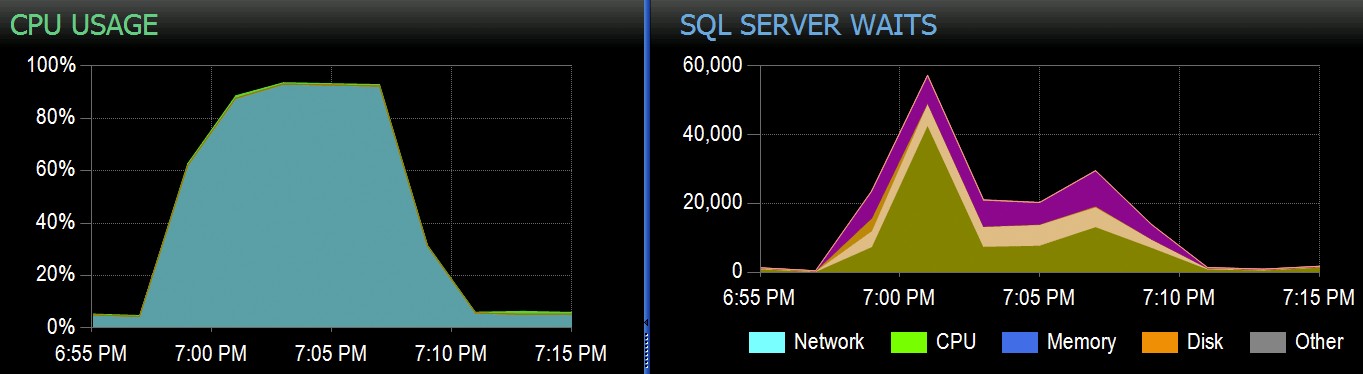
Tại Stack Overflow, chúng tôi có một số bảng sử dụng các chỉ mục columnstore được phân cụm và những bảng này hoạt động hiệu quả đối với phần lớn khối lượng công việc của chúng tôi. Nhưng gần đây chúng tôi đã gặp phải một tình huống mà "cơn bão hoàn hảo" - nhiều quy trình cố gắng xóa khỏi cùng một CCI - sẽ áp đảo CPU vì tất cả chúng đều hoạt động song song và chiến đấu để hoàn thành hoạt động của mình. Đây là những gì nó trông như thế nào trong SolarWinds SQL Sentry:
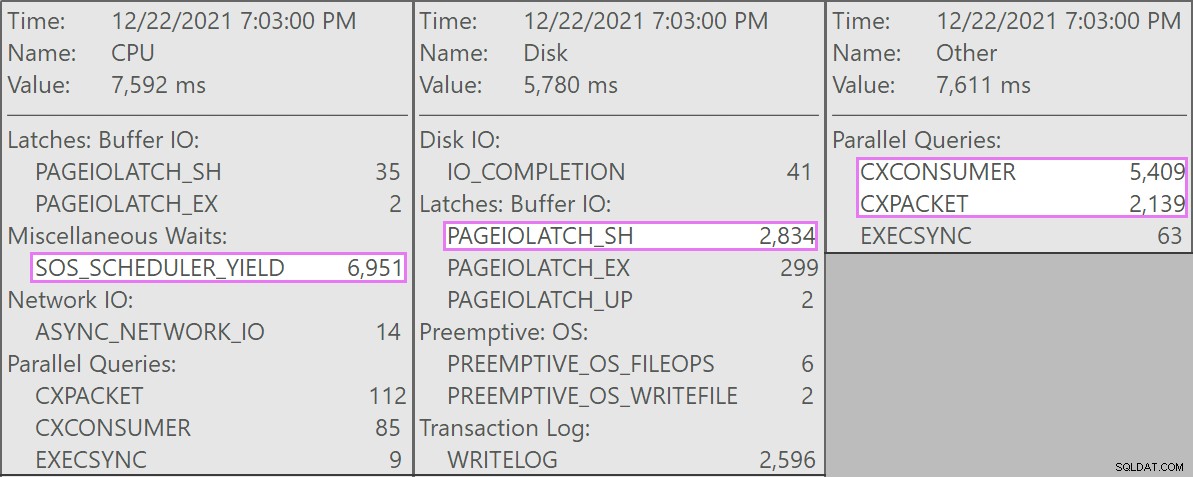
Và đây là những chờ đợi thú vị liên quan đến những truy vấn này:
Các truy vấn cạnh tranh đều ở dạng này:
DELETE dbo.LargeColumnstoreTable WHERE col1 = @p1 AND col2 = @p2;
Kế hoạch trông như thế này:

Và cảnh báo trên bản quét đã cho chúng tôi biết về một số I / O dư khá cực đoan:

Bảng có 1,9 tỷ hàng nhưng chỉ có 32GB (cảm ơn bạn, bộ nhớ dạng cột!). Tuy nhiên, các thao tác xóa một hàng này sẽ mất 10 - 15 giây mỗi lần, với phần lớn thời gian này được dành cho SOS_SCHEDULER_YIELD .
