Bài viết này xem xét tính chọn lọc và ước tính số lượng cho các vị từ trên COUNT(*) biểu thức, như có thể thấy trong HAVING điều khoản. Các chi tiết hy vọng là thú vị trong chính họ. Chúng cũng cung cấp thông tin chi tiết về một số cách tiếp cận và thuật toán chung được sử dụng bởi công cụ ước tính bản số.
Một ví dụ đơn giản bằng cách sử dụng cơ sở dữ liệu mẫu AdventureWorks:
SELECT A.City FROM Person.[Address] AS A GROUP BY A.City HAVING COUNT_BIG(*) = 1;
Chúng tôi muốn xem cách SQL Server lấy ước tính cho vị từ trên biểu thức đếm trong HAVING mệnh đề.
Tất nhiên là HAVING mệnh đề chỉ là đường cú pháp. Chúng ta có thể viết truy vấn bằng cách sử dụng bảng dẫn xuất hoặc biểu thức bảng chung:
-- Derived table
SELECT SQ1.City
FROM
(
SELECT A.City, Expr1001 = COUNT_BIG(*)
FROM Person.[Address] AS A
GROUP BY A.City
) AS SQ1
WHERE SQ1.Expr1001 = 1;
-- CTE
WITH Grouped AS
(
SELECT A.City, Expr1001 = COUNT_BIG(*)
FROM Person.[Address] AS A
GROUP BY A.City
)
SELECT G.City
FROM Grouped AS G
WHERE G.Expr1001 = 1; Tất cả ba biểu mẫu truy vấn tạo ra cùng một kế hoạch thực thi, với các giá trị băm của kế hoạch truy vấn giống hệt nhau.
Kế hoạch sau khi thực hiện (thực tế) cho thấy một ước tính hoàn hảo cho tổng thể; tuy nhiên, ước tính cho HAVING bộ lọc mệnh đề (hoặc tương đương, trong các biểu mẫu truy vấn khác) kém:
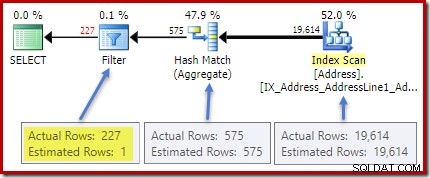
Thống kê về City cột cung cấp thông tin chính xác về số lượng các giá trị thành phố riêng biệt:
DBCC SHOW_STATISTICS ([Person.Address], City) WITH DENSITY_VECTOR;
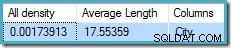
Tất cả mật độ hình là nghịch đảo của số lượng các giá trị duy nhất. Chỉ cần tính toán (1 / 0,00173913) = 575 đưa ra ước tính bản số cho tổng thể. Việc nhóm theo thành phố rõ ràng sẽ tạo ra một hàng cho mỗi giá trị riêng biệt.
Lưu ý rằng tất cả mật độ xuất phát từ véc tơ mật độ. Hãy cẩn thận để không vô tình sử dụng mật độ giá trị từ đầu ra tiêu đề thống kê của DBCC SHOW_STATISTICS . Mật độ tiêu đề chỉ được duy trì để tương thích ngược; nó không được trình tối ưu hóa sử dụng trong quá trình ước tính số lượng những ngày này.
Vấn đề
Tổng hợp giới thiệu một cột được tính toán mới cho quy trình làm việc, có nhãn Expr1001 trong kế hoạch thực hiện. Nó chứa giá trị COUNT(*) trong mỗi hàng đầu ra được nhóm:
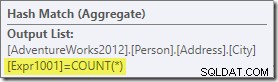
Rõ ràng là không có thông tin thống kê trong cơ sở dữ liệu về cột tính toán mới này. Mặc dù trình tối ưu hóa biết sẽ có 575 hàng, nhưng nó không biết gì về phân phối giá trị đếm trong các hàng đó.
Cũng không hẳn là không có gì:Trình tối ưu hóa biết rằng các giá trị đếm sẽ là số nguyên dương (1, 2, 3…). Tuy nhiên, đó là sự phân phối của các giá trị đếm số nguyên này trong số 575 hàng sẽ cần thiết để ước tính chính xác độ chọn lọc của COUNT(*) = 1 vị ngữ.
