CẬP NHẬT:ngày 2 tháng 9 năm 2021 (Xuất bản lần đầu vào ngày 26 tháng 7 năm 2012.)
Rất nhiều thứ thay đổi trong quá trình một vài phiên bản chính của nền tảng cơ sở dữ liệu yêu thích của chúng tôi. SQL Server 2016 đã mang đến cho chúng tôi STRING_SPLIT, một hàm gốc giúp loại bỏ nhu cầu về nhiều giải pháp tùy chỉnh mà chúng tôi cần trước đây. Nó cũng nhanh, nhưng nó không hoàn hảo. Ví dụ:nó chỉ hỗ trợ dấu phân cách một ký tự và nó không trả về bất kỳ thứ gì để chỉ ra thứ tự của các phần tử đầu vào. Tôi đã viết một số bài báo về chức năng này (và STRING_AGG, đã có trong SQL Server 2017) kể từ khi bài đăng này được viết:
- Sự ngạc nhiên và giả định về hiệu suất:STRING_SPLIT ()
- STRING_SPLIT () trong SQL Server 2016:Tiếp theo # 1
- STRING_SPLIT () trong SQL Server 2016:Tiếp theo # 2
- Mã thay thế chuỗi phân tách máy chủ SQL bằng STRING_SPLIT
- So sánh các phương pháp tách / nối chuỗi
- Giải quyết các sự cố cũ với các hàm STRING_AGG và STRING_SPLIT mới của SQL Server
- Xử lý dấu phân cách một ký tự trong hàm STRING_SPLIT của SQL Server
- Vui lòng trợ giúp với các cải tiến STRING_SPLIT
- Một cách để cải thiện STRING_SPLIT trong SQL Server - và bạn có thể trợ giúp
Tôi sẽ để lại nội dung bên dưới ở đây vì sự liên quan đến hậu thế và lịch sử, và cũng bởi vì một số phương pháp kiểm tra có liên quan đến các vấn đề khác ngoài việc tách chuỗi, nhưng vui lòng xem một số tài liệu tham khảo ở trên để biết thông tin về cách bạn nên tách chuỗi trong các phiên bản SQL Server hiện đại, được hỗ trợ - cũng như bài đăng này, giải thích lý do tại sao việc tách chuỗi có thể không phải là vấn đề bạn muốn cơ sở dữ liệu giải quyết ngay từ đầu, dù là chức năng mới hay không.
- Tách chuỗi:Giờ đây với ít T-SQL hơn
Tôi biết nhiều người cảm thấy nhàm chán với vấn đề "chia chuỗi", nhưng nó dường như vẫn xuất hiện gần như hàng ngày trên diễn đàn và các trang web Hỏi &Đáp như Stack Overflow. Đây là vấn đề mà mọi người muốn truyền vào một chuỗi như thế này:
EXEC dbo.UpdateProfile @UserID = 1, @FavoriteTeams = N'Patriots,Red Sox,Bruins';
Bên trong thủ tục, họ muốn làm điều gì đó như sau:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (@FavoriteTeams); Điều này không hoạt động vì @FavoriteTeams là một chuỗi đơn và ở trên dịch thành:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots,Red Sox,Bruins'); Do đó, SQL Server sẽ cố gắng tìm một nhóm có tên Patriots, Red Sox, Bruins , và tôi đoán không có đội nào như vậy. Những gì họ thực sự muốn ở đây tương đương với:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots', N'Red Sox', N'Bruins'); Nhưng vì không có kiểu mảng trong SQL Server, nên đây không phải là cách biến được diễn giải - nó vẫn là một chuỗi đơn, đơn giản có chứa một số dấu phẩy. Bỏ qua thiết kế lược đồ đáng nghi vấn, trong trường hợp này, danh sách được phân tách bằng dấu phẩy cần được "tách" thành các giá trị riêng lẻ - và đây là câu hỏi thường xuyên thúc đẩy rất nhiều cuộc tranh luận và bình luận "mới" về giải pháp tốt nhất để đạt được điều đó.
Câu trả lời dường như luôn luôn là bạn nên sử dụng CLR. Nếu bạn không thể sử dụng CLR - và tôi biết có rất nhiều người trong số các bạn không thể sử dụng, do chính sách của công ty, ông chủ đầu bù tóc nhọn hoặc sự bướng bỉnh - thì bạn sử dụng một trong nhiều cách giải quyết tồn tại. Và nhiều cách giải quyết tồn tại.
Nhưng bạn nên sử dụng cái nào?