Rất may, vì trong trường hợp này, thao tác xóa có thể không đồng bộ, chúng tôi có thể giải quyết vấn đề bằng hai thay đổi (mặc dù tôi đang đơn giản hóa quá mức ở đây):
- Chúng tôi giới hạn
MAXDOPở cấp cơ sở dữ liệu, do đó, các thao tác xóa này không thể diễn ra song song như vậy - Chúng tôi đã cải thiện việc tuần tự hóa các quy trình đến từ ứng dụng (về cơ bản, chúng tôi đã xếp hàng đợi xóa thông qua một người điều phối duy nhất)
Là một DBA, chúng tôi có thể dễ dàng kiểm soát MAXDOP , trừ khi nó bị ghi đè ở cấp truy vấn (một lỗ thỏ khác cho một ngày khác). Chúng tôi không nhất thiết phải kiểm soát ứng dụng ở mức độ này, đặc biệt nếu ứng dụng đó được phân phối hoặc không phải của chúng tôi. Làm thế nào chúng ta có thể tuần tự hóa các lần ghi trong trường hợp này mà không thay đổi đáng kể logic ứng dụng?
Thiết lập Mock
Tôi sẽ không cố gắng tạo cục bộ một bảng hai tỷ hàng - đừng bận tâm đến bảng chính xác - nhưng chúng tôi có thể ước lượng một cái gì đó ở quy mô nhỏ hơn và cố gắng tái tạo cùng một vấn đề.
Hãy giả sử đây là SuggestedEdits bảng (trong thực tế, nó không phải). Nhưng đây là một ví dụ dễ sử dụng vì chúng ta có thể lấy lược đồ từ Stack Exchange Data Explorer. Sử dụng bảng này làm cơ sở, chúng ta có thể tạo một bảng tương đương (với một vài thay đổi nhỏ để dễ điền hơn) và ném một chỉ mục columnstore theo cụm lên đó:
CREATE TABLE dbo.FakeSuggestedEdits ( Id int IDENTITY(1,1), PostId int NOT NULL DEFAULT CONVERT(int, ABS(CHECKSUM(NEWID()))) % 200, CreationDate datetime2 NOT NULL DEFAULT sysdatetime(), ApprovalDate datetime2 NOT NULL DEFAULT sysdatetime(), RejectionDate datetime2 NULL, OwnerUserId int NOT NULL DEFAULT 7, Comment nvarchar (800) NOT NULL DEFAULT NEWID(), Text nvarchar (max) NOT NULL DEFAULT NEWID(), Title nvarchar (250) NOT NULL DEFAULT NEWID(), Tags nvarchar (250) NOT NULL DEFAULT NEWID(), RevisionGUID uniqueidentifier NOT NULL DEFAULT NEWSEQUENTIALID(), INDEX CCI_FSE CLUSTERED COLUMNSTORE );
Để điền nó với 100 triệu hàng, chúng ta có thể kết hợp chéo sys.all_objects và sys.all_columns năm lần (trên hệ thống của tôi, điều này sẽ tạo ra 2,68 triệu hàng mỗi lần, nhưng YMMV):
-- 2680350 * 5 ~ 3 minutes INSERT dbo.FakeSuggestedEdits(CreationDate) SELECT TOP (10) /*(2000000) */ modify_date FROM sys.all_objects AS o CROSS JOIN sys.columns AS c; GO 5
Sau đó, chúng tôi có thể kiểm tra không gian:
EXEC sys.sp_spaceused @objname = N'dbo.FakeSuggestedEdits';
Nó chỉ có 1,3GB, nhưng điều này phải đủ:

