Một phần quan trọng của điều chỉnh truy vấn là hiểu các thuật toán có sẵn cho trình tối ưu hóa để xử lý các cấu trúc truy vấn khác nhau, ví dụ:lọc, tham gia, nhóm và tổng hợp cũng như cách chúng mở rộng quy mô. Kiến thức này giúp bạn chuẩn bị một môi trường vật lý tối ưu cho các truy vấn của mình, chẳng hạn như tạo các chỉ mục phù hợp. Nó cũng giúp bạn nhận biết trực quan thuật toán nào bạn sẽ thấy trong kế hoạch trong một số trường hợp nhất định, dựa trên mức độ quen thuộc của bạn với các ngưỡng mà trình tối ưu hóa sẽ chuyển từ thuật toán này sang thuật toán khác. Sau đó, khi điều chỉnh các truy vấn hoạt động kém, bạn có thể dễ dàng phát hiện ra các khu vực trong kế hoạch truy vấn nơi trình tối ưu hóa có thể đã đưa ra các lựa chọn không tối ưu, chẳng hạn như do ước tính số lượng không chính xác và thực hiện hành động để khắc phục những điều đó.
Một phần quan trọng khác của việc điều chỉnh truy vấn là suy nghĩ thấu đáo - ngoài các thuật toán có sẵn cho trình tối ưu hóa khi sử dụng các công cụ rõ ràng. Sáng tạo. Giả sử bạn có một truy vấn hoạt động kém mặc dù bạn đã sắp xếp môi trường vật lý tối ưu. Đối với các cấu trúc truy vấn mà bạn đã sử dụng, các thuật toán có sẵn cho trình tối ưu hóa là x, y và z và trình tối ưu hóa đã chọn điều tốt nhất có thể trong từng trường hợp. Tuy nhiên, truy vấn hoạt động không tốt. Bạn có thể tưởng tượng một kế hoạch lý thuyết với một thuật toán có thể mang lại một truy vấn hoạt động tốt hơn nhiều không? Nếu bạn có thể tưởng tượng ra điều đó, rất có thể bạn sẽ đạt được nó với một số lần viết lại truy vấn, có lẽ với các cấu trúc truy vấn ít rõ ràng hơn cho nhiệm vụ.
Trong loạt bài viết này, tôi tập trung vào phân nhóm và tổng hợp dữ liệu. Tôi sẽ bắt đầu bằng cách xem qua các thuật toán có sẵn cho trình tối ưu hóa khi sử dụng các truy vấn được nhóm lại. Sau đó, tôi sẽ mô tả các tình huống mà không có thuật toán hiện tại nào hoạt động tốt và hiển thị các bản ghi lại truy vấn dẫn đến hiệu suất và tỷ lệ xuất sắc.
Tôi muốn cảm ơn Craig Freedman, Vassilis Papadimos và Joe Sack, các thành viên của giao điểm của nhóm những người thông minh nhất hành tinh và nhóm các nhà phát triển SQL Server, đã trả lời các câu hỏi của tôi về tối ưu hóa truy vấn!
Đối với dữ liệu mẫu, tôi sẽ sử dụng cơ sở dữ liệu có tên là PerformanceV3. Bạn có thể tải xuống tập lệnh để tạo và điền cơ sở dữ liệu từ đây. Tôi sẽ sử dụng một bảng có tên là dbo.Orders, có 1.000.000 hàng. Bảng này có một số chỉ mục không cần thiết và có thể ảnh hưởng đến các ví dụ của tôi, vì vậy hãy chạy đoạn mã sau để loại bỏ các chỉ mục không cần thiết đó:
DROP INDEX idx_nc_sid_od_cid ON dbo.Orders; DROP INDEX idx_unc_od_oid_i_cid_eid ON dbo.Orders;
Hai chỉ mục duy nhất còn lại trên bảng này là một chỉ mục nhóm có tên idx_cl_od trên cột orderdate và một chỉ mục duy nhất không phân biệt có tên PK_Orders trên cột orderid, thực thi ràng buộc khóa chính.
