Galera Cluster đi kèm với nhiều tính năng đáng chú ý mà không có trong bản sao MySQL tiêu chuẩn (hoặc Nhân rộng nhóm); cung cấp nút tự động, đa tổng thể thực sự với các giải pháp xung đột và chuyển đổi dự phòng tự động. Ngoài ra còn có một số hạn chế có thể ảnh hưởng đến hiệu suất cụm. May mắn thay, nếu bạn không nhận thức được những điều này, có những cách giải quyết. Và nếu bạn làm đúng, bạn có thể giảm thiểu tác động của những hạn chế này và cải thiện hiệu suất tổng thể.
Trước đây chúng tôi đã đề cập đến nhiều mẹo và thủ thuật liên quan đến Galera Cluster, bao gồm cả việc chạy Galera trên AWS Cloud. Bài đăng trên blog này đi sâu vào các khía cạnh hiệu suất, với các ví dụ về cách tận dụng tối đa Galera.
Khối lượng nhân bản
Giới thiệu một chút - Galera sao chép các tập ghi trong giai đoạn cam kết, chuyển các tập ghi từ nút khởi tạo đến các nút nhận một cách đồng bộ thông qua plugin sao chép wsrep. Plugin này cũng sẽ xác nhận các bản ghi trên các nút bộ thu. Nếu quá trình chứng nhận vượt qua, nó sẽ trả về OK cho máy khách trên nút khởi tạo và sẽ được áp dụng trên các nút người nhận sau đó một cách không đồng bộ. Nếu không, giao dịch sẽ được quay lại trên nút khởi tạo (trả lại lỗi cho máy khách) và các tập ghi đã được chuyển đến các nút nhận sẽ bị loại bỏ.
Một bộ ghi bao gồm các hoạt động ghi bên trong một giao dịch thay đổi trạng thái cơ sở dữ liệu. Trong Galera Cluster, autocommit được mặc định là 1 (đã bật). Theo nghĩa đen, bất kỳ câu lệnh SQL nào được thực thi trong Galera Cluster sẽ được bao gồm dưới dạng một giao dịch, trừ khi bạn bắt đầu rõ ràng bằng BEGIN, BẮT ĐẦU GIAO DỊCH hoặc SET autocommit =0. Sơ đồ sau minh họa việc đóng gói một câu lệnh DML đơn lẻ vào một tập ghi:
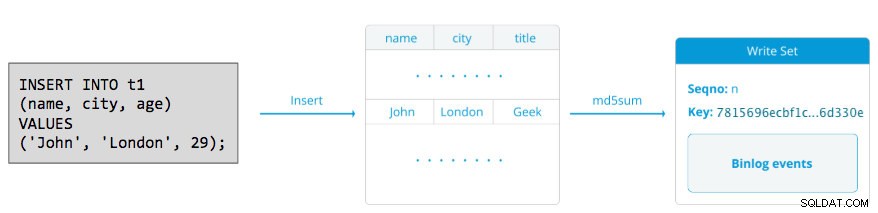
Đối với DML (INSERT, UPDATE, DELETE ..), trọng tải bộ ghi bao gồm các sự kiện nhật ký nhị phân cho một giao dịch cụ thể trong khi đối với DDL (ALTER, GRANT, CREATE ..), trọng tải bộ ghi là chính câu lệnh DDL. Đối với DML, tập ghi sẽ phải được chứng nhận chống xung đột trên nút thu trong khi đối với DDL (tùy thuộc vào wsrep_osu_method , mặc định là TOI), cụm cụm chạy câu lệnh DDL trên tất cả các nút trong cùng một chuỗi thứ tự tổng thể, chặn các giao dịch khác thực hiện trong khi DDL đang diễn ra (xem thêm RSU). Nói cách đơn giản, Galera Cluster xử lý sao chép DDL và DML theo cách khác nhau.
Thời gian khứ hồi
Nói chung, các yếu tố sau đây xác định tốc độ Galera có thể sao chép một bộ ghi từ một nút khởi tạo đến tất cả các nút nhận:
- Thời gian khứ hồi (RTT) đến nút xa nhất trong cụm từ nút khởi tạo.
- Kích thước của bộ ghi sẽ được chuyển và được chứng nhận về xung đột trên nút bộ thu.