Bắt chước Xóa Columnstore theo cụm của chúng tôi
Dưới đây là một truy vấn đơn giản gần như khớp với những gì ứng dụng của chúng tôi đang làm với bảng:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; DELETE dbo.FakeSuggestedEdits WHERE Id = @p1 AND OwnerUserId = @p2;
Tuy nhiên, kế hoạch không hoàn toàn phù hợp:
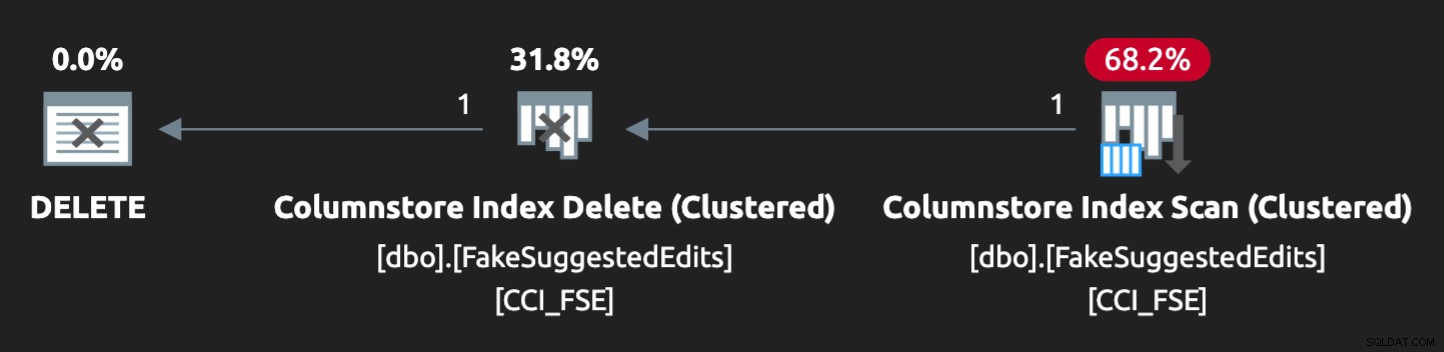
Để làm cho nó hoạt động song song và tạo ra sự tranh cãi tương tự trên chiếc máy tính xách tay ít ỏi của tôi, tôi đã phải ép buộc trình tối ưu hóa một chút với gợi ý này:
OPTION (QUERYTRACEON 8649);
Bây giờ, có vẻ đúng:

Tái tạo vấn đề
Sau đó, chúng ta có thể tạo ra một loạt các hoạt động xóa đồng thời bằng cách sử dụng SqlSedlyCmd để xóa 1.000 hàng ngẫu nhiên bằng cách sử dụng chuỗi 16 và 32:
sqlstresscmd -s docs/ColumnStore.json -t 16 sqlstresscmd -s docs/ColumnStore.json -t 32
Chúng ta có thể quan sát sự căng thẳng mà điều này gây ra trên CPU:
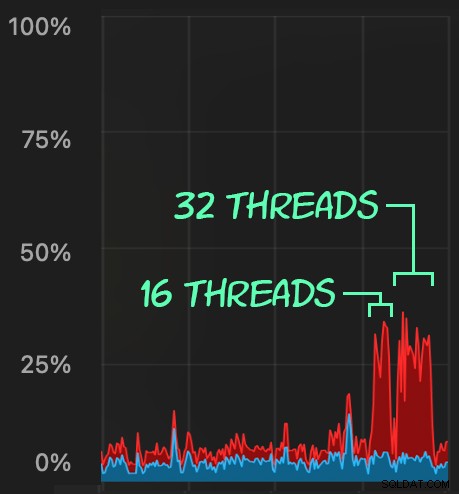
Sự căng thẳng trên CPU kéo dài trong suốt các đợt khoảng 64 và 130 giây, tương ứng:
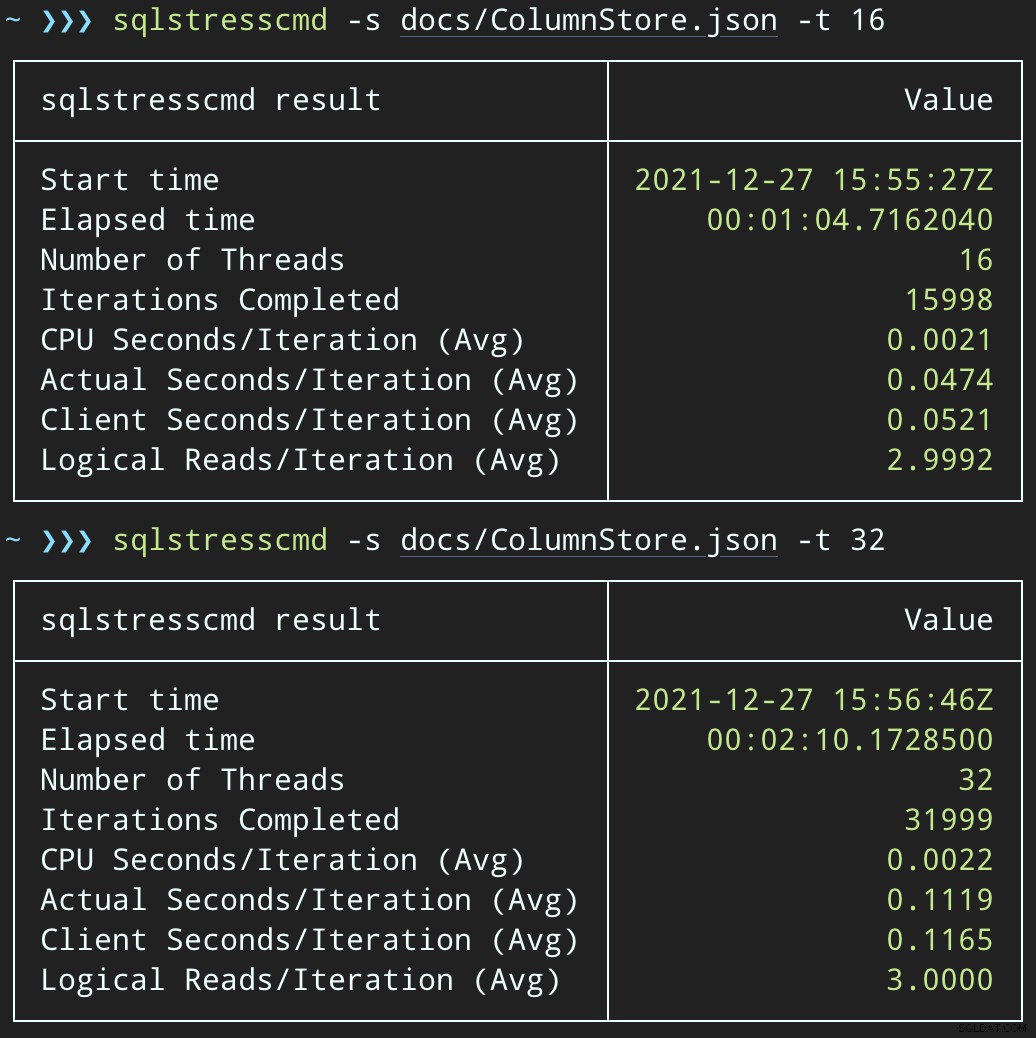
Lưu ý:Kết quả đầu ra từ SQLQueryS Stress đôi khi hơi sai khi lặp lại, nhưng tôi đã xác nhận rằng công việc bạn yêu cầu được thực hiện chính xác.