EXEC sys.sp_helpindex 'dbo.Orders';
index_name index_description index_keys ----------- ----------------------------------------------------- ----------- idx_cl_od clustered located on PRIMARY orderdate PK_Orders nonclustered, unique, primary key located on PRIMARY orderid
Các thuật toán hiện có
SQL Server hỗ trợ hai thuật toán chính để tổng hợp dữ liệu:Stream Aggregate và Hash Aggregate. Với các truy vấn được nhóm, thuật toán Tổng hợp Luồng yêu cầu dữ liệu phải được sắp xếp theo thứ tự của các cột được nhóm, vì vậy bạn cần phân biệt giữa hai trường hợp. Một là Tổng hợp luồng được sắp xếp trước, ví dụ:khi dữ liệu được thu thập được sắp xếp trước từ một chỉ mục. Một thứ khác là Tổng hợp luồng không được sắp xếp thứ tự, trong đó cần thêm một bước để sắp xếp đầu vào một cách rõ ràng. Hai trường hợp này có quy mô rất khác nhau nên bạn cũng có thể coi chúng là hai thuật toán khác nhau.
Thuật toán Hash Aggregate sắp xếp các nhóm và tổng hợp của chúng trong một bảng băm. Nó không yêu cầu đầu vào phải được đặt hàng.
Với đủ dữ liệu, trình tối ưu hóa sẽ xem xét việc song song hóa công việc, áp dụng những gì được gọi là tổng hợp cục bộ-toàn cầu. Trong trường hợp như vậy, đầu vào được chia thành nhiều luồng và mỗi luồng áp dụng một trong các thuật toán nói trên để tổng hợp cục bộ tập hợp con các hàng của nó. Sau đó, tổng hợp toàn cầu sử dụng một trong các thuật toán nói trên để tổng hợp kết quả của các tổng hợp cục bộ.
Trong bài viết này, tôi tập trung vào thuật toán Tổng hợp luồng được sắp xếp trước và khả năng mở rộng quy mô của nó. Trong các phần sau của loạt bài này, tôi sẽ đề cập đến các thuật toán khác và mô tả các ngưỡng mà trình tối ưu hóa chuyển từ cái này sang cái khác và khi nào bạn nên xem xét việc viết lại truy vấn.
Tổng hợp luồng được đặt hàng trước
Đưa ra một truy vấn được nhóm với một tập hợp nhóm khác nhau (tập hợp các biểu thức mà bạn nhóm theo), thuật toán Tổng hợp Luồng yêu cầu các hàng đầu vào phải được sắp xếp theo thứ tự của các biểu thức tạo thành tập hợp nhóm. Khi thuật toán xử lý hàng đầu tiên trong một nhóm, nó sẽ khởi tạo một thành viên giữ giá trị tổng hợp trung gian với giá trị có liên quan (ví dụ:giá trị của hàng đầu tiên cho tổng giá trị MAX). Khi nó xử lý một hàng không phải đầu tiên trong nhóm, nó sẽ chỉ định thành viên đó với kết quả của một phép tính liên quan đến giá trị tổng hợp trung gian và giá trị của hàng mới (ví dụ:giá trị tối đa giữa giá trị tổng hợp trung gian và giá trị mới). Ngay sau khi bất kỳ thành viên nào của nhóm phân nhóm thay đổi giá trị của nó hoặc đầu vào được sử dụng, giá trị tổng hợp hiện tại được coi là kết quả cuối cùng cho nhóm cuối cùng.
Một cách để dữ liệu được sắp xếp theo thứ tự như thuật toán Tổng hợp Luồng cần là lấy dữ liệu được sắp xếp trước từ một chỉ mục. Bạn cần chỉ mục được xác định với các cột của nhóm nhóm làm khóa — theo bất kỳ thứ tự nào trong số đó. Bạn cũng muốn chỉ mục được bao phủ. Ví dụ:hãy xem xét truy vấn sau (chúng tôi sẽ gọi nó là Truy vấn 1):
SELECT shipperid, MAX(orderdate) AS maxorderid FROM dbo.Orders GROUP BY shipperid;
Chỉ mục lưu trữ hàng tối ưu để hỗ trợ truy vấn này sẽ là chỉ mục được xác định với shipperid làm cột khóa hàng đầu và ngày đặt hàng dưới dạng cột được bao gồm hoặc là cột khóa thứ hai:
CREATE INDEX idx_sid_od ON dbo.Orders(shipperid, orderdate);
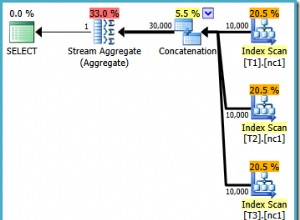
Với chỉ mục này, bạn sẽ có được kế hoạch ước tính được hiển thị trong Hình 1 (sử dụng SentryOne Plan Explorer).

