Tôi đã đề cập ngắn gọn rằng dữ liệu chế độ hàng loạt được chuẩn hóa trong bài viết cuối cùng của tôi Batch Mode Bitmaps trong SQL Server. Tất cả dữ liệu trong một lô được biểu thị bằng giá trị tám byte ở định dạng chuẩn hóa cụ thể này, bất kể kiểu dữ liệu cơ bản là gì.
Tuyên bố đó chắc chắn đặt ra một số câu hỏi, đặc biệt là về cách dữ liệu có độ dài lớn hơn 8 byte có thể được lưu trữ theo cách đó. Bài viết này khám phá cách biểu diễn chuẩn hóa dữ liệu hàng loạt, giải thích lý do tại sao không phải tất cả các kiểu dữ liệu tám byte đều có thể vừa trong 64 bit và cho thấy một ví dụ về cách tất cả điều này ảnh hưởng đến hiệu suất của chế độ hàng loạt.
Demo
Tôi sẽ bắt đầu với một ví dụ cho thấy định dạng dữ liệu hàng loạt tạo ra sự khác biệt quan trọng đối với kế hoạch thực thi. Bạn sẽ cần SQL Server 2016 (trở lên) và Phiên bản dành cho nhà phát triển (hoặc tương đương) để tạo lại kết quả được hiển thị ở đây.
Điều đầu tiên chúng ta cần là một bảng bigint bao gồm các số từ 1 đến 102.400. Những con số này sẽ sớm được sử dụng để điền vào bảng columnstore (số hàng là số lượng tối thiểu cần thiết để có được một phân đoạn nén duy nhất).
DROP TABLE IF EXISTS #Numbers;
GO
CREATE TABLE #Numbers (n bigint NOT NULL PRIMARY KEY);
GO
INSERT #Numbers (n)
SELECT
n = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
n
OFFSET 0 ROWS
FETCH FIRST 102400 ROWS ONLY
OPTION (MAXDOP 1); Đẩy xuống tổng hợp thành công
Tập lệnh sau sử dụng bảng số để tạo một bảng khác có chứa các số giống nhau được bù trừ bởi một giá trị cụ thể. Bảng này sử dụng columnstore cho bộ nhớ chính của nó để tạo ra việc thực thi chế độ hàng loạt sau này.
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
@Start bigint = CONVERT(bigint, -4611686018427387905);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Chạy các truy vấn kiểm tra sau đối với bảng columnstore mới:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Phần bổ sung bên trong SUM là để tránh tràn. Bạn có thể bỏ qua WHERE các mệnh đề (để tránh một kế hoạch tầm thường) nếu bạn đang chạy SQL Server 2017.
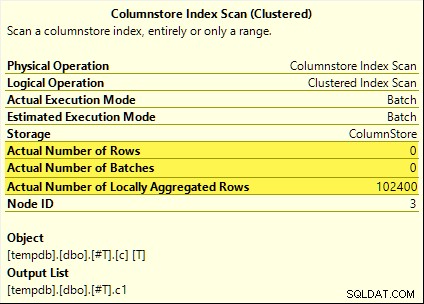
Tất cả các truy vấn đó đều được hưởng lợi từ việc đẩy xuống tổng hợp. Tổng hợp được tính tại Columnstore Index Scan thay vì chế độ hàng loạt Hash Aggregate nhà điều hành. Các kế hoạch sau khi thực hiện hiển thị không có hàng nào được phát ra bởi quá trình quét. Tất cả 102.400 hàng được "tổng hợp cục bộ".