Giải pháp thay thế tiềm năng:Xóa hàng đợi
Ban đầu, tôi nghĩ về việc giới thiệu một bảng hàng đợi trong cơ sở dữ liệu, mà chúng tôi có thể sử dụng để giảm tải hoạt động xóa:
CREATE TABLE dbo.SuggestedEditDeleteQueue ( QueueID int IDENTITY(1,1) PRIMARY KEY, EnqueuedDate datetime2 NOT NULL DEFAULT sysdatetime(), ProcessedDate datetime2 NULL, Id int NOT NULL, OwnerUserId int NOT NULL );
Tất cả những gì chúng ta cần là một bộ kích hoạt INSTEAD OF để chặn những lần xóa giả mạo này đến từ ứng dụng và đặt chúng vào hàng đợi để xử lý nền. Rất tiếc, bạn không thể tạo trình kích hoạt trên bảng có chỉ mục cột lưu trữ được phân cụm:
Msg 35358, Mức 16, Trạng thái 1TẠO TRIGGER trên bảng 'dbo.FakeSuggestedEdits' không thành công vì bạn không thể tạo một trình kích hoạt trên một bảng có chỉ mục chuỗi cột được phân nhóm. Xem xét thực thi logic của trình kích hoạt theo một số cách khác hoặc nếu bạn phải sử dụng trình kích hoạt, hãy sử dụng chỉ mục heap hoặc B-tree để thay thế.
Chúng tôi sẽ cần một thay đổi tối thiểu đối với mã ứng dụng để mã gọi một quy trình đã lưu trữ để xử lý việc xóa:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; DELETE dbo.FakeSuggestedEdits WHERE Id = @Id AND OwnerUserId = @OwnerUserId; END