Người ta có thể nghĩ rằng một số loại thông tin phân phối có thể được lấy từ biểu đồ, nhưng biểu đồ chỉ cung cấp thông tin về số lượng cụ thể (trong EQ_ROWS ) cho các giá trị bước biểu đồ. Giữa các bước biểu đồ, tất cả những gì chúng ta có là một bản tóm tắt:RANGE_ROWS các hàng có DISTINCT_RANGE_ROWS các giá trị khác biệt. Đối với các bảng đủ lớn mà chúng tôi quan tâm đến chất lượng của ước tính độ chọn lọc, rất có thể phần lớn bảng được thể hiện bằng các tóm tắt nội bộ này.
Ví dụ:hai hàng đầu tiên của City biểu đồ cột là:
DBCC SHOW_STATISTICS ([Person.Address], City) WITH HISTOGRAM;

Điều này cho chúng ta biết rằng có chính xác một hàng cho "Abingdon" và 29 hàng khác sau "Abingdon" nhưng trước "Ballard", với 19 giá trị khác biệt trong dải 29 hàng đó. Truy vấn sau đây hiển thị phân phối thực tế của các hàng trong số các giá trị duy nhất trong phạm vi bước trong 29 hàng đó:
SELECT A.City, NumRows = COUNT_BIG(*) FROM Person.[Address] AS A WHERE A.City > N'Abingdon' AND A.City < N'Ballard' GROUP BY ROLLUP (A.City);

Có 29 hàng với 19 giá trị khác biệt, giống như biểu đồ cho biết. Tuy nhiên, rõ ràng là chúng tôi không có cơ sở để đánh giá tính chọn lọc của một vị từ trên cột đếm trong truy vấn đó. Ví dụ:HAVING COUNT_BIG(*) = 2 sẽ trả về 5 hàng (cho Alexandria, Altadena, Atlanta, Augsburg và Austin) nhưng chúng tôi không có cách nào để xác định điều đó từ biểu đồ.
Một dự đoán có giáo dục
Phương pháp SQL Server thực hiện là giả định rằng mỗi nhóm có nhiều khả năng nhất để chứa số hàng trung bình (trung bình) tổng thể. Đây chỉ đơn giản là số lượng chia cho số lượng các giá trị duy nhất. Ví dụ:đối với 1000 hàng có 20 giá trị duy nhất, SQL Server sẽ giả định rằng (1000/20) =50 hàng cho mỗi nhóm là giá trị có nhiều khả năng nhất.
Quay lại ví dụ ban đầu của chúng tôi, điều này có nghĩa là cột đếm được tính toán "có nhiều khả năng" chứa giá trị khoảng (19614/575) ~ = 34.1113 . Kể từ khi mật độ là nghịch đảo của số lượng giá trị duy nhất, chúng tôi cũng có thể biểu thị điều đó dưới dạng mật độ cardinality * =(19614 * 0,00173913), cho một kết quả rất giống nhau.
Phân phối
Nói rằng giá trị trung bình rất có thể chỉ đưa chúng ta đến nay. Chúng ta cũng cần xác định chính xác khả năng xảy ra như thế nào; và khả năng thay đổi như thế nào khi chúng ta di chuyển khỏi giá trị trung bình. Giả sử rằng tất cả các nhóm có chính xác 34.113 hàng trong ví dụ của chúng tôi sẽ không phải là một phỏng đoán rất "có học thức"!
SQL Server xử lý điều này bằng cách giả sử một phân phối chuẩn. Cái này có hình dạng chuông đặc trưng mà bạn có thể đã quen thuộc (hình ảnh từ mục nhập Wikipedia được liên kết):
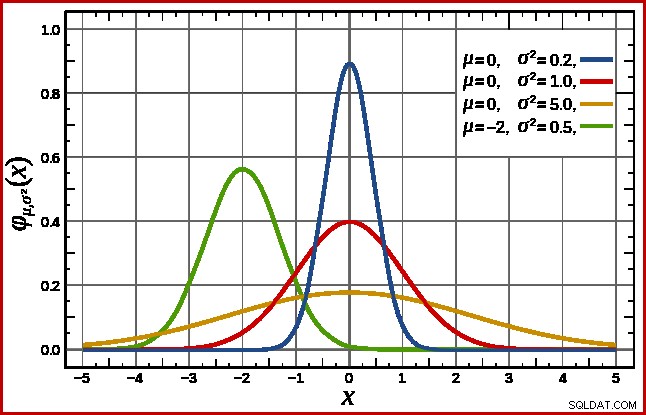
Hình dạng chính xác của phân phối chuẩn phụ thuộc vào hai tham số :nghĩa là ( µ ) và độ lệch chuẩn ( σ ). Giá trị trung bình xác định vị trí của đỉnh. Độ lệch chuẩn xác định đường cong hình chuông được "làm phẳng" như thế nào. Đường cong càng phẳng, đỉnh càng thấp và mật độ xác suất càng được phân phối trên các giá trị khác.
