Dữ liệu ngày và giờ đấu giá liên quan đến việc tổ chức dữ liệu theo nhóm đại diện cho các khoảng thời gian cố định cho mục đích phân tích. Thông thường, đầu vào là dữ liệu chuỗi thời gian được lưu trữ trong bảng trong đó các hàng đại diện cho các phép đo được thực hiện trong các khoảng thời gian đều đặn. Ví dụ:các phép đo có thể là các bài đọc về nhiệt độ và độ ẩm được thực hiện cứ sau 5 phút và bạn muốn nhóm dữ liệu bằng cách sử dụng các nhóm hàng giờ và tính toán các tổng hợp như trung bình mỗi giờ. Mặc dù dữ liệu chuỗi thời gian là nguồn phổ biến cho phân tích dựa trên nhóm, nhưng khái niệm này cũng phù hợp với bất kỳ dữ liệu nào liên quan đến thuộc tính ngày và giờ và các thước đo liên quan. Ví dụ:bạn có thể muốn tổ chức dữ liệu bán hàng theo nhóm năm tài chính và tính toán các tổng hợp như tổng giá trị bán hàng mỗi năm tài chính. Trong bài viết này, tôi đề cập đến hai phương pháp đấu giá dữ liệu ngày và giờ. Một người đang sử dụng một hàm có tên DATE_BUCKET, hàm này tại thời điểm viết bài này chỉ khả dụng trong Azure SQL Edge. Một cách khác là sử dụng một phép tính tùy chỉnh mô phỏng hàm DATE_BUCKET, bạn có thể sử dụng hàm này trong bất kỳ phiên bản, phiên bản và phiên bản nào của SQL Server và Azure SQL Database.
Trong các ví dụ của mình, tôi sẽ sử dụng cơ sở dữ liệu mẫu TSQLV5. Bạn có thể tìm thấy tập lệnh tạo và điền TSQLV5 tại đây và sơ đồ ER của nó tại đây.
DATE_BUCKET
Như đã đề cập, hàm DATE_BUCKET hiện chỉ khả dụng trong Azure SQL Edge. SQL Server Management Studio đã có hỗ trợ IntelliSense, như trong Hình 1:
 Hình 1:Hỗ trợ Intellisence cho DATE_BUCKET trong SSMS
Hình 1:Hỗ trợ Intellisence cho DATE_BUCKET trong SSMS
Cú pháp của hàm như sau:
DATE_BUCKET (Đầu vào nguồn gốc đại diện cho một điểm neo trên mũi tên thời gian. Nó có thể thuộc bất kỳ kiểu dữ liệu ngày và giờ nào được hỗ trợ. Nếu không xác định, giá trị mặc định là 1900, ngày 1 tháng 1, nửa đêm. Sau đó, bạn có thể tưởng tượng dòng thời gian được chia thành các khoảng rời rạc bắt đầu bằng điểm gốc, trong đó độ dài của mỗi khoảng dựa trên đầu vào chiều rộng nhóm và phần ngày . Cái trước là số lượng và cái sau là đơn vị. Ví dụ:để tổ chức tiến trình theo đơn vị 2 tháng, bạn sẽ chỉ định 2 dưới dạng chiều rộng thùng đầu vào và tháng làm phần ngày đầu vào.
Đầu vào dấu thời gian là một thời điểm tùy ý cần được liên kết với thùng chứa của nó. Kiểu dữ liệu của nó cần phải khớp với kiểu dữ liệu của đầu vào origin . Đầu vào dấu thời gian là giá trị ngày và giờ được liên kết với các số đo bạn đang nắm bắt.
Đầu ra của hàm sau đó là điểm bắt đầu của thùng chứa. Kiểu dữ liệu của đầu ra là kiểu của đầu vào dấu thời gian .
