Đây là phần thứ tư trong loạt bài về các giải pháp cho thử thách máy phát chuỗi số. Rất cảm ơn Alan Burstein, Joe Obbish, Adam Machanic, Christopher Ford, Jeff Moden, Charlie, NoamGr, Kamil Kosno, Dave Mason, John Nelson # 2, Ed Wagner, Michael Burbea và Paul White đã chia sẻ ý kiến và nhận xét của bạn.
Tôi yêu công việc của Paul White. Tôi tiếp tục bị sốc bởi những khám phá của anh ấy, và tự hỏi làm thế quái nào mà anh ấy lại tìm ra được những gì anh ấy làm. Tôi cũng thích phong cách viết hiệu quả và hùng hồn của anh ấy. Thường khi đọc các bài báo hoặc bài đăng của anh ấy, tôi lắc đầu và nói với vợ tôi, Lilach, rằng khi lớn lên, tôi muốn giống như Paul.
Khi tôi đăng thử thách ban đầu, tôi đã thầm hy vọng rằng Paul sẽ đăng một giải pháp. Tôi biết rằng nếu anh ấy làm vậy, đó sẽ là một điều rất đặc biệt. Chà, anh ấy đã làm được, và điều đó thật hấp dẫn! Nó có hiệu suất tuyệt vời và có khá nhiều thứ mà bạn có thể học hỏi từ nó. Bài viết này dành riêng cho giải pháp của Paul.
Tôi sẽ thực hiện thử nghiệm của mình trong tempdb, bật I / O và thống kê thời gian:
SET NOCOUNT ON; USE tempdb; SET STATISTICS TIME, IO ON;
Hạn chế của các ý tưởng trước đây
Đánh giá các giải pháp trước đó, một trong những yếu tố quan trọng để đạt được hiệu suất tốt là khả năng sử dụng xử lý hàng loạt. Nhưng chúng ta đã khai thác nó ở mức tối đa có thể chưa?
Chúng ta hãy xem xét các kế hoạch cho hai trong số các giải pháp trước đó sử dụng xử lý hàng loạt. Trong Phần 1, tôi đã đề cập đến hàm dbo.GetNumsAlanCharlieItzikBatch, nó kết hợp các ý tưởng từ Alan, Charlie và chính tôi.
Đây là định nghĩa của hàm:
-- Helper dummy table
DROP TABLE IF EXISTS dbo.BatchMe;
GO
CREATE TABLE dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
GO
-- Function definition
CREATE OR ALTER FUNCTION dbo.GetNumsAlanCharlieItzikBatch(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums LEFT OUTER JOIN dbo.BatchMe ON 1 = 0
ORDER BY rownum;
GO Giải pháp này xác định phương thức khởi tạo giá trị bảng cơ sở có 16 hàng và một loạt CTE xếp tầng với các phép nối chéo để tăng số lượng hàng lên 4B tiềm năng. Giải pháp sử dụng hàm ROW_NUMBER để tạo chuỗi số cơ bản trong CTE được gọi là Nums và bộ lọc TOP để lọc bản số chuỗi số mong muốn. Để kích hoạt xử lý hàng loạt, giải pháp sử dụng kết nối trái giả với điều kiện sai giữa Nums CTE và một bảng được gọi là dbo.BatchMe, có chỉ mục columnstore.
Sử dụng mã sau để kiểm tra hàm bằng kỹ thuật gán biến:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Mô tả của Plan Explorer về thực tế kế hoạch cho việc thực hiện này được thể hiện trong Hình 1.
 Hình 1:Kế hoạch cho hàm dbo.GetNumsAlanCharlieItzikBatch
Hình 1:Kế hoạch cho hàm dbo.GetNumsAlanCharlieItzikBatch
Khi phân tích chế độ hàng loạt và xử lý chế độ hàng, thật tuyệt khi chỉ cần nhìn vào một kế hoạch ở cấp cao mà mỗi người vận hành đã sử dụng chế độ xử lý nào. Thật vậy, Plan Explorer hiển thị một con số lô màu xanh nhạt ở dưới cùng bên trái của toán tử khi chế độ thực thi thực tế của nó là Hàng loạt. Như bạn có thể thấy trong Hình 1, toán tử duy nhất đã sử dụng chế độ hàng loạt là toán tử Window Aggregate, toán tử này sẽ tính toán các số hàng. Vẫn còn rất nhiều công việc được thực hiện bởi các nhà khai thác khác ở chế độ hàng.
Dưới đây là những con số hiệu suất mà tôi nhận được trong thử nghiệm của mình:
Thời gian CPU =10032 ms, thời gian đã trôi qua =10025 ms.lần đọc logic 0
Để xác định nhà khai thác nào mất nhiều thời gian nhất để thực thi, hãy sử dụng tùy chọn Kế hoạch thực thi thực tế trong SSMS hoặc tùy chọn Nhận kế hoạch thực tế trong Plan Explorer. Đảm bảo rằng bạn đã đọc bài viết gần đây của Paul về Hiểu Thời gian của Người điều hành Kế hoạch Thực thi. Bài viết mô tả cách chuẩn hóa thời gian thực thi của toán tử được báo cáo để có được các số chính xác.
Trong kế hoạch ở Hình 1, hầu hết thời gian được sử dụng bởi các toán tử Vòng lặp lồng nhau và trên cùng bên trái, cả hai đều thực thi ở chế độ hàng. Bên cạnh chế độ hàng kém hiệu quả hơn chế độ hàng loạt đối với các hoạt động chuyên sâu của CPU, hãy nhớ rằng việc chuyển đổi từ hàng sang chế độ hàng loạt và quay lại sẽ mất thêm phí.