Ví dụ:nếu chúng ta có Cụm Galera ba nút và một trong các nút nằm cách 10 mili giây (0,01 giây), thì rất ít khả năng bạn có thể ghi nhiều hơn 100 lần mỗi giây vào cùng một hàng mà không xung đột. Có một câu trích dẫn phổ biến của Mark Callaghan mô tả hành vi này khá hay:
"[Trong một cụm Galera] không thể sửa đổi một hàng nhất định nhiều hơn một lần cho mỗi RTT"
Để đo giá trị RTT, chỉ cần thực hiện ping trên nút khởi tạo đến nút xa nhất trong cụm:
$ ping 192.168.55.173 # the farthest nodeChờ một vài giây (hoặc vài phút) và kết thúc lệnh. Dòng cuối cùng của phần thống kê ping là những gì chúng tôi đang tìm kiếm:
--- 192.168.55.172 ping statistics ---
65 packets transmitted, 65 received, 0% packet loss, time 64019ms
rtt min/avg/max/mdev = 0.111/0.431/1.340/0.240 msmax giá trị là 1,340 ms (0,00134 giây) và chúng ta nên lấy giá trị này khi ước tính tối thiểu giao dịch mỗi giây (tps) cho cụm này. trung bình giá trị là 0,431ms (0,000431s) và chúng tôi có thể sử dụng để ước tính trung bình tps trong khi phút giá trị là 0,111ms (0,000111s) mà chúng tôi có thể sử dụng để ước tính tối đa tps. Mdev có nghĩa là cách các mẫu RTT được phân phối từ mức trung bình. Giá trị thấp hơn có nghĩa là RTT ổn định hơn.
Do đó, các giao dịch mỗi giây có thể được ước tính bằng cách chia RTT (tính bằng giây) thành 1 giây:

Kết quả,
- Tps tối thiểu:1 / 0,00134 (RTT tối đa) =746,26 ~ 746 tps
- Tps trung bình:1 / 0,000431 (RTT trung bình) =2320,19 ~ 2320 tps
- Tps tối đa:1 / 0,000111 (RTT tối thiểu) =9009,01 ~ 9009 tps
Lưu ý rằng đây chỉ là ước tính để dự đoán hiệu suất nhân rộng. Chúng tôi không thể làm gì nhiều để cải thiện điều này ở phía cơ sở dữ liệu, một khi chúng tôi đã triển khai và chạy mọi thứ. Ngoại trừ, nếu bạn di chuyển hoặc di chuyển các máy chủ cơ sở dữ liệu gần nhau hơn để cải thiện RTT giữa các nút hoặc nâng cấp các thiết bị ngoại vi hoặc cơ sở hạ tầng mạng. Điều này sẽ yêu cầu thời hạn bảo trì và lập kế hoạch phù hợp.
Tập hợp các giao dịch lớn
Một yếu tố khác là quy mô giao dịch. Sau khi bộ ghi được chuyển, sẽ có một quá trình chứng nhận. Chứng nhận là một quá trình để xác định xem liệu nút có thể áp dụng bộ ghi hay không. Galera tạo khóa giả tổng kiểm tra MD5 từ mọi hàng đầy đủ. Chi phí chứng nhận phụ thuộc vào kích thước của bộ ghi, được chuyển thành một số tra cứu khóa duy nhất thành chỉ mục chứng nhận (bảng băm). Nếu bạn cập nhật 500.000 hàng trong một giao dịch, ví dụ:
# a 500,000 rows table
mysql> UPDATE mydb.settings SET success = 1;Ở trên sẽ tạo ra một tập ghi đơn với 500.000 sự kiện nhật ký nhị phân trong đó. Bộ ghi khổng lồ này không vượt quá wsrep_max_ws_size (mặc định là 2GB) vì vậy nó sẽ được plugin sao chép Galera chuyển sang tất cả các nút trong cụm, xác nhận 500.000 hàng này trên các nút nhận cho bất kỳ giao dịch xung đột nào vẫn còn trong hàng đợi nô lệ. Cuối cùng, trạng thái chứng nhận được trả lại cho plugin nhân rộng nhóm. Quy mô giao dịch càng lớn, rủi ro xung đột với các giao dịch khác đến từ chủ khác càng cao. Các giao dịch xung đột làm lãng phí tài nguyên của máy chủ, đồng thời gây ra sự khôi phục lớn đối với nút khởi tạo. Lưu ý rằng hoạt động khôi phục trong MySQL chậm hơn và kém tối ưu hơn so với hoạt động cam kết.