Tôi sẽ so sánh hiệu suất của một số giải pháp - và tập trung vào câu hỏi mà mọi người luôn hỏi:"Giải pháp nào nhanh nhất?" Tôi sẽ không coi thường cuộc thảo luận xung quanh * tất cả * các phương pháp tiềm năng, bởi vì một số phương pháp đã bị loại bỏ do thực tế là chúng không mở rộng quy mô. Và tôi có thể sẽ truy cập lại trang này trong tương lai để xem xét tác động lên các chỉ số khác, nhưng hiện tại tôi chỉ tập trung vào thời lượng. Dưới đây là các đối thủ mà tôi sẽ so sánh (sử dụng SQL Server 2012, 11.00.2316, trên máy ảo Windows 7 với 4 CPU và 8 GB RAM):
CLR
Nếu bạn muốn sử dụng CLR, bạn chắc chắn nên mượn mã từ đồng nghiệp MVP Adam Machanic trước khi nghĩ đến việc viết mã của riêng bạn (Tôi đã viết blog trước đây về việc phát minh lại bánh xe và nó cũng áp dụng cho các đoạn mã miễn phí như thế này). Anh ấy đã dành rất nhiều thời gian để tinh chỉnh hàm CLR này để phân tích cú pháp một chuỗi một cách hiệu quả. Nếu bạn hiện đang sử dụng một hàm CLR và đây không phải là nó, tôi thực sự khuyên bạn nên triển khai nó và so sánh - Tôi đã thử nghiệm nó với một quy trình CLR dựa trên VB đơn giản hơn nhiều, tương đương về mặt chức năng, nhưng cách tiếp cận VB hoạt động kém hơn khoảng ba lần hơn của Adam.
Vì vậy, tôi đã sử dụng chức năng của Adam, biên dịch mã thành một DLL (sử dụng csc) và chỉ triển khai tệp đó đến máy chủ. Sau đó, tôi đã thêm assembly và chức năng sau vào cơ sở dữ liệu của mình:
CREATE ASSEMBLY CLRUtilities FROM 'c:\DLLs\CLRUtilities.dll' WITH PERMISSION_SET = SAFE; GO CREATE FUNCTION dbo.SplitStrings_CLR ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) ) RETURNS TABLE ( Item NVARCHAR(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi; GO
XML
Đây là chức năng điển hình mà tôi sử dụng cho các tình huống một lần trong đó tôi biết đầu vào là "an toàn", nhưng không phải là chức năng tôi khuyên dùng cho môi trường sản xuất (xem thêm về điều đó bên dưới).
CREATE FUNCTION dbo.SplitStrings_XML
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = y.i.value('(./text())[1]', 'nvarchar(4000)')
FROM
(
SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)
);
GO Một cảnh báo rất quan trọng phải đi cùng với cách tiếp cận XML:nó chỉ có thể được sử dụng nếu bạn có thể đảm bảo rằng chuỗi đầu vào của bạn không chứa bất kỳ ký tự XML bất hợp pháp nào. Một tên có dấu <,> hoặc &và hàm sẽ nổ tung. Vì vậy, bất kể hiệu suất như thế nào, nếu bạn định sử dụng phương pháp này, hãy lưu ý những hạn chế - nó không nên được coi là một lựa chọn khả thi cho bộ tách chuỗi chung. Tôi sẽ đưa nó vào phần tổng hợp này vì bạn có thể gặp trường hợp mà bạn có thể tin tưởng đầu vào - ví dụ:nó có thể được sử dụng cho danh sách các số nguyên hoặc GUID được phân tách bằng dấu phẩy.
Bảng số
Giải pháp này sử dụng bảng Numbers mà bạn phải tự xây dựng và điền vào. (Chúng tôi đã yêu cầu phiên bản cài sẵn cho các độ tuổi.) Bảng Numbers phải chứa đủ hàng để vượt quá độ dài của chuỗi dài nhất mà bạn sẽ tách. Trong trường hợp này, chúng tôi sẽ sử dụng 1.000.000 hàng:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 1000000;
WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
CROSS JOIN sys.all_objects AS s3
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number)
WITH (DATA_COMPRESSION = PAGE);
GO (Sử dụng tính năng nén dữ liệu sẽ giảm đáng kể số lượng trang cần thiết, nhưng rõ ràng bạn chỉ nên sử dụng tùy chọn này nếu bạn đang chạy Phiên bản Doanh nghiệp. Trong trường hợp này, dữ liệu nén yêu cầu 1.360 trang, so với 2.102 trang không nén - tiết kiệm khoảng 35%. )
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers
WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
Biểu thức bảng chung
Giải pháp này sử dụng một CTE đệ quy để trích xuất từng phần của chuỗi từ "phần còn lại" của phần trước đó. Là một CTE đệ quy với các biến cục bộ, bạn sẽ lưu ý rằng đây phải là một hàm có giá trị bảng nhiều câu lệnh, không giống như các hàm khác đều là nội tuyến.