Trong Phần 2, tôi đã đề cập đến một giải pháp khác sử dụng xử lý hàng loạt, được triển khai trong hàm dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2. Giải pháp này kết hợp các ý tưởng từ John Number2, Dave Mason, Joe Obbish, Alan, Charlie và bản thân tôi. Sự khác biệt chính giữa giải pháp trước đó và giải pháp này là với tư cách là đơn vị cơ sở, giải pháp trước đây sử dụng phương thức khởi tạo giá trị bảng ảo và giải pháp sau sử dụng một bảng thực tế với chỉ mục columnstore, cho phép bạn xử lý hàng loạt “miễn phí”. Đây là mã tạo bảng và điền nó bằng câu lệnh INSERT với 102.400 hàng để nén bảng:
DROP TABLE IF EXISTS dbo.NullBits102400;
GO
CREATE TABLE dbo.NullBits102400
(
b BIT NULL,
INDEX cc_NullBits102400 CLUSTERED COLUMNSTORE
WITH (DATA_COMPRESSION = COLUMNSTORE_ARCHIVE)
);
GO
WITH
L0 AS (SELECT CAST(NULL AS BIT) AS b
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1),(1)) AS D(b)),
L1 AS (SELECT A.b FROM L0 AS A CROSS JOIN L0 AS B),
nulls(b) AS (SELECT A.b FROM L1 AS A CROSS JOIN L1 AS B CROSS JOIN L1 AS C)
INSERT INTO dbo.NullBits102400 WITH (TABLOCK) (b)
SELECT TOP(102400) b FROM nulls;
GO Đây là định nghĩa của hàm:
CREATE OR ALTER FUNCTION dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
(@low AS BIGINT = 1, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM dbo.NullBits102400 AS A
CROSS JOIN dbo.NullBits102400 AS B)
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO Một phép nối chéo duy nhất giữa hai phiên bản của bảng cơ sở là đủ để tạo ra ngoài tiềm năng mong muốn của các hàng 4B. Một lần nữa ở đây, giải pháp sử dụng hàm ROW_NUMBER để tạo ra dãy số cơ bản và bộ lọc TOP để hạn chế số lượng dãy số mong muốn.
Đây là mã để kiểm tra hàm bằng kỹ thuật gán biến:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
Kế hoạch cho việc thực hiện này được thể hiện trong Hình 2.
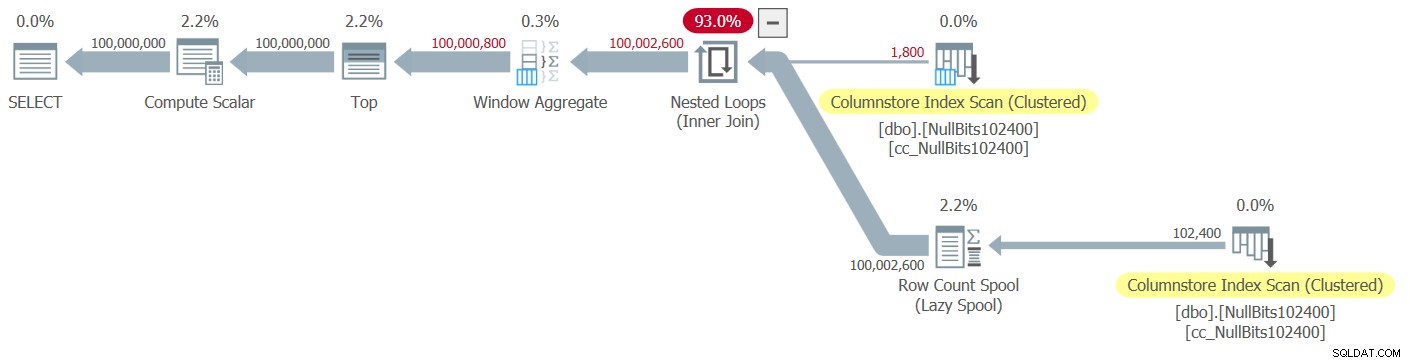 Hình 2:Kế hoạch cho hàm dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Hình 2:Kế hoạch cho hàm dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2
Hãy quan sát rằng chỉ có hai toán tử trong kế hoạch này sử dụng chế độ hàng loạt — bản quét trên cùng của chỉ mục chuỗi cột được phân nhóm của bảng, được sử dụng làm đầu vào bên ngoài của phép nối Vòng lặp lồng nhau và toán tử Tổng hợp cửa sổ, được sử dụng để tính toán số hàng cơ sở .
Tôi nhận được các số hiệu suất sau cho thử nghiệm của mình:
Thời gian CPU =9812 ms, thời gian đã trôi qua =9813 ms.Bảng 'NullBits102400'. Quét đếm 2, đọc lôgic 0, đọc vật lý 0, máy chủ trang đọc 0, đọc trước đọc 0, máy chủ trang đọc trước đọc 0, lôgic đọc 8, đọc vật lý lob 0, máy chủ trang lob đọc 0, đọc lob- lượt đọc trước 0, máy chủ trang lob đọc trước lượt đọc 0.
Bảng 'NullBits102400'. Phân đoạn đọc 2, phân đoạn bị bỏ qua 0.
Một lần nữa, phần lớn thời gian trong quá trình thực hiện kế hoạch này được sử dụng bởi các toán tử Vòng lặp lồng nhau và trên cùng bên trái, chúng thực thi ở chế độ hàng.
Giải pháp của Paul
Trước khi trình bày giải pháp của Paul, tôi sẽ bắt đầu với lý thuyết của mình về quá trình suy nghĩ mà anh ấy đã trải qua. Đây thực sự là một bài tập học tập tuyệt vời, và tôi khuyên bạn nên xem qua nó trước khi xem lời giải. Paul đã nhận ra những tác động làm suy yếu của một kế hoạch kết hợp cả chế độ hàng loạt và hàng, đồng thời tự đặt ra thử thách cho bản thân để đưa ra giải pháp có được kế hoạch chế độ tất cả hàng loạt. Nếu thành công, khả năng một giải pháp như vậy hoạt động tốt là khá cao. Chắc chắn là rất hấp dẫn khi xem liệu mục tiêu đó có thể đạt được hay không vì vẫn còn nhiều toán tử chưa hỗ trợ chế độ hàng loạt và nhiều yếu tố cản trở quá trình xử lý hàng loạt. Ví dụ, tại thời điểm viết bài, thuật toán nối duy nhất hỗ trợ xử lý hàng loạt là thuật toán tham gia băm. Một phép nối chéo được tối ưu hóa bằng cách sử dụng thuật toán vòng lặp lồng nhau. Hơn nữa, toán tử Top hiện chỉ được triển khai ở chế độ hàng. Hai yếu tố này là yếu tố cơ bản quan trọng được sử dụng trong các kế hoạch cho nhiều giải pháp mà tôi đã đề cập cho đến nay, bao gồm cả hai yếu tố trên.
Giả sử rằng bạn đã đưa ra thử thách để tạo ra một giải pháp với kế hoạch chế độ tất cả các đợt thử một cách hợp lý, chúng ta hãy tiếp tục bài tập thứ hai. Trước tiên, tôi sẽ trình bày giải pháp của Paul khi anh ấy cung cấp nó, cùng với các nhận xét nội tuyến của anh ấy. Tôi cũng sẽ chạy nó để so sánh hiệu suất của nó với các giải pháp khác. Tôi đã học được rất nhiều điều bằng cách giải mã và tái tạo lại giải pháp của anh ấy, từng bước một, để đảm bảo rằng tôi đã hiểu cẩn thận lý do tại sao anh ấy sử dụng từng kỹ thuật mà anh ấy đã làm. Tôi khuyên bạn nên làm như vậy trước khi chuyển sang đọc phần giải thích của tôi.