SQL Server có thể lấy giá trị trung bình từ thông tin thống kê như đã được lưu ý. Độ lệch chuẩn của các giá trị cột đếm được tính toán là không xác định. SQL Server ước tính nó là căn bậc hai của giá trị trung bình (với một điều chỉnh nhỏ được trình bày chi tiết sau này). Trong ví dụ của chúng tôi, điều này có nghĩa là hai tham số của phân phối chuẩn là khoảng 34.1113 và 5.84 (căn bậc hai).
Tiêu chuẩn phân phối chuẩn (đường cong màu đỏ trong sơ đồ trên) là một trường hợp đặc biệt đáng chú ý. Điều này xảy ra khi giá trị trung bình bằng 0 và độ lệch chuẩn là 1. Mọi phân phối chuẩn đều có thể được chuyển đổi thành phân phối chuẩn chuẩn bằng cách trừ giá trị trung bình và chia cho độ lệch chuẩn.
Khu vực và Khoảng thời gian
Chúng tôi quan tâm đến việc ước tính độ chọn lọc, vì vậy chúng tôi đang tìm kiếm xác suất để cột được tính toán có một giá trị nhất định (x). Xác suất này không được đưa ra bởi giá trị trục y ở trên mà bởi diện tích bên dưới đường cong ở bên trái của x.
Đối với phân phối chuẩn với trung bình 34,113 và độ lệch chuẩn 5,84, diện tích dưới đường cong bên trái của x =30 là khoảng 0,2406:
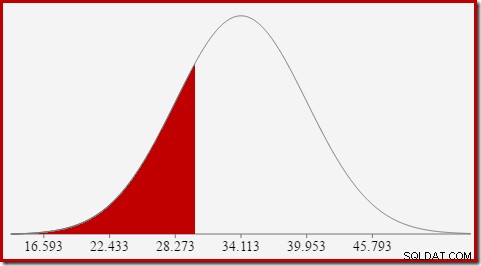
Điều này tương ứng với xác suất cột đếm được tính là nhỏ hơn hoặc bằng 30 cho truy vấn mẫu của chúng tôi.
Điều này dẫn đến ý tưởng rằng nói chung, chúng tôi không tìm kiếm xác suất của một giá trị cụ thể, mà là một khoảng thời gian . Để tìm giá trị có thể mà số lượng bằng một giá trị nguyên, chúng ta cần tính đến thực tế là các số nguyên kéo dài một khoảng có kích thước là 1. Cách chúng ta chuyển đổi một số nguyên thành một khoảng là hơi tùy ý. SQL Server xử lý điều này bằng cách cộng và trừ 0,5 để cung cấp giới hạn dưới và giới hạn trên của khoảng thời gian.
Ví dụ:để tìm xác suất giá trị đếm được tính toán bằng 30, chúng ta cần phải trừ diện tích dưới đường cong phân phối chuẩn cho (x =29,5) từ vùng cho (x =30,5). Kết quả tương ứng với lát cắt cho (29,5
Diện tích của lát màu đỏ là khoảng 0,0533 . Đối với một giá trị gần đúng đầu tiên, đây là độ chọn lọc của vị từ count =30 trong truy vấn thử nghiệm của chúng tôi.
Việc tính diện tích theo phân phối chuẩn ở bên trái của một giá trị đã cho là không đơn giản. Công thức chung được đưa ra bởi hàm phân phối tích lũy (CDF). Vấn đề là CDF không thể được biểu thị dưới dạng các hàm toán học cơ bản, vì vậy phương pháp xấp xỉ số phải được sử dụng để thay thế.
Vì tất cả các phân phối chuẩn đều có thể dễ dàng chuyển đổi thành phân phối chuẩn chuẩn (giá trị trung bình =0, độ lệch chuẩn =1), nên tất cả các phép gần đúng đều có tác dụng ước tính chuẩn bình thường. Điều này có nghĩa là chúng tôi cần chuyển đổi khoảng giới hạn của chúng tôi từ phân phối chuẩn cụ thể phù hợp với truy vấn, đến phân phối chuẩn chuẩn. Điều này được thực hiện, như đã đề cập trước đó, bằng cách trừ giá trị trung bình và chia cho độ lệch chuẩn.
Nếu bạn đã quen thuộc với Excel, bạn có thể biết các hàm NORM.DIST và NORM.S.DIST có thể tính CDF (sử dụng phương pháp xấp xỉ số) cho một phân phối chuẩn cụ thể hoặc phân phối chuẩn chuẩn.