Nếu nó chưa rõ ràng, thông thường bạn sẽ sử dụng hàm DATE_BUCKET làm phần tử nhóm nhóm trong mệnh đề GROUP BY của truy vấn và tự nhiên trả lại nó trong danh sách CHỌN cùng với các số đo tổng hợp.
Vẫn còn một chút bối rối về chức năng, đầu vào và đầu ra của nó? Có thể một ví dụ cụ thể với mô tả trực quan về logic của hàm sẽ hữu ích. Tôi sẽ bắt đầu với một ví dụ sử dụng các biến đầu vào và ở phần sau của bài viết sẽ trình bày cách điển hình hơn mà bạn sẽ sử dụng nó như một phần của truy vấn đối với bảng đầu vào.
Hãy xem xét ví dụ sau:
DECLARE @timestamp AS DATETIME2 ='20210510 06:30:00', @bucketwidth AS INT =2, @origin AS DATETIME2 ='20210115 00:00:00'; CHỌN DATE_BUCKET (tháng, @bucketwidth, @timestamp, @origin);
Bạn có thể tìm thấy mô tả trực quan về logic của hàm trong Hình 2.
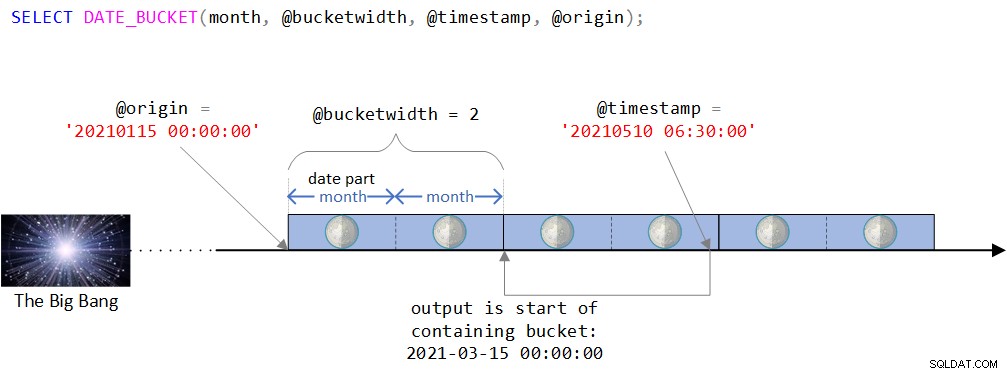 Hình 2:Mô tả trực quan logic của hàm DATE_BUCKET
Hình 2:Mô tả trực quan logic của hàm DATE_BUCKET
Như bạn có thể thấy trong Hình 2, điểm gốc là giá trị DATETIME2 ngày 15 tháng 1 năm 2021, nửa đêm. Nếu điểm gốc này có vẻ hơi kỳ quặc, bạn sẽ đúng khi cảm nhận bằng trực giác rằng thông thường bạn sẽ sử dụng điểm gốc tự nhiên hơn như đầu năm hoặc đầu một ngày nào đó. Trên thực tế, bạn thường hài lòng với mặc định, như bạn nhớ lại là ngày 1 tháng 1 năm 1900 lúc nửa đêm. Tôi cố ý muốn sử dụng một điểm gốc ít tầm thường hơn để có thể thảo luận về một số điểm phức tạp nhất định có thể không liên quan khi sử dụng điểm gốc tự nhiên hơn. Sẽ sớm có thêm thông tin về điều này.
Sau đó, mốc thời gian được chia thành các khoảng thời gian 2 tháng rời rạc bắt đầu từ điểm gốc. Dấu thời gian đầu vào là giá trị DATETIME2 ngày 10 tháng 5 năm 2021, 6:30 sáng.
