Có nhiều phương pháp để xem xét các truy vấn hoạt động kém trong SQL Server, đặc biệt là Cửa hàng truy vấn, Sự kiện mở rộng và chế độ xem quản lý động (DMV). Mỗi lựa chọn đều có ưu và nhược điểm. Sự kiện mở rộng cung cấp dữ liệu về việc thực thi từng truy vấn, trong khi Cửa hàng truy vấn và DMV tổng hợp dữ liệu hiệu suất. Để sử dụng Cửa hàng truy vấn và Sự kiện mở rộng, bạn phải định cấu hình chúng trước - bật Cửa hàng truy vấn cho (các) cơ sở dữ liệu của bạn hoặc thiết lập phiên XE và khởi động nó. Dữ liệu DMV luôn có sẵn, vì vậy, đây thường là phương pháp dễ dàng nhất để có được cái nhìn đầu tiên nhanh chóng về hiệu suất truy vấn. Đây là lúc các truy vấn DMV của Glenn trở nên hữu ích - trong tập lệnh của anh ấy, anh ấy có nhiều truy vấn mà bạn có thể sử dụng để tìm các truy vấn hàng đầu cho ví dụ dựa trên CPU, I / O logic và thời lượng. Nhắm mục tiêu các truy vấn tiêu tốn tài nguyên cao nhất thường là một khởi đầu tốt khi khắc phục sự cố, nhưng chúng ta không thể quên về kịch bản "chết bởi một nghìn vết cắt" - truy vấn hoặc tập hợp các truy vấn chạy RẤT thường xuyên - có thể hàng trăm hoặc hàng nghìn lần a phút. Glenn có một truy vấn trong bộ của anh ấy liệt kê các truy vấn hàng đầu cho cơ sở dữ liệu dựa trên số lượng thực thi, nhưng theo kinh nghiệm của tôi, nó không cung cấp cho bạn bức tranh toàn cảnh về khối lượng công việc của bạn.
DMV chính được sử dụng để xem xét các chỉ số hiệu suất truy vấn là sys.dm_exec_query_stats. Dữ liệu bổ sung dành riêng cho các thủ tục được lưu trữ (sys.dm_exec_procedure_stats), các chức năng (sys.dm_exec_ Chức năng_stats) và trình kích hoạt (sys.dm_exec_trigger_stats) cũng có sẵn, nhưng hãy xem xét khối lượng công việc không hoàn toàn là các thủ tục, hàm và trình kích hoạt được lưu trữ. Hãy xem xét một khối lượng công việc hỗn hợp có một số truy vấn đặc biệt hoặc có thể là hoàn toàn đột xuất.
Tình huống mẫu