Hình 1:Kế hoạch cho Truy vấn 1
Lưu ý rằng toán tử Quét chỉ mục có thuộc tính Có thứ tự:Đúng biểu thị rằng nó được yêu cầu phân phối các hàng được sắp xếp theo khóa chỉ mục. Sau đó, toán tử Tổng hợp luồng sẽ nhập các hàng được sắp xếp theo thứ tự mà nó cần. Đối với cách tính chi phí của nhà điều hành; trước khi chúng ta đạt được điều đó, trước tiên hãy nói nhanh…
Như bạn có thể đã biết, khi SQL Server tối ưu hóa một truy vấn, nó sẽ đánh giá nhiều kế hoạch ứng viên và cuối cùng chọn một kế hoạch có chi phí ước tính thấp nhất. Chi phí gói ước tính là tổng của tất cả các chi phí ước tính của nhà điều hành. Đổi lại, chi phí ước tính của mỗi nhà điều hành là tổng chi phí I / O ước tính và chi phí CPU ước tính. Đơn vị chi phí là vô nghĩa theo đúng nghĩa của nó. Mức độ liên quan của nó nằm trong sự so sánh mà trình tối ưu hóa thực hiện giữa các kế hoạch ứng viên. Đó là, các công thức tính chi phí được thiết kế với mục tiêu rằng, giữa các kế hoạch ứng viên, cái có chi phí thấp nhất (hy vọng) sẽ đại diện cho cái sẽ hoàn thành nhanh hơn. Một nhiệm vụ cực kỳ phức tạp để thực hiện chính xác!
Các công thức chi phí càng tính đến đầy đủ các yếu tố thực sự ảnh hưởng đến hiệu suất và tỷ lệ của thuật toán, thì chúng càng chính xác và càng có nhiều khả năng đưa ra các ước tính về số lượng chính xác, trình tối ưu hóa sẽ chọn phương án tối ưu. Ở mức độ nào đó, nếu bạn muốn hiểu lý do tại sao trình tối ưu hóa chọn một thuật toán so với một thuật toán khác, bạn cần hiểu hai điều chính:một là cách các thuật toán hoạt động và mở rộng quy mô, và một là mô hình chi phí của SQL Server.
Vì vậy, trở lại kế hoạch trong Hình 1; hãy thử và hiểu cách tính chi phí. Theo chính sách, Microsoft sẽ không tiết lộ các công thức tính giá nội bộ mà họ sử dụng. Khi tôi còn là một đứa trẻ, tôi đã thích thú với việc tách rời mọi thứ. Đồng hồ, đài, băng cát-xét (vâng, tôi già rồi), bạn kể tên nó. Tôi muốn biết mọi thứ được tạo ra như thế nào. Tương tự, tôi thấy giá trị trong việc thiết kế ngược các công thức vì nếu tôi quản lý để dự đoán chi phí một cách chính xác một cách hợp lý, điều đó có thể có nghĩa là tôi hiểu rất rõ về thuật toán. Trong quá trình này, bạn sẽ học hỏi được rất nhiều điều.
Truy vấn của chúng tôi nhập 1.000.000 hàng. Ngay cả với số hàng này, chi phí I / O dường như không đáng kể so với chi phí CPU, vì vậy có thể an toàn để bỏ qua nó.