SUM kế hoạch được hiển thị dưới đây như một ví dụ:

Đẩy xuống tổng hợp không thành công
Bây giờ thả xuống, sau đó tạo lại bảng kiểm tra columnstore với độ lệch giảm đi một:
DROP TABLE IF EXISTS #T;
GO
CREATE TABLE #T (c1 bigint NOT NULL);
GO
DECLARE
-- Note this value has decreased by one
@Start bigint = CONVERT(bigint, -4611686018427387906);
INSERT #T (c1)
SELECT
c1 = @Start + N.n
FROM #Numbers AS N;
GO
CREATE CLUSTERED COLUMNSTORE INDEX c ON #T
WITH (MAXDOP = 1); Chạy chính xác các truy vấn kiểm tra tổng hợp kéo xuống giống như trước đây:
SELECT
c = COUNT_BIG(*)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
m = MAX(T.c1)
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
SELECT
s = SUM(T.c1 + CONVERT(bigint, 4611686018427387904))
FROM #T AS T
WHERE 1 = (SELECT 1) -- Avoid trivial plan
OPTION (MAXDOP 1);
Lần này, chỉ COUNT_BIG tổng hợp đạt được tổng hợp đẩy xuống (chỉ dành cho SQL Server 2017). MAX và SUM uẩn không. Đây là SUM mới kế hoạch để so sánh với kế hoạch từ thử nghiệm đầu tiên:

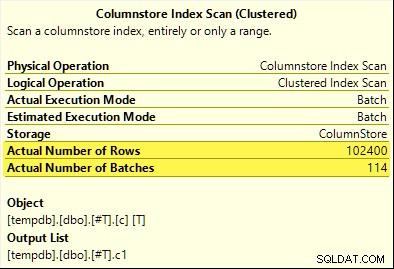
Tất cả 102.400 hàng (trong 114 lô) được phát ra bởi Columnstore Index Scan , được xử lý bởi Compute Scalar và được gửi đến Hash Aggregate .
Tại sao sự khác biệt? Tất cả những gì chúng tôi làm là bù lại dải số được lưu trữ trong bảng columnstore bằng một!
Giải thích
Tôi đã đề cập trong phần giới thiệu rằng không phải tất cả các kiểu dữ liệu tám byte đều có thể phù hợp với 64 bit. Sự thật này quan trọng bởi vì nhiều tính năng tối ưu hóa hiệu suất chế độ cột và chế độ hàng loạt chỉ hoạt động với dữ liệu có kích thước 64 bit. Tổng hợp đẩy xuống là một trong những điều đó. Có nhiều tính năng hiệu suất khác (không phải tất cả đều được ghi lại) hoạt động tốt nhất (hoặc hoàn toàn) chỉ khi dữ liệu vừa với 64 bit.
Trong ví dụ cụ thể của chúng tôi, tổng hợp kéo xuống bị tắt cho một phân đoạn trong cột khi nó chứa thậm chí một giá trị dữ liệu không phù hợp với 64 bit. SQL Server có thể xác định điều này từ siêu dữ liệu giá trị tối thiểu và tối đa được liên kết với từng phân đoạn mà không cần kiểm tra tất cả dữ liệu. Mỗi phân đoạn được đánh giá riêng biệt.
Tổng hợp kéo xuống vẫn hoạt động cho COUNT_BIG chỉ tổng hợp trong lần thử nghiệm thứ hai. Đây là một tối ưu hóa được thêm vào một số thời điểm trong SQL Server 2017 (các thử nghiệm của tôi đã được chạy trên CU16). Hợp lý là không tắt tính năng đẩy xuống tổng hợp khi chúng ta chỉ đếm hàng và không thực hiện bất kỳ điều gì với các giá trị dữ liệu cụ thể. Tôi không thể tìm thấy bất kỳ tài liệu nào về cải tiến này, nhưng điều đó không quá bất thường hiện nay.
Lưu ý thêm, tôi nhận thấy rằng SQL Server 2017 CU16 cho phép tổng hợp kéo xuống cho các loại dữ liệu không được hỗ trợ trước đây real , float , datetimeoffset và numeric với độ chính xác lớn hơn 18 - khi dữ liệu vừa với 64 bit. Điều này cũng không có tài liệu tại thời điểm viết bài.
Được, nhưng tại sao?
Bạn có thể đặt câu hỏi rất hợp lý:Tại sao một bộ bigint lại giá trị kiểm tra dường như phù hợp với 64 bit nhưng giá trị kia thì không?