Đây không phải là trạng thái vĩnh viễn; điều này chỉ để giữ nguyên hành vi trong khi chỉ thay đổi một thứ trong ứng dụng. Sau khi ứng dụng được thay đổi và đang gọi thành công thủ tục được lưu trữ này thay vì gửi truy vấn xóa đột xuất, thủ tục được lưu trữ có thể thay đổi:
CREATE PROCEDURE dbo.DeleteSuggestedEdit @Id int, @OwnerUserId int AS BEGIN SET NOCOUNT ON; INSERT dbo.SuggestedEditDeleteQueue(Id, OwnerUserId) SELECT @Id, @OwnerUserId; END
Kiểm tra tác động của hàng đợi
Bây giờ, nếu chúng ta thay đổi SqlQueryS Stress để gọi thủ tục được lưu trữ thay thế:
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.DeleteSuggestedEdit @Id = @p1, @OwnerUserId = @p2;
Và gửi các lô tương tự (đặt 16 nghìn hoặc 32 nghìn hàng trên hàng đợi):
DECLARE @p1 int = ABS(CHECKSUM(NEWID())) % 10000000, @p2 int = 7; EXEC dbo.@Id = @p1 AND OwnerUserId = @p2;
Tác động của CPU cao hơn một chút:
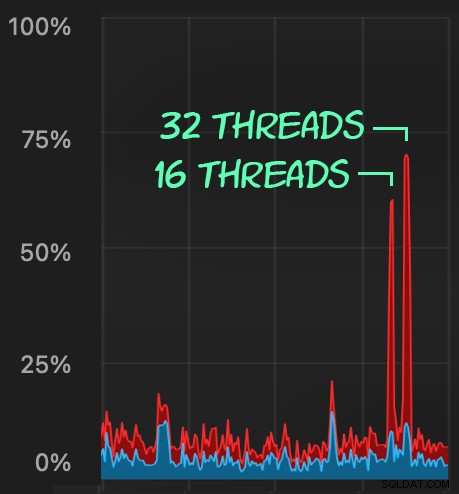
Nhưng khối lượng công việc hoàn thành nhanh hơn nhiều - lần lượt là 16 và 23 giây:
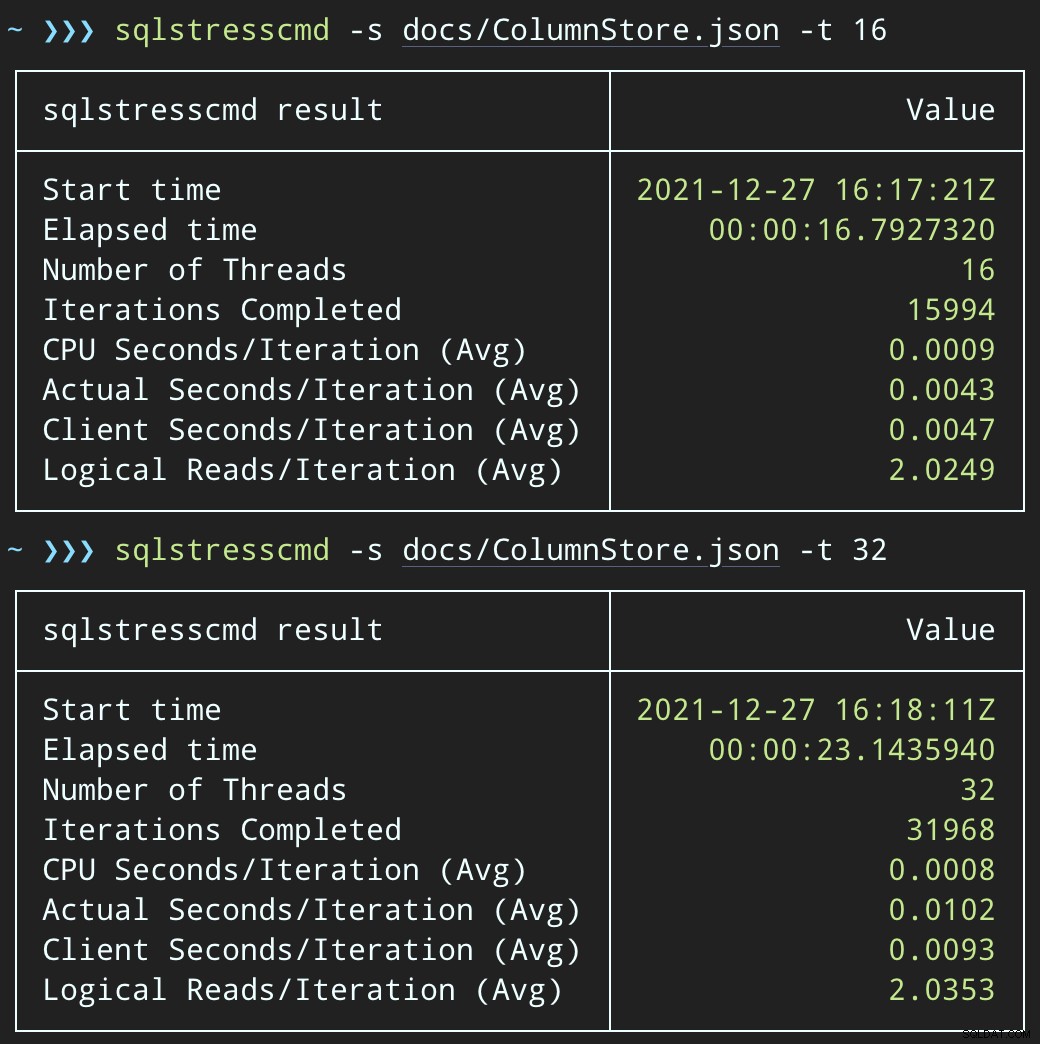
Điều này giúp giảm đáng kể sự đau đớn mà các ứng dụng sẽ cảm thấy khi chúng đi vào các giai đoạn đồng thời cao.