Đây là giải pháp của Paul, bao gồm một bảng cột lưu trữ trợ giúp được gọi là dbo.CS và một hàm được gọi là dbo.GetNums_SQLkiwi:
-- Helper columnstore table
DROP TABLE IF EXISTS dbo.CS;
-- 64K rows (enough for 4B rows when cross joined)
-- column 1 is always zero
-- column 2 is (1...65536)
SELECT
-- type as integer NOT NULL
-- (everything is normalized to 64 bits in columnstore/batch mode anyway)
n1 = ISNULL(CONVERT(integer, 0), 0),
n2 = ISNULL(CONVERT(integer, N.rn), 0)
INTO dbo.CS
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@SPID)
FROM master.dbo.spt_values AS SV1
CROSS JOIN master.dbo.spt_values AS SV2
ORDER BY
rn ASC
OFFSET 0 ROWS
FETCH NEXT 65536 ROWS ONLY
) AS N;
-- Single compressed rowgroup of 65,536 rows
CREATE CLUSTERED COLUMNSTORE INDEX CCI
ON dbo.CS
WITH (MAXDOP = 1);
GO
-- The function
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scala
@low - 2 + N.rn < @high;
GO Đây là mã tôi đã sử dụng để kiểm tra hàm bằng kỹ thuật gán biến:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000);
Tôi nhận được kế hoạch được hiển thị trong Hình 3 cho thử nghiệm của mình.
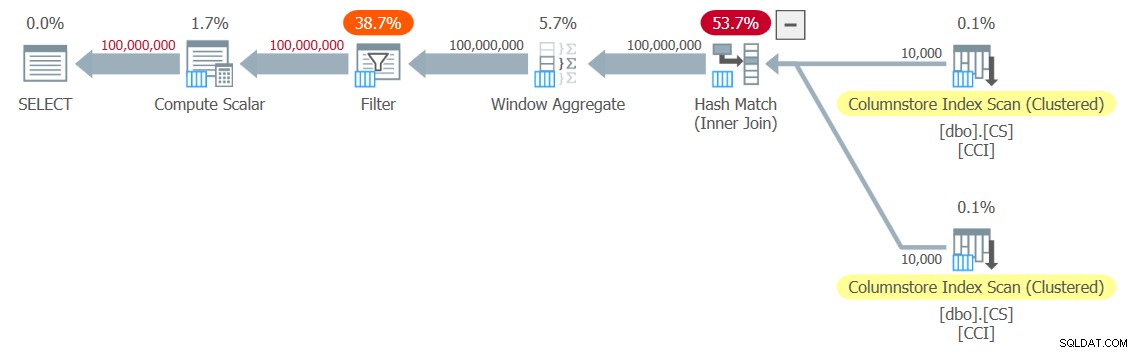 Hình 3:Kế hoạch cho hàm dbo.GetNums_SQLkiwi
Hình 3:Kế hoạch cho hàm dbo.GetNums_SQLkiwi
Đó là một gói chế độ tất cả các đợt! Điều đó khá ấn tượng.
Dưới đây là số hiệu suất mà tôi nhận được cho bài kiểm tra này trên máy của mình:
Thời gian CPU =7812 ms, thời gian đã trôi qua =7876 ms.Bảng 'CS'. Quét đếm 2, đọc lôgic 0, đọc vật lý 0, máy chủ trang đọc 0, đọc trước đọc 0, máy chủ trang đọc trước đọc 0, lôgic đọc 44, đọc vật lý lob 0, máy chủ trang lob đọc 0, đọc lob- lượt đọc trước 0, máy chủ trang lob đọc trước lượt đọc 0.
Bảng 'CS'. Phân đoạn đọc 2, phân đoạn bị bỏ qua 0.
Cũng hãy xác minh rằng nếu bạn cần trả lại các số được sắp xếp theo n, thì giải pháp là bảo toàn thứ tự đối với rn — ít nhất là khi sử dụng hằng số làm đầu vào — và do đó tránh sắp xếp rõ ràng trong kế hoạch. Đây là mã để kiểm tra nó với đơn đặt hàng:
DECLARE @n AS BIGINT; SELECT @n = n FROM dbo.GetNums_SQLkiwi(1, 100000000) ORDER BY n;
Bạn nhận được kế hoạch tương tự như trong Hình 3 và do đó các số hiệu suất tương tự:
Thời gian CPU =7765 ms, thời gian đã trôi qua =7822 ms.Bảng 'CS'. Quét đếm 2, đọc lôgic 0, đọc vật lý 0, máy chủ trang đọc 0, đọc trước đọc 0, máy chủ trang đọc trước đọc 0, lôgic đọc 44, đọc vật lý lob 0, máy chủ trang lob đọc 0, đọc lob- lượt đọc trước 0, máy chủ trang lob đọc trước lượt đọc 0.
Bảng 'CS'. Phân đoạn đọc 2, phân đoạn bị bỏ qua 0.
Đó là một mặt quan trọng của giải pháp.
Thay đổi phương pháp thử nghiệm của chúng tôi
Hiệu suất của giải pháp của Paul là một sự cải thiện đáng kể về cả thời gian đã trôi qua và thời gian CPU so với hai giải pháp trước đó, nhưng có vẻ như đây không phải là sự cải thiện mạnh mẽ hơn mà người ta mong đợi từ gói chế độ tất cả. Có lẽ chúng ta đang thiếu một cái gì đó?
Hãy thử và phân tích thời gian thực thi của người vận hành bằng cách xem Kế hoạch thực thi thực tế trong SSMS như thể hiện trong Hình 4.