Đối với chi phí CPU, bạn muốn thử và tìm ra những yếu tố nào ảnh hưởng đến nó và theo cách nào. Về mặt lý thuyết, có thể có một số yếu tố:số lượng hàng đầu vào, số lượng nhóm, số lượng của tập hợp nhóm, kiểu dữ liệu và kích thước của các thành viên của tập hợp nhóm. Vì vậy, để thử và đo lường ảnh hưởng của bất kỳ yếu tố nào trong số này, bạn muốn so sánh chi phí ước tính của hai truy vấn chỉ khác nhau về yếu tố bạn muốn đo lường. Ví dụ:để đo lường tác động của số lượng hàng đối với chi phí, hãy có hai truy vấn với số lượng hàng đầu vào khác nhau, nhưng với tất cả các khía cạnh khác đều giống nhau (số lượng nhóm, số lượng của tập hợp nhóm, v.v.). Ngoài ra, điều quan trọng là phải xác minh rằng những con số ước tính — không phải thực tế — là những con số mong muốn vì trình tối ưu hoá dựa vào những con số ước tính để tính toán chi phí.
Khi thực hiện các phép so sánh như vậy, rất tốt nếu bạn có các kỹ thuật cho phép bạn kiểm soát hoàn toàn các con số ước tính. Ví dụ:một cách đơn giản để kiểm soát số lượng hàng đầu vào ước tính là truy vấn biểu thức bảng dựa trên truy vấn TOP và áp dụng hàm tổng hợp trong truy vấn bên ngoài. Nếu bạn lo ngại rằng do việc bạn sử dụng toán tử TOP, trình tối ưu hóa sẽ áp dụng các mục tiêu hàng và những mục tiêu đó sẽ dẫn đến việc điều chỉnh chi phí ban đầu, điều này chỉ áp dụng cho các toán tử xuất hiện trong kế hoạch bên dưới toán tử Top (đối với phải), không phải ở trên (bên trái). Toán tử Tổng hợp luồng tự nhiên xuất hiện phía trên Toán tử hàng đầu trong kế hoạch vì nó nhập các hàng được lọc.
Đối với việc kiểm soát số lượng nhóm đầu ra ước tính, bạn có thể làm như vậy bằng cách sử dụng biểu thức nhóm
Để đảm bảo rằng bạn nhận được thuật toán Tổng hợp Luồng và một kế hoạch nối tiếp, bạn có thể thực hiện điều này với gợi ý truy vấn:TÙY CHỌN (NHÓM ĐƠN HÀNG, MAXDOP 1).
Bạn cũng muốn tìm hiểu xem có bất kỳ chi phí khởi động nào cho nhà điều hành hay không để bạn có thể tính đến chi phí đó trong công thức được thiết kế ngược của mình.
Hãy bắt đầu bằng cách tìm ra cách số lượng hàng đầu vào ảnh hưởng đến chi phí CPU ước tính của nhà điều hành. Rõ ràng, yếu tố này phải liên quan đến chi phí của nhà điều hành. Ngoài ra, bạn sẽ mong đợi giá mỗi hàng không đổi. Dưới đây là một số truy vấn để so sánh chỉ khác nhau về số lượng hàng đầu vào ước tính (gọi chúng là Truy vấn 2 và Truy vấn 3, tương ứng):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (200000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Hình 2 có các phần liên quan của kế hoạch ước tính cho các truy vấn này:

Hình 2:Kế hoạch cho Truy vấn 2 và Truy vấn 3
Giả sử chi phí trên mỗi hàng là không đổi, bạn có thể tính nó bằng hiệu số giữa chi phí của toán tử chia cho chênh lệch giữa các cấp số đầu vào của toán tử:
CPU cost per row = (0.125 - 0.065) / (200000 - 100000) = 0.0000006
Để xác minh rằng con số bạn nhận được thực sự không đổi và chính xác, bạn có thể thử và dự đoán chi phí ước tính trong các truy vấn với số lượng hàng đầu vào khác. Ví dụ:chi phí dự đoán với 500.000 hàng đầu vào là:
Cost for 500K input rows = <cost for 100K input rows> + 400000 * 0.0000006 = 0.065 + 0.24 = 0.305
Sử dụng truy vấn sau để kiểm tra xem dự đoán của bạn có chính xác hay không (gọi là Truy vấn 4):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (500000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1);
Phần có liên quan của kế hoạch cho truy vấn này được thể hiện trong Hình 3.