CREATE FUNCTION dbo.SplitStrings_CTE
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
[start] = 1,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll),
[value] = SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll) - 1)
UNION ALL
SELECT
[start] = CONVERT(INT, [end]) + @ld,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll),
[value] = SUBSTRING(@List, [end] + @ld,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll)-[end]-@ld)
FROM a
WHERE [end] < @ll ) INSERT @Items SELECT [value] FROM a WHERE LEN([value]) > 0
OPTION (MAXRECURSION 0);
RETURN;
END
GO
Bộ tách của Jeff Moden Một chức năng dựa trên bộ tách của Jeff Moden với những thay đổi nhỏ để hỗ trợ các chuỗi dài hơn
Trên SQLServerCentral, Jeff Moden đã trình bày một hàm bộ tách sánh ngang với hiệu suất của CLR, vì vậy tôi nghĩ chỉ cần đưa một biến thể sử dụng cách tiếp cận tương tự vào vòng này là hợp lý. Tôi đã phải thực hiện một vài thay đổi nhỏ đối với chức năng của anh ấy để xử lý chuỗi dài nhất của chúng tôi (500.000 ký tự) và cũng thực hiện các quy ước đặt tên tương tự:
CREATE FUNCTION dbo.SplitStrings_Moden
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E42(N) AS (SELECT 1 FROM E4 a, E2 b),
cteTally(N) AS (SELECT 0 UNION ALL SELECT TOP (DATALENGTH(ISNULL(@List,1)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E42),
cteStart(N1) AS (SELECT t.N+1 FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0))
SELECT Item = SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter,@List,s.N1),0)-s.N1,8000))
FROM cteStart s; Ngoài ra, đối với những người sử dụng giải pháp của Jeff Moden, bạn có thể cân nhắc sử dụng bảng Numbers như trên và thử nghiệm với một chút thay đổi trong hàm của Jeff:
CREATE FUNCTION dbo.SplitStrings_Moden2
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH cteTally(N) AS
(
SELECT TOP (DATALENGTH(ISNULL(@List,1))+1) Number-1
FROM dbo.Numbers ORDER BY Number
),
cteStart(N1) AS
(
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0)
)
SELECT Item = SUBSTRING(@List, s.N1,
ISNULL(NULLIF(CHARINDEX(@Delimiter, @List, s.N1), 0) - s.N1, 8000))
FROM cteStart AS s; (Điều này sẽ trao đổi số lần đọc cao hơn một chút cho CPU thấp hơn một chút, vì vậy có thể tốt hơn tùy thuộc vào việc hệ thống của bạn đã được ràng buộc CPU hay I / O.)
Kiểm tra tình trạng
Chỉ để chắc chắn rằng chúng tôi đang đi đúng hướng, chúng tôi có thể xác minh rằng tất cả năm hàm đều trả về kết quả mong đợi:
DECLARE @s NVARCHAR(MAX) = N'Patriots,Red Sox,Bruins'; SELECT Item FROM dbo.SplitStrings_CLR (@s, N','); SELECT Item FROM dbo.SplitStrings_XML (@s, N','); SELECT Item FROM dbo.SplitStrings_Numbers (@s, N','); SELECT Item FROM dbo.SplitStrings_CTE (@s, N','); SELECT Item FROM dbo.SplitStrings_Moden (@s, N',');
Và trên thực tế, đây là những kết quả mà chúng tôi thấy trong cả năm trường hợp…

Dữ liệu thử nghiệm
Bây giờ chúng ta đã biết các hàm hoạt động như mong đợi, chúng ta có thể đến với phần thú vị:kiểm tra hiệu suất dựa trên nhiều chuỗi có độ dài khác nhau. Nhưng trước tiên chúng ta cần một cái bàn. Tôi đã tạo đối tượng đơn giản sau:
CREATE TABLE dbo.strings ( string_type TINYINT, string_value NVARCHAR(MAX) ); CREATE CLUSTERED INDEX st ON dbo.strings(string_type);
Tôi đã điền vào bảng này một tập hợp các chuỗi có độ dài khác nhau, đảm bảo rằng gần như cùng một tập dữ liệu sẽ được sử dụng cho mỗi thử nghiệm - 10.000 hàng đầu tiên trong đó chuỗi dài 50 ký tự, sau đó 1.000 hàng trong đó chuỗi dài 500 ký tự , 100 hàng trong đó chuỗi dài 5.000 ký tự, 10 hàng trong đó chuỗi dài 50.000 ký tự, v.v. lên đến 1 hàng 500.000 ký tự. Tôi đã làm điều này để so sánh cùng một lượng dữ liệu tổng thể đang được các chức năng xử lý, cũng như để cố gắng giữ cho thời gian thử nghiệm của tôi có thể dự đoán được phần nào.