Mượn và điều chỉnh mã từ một bài trước, Kiểm tra Tác động Hiệu suất của Khối lượng Công việc Adhoc, trước tiên chúng tôi sẽ tạo hai thủ tục được lưu trữ. Đầu tiên, dbo.RandomSelects, tạo và thực thi một câu lệnh đặc biệt và câu thứ hai, dbo.SPRandomSelects, tạo và thực thi một truy vấn được tham số hóa.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT c.CustomerID, c.AccountOpenedDate, COUNT(ct.CustomerTransactionID)
FROM Sales.Customers c
JOIN Sales.CustomerTransactions ct
ON c.CustomerID = ct.CustomerID
WHERE c.CustomerName = @ConcatString
GROUP BY c.CustomerID, c.AccountOpenedDate;
SELECT @RowLoop = @RowLoop + 1;
END
GO Bây giờ, chúng tôi sẽ thực thi cả hai quy trình được lưu trữ 1000 lần, sử dụng cùng một phương pháp được nêu trong bài đăng trước của tôi với tệp .cmd gọi tệp .sql với các câu lệnh sau:
Nội dung tệp Adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 1000;
Nội dung tệp parameterized.sql:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 1000;
Cú pháp mẫu trong tệp .cmd gọi tệp .sql:
sqlcmd -S WIN2016\SQL2017 -i"Adhoc.sql" exit
Nếu chúng tôi sử dụng một biến thể của truy vấn Thời gian công nhân hàng đầu của Glenn để xem xét các truy vấn hàng đầu dựa trên thời gian của công nhân (CPU):
-- Get top total worker time queries for entire instance (Query 44) (Top Worker Time Queries) SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.total_worker_time AS [Total Worker Time], qs.execution_count AS [Execution Count], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY qs.total_worker_time DESC OPTION (RECOMPILE);
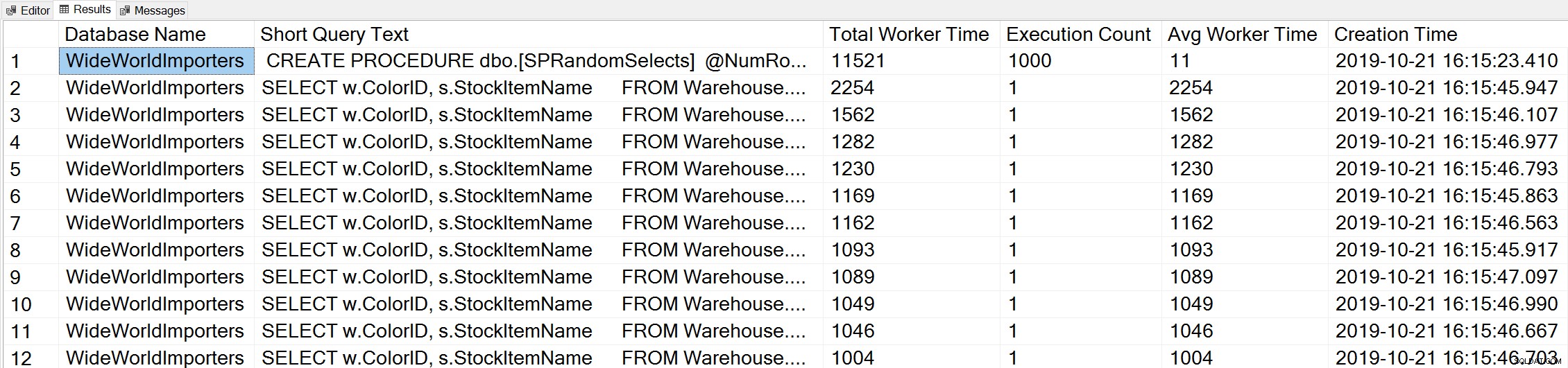
Chúng tôi xem câu lệnh từ thủ tục được lưu trữ của chúng tôi là truy vấn thực thi với số lượng CPU tích lũy cao nhất.
Nếu chúng tôi chạy một biến thể của truy vấn Số lượng thực thi truy vấn của Glenn dựa trên cơ sở dữ liệu WideWorldImporters:
USE [WideWorldImporters]; GO -- Get most frequently executed queries for this database (Query 57) (Query Execution Counts) SELECT TOP(50) LEFT(t.[text], 50) AS [Short Query Text], qs.execution_count AS [Execution Count], qs.total_logical_reads AS [Total Logical Reads], qs.total_logical_reads/qs.execution_count AS [Avg Logical Reads], qs.total_worker_time AS [Total Worker Time], qs.total_worker_time/qs.execution_count AS [Avg Worker Time], qs.total_elapsed_time AS [Total Elapsed Time], qs.total_elapsed_time/qs.execution_count AS [Avg Elapsed Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp WHERE t.dbid = DB_ID() ORDER BY qs.execution_count DESC OPTION (RECOMPILE);
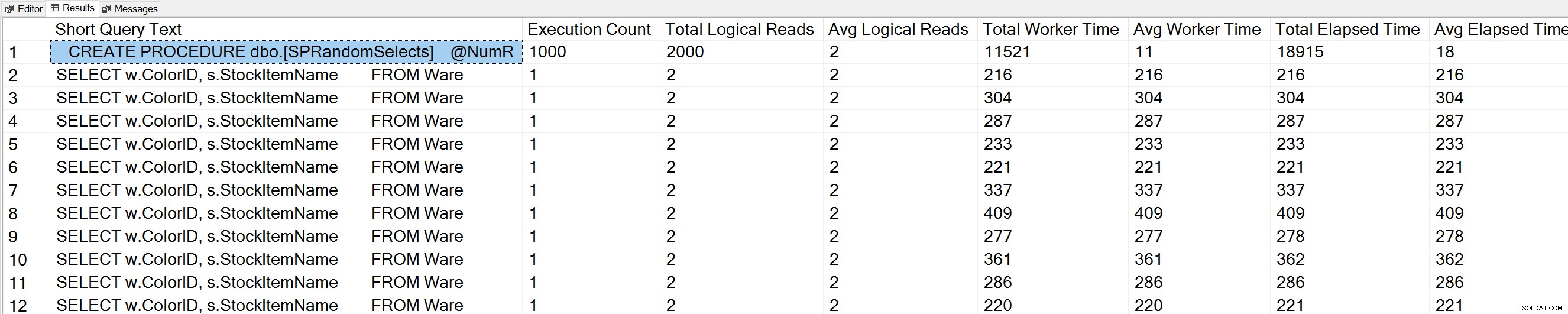
Chúng tôi cũng thấy tuyên bố thủ tục được lưu trữ của chúng tôi ở đầu danh sách.
Nhưng truy vấn đặc biệt mà chúng tôi đã thực thi, mặc dù nó có các giá trị chữ khác nhau, về cơ bản là giống nhau câu lệnh được thực thi lặp đi lặp lại, như chúng ta có thể thấy bằng cách nhìn vào query_hash:
SELECT TOP(50) DB_NAME(t.[dbid]) AS [Database Name], REPLACE(REPLACE(LEFT(t.[text], 255), CHAR(10),''), CHAR(13),'') AS [Short Query Text], qs.query_hash AS [query_hash], qs.creation_time AS [Creation Time] FROM sys.dm_exec_query_stats AS qs WITH (NOLOCK) CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS t CROSS APPLY sys.dm_exec_query_plan(plan_handle) AS qp ORDER BY [Short Query Text];
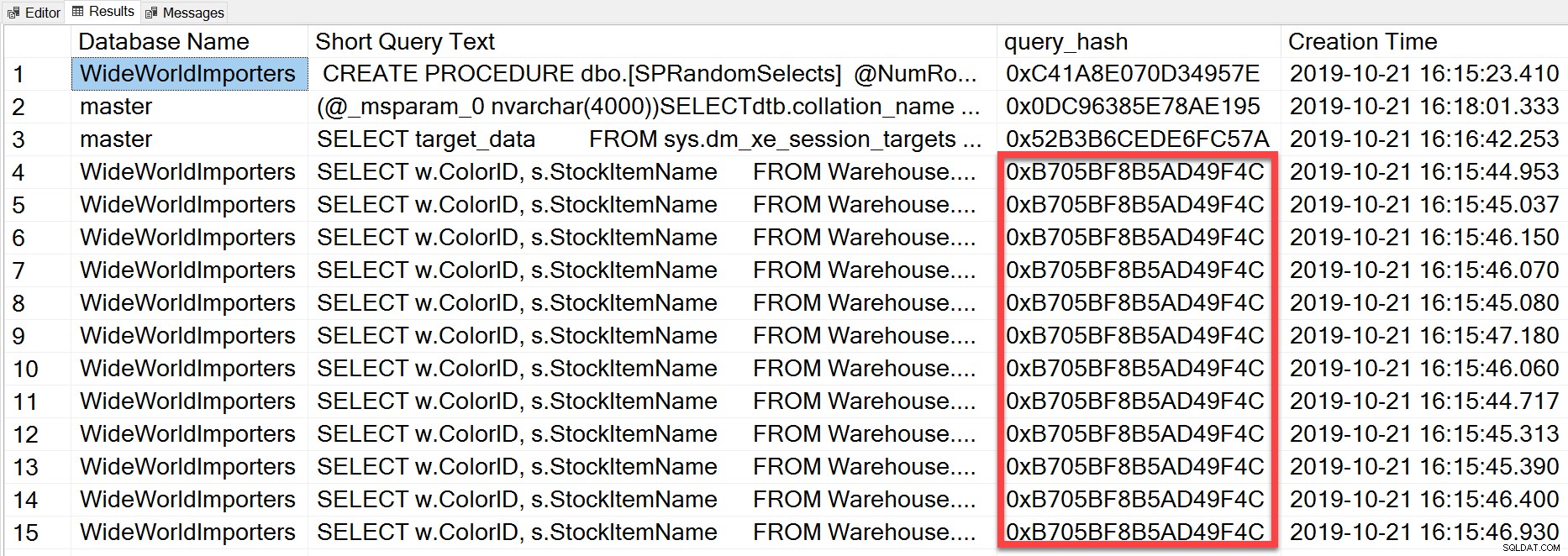
Query_hash đã được thêm vào SQL Server 2008 và dựa trên cây của các toán tử logic được tạo bởi Trình tối ưu hoá Truy vấn cho văn bản câu lệnh. Các truy vấn có văn bản câu lệnh tương tự tạo ra cùng một cây các toán tử logic sẽ có cùng một query_hash, ngay cả khi các giá trị chữ trong vị từ truy vấn khác nhau. Mặc dù các giá trị chữ có thể khác nhau, nhưng các đối tượng và bí danh của chúng phải giống nhau, cũng như gợi ý truy vấn và có thể là các tùy chọn SET. Thủ tục lưu trữ RandomSelects tạo ra các truy vấn với các giá trị chữ khác nhau:
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1005451175198';
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = '1006416358897'; Nhưng mọi thực thi đều có cùng một giá trị cho query_hash, 0xB705BF8B5AD49F4C. Để hiểu mức độ thường xuyên của một truy vấn đặc biệt - và những truy vấn giống nhau về query_hash - thực thi, chúng ta phải nhóm theo thứ tự query_hash trên số lượng đó, thay vì xem xét thực thi_count trong sys.dm_exec_query_stats (thường hiển thị một giá trị của 1).
Nếu chúng tôi thay đổi ngữ cảnh thành cơ sở dữ liệu WideWorldImporters và tìm kiếm các truy vấn hàng đầu dựa trên số lượng thực thi, nơi chúng tôi nhóm trên query_hash, bây giờ chúng tôi có thể thấy cả thủ tục được lưu trữ và truy vấn đặc biệt của chúng tôi:
;WITH qh AS
(
SELECT TOP (25) query_hash, COUNT(*) AS COUNT
FROM sys.dm_exec_query_stats
GROUP BY query_hash
ORDER BY COUNT(*) DESC
),
qs AS
(
SELECT obj = COALESCE(ps.object_id, fs.object_id, ts.object_id),
db = COALESCE(ps.database_id, fs.database_id, ts.database_id),
qs.query_hash, qs.query_plan_hash, qs.execution_count,
qs.sql_handle, qs.plan_handle
FROM sys.dm_exec_query_stats AS qs
INNER JOIN qh ON qs.query_hash = qh.query_hash
LEFT OUTER JOIN sys.dm_exec_procedure_stats AS [ps]
ON [qs].[sql_handle] = [ps].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_function_stats AS [fs]
ON [qs].[sql_handle] = [fs].[sql_handle]
LEFT OUTER JOIN sys.dm_exec_trigger_stats AS [ts]
ON [qs].[sql_handle] = [ts].[sql_handle]
)
SELECT TOP (50)
OBJECT_NAME(qs.obj, qs.db),
query_hash,
query_plan_hash,
SUM([qs].[execution_count]) AS [ExecutionCount],
MAX([st].[text]) AS [QueryText]
FROM qs
CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st]
CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp]
GROUP BY qs.obj, qs.db, qs.query_hash, qs.query_plan_hash
ORDER BY ExecutionCount DESC;

Lưu ý:DMV sys.dm_exec_osystem_stats đã được thêm vào SQL Server 2016. Việc chạy truy vấn này trên SQL Server 2014 trở về trước yêu cầu xóa tham chiếu đến DMV này.
Kết quả này cung cấp sự hiểu biết toàn diện hơn về những truy vấn nào thực sự thực thi thường xuyên nhất, vì nó tổng hợp dựa trên query_hash, chứ không chỉ đơn giản là xem giá trị thực thi trong sys.dm_exec_query_stats, có thể có nhiều mục nhập cho cùng một query_hash khi các giá trị theo nghĩa đen khác nhau. đã sử dụng. Đầu ra truy vấn cũng bao gồm query_plan_hash, có thể khác đối với các truy vấn có cùng query_hash. Thông tin bổ sung này rất hữu ích khi đánh giá hiệu suất kế hoạch cho một truy vấn. Trong ví dụ trên, mọi truy vấn đều có cùng query_plan_hash, 0x299275DD475C4B17, chứng tỏ rằng ngay cả với các giá trị đầu vào khác nhau, Trình tối ưu hóa truy vấn tạo ra cùng một kế hoạch - nó ổn định. Khi tồn tại nhiều giá trị query_plan_hash cho cùng một query_hash, thì sự thay đổi của kế hoạch sẽ tồn tại. Trong một tình huống mà cùng một truy vấn, dựa trên query_hash, thực thi hàng nghìn lần, một khuyến nghị chung là tham số hóa truy vấn. Nếu bạn có thể xác minh rằng không tồn tại sự thay đổi kế hoạch, thì việc tham số hóa truy vấn sẽ loại bỏ thời gian tối ưu hóa và biên dịch cho mỗi lần thực thi, đồng thời có thể làm giảm CPU tổng thể. Trong một số trường hợp, việc tham số hóa 5 đến 10 truy vấn đặc biệt có thể cải thiện hiệu suất toàn hệ thống.
Tóm tắt
Đối với bất kỳ môi trường nào, điều quan trọng là phải hiểu truy vấn nào tốn kém nhất về sử dụng tài nguyên và truy vấn nào chạy thường xuyên nhất. Cùng một tập hợp các truy vấn có thể hiển thị cho cả hai loại phân tích khi sử dụng tập lệnh Glenn’s DMV, điều này có thể gây hiểu lầm. Do đó, điều quan trọng là phải xác định xem khối lượng công việc chủ yếu là theo thủ tục, chủ yếu là đột xuất hay hỗn hợp. Trong khi có nhiều tài liệu về lợi ích của các thủ tục được lưu trữ, tôi thấy rằng khối lượng công việc hỗn hợp hoặc đặc biệt rất phổ biến, đặc biệt là với các giải pháp sử dụng trình ánh xạ quan hệ đối tượng (ORM) như Entity Framework, NHibernate và LINQ to SQL. Nếu bạn không rõ về loại khối lượng công việc cho máy chủ, thì việc chạy truy vấn ở trên để xem các truy vấn được thực thi nhiều nhất dựa trên query_hash là một khởi đầu tốt. Khi bạn bắt đầu hiểu khối lượng công việc và những gì tồn tại đối với cả những truy vấn nặng nề và cái chết của hàng nghìn truy vấn cắt giảm, bạn có thể chuyển sang thực sự hiểu việc sử dụng tài nguyên và tác động của những truy vấn này đối với hiệu suất hệ thống và nhắm mục tiêu nỗ lực của bạn để điều chỉnh.