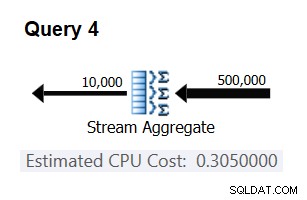
Hình 3:Kế hoạch cho Truy vấn 4
Chơi lô tô. Đương nhiên, bạn nên kiểm tra nhiều bản số đầu vào bổ sung. Với tất cả các giá trị mà tôi đã kiểm tra, luận điểm rằng có chi phí không đổi cho mỗi hàng đầu vào là 0,0000006 là đúng.
Tiếp theo, hãy thử và tìm ra cách mà số lượng nhóm ước tính ảnh hưởng đến chi phí CPU của nhà điều hành. Bạn mong đợi một số công việc của CPU là cần thiết để xử lý từng nhóm và cũng hợp lý khi mong đợi nó không đổi cho mỗi nhóm. Để kiểm tra luận điểm này và tính toán chi phí cho mỗi nhóm, bạn có thể sử dụng hai truy vấn sau, chỉ khác nhau về số lượng nhóm kết quả (gọi chúng là Truy vấn 5 và Truy vấn 6, tương ứng):
SELECT orderid % 10000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 10000 OPTION(ORDER GROUP, MAXDOP 1); SELECT orderid % 20000 AS grp, MAX(orderdate) AS maxod FROM (SELECT TOP (100000) * FROM dbo.Orders) AS D GROUP BY orderid % 20000 OPTION(ORDER GROUP, MAXDOP 1);
Các phần liên quan của kế hoạch truy vấn ước tính được thể hiện trong Hình 4.
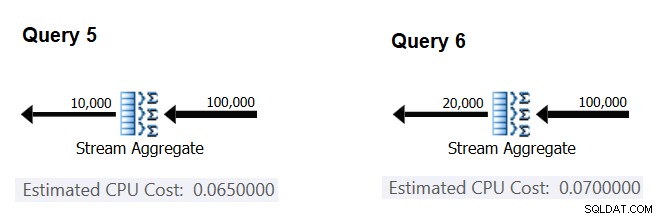
Hình 4:Kế hoạch cho Truy vấn 5 và Truy vấn 6
Tương tự như cách bạn tính toán chi phí cố định trên mỗi hàng đầu vào, bạn có thể tính chi phí cố định trên mỗi nhóm đầu ra dưới dạng chênh lệch giữa chi phí của toán tử chia cho chênh lệch giữa các cấp số đầu ra của toán tử:
CPU cost per group = (0.07 - 0.065) / (20000 - 10000) = 0.0000005
Và giống như tôi đã trình bày trước đây, bạn có thể xác minh các phát hiện của mình bằng cách dự đoán chi phí với các số lượng nhóm đầu ra khác và so sánh các con số dự đoán của bạn với các con số do trình tối ưu hóa tạo ra. Với tất cả số lượng nhóm mà tôi đã thử, chi phí dự đoán là chính xác.
Sử dụng các kỹ thuật tương tự, bạn có thể kiểm tra xem các yếu tố khác có ảnh hưởng đến chi phí của nhà điều hành hay không. Thử nghiệm của tôi cho thấy rằng bản chất của tập hợp nhóm (số biểu thức mà bạn nhóm theo), kiểu dữ liệu và kích thước của các biểu thức được nhóm không có tác động đến chi phí ước tính.
Việc còn lại là kiểm tra xem có bất kỳ chi phí khởi động có ý nghĩa nào được giả định cho nhà điều hành hay không. Nếu có, công thức hoàn chỉnh (hy vọng) để tính chi phí CPU của người vận hành phải là:
Operator CPU cost = <startup cost> + <#input rows> * 0.0000006 + <#output groups> * 0.0000005
Vì vậy, bạn có thể tính chi phí khởi động từ phần còn lại:
Startup cost =- (<#input rows> * 0.0000006 + <#output groups> * 0.0000005)
Bạn có thể sử dụng bất kỳ kế hoạch truy vấn nào từ bài viết này cho mục đích này. Ví dụ:sử dụng các số từ kế hoạch cho Truy vấn 5 được hiển thị trước đó trong Hình 4, bạn nhận được:
Startup cost = 0.065 - (100000 * 0.0000006 + 10000 * 0.0000005) = 0
Như nó sẽ xuất hiện, nhà điều hành Tổng hợp luồng không có bất kỳ chi phí khởi động nào liên quan đến CPU hoặc chi phí này thấp đến mức không được hiển thị với độ chính xác của thước đo chi phí.