Không có máy tính CDF nào được tích hợp sẵn trong SQL Server, nhưng chúng ta có thể dễ dàng tạo một máy tính. Cho rằng CDF cho phân phối chuẩn chuẩn là:
… Ở đâu erf là hàm lỗi:
Việc triển khai T-SQL để lấy CDF cho phân phối chuẩn chuẩn được hiển thị bên dưới. Nó sử dụng một số gần đúng cho hàm lỗi rất gần với máy chủ SQL sử dụng nội bộ:
Ví dụ, để tính CDF cho x =30 bằng cách sử dụng phân phối chuẩn cho truy vấn thử nghiệm của chúng tôi:
Lưu ý bước chuẩn hóa để chuyển sang phân phối chuẩn chuẩn. Thủ tục trả về giá trị 0,2407196…, giá trị này khớp với kết quả Excel tương ứng với bảy chữ số thập phân.
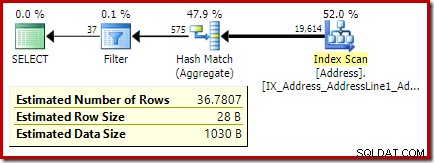
Đoạn mã sau sửa đổi truy vấn mẫu của chúng tôi để tạo ra ước tính lớn hơn cho Bộ lọc (so sánh hiện là với giá trị 32, gần với giá trị trung bình hơn nhiều so với trước đây):
Ước tính từ trình tối ưu hóa hiện là 36,7807 .
Để tính toán ước tính theo cách thủ công, trước tiên chúng ta cần giải quyết một số chi tiết cuối cùng:
Quy trình sau đây kết hợp tất cả các chi tiết trong bài viết này. Nó yêu cầu thủ tục CDF được cung cấp trước đó:
Giờ đây, chúng tôi có thể sử dụng quy trình này để tạo ước tính cho truy vấn thử nghiệm mới của chúng tôi:
Đầu ra là:
Điều này so sánh rất tốt với ước tính tổng số của trình tối ưu hóa là 36,7807.
Quy trình này có thể được sử dụng cho các khoảng đếm khác ngoài các phép thử bình đẳng. Tất cả những gì được yêu cầu là đặt
Để sử dụng điều này với quy trình của chúng tôi, chúng tôi đặt
Kết quả là 572.5964:
Một ví dụ cuối cùng sử dụng
Ước tính của trình tối ưu hóa là
Kể từ
Một lần nữa, điều này phù hợp với ước tính của trình tối ưu hóa. 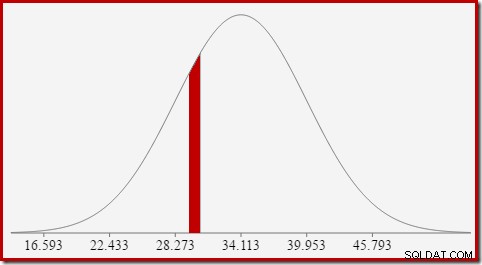
Hàm phân phối tích lũy
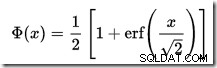
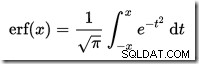
CREATE PROCEDURE dbo.GetStandardNormalCDF
(
@x float,
@cdf float OUTPUT
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
DECLARE
@sign float,
@erf float;
SET @sign = SIGN(@x);
SET @x = ABS(@x) / SQRT(2);
SET @erf = 1;
SET @erf = @erf + (0.0705230784 * @x);
SET @erf = @erf + (0.0422820123 * POWER(@x, 2));
SET @erf = @erf + (0.0092705272 * POWER(@x, 3));
SET @erf = @erf + (0.0001520143 * POWER(@x, 4));
SET @erf = @erf + (0.0002765672 * POWER(@x, 5));
SET @erf = @erf + (0.0000430638 * POWER(@x, 6));
SET @erf = POWER(@erf, -16);
SET @erf = 1 - @erf;
SET @erf = @erf * @sign;
SET @cdf = 0.5 * (1 + @erf);
END; DECLARE @cdf float;
DECLARE @x float;
-- HAVING COUNT_BIG(*) = x
SET @x = 30;
-- Normalize 30 by subtracting the mean
-- and dividing by the standard deviation
SET @x = (@x - 34.1113) / 5.84;
EXECUTE dbo.GetStandardNormalCDF
@x = @x,
@cdf = @cdf OUTPUT;
SELECT CDF = @cdf; Chi tiết và Ví dụ cuối cùng
SELECT A.City
FROM Person.[Address] AS A
GROUP BY A.City
HAVING COUNT_BIG(*) = 32;
COUNT(*) = 1 , mà không phải là chi tiết ở đây. COUNT(*) = 1 trường hợp, CE cũ sử dụng cùng một logic với CE mới (khả dụng trong SQL Server 2014 trở đi). CREATE PROCEDURE dbo.GetCountPredicateEstimate