Quan sát rằng dấu thời gian đầu vào là một phần của nhóm bắt đầu vào nửa đêm ngày 15 tháng 3 năm 2021. Thật vậy, hàm trả về giá trị này dưới dạng giá trị được nhập kiểu DATETIME2:
--------------------------- 2021-03-15 00:00:00.0000000
Mô phỏng DATE_BUCKET
Trừ khi bạn đang sử dụng Azure SQL Edge, nếu bạn muốn đấu giá dữ liệu ngày và giờ, thì trong lúc này, bạn cần tạo giải pháp tùy chỉnh của riêng mình để mô phỏng chức năng DATE_BUCKET hoạt động. Làm như vậy không quá phức tạp nhưng cũng không quá đơn giản. Xử lý dữ liệu ngày và giờ thường liên quan đến logic phức tạp và những cạm bẫy mà bạn cần phải cẩn thận.
Tôi sẽ xây dựng phép tính theo các bước và sử dụng các đầu vào giống như tôi đã sử dụng với ví dụ DATE_BUCKET mà tôi đã hiển thị trước đó:
DECLARE @timestamp AS DATETIME2 ='20210510 06:30:00', @bucketwidth AS INT =2, @origin AS DATETIME2 ='20210115 00:00:00';
Đảm bảo bạn bao gồm phần này trước mỗi mẫu mã mà tôi sẽ hiển thị nếu bạn thực sự muốn chạy mã.
Ở Bước 1, bạn sử dụng hàm DATEDIFF để tính toán sự khác biệt trong phần ngày đơn vị giữa nguồn gốc và dấu thời gian . Tôi sẽ gọi sự khác biệt này là diff1 . Điều này được thực hiện với đoạn mã sau:
CHỌN DATEDIFF (tháng, @origin, @timestamp) AS diff1;
Với đầu vào mẫu của chúng tôi, biểu thức này trả về 4.
Phần khó ở đây là bạn cần phải tính toán có bao nhiêu đơn vị nguyên của phần ngày tồn tại giữa nguồn gốc và dấu thời gian . Với các đầu vào mẫu của chúng tôi, có 3 tháng giữa hai và không phải 4. Lý do hàm DATEDIFF báo cáo 4 là khi nó tính toán sự khác biệt, nó chỉ xem xét phần được yêu cầu của đầu vào và các phần cao hơn chứ không xem xét các phần thấp hơn . Vì vậy, khi bạn yêu cầu sự khác biệt trong các tháng, hàm chỉ quan tâm đến phần năm và tháng của đầu vào chứ không quan tâm đến phần bên dưới tháng (ngày, giờ, phút, giây, v.v.). Thật vậy, có 4 tháng từ tháng 1 năm 2021 đến tháng 5 năm 2021, nhưng chỉ có 3 tháng giữa các đầu vào đầy đủ.
Sau đó, mục đích của Bước 2 là tính toán có bao nhiêu đơn vị nguyên của phần ngày tồn tại giữa nguồn gốc và dấu thời gian . Tôi sẽ gọi sự khác biệt này là diff2 . Để đạt được điều này, bạn có thể thêm diff1 đơn vị của phần ngày đến nguồn gốc . Nếu kết quả lớn hơn dấu thời gian , bạn trừ 1 từ diff1 để tính toán diff2 , nếu không thì trừ 0 và do đó sử dụng diff1 as diff2 . Điều này có thể được thực hiện bằng cách sử dụng biểu thức CASE, như sau:
CHỌN DATEDIFF (tháng, @origin, @timestamp) - TRƯỜNG HỢP KHI DATEADD (tháng, DATEDIFF (tháng, @origin, @timestamp), @origin)> @timestamp THEN 1 ELSE 0 END AS diff2;
Biểu thức này trả về 3, là số tháng nguyên giữa hai đầu vào.