Nếu bạn đoán lý do có liên quan đến NULL , hãy đánh dấu cho chính mình. Mặc dù cột của bảng kiểm tra được xác định là NOT NULL , SQL Server sử dụng cùng một bố cục dữ liệu chuẩn hóa cho bigint dữ liệu có cho phép null hay không. Có những lý do giải thích cho điều này và tôi sẽ giải nén từng chút một.
Hãy để tôi bắt đầu với một số quan sát:
- Mỗi giá trị cột trong một lô được lưu trữ trong chính xác tám byte (64 bit) bất kể kiểu dữ liệu cơ bản là gì. Bố cục có kích thước cố định này giúp mọi thứ trở nên dễ dàng và nhanh chóng hơn. Thực thi chế độ hàng loạt là tất cả về tốc độ.
- Một lô có kích thước 64KB và chứa từ 64 đến 900 hàng, tùy thuộc vào số lượng cột được chiếu. Điều này có ý nghĩa khi kích thước dữ liệu cột được cố định ở 64 bit. Nhiều cột hơn có nghĩa là ít hàng hơn có thể phù hợp với mỗi lô 64KB.
- Không phải tất cả các kiểu dữ liệu SQL Server đều có thể phù hợp với 64 bit, ngay cả về nguyên tắc. Một chuỗi dài (để lấy một ví dụ) thậm chí có thể không phù hợp với toàn bộ lô 64KB (nếu điều đó được cho phép), chứ đừng nói đến một mục nhập 64 bit.
SQL Server giải quyết vấn đề cuối cùng này bằng cách lưu trữ một tham chiếu 8 byte thành dữ liệu lớn hơn 64 bit. Giá trị dữ liệu 'lớn' được lưu trữ ở nơi khác trong bộ nhớ. Bạn có thể gọi cách sắp xếp này là bộ nhớ "hàng không" hoặc "hàng hết đợt". Về mặt nội bộ, nó được gọi là dữ liệu sâu .
Bây giờ, các kiểu dữ liệu tám byte không thể phù hợp với 64 bit khi có thể null. Lấy bigint NULL Ví dụ . Dải dữ liệu không phải null có thể yêu cầu 64 bit đầy đủ và chúng tôi vẫn cần một bit khác để chỉ ra null hay không.
Giải quyết vấn đề
Giải pháp sáng tạo và hiệu quả cho những thách thức này là đặt trước bit quan trọng thấp nhất (LSB) của giá trị 64 bit dưới dạng cờ. Cờ cho biết trong lô lưu trữ dữ liệu khi LSB rõ ràng (đặt thành không). Khi LSB được đặt (thành một), nó có thể có nghĩa là một trong hai điều:
- Giá trị là null; hoặc
- Giá trị được lưu trữ theo đợt (đó là dữ liệu sâu).
Hai trường hợp này được phân biệt bởi trạng thái của 63 bit còn lại. Khi chúng tất cả đều không , giá trị là NULL . Nếu không, 'giá trị' là một con trỏ đến dữ liệu sâu được lưu trữ ở nơi khác.
Khi được xem dưới dạng số nguyên, việc đặt LSB có nghĩa là con trỏ đến dữ liệu sâu sẽ luôn lẻ những con số. Các giá trị rỗng được biểu diễn bằng số (lẻ) 1 (tất cả các bit khác đều bằng 0). Dữ liệu trong lô được biểu thị bằng chẵn vì LSB bằng không.
Điều này không nghĩa là SQL Server chỉ có thể lưu trữ các số chẵn trong một lô! Nó chỉ có nghĩa là đại diện chuẩn hóa của các giá trị cột bên dưới sẽ luôn có LSB bằng 0 khi được lưu trữ “trong lô”. Điều này sẽ có ý nghĩa hơn trong giây lát.