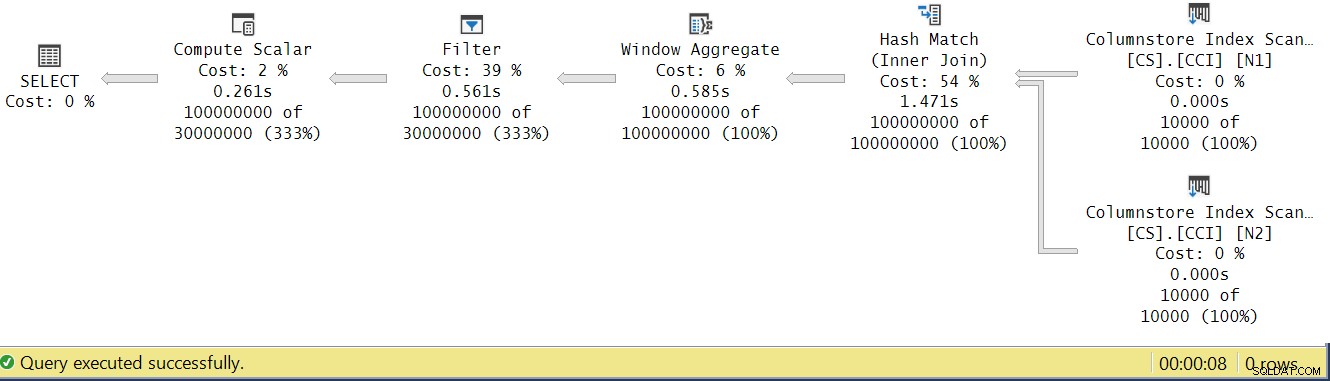 Hình 4:Thời gian thực thi toán tử cho hàm dbo.GetNums_SQLkiwi
Hình 4:Thời gian thực thi toán tử cho hàm dbo.GetNums_SQLkiwi
Trong bài viết của Paul về phân tích thời gian thực thi của toán tử, anh ấy giải thích rằng với các toán tử chế độ hàng loạt, mỗi toán tử báo cáo thời gian thực thi của riêng mình. Nếu bạn tính tổng thời gian thực thi của tất cả các toán tử trong gói thực tế này, bạn sẽ có 2,878 giây, tuy nhiên gói này mất 7,876 để thực thi. 5 giây của thời gian thực hiện dường như bị thiếu. Câu trả lời cho điều này nằm trong kỹ thuật kiểm tra mà chúng tôi đang sử dụng, với phép gán có thể thay đổi. Nhớ lại rằng chúng tôi đã quyết định sử dụng kỹ thuật này để loại bỏ sự cần thiết phải gửi tất cả các hàng từ máy chủ tới trình gọi và để tránh I / Os liên quan đến việc ghi kết quả vào bảng. Nó có vẻ như là một lựa chọn hoàn hảo. Tuy nhiên, chi phí thực sự của việc gán biến được ẩn trong kế hoạch này và tất nhiên, nó thực hiện ở chế độ hàng. Bí ẩn đã được giải đáp.
Rõ ràng là vào cuối ngày, một bài kiểm tra tốt là một bài kiểm tra phản ánh đầy đủ việc sử dụng giải pháp trong sản xuất của bạn. Nếu bạn thường ghi dữ liệu vào một bảng, bạn cần kiểm tra để phản ánh điều đó. Nếu bạn gửi kết quả cho người gọi, bạn cần thử nghiệm của mình để phản ánh điều đó. Ở bất kỳ mức độ nào, phép gán biến số dường như đại diện cho một phần lớn thời gian thực hiện trong thử nghiệm của chúng tôi và rõ ràng là không thể đại diện cho việc sử dụng sản xuất điển hình của hàm. Paul gợi ý rằng thay vì gán biến, kiểm tra có thể áp dụng một tổng hợp đơn giản như MAX cho cột số được trả về (n / rn / op). Một nhà điều hành tổng hợp có thể sử dụng xử lý hàng loạt, do đó, kế hoạch sẽ không liên quan đến việc chuyển đổi từ chế độ hàng loạt sang chế độ hàng do kết quả của việc sử dụng nó và đóng góp của nó vào tổng thời gian chạy phải khá nhỏ và được biết đến.
Vì vậy, hãy thử nghiệm lại cả ba giải pháp được đề cập trong bài viết này. Đây là mã để kiểm tra hàm dbo.GetNumsAlanCharlieItzikBatch:
SELECT MAX(n) AS mx FROM dbo.GetNumsAlanCharlieItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Tôi nhận được kế hoạch được hiển thị trong Hình 5 cho bài kiểm tra này.
 Hình 5:Kế hoạch cho hàm dbo.GetNumsAlanCharlieItzikBatch với tổng hợp
Hình 5:Kế hoạch cho hàm dbo.GetNumsAlanCharlieItzikBatch với tổng hợp
Dưới đây là những con số hiệu suất mà tôi nhận được cho bài kiểm tra này:
Thời gian CPU =8469 ms, thời gian đã trôi qua =8733 ms.lần đọc logic 0
Quan sát rằng thời gian chạy đã giảm từ 10,025 giây bằng kỹ thuật gán biến đổi xuống 8,733 bằng kỹ thuật tổng hợp. Đó là hơn một giây thời gian thực thi mà chúng tôi có thể gán cho phép gán biến ở đây.
Đây là mã để kiểm tra hàm dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2:
SELECT MAX(n) AS mx FROM dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2(1, 100000000) OPTION(MAXDOP 1);
Tôi nhận được kế hoạch được hiển thị trong Hình 6 cho bài kiểm tra này.
 Hình 6:Kế hoạch cho hàm dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 với tổng hợp
Hình 6:Kế hoạch cho hàm dbo.GetNumsJohn2DaveObbishAlanCharlieItzik2 với tổng hợp
Dưới đây là những con số hiệu suất mà tôi nhận được cho bài kiểm tra này:
Thời gian CPU =7031 ms, thời gian đã trôi qua =7053 ms.Bảng 'NullBits102400'. Quét đếm 2, đọc lôgic 0, đọc vật lý 0, máy chủ trang đọc 0, đọc trước đọc 0, máy chủ trang đọc trước đọc 0, lôgic đọc 8, đọc vật lý lob 0, máy chủ trang lob đọc 0, đọc lob- lượt đọc trước 0, máy chủ trang lob đọc trước lượt đọc 0.
Bảng 'NullBits102400'. Phân đoạn đọc 2, phân đoạn bị bỏ qua 0.
Quan sát thấy rằng thời gian chạy đã giảm từ 9,813 giây bằng kỹ thuật gán biến xuống 7,053 bằng kỹ thuật tổng hợp. Đó là khoảng hơn hai giây thời gian thực thi mà chúng tôi có thể gán cho phép gán biến ở đây.
Và đây là mã để kiểm tra giải pháp của Paul:
SELECT MAX(n) AS mx FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(MAXDOP 1);
Tôi nhận được kế hoạch được hiển thị trong Hình 7 cho thử nghiệm này.
 Hình 7:Kế hoạch cho hàm dbo.GetNums_SQLkiwi với tổng hợp
Hình 7:Kế hoạch cho hàm dbo.GetNums_SQLkiwi với tổng hợp
Và bây giờ là thời điểm quan trọng. Tôi nhận được các số hiệu suất sau cho bài kiểm tra này:
Thời gian CPU =3125 mili giây, thời gian đã trôi qua =3149 mili giây.Bảng 'CS'. Quét đếm 2, đọc lôgic 0, đọc vật lý 0, máy chủ trang đọc 0, đọc trước đọc 0, máy chủ trang đọc trước đọc 0, lôgic đọc 44, đọc vật lý lob 0, máy chủ trang lob đọc 0, đọc lob- lượt đọc trước 0, máy chủ trang lob đọc trước lượt đọc 0.