Nhớ lại rằng trước đó tôi đã đề cập rằng trong ví dụ của tôi, tôi đã cố ý sử dụng một điểm gốc không phải là điểm tự nhiên như điểm bắt đầu một chu kỳ để tôi có thể thảo luận về những phức tạp nhất định mà sau đó có thể có liên quan. Ví dụ:nếu bạn sử dụng tháng dưới dạng phần ngày và bắt đầu chính xác của tháng nào đó (1 của tháng nào đó lúc nửa đêm) làm điểm gốc, bạn có thể an toàn bỏ qua Bước 2 và sử dụng diff1 as diff2 . Đó là bởi vì nguồn gốc + diff1 không bao giờ có thể là> dấu thời gian trong trường hợp như vậy. Tuy nhiên, mục tiêu của tôi là cung cấp một giải pháp thay thế tương đương về mặt logic cho hàm DATE_BUCKET sẽ hoạt động chính xác cho bất kỳ điểm gốc nào, phổ biến hay không. Vì vậy, tôi sẽ bao gồm logic cho Bước 2 trong các ví dụ của mình, nhưng chỉ cần nhớ khi bạn xác định các trường hợp mà bước này không liên quan, bạn có thể loại bỏ một cách an toàn phần mà bạn trừ đầu ra của biểu thức CASE.
Ở Bước 3, bạn xác định có bao nhiêu đơn vị của phần ngày có trong toàn bộ nhóm tồn tại giữa nguồn gốc và dấu thời gian . Tôi sẽ gọi giá trị này là diff3 . Điều này có thể được thực hiện với công thức sau:
diff3 =diff2 /*
Mẹo ở đây là khi sử dụng toán tử chia / trong T-SQL với các toán hạng số nguyên, bạn sẽ nhận được phép chia số nguyên. Ví dụ, 3/2 trong T-SQL là 1 chứ không phải 1,5. Biểu thức diff2 /
CHỌN (DATEDIFF (tháng, @origin, @timestamp) - TRƯỜNG HỢP KHI DATEADD (tháng, DATEDIFF (tháng, @origin, @timestamp), @origin)> @timestamp THEN 1 ELSE 0 END) / @bucketwidth * @ băng thông AS diff3;
Biểu thức này trả về 2, là số tháng trong toàn bộ nhóm 2 tháng tồn tại giữa hai đầu vào.
Ở Bước 4, là bước cuối cùng, bạn thêm diff3 đơn vị của phần ngày đến nguồn gốc để tính thời gian bắt đầu của thùng chứa. Đây là mã để đạt được điều này:
CHỌN DATEADD (tháng, (DATEDIFF (tháng, @origin, @timestamp) - TRƯỜNG HỢP KHI DATEADD (tháng, DATEDIFF (tháng, @origin, @timestamp), @origin)> @timestamp THEN 1 ELSE 0 END) / @bucketwidth * @bucketwidth, @origin);
Mã này tạo ra kết quả sau:
--------------------------- 2021-03-15 00:00:00.0000000
Như bạn nhớ lại, đây là cùng một đầu ra được tạo bởi hàm DATE_BUCKET cho các đầu vào giống nhau.
Tôi khuyên bạn nên thử biểu thức này với các đầu vào và các bộ phận khác nhau. Tôi sẽ đưa ra một vài ví dụ ở đây, nhưng hãy thử của riêng bạn.
Đây là một ví dụ về nguồn gốc chỉ đi trước dấu thời gian một chút trong tháng:
DECLARE @timestamp AS DATETIME2 ='20210510 06:30:00', @bucketwidth AS INT =2, @origin AS DATETIME2 ='20210110 06:30:01'; - CHỌN DATE_BUCKET (tuần, @bucketwidth, @timestamp, @origin); CHỌN DATEADD (tháng, (DATEDIFF (tháng, @origin, @timestamp) - TRƯỜNG HỢP KHI DATEADD (tháng, DATEDIFF (tháng, @origin, @timestamp), @origin)> @timestamp THEN 1 ELSE 0 END) / @bucketwidth * @bucketwidth, @origin);
Mã này tạo ra kết quả sau:
--------------------------- 2021-03-10 06:30:01.0000000
Lưu ý rằng thời điểm bắt đầu nhóm chứa là vào tháng 3.