Tuy nhiên, chúng tôi vẫn phải thực hiện xóa
Chúng tôi vẫn phải xử lý những lần xóa đó ở chế độ nền, nhưng giờ đây chúng tôi có thể giới thiệu theo đợt và có toàn quyền kiểm soát tốc độ cũng như bất kỳ sự chậm trễ nào mà chúng tôi muốn đưa vào giữa các hoạt động. Dưới đây là cấu trúc rất cơ bản của một thủ tục được lưu trữ để xử lý hàng đợi (phải thừa nhận là không có kiểm soát giao dịch được cấp đầy đủ, xử lý lỗi hoặc dọn dẹp bảng hàng đợi):
CREATE PROCEDURE dbo.ProcessSuggestedEditQueue
@JobSize int = 10000,
@BatchSize int = 100,
@DelayInSeconds int = 2 -- must be between 1 and 59
AS
BEGIN
SET NOCOUNT ON;
DECLARE @d TABLE(Id int, OwnerUserId int);
DECLARE @rc int = 1,
@jc int = 0,
@wf nvarchar(100) = N'WAITFOR DELAY ' + CHAR(39)
+ '00:00:' + RIGHT('0' + CONVERT(varchar(2),
@DelayInSeconds), 2) + CHAR(39);
WHILE @rc > 0 AND @jc < @JobSize
BEGIN
DELETE @d;
UPDATE TOP (@BatchSize) q SET ProcessedDate = sysdatetime()
OUTPUT inserted.Id, inserted.OwnerUserId INTO @d
FROM dbo.SuggestedEditDeleteQueue AS q WITH (UPDLOCK, READPAST)
WHERE ProcessedDate IS NULL;
SET @rc = @@ROWCOUNT;
IF @rc = 0 BREAK;
DELETE fse
FROM dbo.FakeSuggestedEdits AS fse
INNER JOIN @d AS d
ON fse.Id = d.Id
AND fse.OwnerUserId = d.OwnerUserId;
SET @jc += @rc;
IF @jc > @JobSize BREAK;
EXEC sys.sp_executesql @wf;
END
RAISERROR('Deleted %d rows.', 0, 1, @jc) WITH NOWAIT;
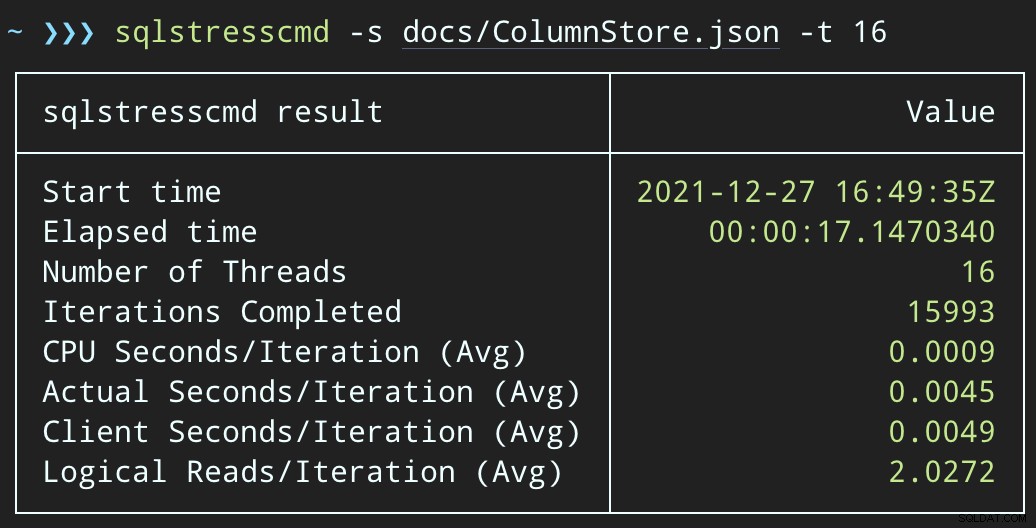