Bảng 'CS'. Phân đoạn đọc 2, phân đoạn bị bỏ qua 0.
Thời gian chạy giảm từ 7,822 giây xuống 3,149 giây! Chúng ta hãy kiểm tra thời gian thực hiện của nhà điều hành trong kế hoạch thực tế trong SSMS, như thể hiện trong Hình 8.
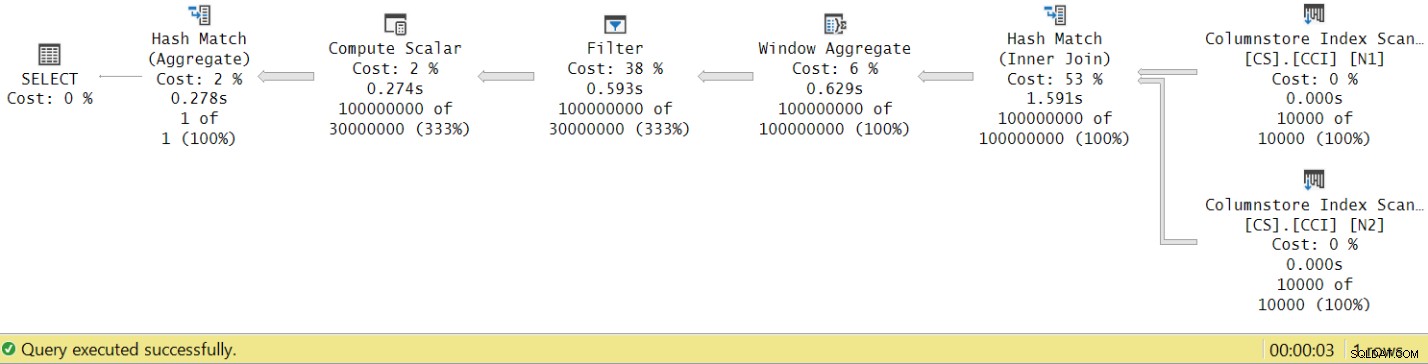 Hình 8:Thời gian thực thi toán tử cho hàm dbo.GetNums với tổng hợp
Hình 8:Thời gian thực thi toán tử cho hàm dbo.GetNums với tổng hợp
Bây giờ, nếu bạn tích lũy thời gian thực hiện của các nhà khai thác riêng lẻ, bạn sẽ nhận được một con số tương tự với tổng thời gian thực hiện gói.
Hình 9 so sánh hiệu suất về thời gian đã trôi qua giữa ba giải pháp bằng cách sử dụng cả kỹ thuật gán biến và kiểm tra tổng hợp.
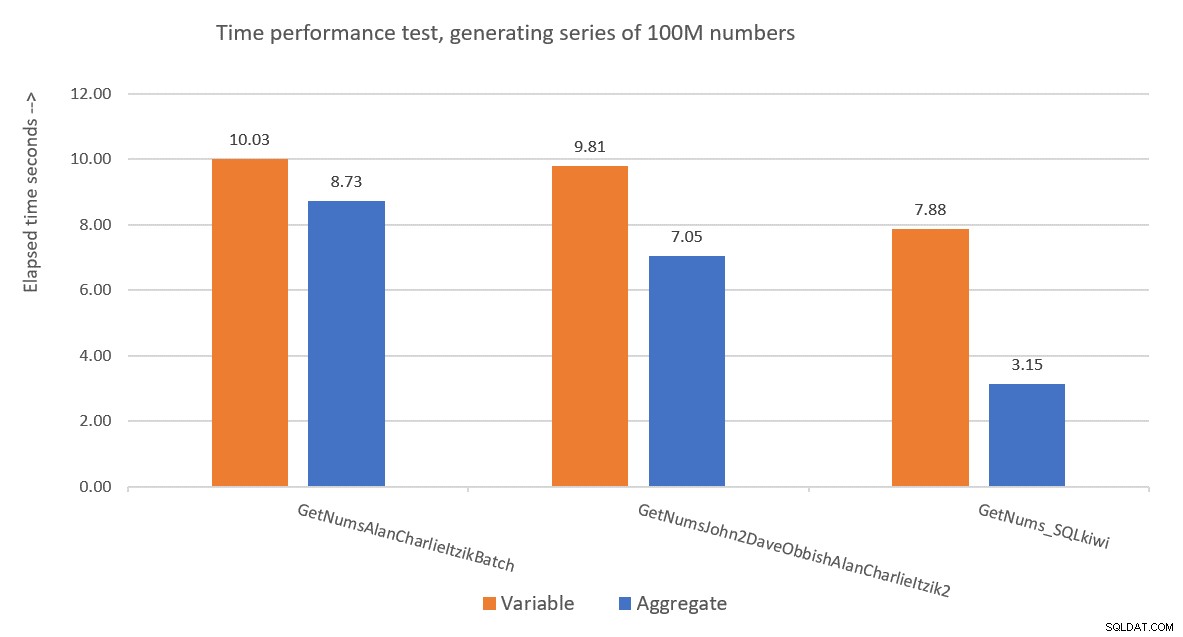 Hình 9:So sánh hiệu suất
Hình 9:So sánh hiệu suất
Giải pháp của Paul rõ ràng là người chiến thắng và điều này đặc biệt rõ ràng khi sử dụng kỹ thuật thử nghiệm tổng hợp. Quả là một kỳ tích ấn tượng!
Giải mã và tái tạo lại giải pháp của Paul
Giải mã và sau đó tái tạo lại giải pháp của Phao-lô là một bài tập tuyệt vời và bạn sẽ học được nhiều điều khi làm như vậy. Như đã đề xuất trước đó, tôi khuyên bạn nên tự mình thực hiện quy trình trước khi tiếp tục đọc.
Lựa chọn đầu tiên mà bạn cần thực hiện là kỹ thuật mà bạn sẽ sử dụng để tạo ra số hàng tiềm năng mong muốn là 4B. Paul đã chọn sử dụng bảng columnstore và điền vào nó nhiều hàng bằng căn bậc hai của số được yêu cầu, nghĩa là 65.536 hàng, để chỉ với một phép nối chéo, bạn sẽ nhận được số cần thiết. Có lẽ bạn đang nghĩ rằng với ít hơn 102.400 hàng, bạn sẽ không nhận được nhóm hàng được nén, nhưng điều này áp dụng khi bạn điền vào bảng bằng câu lệnh INSERT giống như chúng ta đã làm với bảng dbo.NullBits102400. Nó không áp dụng khi bạn tạo chỉ mục cột lưu trữ trên một bảng được tạo sẵn. Vì vậy, Paul đã sử dụng câu lệnh SELECT INTO để tạo và điền bảng dưới dạng một đống dựa trên lưu trữ hàng với 65.536 hàng, sau đó tạo chỉ mục lưu trữ cột theo cụm, dẫn đến một nhóm hàng được nén.