Đây là một ví dụ về nguồn gốc ở cùng một điểm trong tháng là dấu thời gian :
DECLARE @timestamp AS DATETIME2 ='20210510 06:30:00', @bucketwidth AS INT =2, @origin AS DATETIME2 ='20210110 06:30:00'; - CHỌN DATE_BUCKET (tuần, @bucketwidth, @timestamp, @origin); CHỌN DATEADD (tháng, (DATEDIFF (tháng, @origin, @timestamp) - TRƯỜNG HỢP KHI DATEADD (tháng, DATEDIFF (tháng, @origin, @timestamp), @origin)> @timestamp THEN 1 ELSE 0 END) / @bucketwidth * @bucketwidth, @origin);
Mã này tạo ra kết quả sau:
--------------------------- 2021-05-10 06:30:00.0000000
Lưu ý rằng lần này thời điểm bắt đầu nhóm chứa là vào tháng 5.
Dưới đây là một ví dụ về giới hạn 4 tuần:
DECLARE @timestamp AS DATETIME2 ='20210303 21:22:11', @bucketwidth AS INT =4, @origin AS DATETIME2 ='20210115'; - CHỌN DATE_BUCKET (tuần, @bucketwidth, @timestamp, @origin); CHỌN DATEADD (tuần, (DATEDIFF (tuần, @origin, @timestamp) - TRƯỜNG HỢP KHI DATEADD (tuần, DATEDIFF (tuần, @origin, @timestamp), @origin)> @timestamp THEN 1 ELSE 0 END) / @bucketwidth * @bucketwidth, @origin);
Lưu ý rằng mã sử dụng tuần một phần thời gian này.
Mã này tạo ra kết quả sau:
--------------------------- 2021-02-12 00:00:00.0000000
Dưới đây là một ví dụ với nhóm 15 phút:
DECLARE @timestamp AS DATETIME2 ='20210203 21:22:11', @bucketwidth AS INT =15, @origin AS DATETIME2 ='19000101'; - CHỌN DATE_BUCKET (phút, @bucketwidth, @timestamp); CHỌN DATEADD (phút, (DATEDIFF (phút, @origin, @timestamp) - TRƯỜNG HỢP KHI DATEADD (phút, DATEDIFF (phút, @origin, @timestamp), @origin)> @timestamp THEN 1 ELSE 0 END) / @bucketwidth * @bucketwidth, @origin);
Mã này tạo ra kết quả sau:
--------------------------- 2021-02-03 21:15:00.0000000
Lưu ý rằng phần là phút . Trong ví dụ này, bạn muốn sử dụng giới hạn 15 phút bắt đầu từ cuối giờ, vì vậy điểm gốc là cuối của bất kỳ giờ nào sẽ hoạt động. Trên thực tế, một điểm gốc có đơn vị phút là 00, 15, 30 hoặc 45 với các số không ở các phần thấp hơn, với bất kỳ ngày và giờ nào sẽ hoạt động. Vì vậy, mặc định mà hàm DATE_BUCKET sử dụng cho đầu vào origin sẽ hoạt động. Tất nhiên, khi sử dụng biểu thức tùy chỉnh, bạn phải rõ ràng về điểm gốc. Vì vậy, để thông cảm với hàm DATE_BUCKET, bạn có thể sử dụng ngày gốc vào lúc nửa đêm như tôi làm trong ví dụ trên.
Ngẫu nhiên, bạn có thể thấy tại sao đây sẽ là một ví dụ điển hình khi bỏ qua Bước 2 trong giải pháp là hoàn toàn an toàn không? Nếu bạn thực sự chọn bỏ qua Bước 2, bạn sẽ nhận được mã sau:
DECLARE @timestamp AS DATETIME2 ='20210203 21:22:11', @bucketwidth AS INT =15, @origin AS DATETIME2 ='19000101'; - CHỌN DATE_BUCKET (phút, @bucketwidth, @timestamp); CHỌN DATEADD (phút, (DATEDIFF (phút, @origin, @timestamp)) / @bucketwidth * @bucketwidth, @origin);
Rõ ràng, mã trở nên đơn giản hơn đáng kể khi không cần đến Bước 2.