Tôi sử dụng bảng #temp để có thể chỉ cần sử dụng GO
SET NOCOUNT ON; GO CREATE TABLE #x(s NVARCHAR(MAX)); INSERT #x SELECT N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; GO INSERT dbo.strings SELECT 1, s FROM #x; GO 10000 INSERT dbo.strings SELECT 2, REPLICATE(s,10) FROM #x; GO 1000 INSERT dbo.strings SELECT 3, REPLICATE(s,100) FROM #x; GO 100 INSERT dbo.strings SELECT 4, REPLICATE(s,1000) FROM #x; GO 10 INSERT dbo.strings SELECT 5, REPLICATE(s,10000) FROM #x; GO DROP TABLE #x; GO -- then to clean up the trailing comma, since some approaches treat a trailing empty string as a valid element: UPDATE dbo.strings SET string_value = SUBSTRING(string_value, 1, LEN(string_value)-1) + 'x';
Việc tạo và điền bảng này mất khoảng 20 giây trên máy của tôi và bảng biểu thị giá trị khoảng 6 MB dữ liệu (khoảng 500.000 ký tự nhân với 2 byte hoặc 1 MB cho mỗi string_type, cộng với chi phí hàng và chỉ mục). Không phải là một bảng lớn, nhưng nó phải đủ lớn để làm nổi bật bất kỳ sự khác biệt nào về hiệu suất giữa các chức năng.
Các bài kiểm tra
Với các chức năng đã có sẵn và bảng được nhồi đầy đủ các chuỗi lớn để nhai, cuối cùng chúng ta có thể chạy một số thử nghiệm thực tế để xem các chức năng khác nhau hoạt động như thế nào so với dữ liệu thực. Để đo lường hiệu suất mà không bao gồm chi phí mạng, tôi đã sử dụng SQL Sentry Plan Explorer, chạy mỗi bộ kiểm tra 10 lần, thu thập số liệu thời lượng và tính trung bình.
Thử nghiệm đầu tiên chỉ đơn giản là lấy các mục từ mỗi chuỗi thành một tập hợp:
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; DECLARE @string_type TINYINT = ; -- 1-5 from above SELECT t.Item FROM dbo.strings AS s CROSS APPLY dbo.SplitStrings_(s.string_value, ',') AS t WHERE s.string_type = @string_type;