Thách thức tiếp theo là tìm ra cách để có được một phép nối chéo được xử lý với một nhà điều hành chế độ hàng loạt. Đối với điều này, bạn cần thuật toán nối thành băm. Hãy nhớ rằng kết hợp chéo được tối ưu hóa bằng cách sử dụng thuật toán vòng lặp lồng nhau. Bằng cách nào đó, bạn cần đánh lừa trình tối ưu hóa nghĩ rằng bạn đang sử dụng một hàm tương đương bên trong (hàm băm yêu cầu ít nhất một vị từ dựa trên đẳng thức), nhưng thực tế lại có một phép nối chéo.
Một nỗ lực đầu tiên rõ ràng là sử dụng một phép nối bên trong với một vị từ nối nhân tạo luôn đúng, như sau:
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON 0 = 0; Nhưng mã này không thành công với lỗi sau:
Msg 8622, Mức 16, Trạng thái 1, Dòng 246Bộ xử lý truy vấn không thể tạo kế hoạch truy vấn do các gợi ý được xác định trong truy vấn này. Gửi lại truy vấn mà không chỉ định bất kỳ gợi ý nào và không sử dụng SET FORCEPLAN.
Trình tối ưu hóa của SQL Server nhận ra rằng đây là một vị từ liên kết bên trong nhân tạo, đơn giản hóa liên kết bên trong thành một liên kết chéo và tạo ra lỗi nói rằng nó không thể đáp ứng gợi ý để buộc một thuật toán liên kết băm.
Để giải quyết vấn đề này, Paul đã tạo một cột INT NOT NULL (tìm hiểu thêm về lý do tại sao thông số kỹ thuật này ngay lập tức) được gọi là n1 trong bảng dbo.CS của anh ấy và điền nó bằng 0 trong tất cả các hàng. Sau đó, anh ấy đã sử dụng vị từ nối N2.n1 =N1.n1, nhận mệnh đề 0 =0 một cách hiệu quả trong tất cả các đánh giá đối sánh, đồng thời tuân thủ các yêu cầu tối thiểu đối với thuật toán liên kết băm.
Điều này hoạt động và tạo ra một gói chế độ tất cả các đợt:
SELECT *
FROM dbo.CS AS N1
INNER HASH JOIN dbo.CS AS N2
ON N2.n1 = N1.n1; Đối với lý do cho n1 được định nghĩa là INT NOT NULL; tại sao không cho phép NULL và tại sao không sử dụng BIGINT? Lý do cho những lựa chọn này là để tránh dư lượng thăm dò băm (một bộ lọc bổ sung được áp dụng bởi toán tử tham gia băm ngoài vị từ tham gia ban đầu), điều này có thể dẫn đến chi phí bổ sung không cần thiết. Xem bài viết của Paul Tham gia Hiệu suất, Chuyển đổi ngầm và Phần còn lại để biết chi tiết. Đây là một phần của bài viết có liên quan đến chúng tôi:
"Nếu tham gia nằm trên một cột đơn được nhập là tinyint, smallint hoặc integer và nếu cả hai cột bị ràng buộc là KHÔNG ĐỦ, thì hàm băm là 'hoàn hảo' - có nghĩa là không có khả năng xảy ra xung đột và trình xử lý truy vấn không phải kiểm tra lại các giá trị để đảm bảo chúng thực sự khớp.Lưu ý rằng tối ưu hóa này không áp dụng cho các cột bigint. "
Để kiểm tra khía cạnh này, hãy tạo một bảng khác có tên là dbo.CS2 với cột n1 có thể vô hiệu:
DROP TABLE IF EXISTS dbo.CS2; SELECT * INTO dbo.CS2 FROM dbo.CS; ALTER TABLE dbo.CS2 ALTER COLUMN n1 INT NULL; CREATE CLUSTERED COLUMNSTORE INDEX CCI ON dbo.CS2 WITH (MAXDOP = 1);
Đầu tiên chúng ta hãy kiểm tra một truy vấn đối với dbo.CS (trong đó n1 được định nghĩa là INT NOT NULL), tạo số hàng cơ sở 4B trong một cột có tên là rn và áp dụng tổng hợp MAX cho cột:
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
) AS N; Chúng tôi sẽ so sánh kế hoạch cho truy vấn này với kế hoạch cho một truy vấn tương tự đối với dbo.CS2 (trong đó n1 được định nghĩa là INT NULL):
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS2 AS N1
JOIN dbo.CS2 AS N2
ON N2.n1 = N1.n1
) AS N; Kế hoạch cho cả hai truy vấn được thể hiện trong Hình 10.
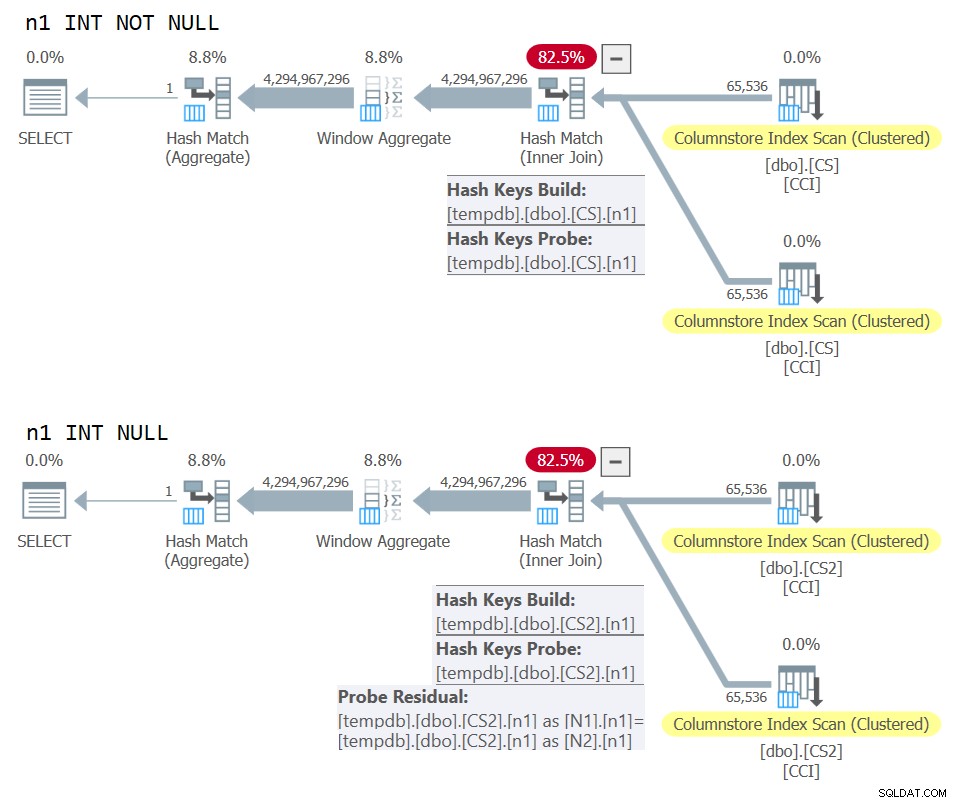 Hình 10:So sánh kế hoạch cho khóa tham gia NOT NULL và NULL
Hình 10:So sánh kế hoạch cho khóa tham gia NOT NULL và NULL
Bạn có thể thấy rõ lượng dư đầu dò bổ sung được áp dụng trong kế hoạch thứ hai chứ không phải kế hoạch đầu tiên.