Nhóm và tổng hợp dữ liệu theo giới hạn ngày và giờ
Có những trường hợp bạn cần mua dữ liệu ngày và giờ không yêu cầu các hàm phức tạp hoặc các biểu thức khó sử dụng. Ví dụ:giả sử bạn muốn truy vấn chế độ xem Sales.OrderValues trong cơ sở dữ liệu TSQLV5, nhóm dữ liệu hàng năm và tính tổng giá trị và số lượng đơn đặt hàng mỗi năm. Rõ ràng, chỉ cần sử dụng hàm YEAR (ngày đặt hàng) làm phần tử nhóm nhóm, như sau:
SỬ DỤNG TSQLV5; CHỌN NĂM (ngày đặt hàng) NHƯ năm đơn hàng, ĐẾM (*) NHƯ số lượng, SUM (val) NHƯ tổng giá trịMã này tạo ra kết quả sau:
tổng giá trị số lượng đơn hàng năm ----------- ----------- ----------- 2017 152 208083.992018 408 617085.302019 270 440623,93Nhưng điều gì sẽ xảy ra nếu bạn muốn bán đấu giá dữ liệu vào năm tài chính của tổ chức mình? Một số tổ chức sử dụng năm tài chính cho các mục đích kế toán, ngân sách và báo cáo tài chính, không phù hợp với năm dương lịch. Ví dụ:giả sử năm tài chính của tổ chức bạn hoạt động theo lịch tài chính từ tháng 10 đến tháng 9 và được biểu thị bằng năm dương lịch mà năm tài chính kết thúc. Vậy một sự kiện diễn ra vào ngày 3/10/2018 thuộc năm tài chính bắt đầu từ ngày 1/10/2018, kết thúc vào ngày 30/9/2019 và được ký hiệu là năm 2019.
Điều này khá dễ dàng đạt được với hàm DATE_BUCKET, như sau:
DECLARE @bucketwidth AS INT =1, @origin AS DATETIME2 ='19001001'; - đây là ngày 1 tháng 10 của năm nào đó CHỌN NĂM (startofbucket) + 1 NHƯ năm tài chính, COUNT (*) AS số, SUM (val) NHƯ tổng giá trị origin))) NHƯ MỘT (startofbucket) NHÓM BỞI startofbucketORDER BY startofbucket;Và đây là mã sử dụng tương đương lôgic tùy chỉnh của hàm DATE_BUCKET:
DECLARE @bucketwidth AS INT =1, @origin AS DATETIME2 ='19001001'; - đây là ngày 1 tháng 10 của năm nào đó CHỌN NĂM (startofbucket) + 1 NHƯ năm tài chính, ĐẾM (*) NHƯ số, SUM (val) NHƯ tổng giá trị origin, orderdate) - CASE WHEN DATEADD (year, DATEDIFF (year, @origin, orderdate), @origin)> orderdate THEN 1 ELSE 0 END) / @bucketwidth * @bucketwidth, @origin))) NHƯ A (startofbucket) NHÓM THEO startofbucketORDER BỞI startofbucket;Mã này tạo ra kết quả sau:
tổng giá trị các số trong năm tài chính ------------- ---------------- 2017 70 79728.582018 370 563759.242019 390 622305.40Tôi đã sử dụng các biến ở đây cho chiều rộng nhóm và điểm gốc để làm cho mã tổng quát hơn, nhưng bạn có thể thay thế các biến đó bằng hằng số nếu bạn luôn sử dụng các biến giống nhau và sau đó đơn giản hóa việc tính toán khi thích hợp.