Chuẩn hóa Dữ liệu Hàng loạt
Quá trình chuẩn hóa được thực hiện theo nhiều cách khác nhau, tùy thuộc vào kiểu dữ liệu cơ bản. Đối với bigint quy trình là:
- Nếu dữ liệu null , lưu trữ giá trị 1 (chỉ bộ LSB).
- Nếu giá trị có thể được biểu diễn bằng 63 bit , dịch chuyển tất cả các bit sang trái và bằng không LSB. Khi xem giá trị dưới dạng số nguyên, điều này có nghĩa là nhân đôi giá trị. Ví dụ:
bigintgiá trị 1 được chuẩn hóa thành giá trị 2. Trong hệ nhị phân, đó là bảy byte tất cả bằng không theo sau là00000010. LSB bằng 0 cho biết đây là dữ liệu được lưu trữ nội tuyến. Khi SQL Server cần giá trị gốc, nó sẽ dịch sang phải giá trị 64 bit theo một vị trí (loại bỏ cờ LSB). - Nếu giá trị không thể được biểu thị bằng 63 bit, giá trị được lưu trữ theo đợt dưới dạng dữ liệu sâu . Con trỏ trong lô có bộ LSB (đặt nó thành một số lẻ).
Quá trình kiểm tra nếu một bigint giá trị có thể vừa với 63 bit là:
- Lưu trữ *
bigintthô giá trị trong thanh ghi bộ xử lý 64-bitr8. - Lưu trữ gấp đôi giá trị của
r8trong đăng kýrax. - Dịch chuyển các bit của
raxmột nơi ở bên phải. - Kiểm tra xem các giá trị trong
raxvàr8ngang nhau.
* Lưu ý rằng giá trị thô không thể được xác định một cách đáng tin cậy cho tất cả các kiểu dữ liệu bằng cách chuyển đổi T-SQL sang kiểu nhị phân. Kết quả T-SQL có thể có thứ tự byte khác và cũng có thể chứa siêu dữ liệu, ví dụ:time độ chính xác phân số giây.
Nếu bài kiểm tra ở bước 4 vượt qua, chúng tôi biết giá trị có thể được nhân đôi và sau đó giảm một nửa trong vòng 64 bit - giữ nguyên giá trị ban đầu.
Dải ô đã giảm
Kết quả của tất cả những điều này là phạm vi bigint các giá trị có thể được lưu trữ theo lô bị giảm xuống bởi một bit (vì LSB không khả dụng). Các phạm vi bao gồm sau của bigint các giá trị sẽ được lưu trữ theo đợt dưới dạng dữ liệu sâu :
- -4,611,686,018,427,387,905 đến -9,223,372,036,854,775,808
- +4,611,686,018,427,387,904 đến +9,223,372,036,854,775,807
Đổi lại việc chấp nhận rằng bigint này giới hạn phạm vi, chuẩn hóa cho phép SQL Server lưu trữ (hầu hết) bigint giá trị, null và tham chiếu dữ liệu sâu theo lô . Điều này đơn giản hơn và tiết kiệm không gian hơn rất nhiều so với việc có các cấu trúc riêng biệt cho tính khả thi và tham chiếu dữ liệu sâu. Nó cũng làm cho việc xử lý dữ liệu hàng loạt với các lệnh của bộ xử lý SIMD dễ dàng hơn rất nhiều.
Chuẩn hóa các kiểu dữ liệu khác
SQL Server chứa chuẩn hóa mã cho từng loại dữ liệu được hỗ trợ bởi thực thi chế độ hàng loạt. Mỗi quy trình được tối ưu hóa để xử lý bố cục nhị phân đến một cách hiệu quả và chỉ tạo dữ liệu sâu khi cần thiết. Quá trình chuẩn hóa luôn dẫn đến việc LSB được dành riêng để chỉ ra dữ liệu rỗng hoặc dữ liệu sâu, nhưng cách bố trí của 63 bit còn lại khác nhau cho mỗi loại dữ liệu.