Kết quả cho thấy rằng khi các dây lớn hơn, lợi thế của CLR thực sự tỏa sáng. Ở phần cuối, các kết quả được trộn lẫn, nhưng một lần nữa, phương thức XML phải có dấu hoa thị bên cạnh, vì việc sử dụng nó phụ thuộc vào việc dựa vào đầu vào an toàn với XML. Đối với trường hợp sử dụng cụ thể này, bảng Numbers luôn hoạt động kém nhất:
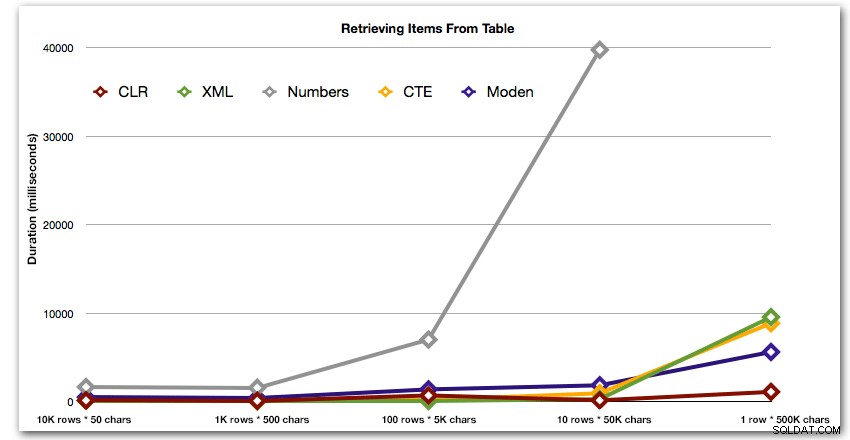
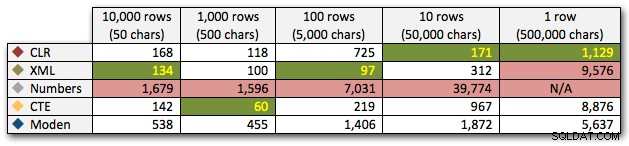
Thời lượng, tính bằng mili giây
Sau hiệu suất 40 giây hyperbolic cho bảng số so với 10 hàng gồm 50.000 ký tự, tôi đã loại bỏ nó khỏi lần chạy thử nghiệm cuối cùng. Để hiển thị tốt hơn hiệu suất tương đối của bốn phương pháp tốt nhất trong thử nghiệm này, tôi đã loại bỏ hoàn toàn các kết quả Số khỏi biểu đồ:
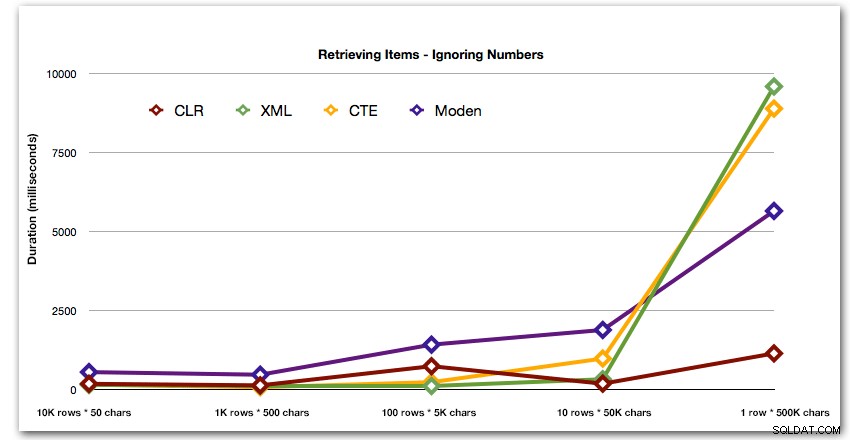
Tiếp theo, hãy so sánh khi chúng tôi thực hiện tìm kiếm với giá trị được phân tách bằng dấu phẩy (ví dụ:trả về các hàng có một trong các chuỗi là 'foo'). Một lần nữa, chúng tôi sẽ sử dụng năm chức năng ở trên, nhưng chúng tôi cũng sẽ so sánh kết quả với một tìm kiếm được thực hiện trong thời gian chạy bằng cách sử dụng LIKE thay vì bận tâm với việc chia nhỏ.
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
DECLARE @i INT = , @search NVARCHAR(32) = N'foo';
;WITH s(st, sv) AS
(
SELECT string_type, string_value
FROM dbo.strings AS s
WHERE string_type = @i
)
SELECT s.string_type, s.string_value FROM s
CROSS APPLY dbo.SplitStrings_(s.sv, ',') AS t
WHERE t.Item = @search;
SELECT s.string_type
FROM dbo.strings
WHERE string_type = @i
AND ',' + string_value + ',' LIKE '%,' + @search + ',%'; Những kết quả này cho thấy rằng, đối với các chuỗi nhỏ, CLR thực sự là chậm nhất và giải pháp tốt nhất là thực hiện quét bằng cách sử dụng LIKE mà không cần phải chia nhỏ dữ liệu. Một lần nữa, tôi lại bỏ giải pháp bảng Numbers từ cách tiếp cận thứ 5, khi rõ ràng rằng thời lượng của nó sẽ tăng theo cấp số nhân khi kích thước của chuỗi tăng lên:
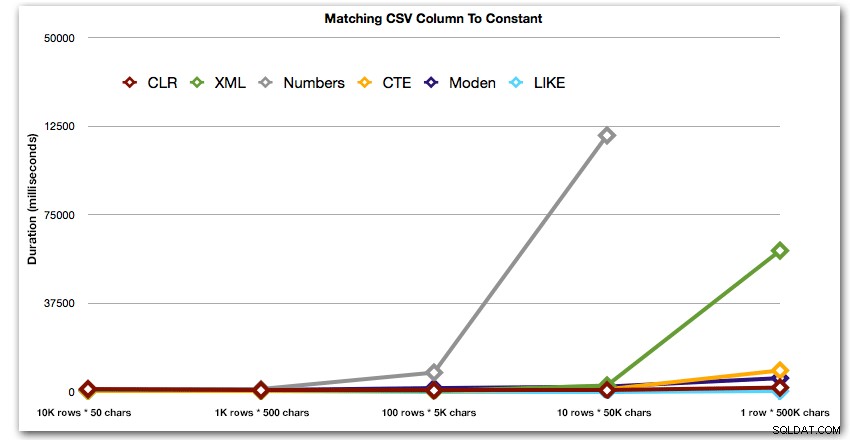
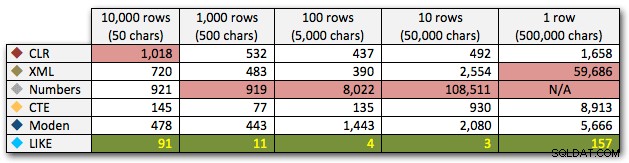
Thời lượng, tính bằng mili giây
Và để chứng minh tốt hơn các mẫu cho 4 kết quả hàng đầu, tôi đã loại bỏ các giải pháp Numbers và XML khỏi biểu đồ:
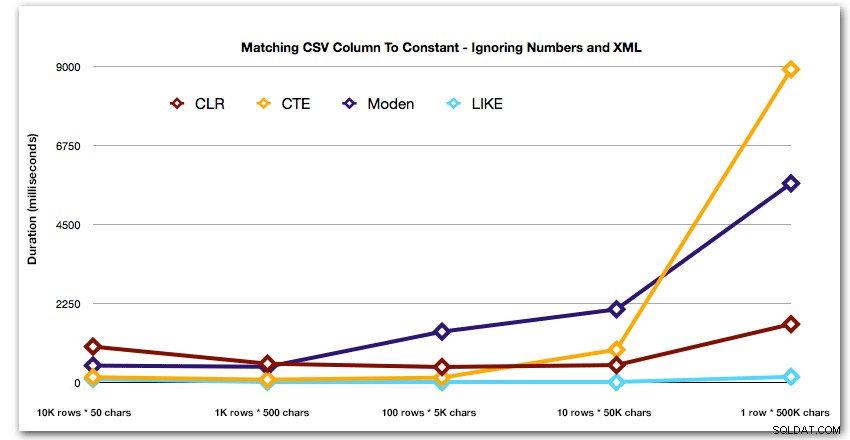
Tiếp theo, hãy xem xét việc tái tạo trường hợp sử dụng từ đầu bài đăng này, nơi chúng tôi đang cố gắng tìm tất cả các hàng trong một bảng tồn tại trong danh sách được chuyển vào. Cũng như dữ liệu trong bảng chúng tôi đã tạo ở trên, chúng tôi sẽ tạo các chuỗi có độ dài khác nhau từ 50 đến 500.000 ký tự, lưu trữ chúng trong một biến, sau đó kiểm tra chế độ xem danh mục chung xem có tồn tại trong danh sách hay không.
DECLARE
@i INT = , -- value 1-5, yielding strings 50 - 500,000 characters
@x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,';
SET @x = REPLICATE(@x, POWER(10, @i-1));
SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x';
SELECT c.[object_id]
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.SplitStrings_(@x, N',') AS x
WHERE Item = c.name
)
ORDER BY c.[object_id];
SELECT [object_id]
FROM sys.all_columns
WHERE N',' + @x + ',' LIKE N'%,' + name + ',%'
ORDER BY [object_id]; Các kết quả này cho thấy rằng, đối với mẫu này, một số phương pháp thấy thời lượng của chúng tăng lên theo cấp số nhân khi kích thước của chuỗi tăng lên. Ở cấp thấp hơn, XML giữ được tốc độ tốt với CLR, nhưng điều này cũng nhanh chóng xấu đi. CLR luôn là người chiến thắng rõ ràng ở đây:
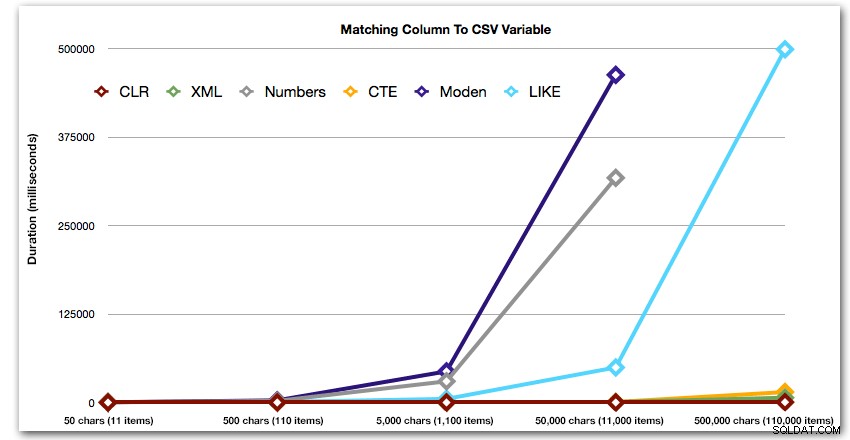
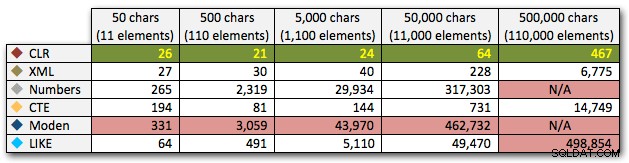
Thời lượng, tính bằng mili giây
Và một lần nữa, không có các phương pháp bùng nổ trở lên về thời lượng:
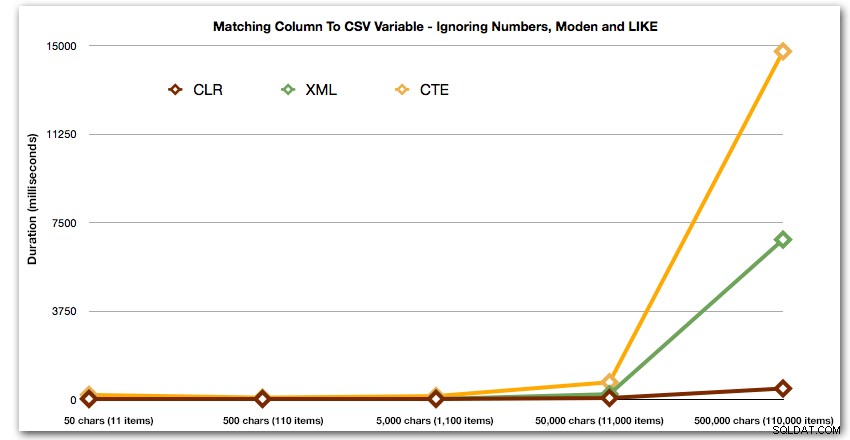
Cuối cùng, hãy so sánh chi phí truy xuất dữ liệu từ một biến duy nhất có độ dài khác nhau, bỏ qua chi phí đọc dữ liệu từ bảng. Một lần nữa, chúng tôi sẽ tạo các chuỗi có độ dài khác nhau, từ 50 - 500.000 ký tự và sau đó chỉ trả về các giá trị dưới dạng một tập hợp:
DECLARE @i INT = , -- value 1-5, yielding strings 50 - 500,000 characters @x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; SET @x = REPLICATE(@x, POWER(10, @i-1)); SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x'; SELECT Item FROM dbo.SplitStrings_(@x, N',');
Các kết quả này cũng cho thấy CLR khá ổn định về thời lượng, lên đến 110.000 mục trong bộ, trong khi các phương pháp khác giữ tốc độ khá cho đến một thời điểm sau 11.000 mục:
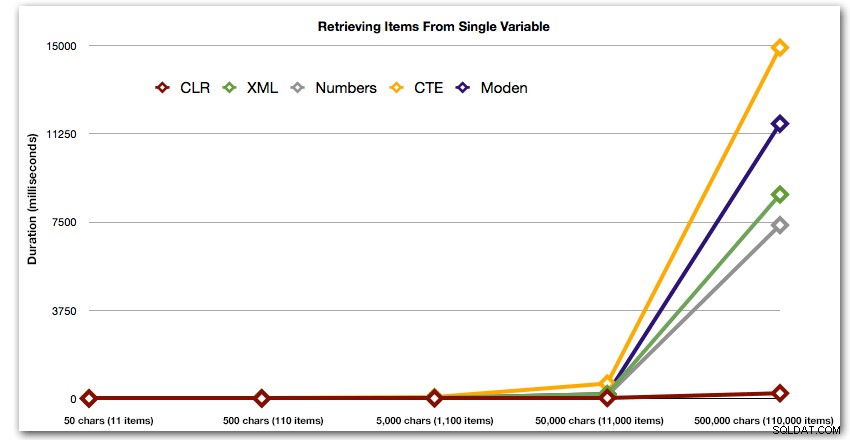
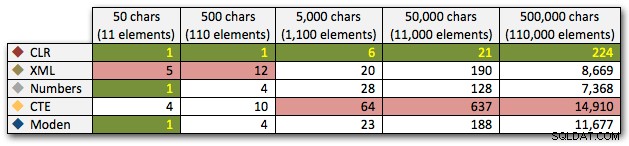
Thời lượng, tính bằng mili giây
Kết luận
Trong hầu hết các trường hợp, giải pháp CLR rõ ràng thực hiện tốt hơn các cách tiếp cận khác - trong một số trường hợp, đó là một chiến thắng vang dội, đặc biệt là khi kích thước chuỗi tăng lên; trong một số trường hợp khác, đó là một kết thúc ảnh có thể rơi theo một trong hai cách. Trong thử nghiệm đầu tiên, chúng tôi thấy rằng XML và CTE hoạt động tốt hơn CLR ở cấp thấp, vì vậy nếu đây là trường hợp sử dụng điển hình * và *, bạn chắc chắn rằng các chuỗi của mình nằm trong phạm vi 1 - 10.000 ký tự, một trong những cách tiếp cận đó có thể là một lựa chọn tốt hơn. Nếu kích thước chuỗi của bạn ít có khả năng dự đoán hơn thì CLR có lẽ vẫn là cách đặt cược tốt nhất của bạn về tổng thể - bạn mất vài mili giây ở mức thấp, nhưng bạn thu được rất nhiều ở mức cao. Dưới đây là các lựa chọn tôi sẽ thực hiện, tùy thuộc vào nhiệm vụ, với vị trí thứ hai được đánh dấu cho các trường hợp CLR không phải là một tùy chọn. Lưu ý rằng XML chỉ là phương pháp ưa thích của tôi nếu tôi biết đầu vào là XML an toàn; đây có thể không nhất thiết là lựa chọn thay thế tốt nhất của bạn nếu bạn không tin tưởng vào thông tin đầu vào của mình.
