@Notes nvarchar(max) = NULL
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.Employees(Name)
VALUES(@Name);
INSERT dbo.EmployeeFile(EmployeeID, Notes)
VALUES(SCOPE_IDENTITY(), @Notes);
END
GO
COMMIT TRANSACTION;
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
-- drop the old (now empty) tables
-- and create the index on the view
-- outside the transaction
DROP TABLE dbo.EmployeeFile_Old;
DROP TABLE dbo.Employees_Old;
GO
-- only portion that is absolutely not online
CREATE UNIQUE CLUSTERED INDEX LGC ON dbo.LunchGroupCount(LunchGroup);
GO Tại thời điểm này, mọi thứ sẽ trở lại hoạt động bình thường, mặc dù bạn có thể muốn xem xét các hoạt động bảo trì điển hình sau các thay đổi lược đồ lớn, chẳng hạn như cập nhật thống kê, xây dựng lại chỉ mục hoặc loại bỏ kế hoạch khỏi bộ nhớ cache.
Kết luận
Đây là một giải pháp khá phức tạp cho một vấn đề đơn giản. Tôi hy vọng rằng tại một số điểm SQL Server có thể thực hiện những việc như thêm / xóa thuộc tính IDENTITY, xây dựng lại chỉ mục với các kiểu dữ liệu đích mới và thay đổi các cột trên cả hai phía của mối quan hệ mà không phải hy sinh mối quan hệ. Trong thời gian chờ đợi, tôi muốn biết giải pháp này có giúp được bạn không hay bạn có cách tiếp cận khác.
Xin gửi lời cảm ơn sâu sắc tới James Lupolt (@jlupoltsql) vì đã giúp kiểm tra sự tỉnh táo của tôi và đưa nó vào thử nghiệm cuối cùng trên một trong những chiếc bàn thực của riêng anh ấy. (Mọi việc diễn ra tốt đẹp. Cảm ơn James!)
-
[Phần 1 | Phần 2 | Phần 3 | Phần 4]