(
@From integer,
@To integer,
@Cardinality float,
@Density float,
@Selectivity float OUTPUT,
@Estimate float OUTPUT
)
AS
BEGIN
SET NOCOUNT, XACT_ABORT ON;
BEGIN TRY
DECLARE
@Start float,
@End float,
@Distinct float,
@Mean float,
@MeanAdj float,
@Stdev float,
@NormStart float,
@NormEnd float,
@CDFStart float,
@CDFEnd float;
-- Validate input and apply defaults
IF ISNULL(@From, 0) = 0 SET @From = 1;
IF @From < 1 RAISERROR ('@From must be >= 1', 16, 1);
IF ISNULL(@Cardinality, -1) <= 0 RAISERROR('@Cardinality must be positive', 16, 1);
IF ISNULL(@Density, -1) <= 0 RAISERROR('@Density must be positive', 16, 1);
IF ISNULL(@To, 0) = 0 SET @To = CEILING(1 / @Density);
IF @To < @From RAISERROR('@To must be >= @From', 16, 1);
-- Convert integer range to interval
SET @Start = @From - 0.5;
SET @End = @To + 0.5;
-- Get number of distinct values
SET @Distinct = 1 / @Density;
-- Calculate mean
SET @Mean = @Cardinality * @Density;
-- Adjust mean;
SET @MeanAdj = @Mean * ((@Distinct - 1) / @Distinct);
-- Get standard deviation (guess)
SET @Stdev = SQRT(@MeanAdj);
-- Normalize interval
SET @NormStart = (@Start - @Mean) / @Stdev;
SET @NormEnd = (@End - @Mean) / @Stdev;
-- Calculate CDFs
EXECUTE dbo.GetStandardNormalCDF
@x = @NormStart,
@cdf = @CDFStart OUTPUT;
EXECUTE dbo.GetStandardNormalCDF
@x = @NormEnd,
@cdf = @CDFEnd OUTPUT;
-- Selectivity
SET @Selectivity =
CASE
-- Unbounded start
WHEN @From = 1 THEN @CDFEnd
-- Unbounded end
WHEN @To >= @Distinct THEN 1 - @CDFStart
-- Normal interval
ELSE @CDFEnd - @CDFStart
END;
-- Return row estimate
SET @Estimate = @Selectivity * @Distinct;
END TRY
BEGIN CATCH
DECLARE @EM nvarchar(4000) = ERROR_MESSAGE();
IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION;
RAISERROR (@EM, 16, 1);
RETURN;
END CATCH;
END; DECLARE
@Selectivity float,
@Estimate float;
EXECUTE dbo.GetCountPredicateEstimate
@From = 32,
@To = 32,
@Cardinality = 19614,
@Density = 0.00173913,
@Selectivity = @Selectivity OUTPUT,
@Estimate = @Estimate OUTPUT;
SELECT
Selectivity = @Selectivity,
Estimate = @Estimate,
Rounded = ROUND(@Estimate, 4); 
Ví dụ về khoảng bất đẳng thức
@From và @To tham số cho các ranh giới khoảng số nguyên. Để chỉ định không bị ràng buộc, hãy chuyển 0 hoặc NULL như bạn muốn. SELECT A.City
FROM Person.[Address] AS A
GROUP BY A.City
HAVING COUNT_BIG(*) < 50;

@From = NULL và @To = 49 (vì 50 bị loại trừ bởi ít hơn):DECLARE
@Selectivity float,
@Estimate float;
EXECUTE dbo.GetCountPredicateEstimate
@From = NULL,
@To = 49,
@Cardinality = 19614,
@Density = 0.00173913,
@Selectivity = @Selectivity OUTPUT,
@Estimate = @Estimate OUTPUT;
SELECT
Selectivity = @Selectivity,
Estimate = @Estimate,
Rounded = ROUND(@Estimate, 4); 
BETWEEN :SELECT A.City
FROM Person.[Address] AS A
GROUP BY A.City
HAVING COUNT_BIG(*) BETWEEN 25 AND 30;

BETWEEN là bao gồm, chúng tôi vượt qua thủ tục @From = 25 và @To = 30 . Kết quả là: