Tôi nghĩ rằng mọi người đã biết ý kiến của tôi về MERGE và tại sao tôi tránh xa nó. Nhưng đây là một mẫu (chống) khác mà tôi thấy ở khắp nơi khi mọi người muốn thực hiện upert (cập nhật một hàng nếu nó tồn tại và chèn nó nếu nó không có):
IF EXISTS (SELECT 1 FROM dbo.t WHERE [key] = @key) BEGIN UPDATE dbo.t SET val = @val WHERE [key] = @key; END ELSE BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END
Điều này trông giống như một dòng chảy khá logic phản ánh cách chúng ta nghĩ về điều này trong cuộc sống thực:
- Có một hàng đã tồn tại cho khóa này không?
- CÓ :OK, cập nhật hàng đó.
- KHÔNG :OK, sau đó thêm nó.
Nhưng điều này thật lãng phí.
Định vị hàng để xác nhận nó tồn tại, chỉ phải định vị lại hàng để cập nhật nó, đang thực hiện hai lần công việc chẳng để lam gi. Ngay cả khi khóa được lập chỉ mục (mà tôi hy vọng luôn luôn như vậy). Nếu tôi đặt logic này vào một biểu đồ luồng và liên kết, ở mỗi bước, loại hoạt động sẽ phải xảy ra trong cơ sở dữ liệu, tôi sẽ có điều này:
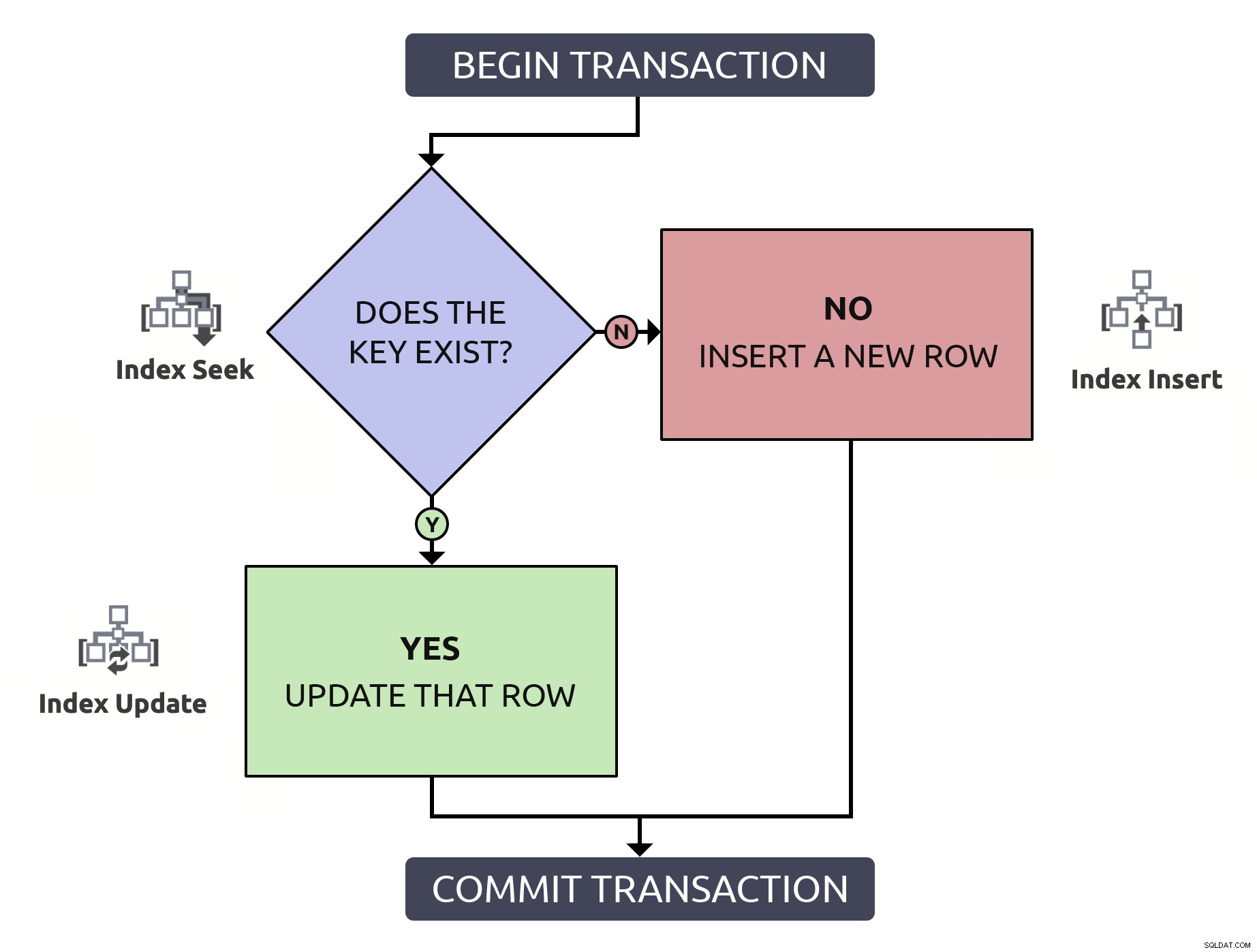 Lưu ý rằng tất cả các đường dẫn sẽ phải chịu hai thao tác lập chỉ mục.
Lưu ý rằng tất cả các đường dẫn sẽ phải chịu hai thao tác lập chỉ mục.
Quan trọng hơn, sang một bên về hiệu suất, trừ khi cả hai bạn sử dụng một giao dịch rõ ràng và nâng cao mức cô lập, nhiều thứ có thể xảy ra sai sót khi hàng chưa tồn tại:
- Nếu khóa tồn tại và hai phiên cố gắng cập nhật đồng thời, chúng sẽ cập nhật thành công (một người sẽ "thắng"; "kẻ thua cuộc" sẽ theo sau với sự thay đổi dính, dẫn đến một "bản cập nhật bị mất"). Đây không phải là vấn đề của riêng nó và là cách chúng ta nên mong đợi một hệ thống có tính đồng thời hoạt động. Paul White nói chi tiết hơn về cơ chế bên trong và Martin Smith nói về một số sắc thái khác tại đây.
- Nếu khóa không tồn tại, nhưng cả hai phiên đều vượt qua kiểm tra tồn tại theo cùng một cách, bất kỳ điều gì có thể xảy ra khi cả hai cùng cố gắng chèn:
- bế tắc vì ổ khóa không tương thích;
- nêu ra các lỗi vi phạm chính điều đó không nên xảy ra; hoặc,
- chèn các giá trị khóa trùng lặp nếu cột đó không được ràng buộc đúng cách.
Cái cuối cùng là tệ nhất, IMHO, vì nó là cái có khả năng làm hỏng dữ liệu . Các bế tắc và ngoại lệ có thể được xử lý dễ dàng bằng những thứ như xử lý lỗi, XACT_ABORT và thử lại logic, tùy thuộc vào tần suất bạn mong đợi va chạm. Nhưng nếu bạn bị ru ngủ trong cảm giác an toàn rằng IF EXISTS kiểm tra bảo vệ bạn khỏi các bản sao (hoặc vi phạm chính), đó là điều bất ngờ đang chờ đợi xảy ra. Nếu bạn mong đợi một cột hoạt động như một khóa, hãy đặt nó chính thức và thêm một ràng buộc.
"Nhiều người đang nói…"
Dan Guzman đã nói về điều kiện cuộc đua hơn một thập kỷ trước trong Điều kiện cuộc đua có điều kiện INSERT / UPDATE và sau đó trong Điều kiện cuộc đua "UPSERT" Với MERGE.
Michael Swart cũng đã điều trị chủ đề này nhiều lần:
- Mythbusting:Đồng thời Cập nhật / Giải pháp Chèn - nơi anh ấy thừa nhận rằng việc giữ nguyên logic ban đầu và chỉ nâng cao mức cô lập chỉ thay đổi các vi phạm chính thành deadlock;
- Cẩn thận với Tuyên bố Hợp nhất - nơi anh ấy kiểm tra sự nhiệt tình của mình về
MERGE; và, - Điều Cần Tránh Nếu Bạn Muốn Sử dụng MERGE - nơi anh ấy khẳng định một lần nữa rằng vẫn còn rất nhiều lý do hợp lệ để tiếp tục tránh
MERGE.
Đảm bảo rằng bạn cũng đọc tất cả các nhận xét trên cả ba bài đăng.
Giải pháp
Tôi đã khắc phục nhiều bế tắc trong sự nghiệp của mình bằng cách chỉ cần điều chỉnh theo mẫu sau (bỏ kiểm tra dư thừa, gói chuỗi trong giao dịch và bảo vệ quyền truy cập bảng đầu tiên bằng khóa thích hợp):
BEGIN TRANSACTION; UPDATE dbo.t WITH (UPDLOCK, SERIALIZABLE) SET val = @val WHERE [key] = @key; IF @@ROWCOUNT = 0 BEGIN INSERT dbo.t([key], val) VALUES(@key, @val); END COMMIT TRANSACTION;
Tại sao chúng ta cần hai gợi ý? Không phải là UPDLOCK đủ chưa?
-
UPDLOCKđược sử dụng để bảo vệ khỏi các bế tắc chuyển đổi tại câu lệnh (để phiên khác đợi thay vì khuyến khích nạn nhân thử lại). -
SERIALIZABLEđược sử dụng để bảo vệ khỏi những thay đổi đối với dữ liệu cơ bản trong suốt giao dịch (đảm bảo một hàng không tồn tại tiếp tục không tồn tại).
Đó là nhiều mã hơn một chút, nhưng nó an toàn hơn 1000% và ngay cả trong trường hợp tồi tệ nhất trường hợp (hàng chưa tồn tại), nó thực hiện tương tự như mẫu chống. Trong trường hợp tốt nhất, nếu bạn đang cập nhật một hàng đã tồn tại, sẽ hiệu quả hơn nếu chỉ định vị hàng đó một lần. Kết hợp logic này với các hoạt động cấp cao sẽ phải xảy ra trong cơ sở dữ liệu, nó đơn giản hơn một chút:
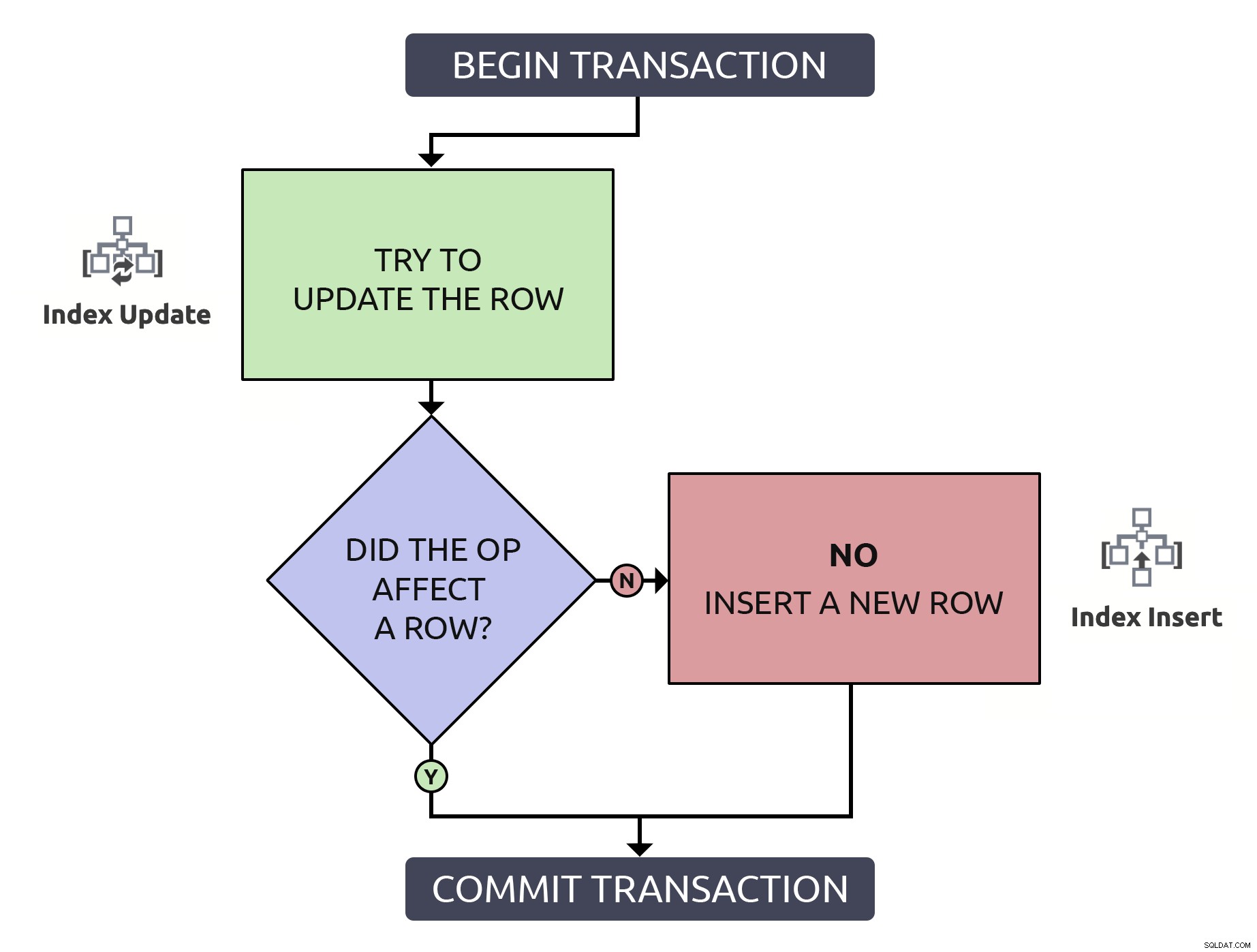 Trong trường hợp này, một đường dẫn chỉ thực hiện một thao tác lập chỉ mục.
Trong trường hợp này, một đường dẫn chỉ thực hiện một thao tác lập chỉ mục.
Nhưng một lần nữa, hãy gạt sang một bên hiệu suất:
- Nếu khoá tồn tại và hai phiên cố gắng cập nhật nó cùng một lúc, chúng sẽ thay phiên nhau và cập nhật hàng thành công , như trước đây.
- Nếu khóa không tồn tại, một phiên sẽ "thắng" và chèn hàng . Người kia sẽ phải đợi cho đến khi ổ khóa được phát hành để kiểm tra sự tồn tại và buộc phải cập nhật.
Trong cả hai trường hợp, người viết chiến thắng cuộc đua sẽ mất dữ liệu của họ cho bất kỳ thứ gì mà "kẻ thua cuộc" cập nhật sau họ.
Lưu ý rằng thông lượng tổng thể trên một hệ thống đồng thời cao có thể đau khổ, nhưng đó là sự đánh đổi mà bạn nên sẵn sàng thực hiện. Rằng bạn đang gặp phải rất nhiều nạn nhân bế tắc hoặc lỗi vi phạm chính, nhưng chúng diễn ra nhanh chóng, không phải là một thước đo hiệu suất tốt. Một số người muốn thấy tất cả các chặn bị xóa khỏi tất cả các tình huống, nhưng một số trong số đó đang chặn mà bạn thực sự muốn để đảm bảo tính toàn vẹn của dữ liệu.
Nhưng điều gì sẽ xảy ra nếu một bản cập nhật ít khả năng xảy ra hơn?
Rõ ràng là giải pháp trên tối ưu hóa cho các bản cập nhật và giả định rằng một khóa bạn đang cố gắng ghi vào sẽ tồn tại trong bảng ít nhất là thường xuyên. Nếu bạn muốn tối ưu hóa cho các lần chèn, biết hoặc đoán rằng các lần chèn sẽ có nhiều khả năng hơn là cập nhật, bạn có thể lật ngược logic xung quanh và vẫn có một hoạt động nâng cấp an toàn:
BEGIN TRANSACTION;
INSERT dbo.t([key], val)
SELECT @key, @val
WHERE NOT EXISTS
(
SELECT 1 FROM dbo.t WITH (UPDLOCK, SERIALIZABLE)
WHERE [key] = @key
);
IF @@ROWCOUNT = 0
BEGIN
UPDATE dbo.t SET val = @val WHERE [key] = @key;
END
COMMIT TRANSACTION; Ngoài ra còn có cách tiếp cận "cứ làm điều đó", trong đó bạn chèn một cách mù quáng và để các va chạm tạo ra ngoại lệ cho người gọi:
BEGIN TRANSACTION; BEGIN TRY INSERT dbo.t([key], val) VALUES(@key, @val); END TRY BEGIN CATCH UPDATE dbo.t SET val = @val WHERE [key] = @key; END CATCH COMMIT TRANSACTION;
Chi phí của những trường hợp ngoại lệ đó thường sẽ lớn hơn chi phí kiểm tra trước; bạn sẽ phải thử nó với một dự đoán gần chính xác về tỷ lệ trúng / trượt. Tôi đã viết về điều này ở đây và ở đây.
Còn việc nâng cấp nhiều hàng thì sao?
Ở trên đề cập đến các quyết định chèn / cập nhật singleton, nhưng Justin Pealing hỏi phải làm gì khi bạn đang xử lý nhiều hàng mà không biết hàng nào đã tồn tại?
Giả sử bạn đang gửi một tập hợp các hàng bằng cách sử dụng thứ gì đó giống như tham số có giá trị bảng, bạn sẽ cập nhật bằng cách sử dụng phép nối, sau đó chèn bằng cách sử dụng NOT EXISTS, nhưng mẫu sẽ vẫn tương đương với cách tiếp cận đầu tiên ở trên:
CREATE PROCEDURE dbo.UpsertTheThings
@tvp dbo.TableType READONLY
AS
BEGIN
SET NOCOUNT ON;
BEGIN TRANSACTION;
UPDATE t WITH (UPDLOCK, SERIALIZABLE)
SET val = tvp.val
FROM dbo.t AS t
INNER JOIN @tvp AS tvp
ON t.[key] = tvp.[key];
INSERT dbo.t([key], val)
SELECT [key], val FROM @tvp AS tvp
WHERE NOT EXISTS (SELECT 1 FROM dbo.t WHERE [key] = tvp.[key]);
COMMIT TRANSACTION;
END Nếu bạn đang kết hợp nhiều hàng với nhau theo một cách nào đó khác với TVP (XML, danh sách được phân tách bằng dấu phẩy, voodoo), trước tiên hãy đặt chúng vào một biểu mẫu bảng và kết hợp với bất kỳ điều gì đó. Hãy cẩn thận không tối ưu hóa cho các lần chèn trước trong trường hợp này, nếu không, bạn có thể sẽ cập nhật một số hàng hai lần.
Kết luận
Những mẫu nâng cấp này vượt trội hơn những mẫu mà tôi thấy quá thường xuyên, và tôi hy vọng bạn bắt đầu sử dụng chúng. Tôi sẽ trỏ đến bài đăng này mỗi khi phát hiện ra IF EXISTS mô hình trong tự nhiên. Và, này, một lời cảm ơn khác dành cho Paul White (sql.kiwi | @SQK_Kiwi), bởi vì anh ấy quá xuất sắc trong việc biến những khái niệm khó hiểu trở nên dễ hiểu và giải thích.
Và nếu bạn cảm thấy mình phải sử dụng MERGE , xin đừng @ tôi; hoặc bạn có lý do chính đáng (có thể bạn cần một số MERGE khó hiểu -chỉ có chức năng), hoặc bạn đã không coi trọng các liên kết trên.