Trên máy của tôi, truy vấn đối với dbo.CS đã hoàn tất trong 91 giây và truy vấn đối với dbo.CS2 hoàn tất trong 92 giây. Trong bài viết của Paul, anh ấy báo cáo sự khác biệt 11% nghiêng về trường hợp KHÔNG ĐỦ đối với ví dụ mà anh ấy đã sử dụng.
BTW, những người trong số các bạn có con mắt tinh tường sẽ nhận thấy việc sử dụng ORDER BY @@ TRANCOUNT làm đặc tả đặt hàng của hàm ROW_NUMBER. Nếu bạn đọc kỹ các nhận xét nội tuyến của Paul trong giải pháp của anh ấy, anh ấy đề cập rằng việc sử dụng hàm @@ TRANCOUNT là một chất ức chế song song, trong khi sử dụng @@ SPID thì không. Vì vậy, bạn có thể sử dụng @@ TRANCOUNT làm hằng số thời gian chạy trong thông số đặt hàng khi bạn muốn bắt buộc một gói nối tiếp và @@ SPID khi bạn không.
Như đã đề cập, truy vấn dbo.CS mất 91 giây để chạy trên máy của tôi. Tại thời điểm này, có thể thú vị khi kiểm tra cùng một mã với một phép nối chéo thực sự, cho phép trình tối ưu hóa sử dụng thuật toán nối các vòng lặp lồng nhau ở chế độ hàng:
SELECT
mx = MAX(N.rn)
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
CROSS JOIN dbo.CS AS N2
) AS N; Phải mất 104 giây để hoàn thành mã này trên máy tính của tôi. Vì vậy, chúng tôi nhận được một sự cải thiện hiệu suất khá lớn với tham gia băm ở chế độ hàng loạt.
Vấn đề tiếp theo của chúng tôi là thực tế là khi sử dụng TOP để lọc số hàng mong muốn, bạn sẽ nhận được một kế hoạch với toán tử Top ở chế độ hàng. Đây là nỗ lực triển khai hàm dbo.GetNums_SQLkiwi với bộ lọc TOP:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT TOP (100000000 - 1 + 1)
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
ORDER BY rn
) AS N;
GO Hãy kiểm tra chức năng:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Tôi nhận được kế hoạch được hiển thị trong Hình 11 cho bài kiểm tra này.
 Hình 11:Lập kế hoạch với bộ lọc TOP
Hình 11:Lập kế hoạch với bộ lọc TOP
Quan sát rằng toán tử Hàng đầu là toán tử duy nhất trong kế hoạch sử dụng xử lý chế độ hàng.
Tôi nhận được thống kê thời gian sau cho lần thực hiện này:
Thời gian CPU =6078 ms, thời gian đã trôi qua =6071 ms.Phần lớn thời gian chạy trong kế hoạch này là do người điều hành Chế độ hàng đầu sử dụng và thực tế là kế hoạch cần phải chuyển đổi chế độ hàng loạt sang chế độ hàng và quay lại.
Thách thức của chúng tôi là tìm ra giải pháp lọc chế độ hàng loạt thay thế cho chế độ hàng TOP. Các bộ lọc dựa trên xác định trước như những bộ lọc được áp dụng với mệnh đề WHERE có thể được xử lý bằng xử lý hàng loạt.
Cách tiếp cận của Paul là giới thiệu cột được nhập kiểu INT thứ hai (xem nhận xét nội tuyến “mọi thứ vẫn được chuẩn hóa thành 64 bit ở chế độ columnstore / batch” ) được gọi là n2 vào bảng dbo.CS và điền nó với dãy số nguyên từ 1 đến 65,536. Trong mã của giải pháp, anh ấy đã sử dụng hai bộ lọc dựa trên vị từ. Một là bộ lọc thô trong truy vấn bên trong với các vị từ liên quan đến cột n2 từ cả hai phía của phép nối. Bộ lọc thô này có thể dẫn đến một số kết quả dương tính giả. Đây là nỗ lực đơn giản đầu tiên đối với một bộ lọc như vậy:
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1)))) Với đầu vào 1 và 100.000.000 là @low và @high, bạn không nhận được kết quả dương tính giả nào. Nhưng hãy thử với 1 và 100.000.001, và bạn sẽ nhận được một số. Bạn sẽ nhận được một chuỗi gồm 100.020.001 số thay vì 100.000.001.
Để loại bỏ các kết quả dương tính giả, Paul đã thêm một bộ lọc thứ hai, chính xác, liên quan đến cột rn trong truy vấn bên ngoài. Đây là nỗ lực đơn giản đầu tiên đối với một bộ lọc chính xác như vậy:
WHERE
-- Precise filter:
N.rn < @high - @low + 2 Hãy sửa đổi định nghĩa của hàm để sử dụng các bộ lọc dựa trên vị từ ở trên thay vì TOP, lấy 1:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
N.rn < @high - @low + 2;
GO Hãy kiểm tra chức năng:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
Tôi nhận được kế hoạch được hiển thị trong Hình 12 cho bài kiểm tra này.
 Hình 12:Lập kế hoạch với bộ lọc WHERE, lấy 1
Hình 12:Lập kế hoạch với bộ lọc WHERE, lấy 1
Than ôi, rõ ràng là có gì đó không ổn. SQL Server đã chuyển đổi bộ lọc dựa trên vị từ của chúng tôi liên quan đến cột rn thành bộ lọc dựa trên TOP và tối ưu hóa nó bằng toán tử Top — đó chính là điều chúng tôi đã cố gắng tránh. Để tăng thêm sự xúc phạm cho thương tích, trình tối ưu hóa cũng quyết định sử dụng thuật toán vòng lặp lồng nhau cho phép kết hợp.