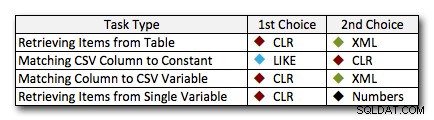
Ngoại lệ thực sự duy nhất mà CLR không phải là lựa chọn của tôi trên toàn bộ bảng là trường hợp bạn đang thực sự lưu trữ các danh sách được phân tách bằng dấu phẩy trong một bảng, sau đó tìm các hàng có một thực thể được xác định trong danh sách đó. Trong trường hợp cụ thể đó, trước tiên tôi có thể khuyên bạn nên thiết kế lại và chuẩn hóa đúng cách lược đồ để các giá trị đó được lưu trữ riêng biệt, thay vì sử dụng nó như một cái cớ để không sử dụng CLR để phân tách.
Nếu bạn không thể sử dụng CLR vì những lý do khác, thì không có "vị trí thứ hai" rõ ràng nào được tiết lộ bởi những thử nghiệm này; các câu trả lời của tôi ở trên dựa trên quy mô tổng thể chứ không phải ở bất kỳ kích thước chuỗi cụ thể nào. Mọi giải pháp ở đây đều được đưa ra trong ít nhất một tình huống - vì vậy mặc dù CLR rõ ràng là sự lựa chọn khi bạn có thể sử dụng nó, nhưng điều bạn nên sử dụng khi không thể chỉ là một câu trả lời "nó phụ thuộc" - bạn sẽ cần phải đánh giá dựa trên (các) trường hợp sử dụng của bạn và các thử nghiệm ở trên (hoặc bằng cách xây dựng các thử nghiệm của riêng bạn), lựa chọn thay thế nào tốt hơn cho bạn.
Phần bổ sung:Một giải pháp thay thế cho việc chia nhỏ ở vị trí đầu tiên
Các phương pháp trên không yêu cầu thay đổi đối với (các) ứng dụng hiện có của bạn, giả sử rằng chúng đã tập hợp một chuỗi được phân tách bằng dấu phẩy và ném nó vào cơ sở dữ liệu để xử lý. Một tùy chọn bạn nên xem xét, nếu CLR không phải là một tùy chọn và / hoặc bạn có thể sửa đổi (các) ứng dụng, đó là sử dụng Tham số giá trị bảng (TVP). Dưới đây là một ví dụ nhanh về cách sử dụng TVP trong bối cảnh trên. Đầu tiên, hãy tạo một loại bảng với một cột chuỗi đơn:
CREATE TYPE dbo.Items AS TABLE ( Item NVARCHAR(4000) );
Sau đó, thủ tục được lưu trữ có thể lấy TVP này làm đầu vào và tham gia vào nội dung (hoặc sử dụng nó theo các cách khác - đây chỉ là một ví dụ):
CREATE PROCEDURE dbo.UpdateProfile
@UserID INT,
@TeamNames dbo.Items READONLY
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, t.TeamID
FROM dbo.Teams AS t
INNER JOIN @TeamNames AS tn
ON t.Name = tn.Item;
END
GO Bây giờ, trong mã C # của bạn, chẳng hạn, thay vì tạo một chuỗi được phân tách bằng dấu phẩy, hãy điền một DataTable (hoặc sử dụng bất kỳ bộ sưu tập tương thích nào có thể đã giữ bộ giá trị của bạn):
DataTable tvp = new DataTable();
tvp.Columns.Add(new DataColumn("Item"));
// in a loop from a collection, presumably:
tvp.Rows.Add(someThing.someValue);
using (connectionObject)
{
SqlCommand cmd = new SqlCommand("dbo.UpdateProfile", connectionObject);
cmd.CommandType = CommandType.StoredProcedure;
SqlParameter tvparam = cmd.Parameters.AddWithValue("@TeamNames", tvp);
tvparam.SqlDbType = SqlDbType.Structured;
// other parameters, e.g. userId
cmd.ExecuteNonQuery();
} Bạn có thể coi đây là phần tiền truyện của một bài đăng tiếp theo.
Tất nhiên điều này không hoạt động tốt với JSON và các API khác - thường là lý do khiến một chuỗi được phân tách bằng dấu phẩy được chuyển đến SQL Server ngay từ đầu.