Như một biến thể nhỏ ở trên, giả sử năm tài chính của bạn kéo dài từ ngày 15 tháng 7 của một năm dương lịch đến ngày 14 tháng 7 của năm dương lịch tiếp theo và được biểu thị bằng năm dương lịch mà đầu năm tài chính đó thuộc về. Vì vậy, sự kiện diễn ra vào ngày 18 tháng 7 năm 2018 thuộc năm tài chính 2018. Sự kiện diễn ra vào ngày 14 tháng 7 năm 2018 thuộc năm tài chính 2017. Sử dụng hàm DATE_BUCKET, bạn sẽ đạt được điều này như sau:
DECLARE @bucketwidth AS INT =1, @origin AS DATETIME2 ='19000715'; - Ngày 15 tháng 7 đánh dấu bắt đầu năm tài chính CHỌN NĂM (startofbucket) NHƯ năm tài chính, - không cần thêm 1 ở đây COUNT (*) AS số, SUM (val) AS tổng giá trị @bucketwidth, orderdate, @origin))) NHƯ MỘT (startofbucket) NHÓM THEO startofbucketORDER BỞI startofbucket;Bạn có thể thấy những thay đổi so với ví dụ trước trong phần nhận xét.
Và đây là mã sử dụng logic tùy chỉnh tương đương với hàm DATE_BUCKET:
DECLARE @bucketwidth AS INT =1, @origin AS DATETIME2 ='19000715'; CHỌN NĂM (startofbucket) NHƯ năm tài chính, COUNT (*) AS số, SUM (val) AS tổng giá trị DATEDIFF (year, @origin, orderdate), @origin)> orderdate THEN 1 ELSE 0 END) / @bucketwidth * @bucketwidth, @origin))) NHƯ A (startofbucket) NHÓM BỞI startofbucketORDER BY startofbucket;Mã này tạo ra kết quả sau:
tổng giá trị các số trong năm tài chính ------------- ---------------- 2016 8 12599.882017 343 495118.142018 479 758075.20Rõ ràng, có những phương pháp thay thế bạn có thể sử dụng trong các trường hợp cụ thể. Lấy ví dụ trước cái cuối cùng, trong đó năm tài chính kéo dài từ tháng 10 đến tháng 9 và được biểu thị bằng năm dương lịch mà năm tài chính kết thúc. Trong trường hợp này, bạn có thể sử dụng biểu thức sau, đơn giản hơn nhiều:
NĂM (ngày đặt hàng) + TRƯỜNG HỢP KHI THÁNG (ngày đặt hàng) GIỮA 10 VÀ 12 THÌ 1 LẦN 0 KẾT THÚCVà sau đó truy vấn của bạn sẽ giống như sau:
CHỌN năm tài chính, COUNT (*) AS số, SUM (val) AS tổng giá trị NHÓM A (năm tài chính) THEO năm tài chính THEO năm tài chính;Tuy nhiên, nếu bạn muốn một giải pháp tổng quát có thể hoạt động trong nhiều trường hợp hơn và bạn có thể tham số hóa, thì đương nhiên bạn sẽ muốn sử dụng dạng tổng quát hơn. Nếu bạn có quyền truy cập vào chức năng DATE_BUCKET, điều đó thật tuyệt. Nếu không, bạn có thể sử dụng logic tương đương tùy chỉnh.
Kết luận
Hàm DATE_BUCKET là một chức năng khá tiện dụng cho phép bạn bán dữ liệu ngày và giờ. Nó hữu ích để xử lý dữ liệu chuỗi thời gian, nhưng cũng để bán đấu giá bất kỳ dữ liệu nào liên quan đến thuộc tính ngày và giờ. Trong bài viết này, tôi đã giải thích cách hoạt động của hàm DATE_BUCKET và cung cấp hàm tương đương logic tùy chỉnh trong trường hợp nền tảng bạn đang sử dụng không hỗ trợ nó.