Tóm lại, công thức được thiết kế ngược cho chi phí nhà điều hành Tổng hợp Luồng là:
I/O cost: negligible CPU cost: <#input rows> * 0.0000006 + <#output groups> * 0.0000005
Hình 5 mô tả quy mô chi phí của nhà điều hành Tổng hợp Dòng đối với cả số lượng hàng và số lượng nhóm.
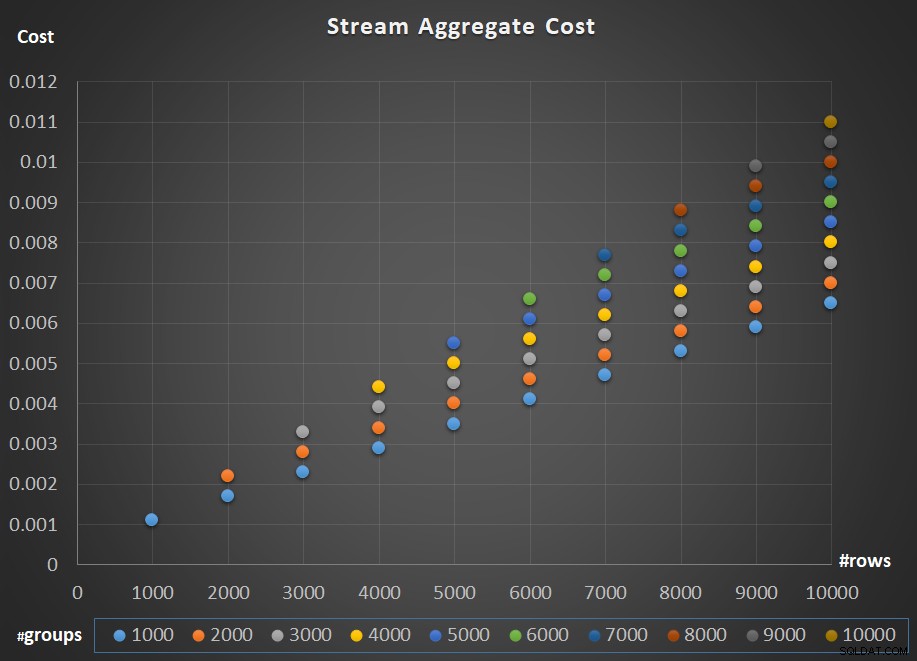
Hình 5:Biểu đồ tỷ lệ thuật toán tổng hợp Luồng
Đối với việc mở rộng quy mô của nhà điều hành; nó là tuyến tính. Trong trường hợp số lượng nhóm có xu hướng tỷ lệ thuận với số hàng, chi phí của toàn bộ nhà điều hành tăng theo cùng một hệ số khiến cả số hàng và nhóm đều tăng. Có nghĩa là tăng gấp đôi số lượng của cả hàng đầu vào và nhóm đầu vào dẫn đến việc tăng gấp đôi chi phí của toàn bộ nhà điều hành. Để biết lý do tại sao, hãy giả sử rằng chúng tôi trình bày chi phí của nhà điều hành là:
r * 0.0000006 + g * 0.0000005
Nếu bạn tăng cả số hàng và số nhóm bằng cùng một hệ số p, bạn sẽ nhận được:
pr * 0.0000006 + pg * 0.0000005 = p * (r * 0.0000006 + g * 0.0000005)
Vì vậy, nếu, đối với một số hàng và nhóm nhất định, chi phí của toán tử Tổng hợp Dòng là C, việc tăng cả số hàng và nhóm theo cùng một hệ số p dẫn đến chi phí toán tử là pC. Xem liệu bạn có thể xác minh điều này hay không bằng cách xác định các ví dụ trong biểu đồ ở Hình 5.