Luôn có trong lô
Dữ liệu chuẩn hóa cho các loại dữ liệu sau luôn được lưu trữ theo lô vì chúng không bao giờ cần nhiều hơn 63 bit:
-
date -
time(n)- được thay đổi tỷ lệ nội bộ thànhtime(7) -
datetime2(n)- được thay đổi tỷ lệ nội bộ thànhdatetime2(7) -
integer -
smallint -
tinyint -
bit- sử dụngtinyintthực hiện. -
smalldatetime -
datetime -
real -
float -
smallmoney
Tùy thuộc vào
Các loại dữ liệu sau có thể được lưu trữ dữ liệu theo lô hoặc dữ liệu sâu tùy thuộc vào giá trị dữ liệu:
-
bigint- như đã mô tả trước đây. -
money- cùng một phạm vi trong lô vớibigintnhưng chia cho 10.000. -
numeric/decimal- 18 chữ số thập phân trở xuống trong lô bất kể của độ chính xác đã khai báo. Ví dụ:decimal(38,9)giá trị -999999999.999999999 có thể được biểu thị dưới dạng số nguyên 8 byte -999999999999999999 (f21f494c589c0001hex), có thể được nhân đôi thành -1999999999999999998 (e43e9298b1380002hex) có thể đảo ngược trong vòng 64 bit. SQL Server biết điểm thập phân đi từ đâu trong thang kiểu dữ liệu. -
datetimeoffset(n)- hàng loạt nếu giá trị thời gian chạy sẽ phù hợp vớidatetimeoffset(2)bất chấp về độ chính xác giây phân số được khai báo. -
timestamp- định dạng bên trong khác với màn hình. Ví dụ:timestampđược hiển thị từ T-SQL dưới dạng0x000000000099449Ađược trình bày bên trong dưới dạng9a449900 00000000(trong hệ lục phân). Giá trị này được lưu trữ dưới dạng dữ liệu sâu vì nó không vừa với 64 bit khi nhân đôi (dịch sang trái một bit).
Dữ liệu luôn sâu
Các thông tin sau luôn được lưu trữ dưới dạng dữ liệu sâu (ngoại trừ giá trị rỗng) :
-
uniqueidentifier -
varbinary(n)- bao gồm(max) -
binary -
char/varchar(n)/nchar/nvarchar(n)/sysnamebao gồm(max)- những loại này cũng có thể sử dụng từ điển (nếu có). -
text/ntext/image/xml- sử dụngvarbinary(n)thực hiện.
Để rõ ràng, giá trị rỗng cho tất cả các loại dữ liệu tương thích với chế độ hàng loạt được lưu trữ theo đợt dưới dạng giá trị đặc biệt "một".
Kết luận
Bạn có thể mong đợi để tận dụng tốt nhất các tối ưu hóa chế độ cột và chế độ hàng loạt có sẵn khi sử dụng các loại dữ liệu và giá trị phù hợp với 64 bit. Bạn cũng sẽ có cơ hội tốt nhất để hưởng lợi từ các cải tiến sản phẩm gia tăng theo thời gian, chẳng hạn như các cải tiến mới nhất đối với tổng hợp kéo xuống được ghi chú trong văn bản chính. Không phải tất cả các lợi thế về hiệu suất sẽ hiển thị trong các kế hoạch thực hiện, hoặc thậm chí được ghi lại. Tuy nhiên, sự khác biệt có thể cực kỳ đáng kể.
Tôi cũng nên đề cập rằng dữ liệu được chuẩn hóa khi nhà điều hành kế hoạch thực thi chế độ hàng cung cấp dữ liệu cho phụ huynh ở chế độ hàng loạt hoặc khi quét không phải cửa hàng cột tạo ra hàng loạt (chế độ hàng loạt trên cửa hàng hàng). Có một bộ điều hợp hàng-lô vô hình gọi quy trình chuẩn hóa thích hợp trên mỗi giá trị cột trước khi thêm nó vào lô. Việc tránh các loại dữ liệu có quá trình chuẩn hóa phức tạp và lưu trữ dữ liệu sâu cũng có thể mang lại lợi ích về hiệu suất ở đây.