Phải mất 18,8 giây mã này mới hoàn tất trên máy của tôi. Trông không đẹp.
Về phép nối vòng lặp lồng nhau, đây là điều mà chúng ta có thể dễ dàng thực hiện bằng cách sử dụng gợi ý phép nối trong truy vấn bên trong. Chỉ để xem tác động về hiệu suất, đây là bài kiểm tra với gợi ý truy vấn kết hợp băm bắt buộc được sử dụng trong chính truy vấn kiểm tra:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000) OPTION(HASH JOIN);
Thời gian chạy giảm xuống còn 13,2 giây.
Chúng tôi vẫn gặp sự cố với việc chuyển đổi bộ lọc WHERE so với rn thành bộ lọc TOP. Hãy thử và hiểu cách điều này xảy ra. Chúng tôi đã sử dụng bộ lọc sau trong truy vấn bên ngoài:
WHERE N.rn < @high - @low + 2
Hãy nhớ rằng rn đại diện cho một biểu thức dựa trên ROW_NUMBER không được điều chỉnh. Bộ lọc dựa trên một biểu thức không được điều chỉnh như vậy nằm trong một phạm vi nhất định thường được tối ưu hóa với toán tử Top, điều này đối với chúng tôi là một tin xấu do sử dụng xử lý chế độ hàng.
Cách giải quyết của Paul là sử dụng một vị từ tương đương, nhưng một vị ngữ áp dụng thao tác cho rn, như vậy:
WHERE @low - 2 + N.rn < @high
Việc lọc một biểu thức có thêm thao tác vào một biểu thức dựa trên ROW_NUMBER sẽ ngăn chặn việc chuyển đổi bộ lọc dựa trên vị từ thành một bộ lọc dựa trên TOP. Thật tuyệt vời!
Let’s revise the function’s definition to use the above WHERE predicate, take 2:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
rn = ROW_NUMBER() OVER (ORDER BY @@TRANCOUNT ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
ON N2.n1 = N1.n1
WHERE
-- Coarse filter:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
) AS N
WHERE
-- Precise filter:
@low - 2 + N.rn < @high;
GO Test the function again, without any special hints or anything:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
It naturally gets an all-batch-mode plan with a hash join algorithm and no Top operator, resulting in an execution time of 3.177 seconds. Looking good.
The next step is to check if the solution handles bad inputs well. Let’s try it with a negative delta:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
This execution fails with the following error.
Msg 3623, Level 16, State 1, Line 436An invalid floating point operation occurred.
The failure is due to the attempt to apply a square root of a negative number.
Paul’s solution involved two additions. One is to add the following predicate to the inner query’s WHERE clause:
@high >= @low
This filter does more than what it seems initially. If you’ve read Paul’s inline comments carefully, you could find this part:
“Try to avoid SQRT on negative numbers and enable simplification to single constant scan if @low> @high (with literals). No start-up filters in batch mode.”The intriguing part here is the potential to use a constant scan with constants as inputs. I’ll get to this shortly.
The other addition is to apply the IIF function to the input expression to the SQRT function. This is done to avoid negative input when using nonconstants as inputs to our numbers function, and in case the optimizer decides to handle the predicate involving SQRT before the predicate @high>=@low.
Before the IIF addition, for example, the predicate involving N1.n2 looked like this:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, @high - @low + 1))))
After adding IIF, it looks like this:
N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
With these two additions, we’re now basically ready for the final definition of the dbo.GetNums_SQLkiwi function:
CREATE OR ALTER FUNCTION dbo.GetNums_SQLkiwi
(
@low bigint = 1,
@high bigint
)
RETURNS table
AS
RETURN
SELECT
N.rn,
n = @low - 1 + N.rn,
op = @high + 1 - N.rn
FROM
(
SELECT
-- Use @@TRANCOUNT instead of @@SPID if you like all your queries serial
rn = ROW_NUMBER() OVER (ORDER BY @@SPID ASC)
FROM dbo.CS AS N1
JOIN dbo.CS AS N2
-- Batch mode hash cross join
-- Integer not null data type avoid hash probe residual
-- This is always 0 = 0
ON N2.n1 = N1.n1
WHERE
-- Try to avoid SQRT on negative numbers and enable simplification
-- to single constant scan if @low > @high (with literals)
-- No start-up filters in batch mode
@high >= @low
-- Coarse filter:
-- Limit each side of the cross join to SQRT(target number of rows)
-- IIF avoids SQRT on negative numbers with parameters
AND N1.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
AND N2.n2 <= CONVERT(integer, CEILING(SQRT(CONVERT(float, IIF(@high >= @low, @high - @low + 1, 0)))))
) AS N
WHERE
-- Precise filter:
-- Batch mode filter the limited cross join to the exact number of rows needed
-- Avoids the optimizer introducing a row-mode Top with following row mode compute scalar
@low - 2 + N.rn < @high;
GO Now back to the comment about the constant scan. When using constants that result in a negative range as inputs to the function, e.g., 100,000,000 and 1 as @low and @high, after parameter embedding the WHERE filter of the inner query looks like this:
WHERE
1 >= 100000000
AND ... The whole plan can then be simplified to a single Constant Scan operator. Hãy thử nó:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(100000000, 1);
The plan for this execution is shown in Figure 13.
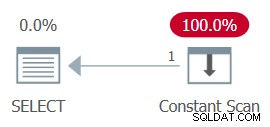 Figure 13:Plan with constant scan
Figure 13:Plan with constant scan
Unsurprisingly, I got the following performance numbers for this execution:
CPU time =0 ms, elapsed time =0 ms.logical reads 0
When passing a negative range with nonconstants as inputs, the use of the IIF function will prevent any attempt to compute a square root of a negative input.
Now let’s test the function with a valid input range:
SELECT MAX(n) FROM dbo.GetNums_SQLkiwi(1, 100000000);
You get the all-batch-mode plan shown in Figure 14.
 Figure 14:Plan for dbo.GetNums_SQLkiwi function
Figure 14:Plan for dbo.GetNums_SQLkiwi function
This is the same plan you saw earlier in Figure 7.
I got the following time statistics for this execution:
CPU time =3000 ms, elapsed time =3111 ms.Ladies and gentlemen, I think we have a winner! :)
Kết luận
I’ll have what Paul’s having.
Are we done yet, or is this series going to last forever?
No and no.