Trong trường hợp số lượng nhóm vẫn khá ổn định ngay cả khi số lượng hàng đầu vào tăng lên, bạn vẫn nhận được tỷ lệ tuyến tính. Bạn chỉ cần coi chi phí liên quan đến số lượng nhóm là một hằng số. Nghĩa là, nếu đối với một số hàng và nhóm nhất định, chi phí của toán tử là C =G (chi phí liên quan đến số lượng nhóm) cộng với R (chi phí liên quan đến số lượng hàng), chỉ tăng số lượng hàng theo hệ số p cho kết quả là G + pR. Trong trường hợp như vậy, đương nhiên, toàn bộ chi phí của nhà điều hành sẽ nhỏ hơn pC. Nghĩa là, tăng gấp đôi số hàng dẫn đến chi phí của toàn bộ nhà điều hành tăng lên ít hơn gấp đôi.
Trên thực tế, trong nhiều trường hợp khi bạn nhóm dữ liệu, số lượng hàng đầu vào lớn hơn đáng kể so với số lượng nhóm đầu ra. Thực tế này, kết hợp với thực tế là chi phí được phân bổ cho mỗi hàng và chi phí cho mỗi nhóm gần như giống nhau, phần chi phí của nhà điều hành được quy cho số lượng nhóm trở nên không đáng kể. Ví dụ:hãy xem kế hoạch cho Truy vấn 1 được hiển thị trước đó trong Hình 1. Trong những trường hợp như vậy, sẽ an toàn nếu chỉ nghĩ về chi phí của nhà điều hành chỉ đơn giản là điều chỉnh tuyến tính theo số lượng hàng đầu vào.
Các trường hợp đặc biệt
Có những trường hợp đặc biệt mà nhà điều hành Tổng hợp luồng hoàn toàn không cần dữ liệu được sắp xếp. Nếu bạn nghĩ về nó, thuật toán Tổng hợp Luồng có yêu cầu sắp xếp thứ tự thoải mái hơn từ đầu vào so với khi bạn cần dữ liệu được sắp xếp theo thứ tự cho mục đích trình bày, ví dụ:khi truy vấn có mệnh đề ORDER BY trình bày bên ngoài. Thuật toán Tổng hợp Dòng chỉ cần tất cả các hàng từ cùng một nhóm được sắp xếp cùng nhau. Lấy tập hợp đầu vào {5, 1, 5, 2, 1, 2}. Đối với mục đích sắp xếp thứ tự bản trình bày, tập hợp này phải được sắp xếp như sau:1, 1, 2, 2, 5, 5. Đối với mục đích tổng hợp, thuật toán Tổng hợp luồng sẽ vẫn hoạt động tốt nếu dữ liệu được sắp xếp theo thứ tự sau:5, 5, 1, 1, 2, 2. Với lưu ý này, khi bạn tính toán tổng hợp vô hướng (truy vấn có hàm tổng hợp và không có mệnh đề GROUP BY) hoặc nhóm dữ liệu theo một tập hợp nhóm trống, không bao giờ có nhiều hơn một nhóm . Không phân biệt thứ tự của các hàng đầu vào, thuật toán Tổng hợp Dòng có thể được áp dụng. Thuật toán Hash Aggregate băm dữ liệu dựa trên các biểu thức của tập hợp nhóm làm đầu vào và cả với tập hợp vô hướng và với tập hợp nhóm trống, không có đầu vào nào để băm theo. Vì vậy, cả với tổng hợp vô hướng và tổng hợp được áp dụng cho tập hợp nhóm trống, trình tối ưu hóa luôn sử dụng thuật toán Tổng hợp luồng mà không yêu cầu dữ liệu phải được sắp xếp trước. Đó ít nhất là trường hợp trong chế độ thực thi hàng, vì hiện tại (kể từ SQL Server 2017 CU4), chế độ hàng loạt chỉ khả dụng với thuật toán Hash Aggregate. Tôi sẽ sử dụng hai truy vấn sau để chứng minh điều này (gọi chúng là Truy vấn 7 và Truy vấn 8):
SELECT COUNT(*) AS numrows FROM dbo.Orders; SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY ();
Kế hoạch cho các truy vấn này được thể hiện trong Hình 6.