END Giờ đây, việc xóa các hàng sẽ mất nhiều thời gian hơn - trung bình cho 10.000 hàng là 223 giây, ~ 100 trong số đó là sự chậm trễ có chủ ý. Nhưng không có người dùng nào đang chờ đợi, vì vậy ai quan tâm? Cấu hình CPU gần như bằng không và ứng dụng có thể tiếp tục thêm các mục trên hàng đợi đồng thời cao như nó muốn, mà hầu như không có xung đột với công việc nền. Trong khi xử lý 10.000 hàng, tôi đã thêm 16K hàng khác vào hàng đợi và nó sử dụng cùng một CPU như trước - chỉ mất một giây lâu hơn khi công việc không chạy:
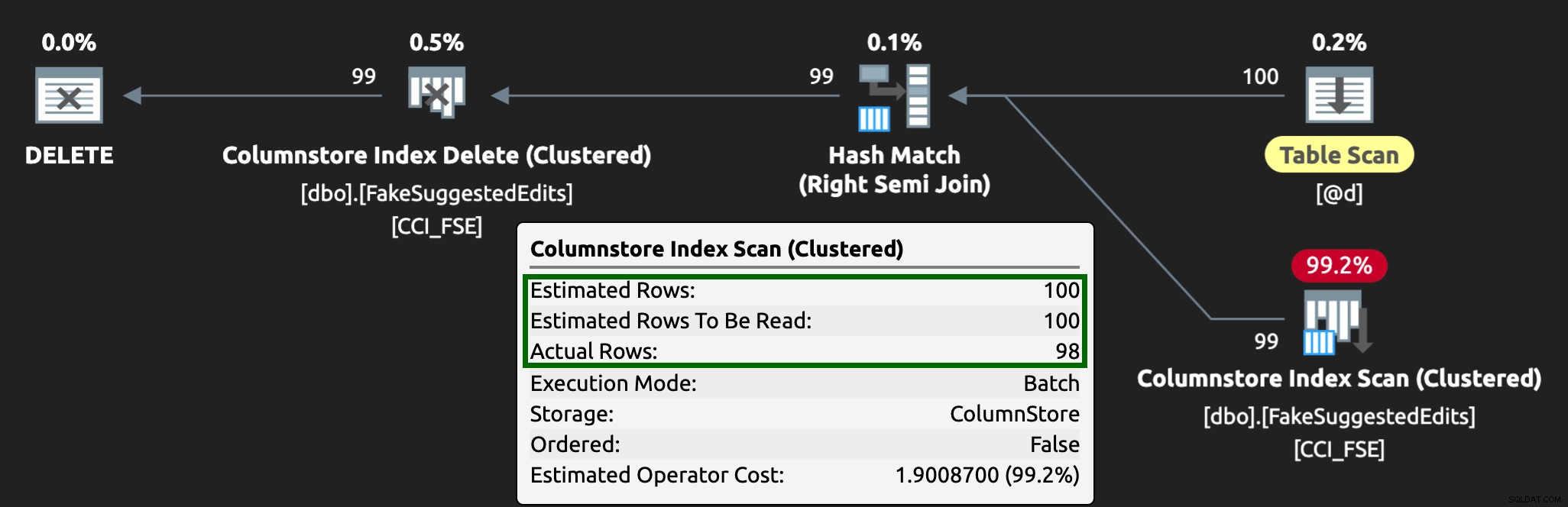
Và kế hoạch bây giờ trông giống như thế này, với các hàng ước tính / thực tế tốt hơn nhiều:
Tôi có thể thấy phương pháp tiếp cận bảng hàng đợi này là một cách hiệu quả để đối phó với tính đồng thời DML cao, nhưng nó đòi hỏi ít nhất một chút linh hoạt với các ứng dụng gửi DML - đây là một lý do tôi thực sự thích các ứng dụng gọi các thủ tục được lưu trữ, vì chúng cung cấp cho chúng tôi nhiều quyền kiểm soát hơn đối với dữ liệu.
Các tùy chọn khác
Nếu bạn không có khả năng thay đổi các truy vấn xóa đến từ ứng dụng - hoặc, nếu bạn không thể trì hoãn quá trình xóa thành một quy trình nền - bạn có thể xem xét các tùy chọn khác để giảm tác động của việc xóa:
- Chỉ mục không phân biệt trên các cột vị ngữ để hỗ trợ tra cứu điểm (chúng tôi có thể thực hiện việc này một cách riêng lẻ mà không cần thay đổi ứng dụng)
- Chỉ sử dụng tính năng xóa mềm (vẫn yêu cầu các thay đổi đối với ứng dụng)
Sẽ rất thú vị khi xem những tùy chọn này có mang lại những lợi ích tương tự hay không, nhưng tôi sẽ lưu chúng cho một bài đăng trong tương lai.