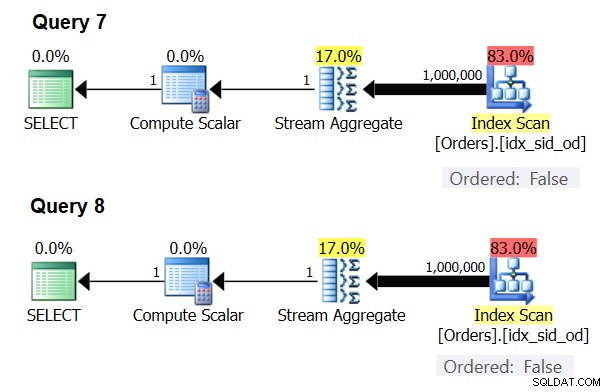
Hình 6:Kế hoạch cho Truy vấn 7 và Truy vấn 8
Thử áp dụng thuật toán Hash Aggregate trong cả hai trường hợp:
SELECT COUNT(*) AS numrows FROM dbo.Orders OPTION(HASH GROUP); SELECT COUNT(*) AS numrows FROM dbo.Orders GROUP BY () OPTION(HASH GROUP);
Trình tối ưu hóa bỏ qua yêu cầu của bạn và tạo ra các kế hoạch giống như trong Hình 6.
Câu hỏi nhanh:sự khác biệt giữa tập hợp vô hướng và tập hợp được áp dụng cho tập hợp nhóm trống là gì?
Trả lời:với tập hợp đầu vào trống, tập hợp vô hướng trả về kết quả có một hàng, trong khi tập hợp trong truy vấn có tập hợp nhóm trống trả về tập kết quả trống. Hãy thử nó:
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2;
numrows ----------- 0 (1 row affected)
SELECT COUNT(*) AS numrows FROM dbo.Orders WHERE 1 = 2 GROUP BY ();
numrows ----------- (0 rows affected)
Khi bạn hoàn tất, hãy chạy mã sau để dọn dẹp:
DROP INDEX idx_sid_od ON dbo.Orders;
Tóm tắt và thách thức
Thiết kế ngược công thức tính chi phí cho thuật toán Tổng hợp luồng là một trò chơi trẻ con. Tôi có thể vừa nói với bạn rằng công thức tính chi phí cho thuật toán Tổng hợp luồng được sắp xếp trước là @numrows * 0,0000006 + @numgroups * 0,0000005 thay vì toàn bộ bài viết để giải thích cách bạn tìm ra điều này. Tuy nhiên, điểm mấu chốt là mô tả quy trình và nguyên tắc của kỹ thuật đảo ngược, trước khi chuyển sang các thuật toán phức tạp hơn và các ngưỡng mà một thuật toán trở nên tối ưu hơn các thuật toán khác. Dạy bạn cách câu cá thay vì cho bạn ăn cá. Tôi đã học được rất nhiều và khám phá ra những điều tôi thậm chí còn chưa nghĩ đến, trong khi cố gắng thiết kế ngược các công thức tính chi phí cho các thuật toán khác nhau.
Sẵn sàng để kiểm tra kỹ năng của bạn? Nhiệm vụ của bạn, nếu bạn chọn chấp nhận nó, khó hơn nhiều so với việc thiết kế ngược lại nhà điều hành Stream Aggregate. Thiết kế ngược lại công thức tính giá của toán tử Sắp xếp nối tiếp. Điều này quan trọng đối với nghiên cứu của chúng tôi vì thuật toán Tổng hợp luồng được áp dụng cho truy vấn có tập hợp nhóm không trống, trong đó dữ liệu đầu vào không được sắp xếp trước, yêu cầu sắp xếp rõ ràng. Trong trường hợp như vậy, chi phí và quy mô của hoạt động tổng hợp phụ thuộc vào chi phí và quy mô của các toán tử Phân loại và Tổng hợp luồng kết hợp.
Nếu bạn cố gắng hoàn thành tốt việc dự đoán chi phí của toán tử Sắp xếp, bạn có thể cảm thấy như mình đã giành được quyền thêm vào chữ ký của mình “Kỹ sư đảo ngược”. Có rất nhiều kỹ sư phần mềm ra khỏi đó; nhưng bạn chắc chắn không thấy nhiều kỹ sư đảo ngược! Chỉ cần đảm bảo kiểm tra công thức của bạn cả với số lượng nhỏ và số lượng lớn; bạn có thể ngạc nhiên bởi những gì bạn tìm thấy.