Câu lệnh SQL trên có thể được viết lại thành một câu lệnh thân thiện với Galera hơn với sự trợ giúp của vòng lặp đơn giản, như ví dụ bên dưới:
(bash)$ for i in {1..500}; do \
mysql -uuser -ppassword -e "UPDATE mydb.settings SET success = 1 WHERE success != 1 LIMIT 1000"; \
sleep 2; \
doneLệnh shell trên sẽ cập nhật 1000 hàng cho mỗi giao dịch trong 500 lần và đợi 2 giây giữa các lần thực hiện. Bạn cũng có thể sử dụng một quy trình được lưu trữ hoặc các phương tiện khác để đạt được kết quả tương tự. Nếu việc viết lại truy vấn SQL không phải là một tùy chọn, chỉ cần hướng dẫn ứng dụng thực hiện giao dịch lớn trong thời gian bảo trì để giảm nguy cơ xung đột.
Đối với những lần xóa lớn, hãy cân nhắc sử dụng trình lưu trữ pt từ Bộ công cụ Percona - một công việc có tác động thấp, chỉ chuyển tiếp để loại bỏ dữ liệu cũ ra khỏi bảng mà không ảnh hưởng nhiều đến các truy vấn OLTP.
Chủ đề nô lệ song song
Trong Galera, applier là một quá trình đa luồng. Applier là một luồng chạy trong Galera để áp dụng các bộ ghi đến từ một nút khác. Có nghĩa là, tất cả các máy thu đều có thể thực hiện đồng thời nhiều hoạt động DML đến ngay từ nút khởi tạo (chính). Sao chép song song Galera chỉ được áp dụng cho các giao dịch khi nó an toàn để thực hiện. Nó cải thiện xác suất của nút để đồng bộ hóa với nút khởi tạo. Tuy nhiên, tốc độ sao chép vẫn bị giới hạn ở kích thước RTT và bộ ghi.
Để đạt được hiệu quả tốt nhất, chúng ta cần biết hai điều:
- Số lượng lõi mà máy chủ có.
- Giá trị của wsrep_cert_deps_distance trạng thái.
Trạng thái wsrep_cert_deps_distance cho chúng ta biết mức độ song song tiềm năng. Nó là giá trị của khoảng cách trung bình giữa các giá trị seqno cao nhất và thấp nhất có thể được áp dụng song song. Bạn có thể sử dụng wsrep_cert_deps_distance biến trạng thái để xác định số luồng phụ tối đa có thể. Lưu ý rằng đây là giá trị trung bình theo thời gian. Do đó, để nhận được giá trị tốt, bạn phải thực hiện các thao tác ghi theo cụm thông qua khối lượng công việc kiểm tra hoặc điểm chuẩn cho đến khi bạn thấy giá trị ổn định xuất hiện.
Để nhận số lõi, bạn có thể chỉ cần sử dụng lệnh sau:
$ grep -c processor /proc/cpuinfo
4Lý tưởng nhất là 2, 3 hoặc 4 luồng ứng dụng phụ trên mỗi lõi CPU là một khởi đầu tốt. Do đó, giá trị tối thiểu cho các luồng phụ phải là 4 x số lõi CPU và không được vượt quá wsrep_cert_deps_distance giá trị:
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cert_deps_distance';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| wsrep_cert_deps_distance | 48.16667 |
+--------------------------+----------+Bạn có thể kiểm soát số lượng chuỗi ứng dụng nô lệ bằng cách sử dụng wsrep_slave_thread Biến đổi. Mặc dù đây là một biến động, chỉ việc tăng số lượng sẽ có tác dụng ngay lập tức. Nếu bạn giảm giá trị một cách tự động, sẽ mất một khoảng thời gian cho đến khi chuỗi applier thoát ra sau khi áp dụng xong. Giá trị được đề xuất nằm trong khoảng từ 16 đến 48:
mysql> SET GLOBAL wsrep_slave_threads = 48;Hãy lưu ý rằng để các luồng phụ song song hoạt động, bạn phải đặt những điều sau (thường được định cấu hình trước cho Galera Cluster):
innodb_autoinc_lock_mode=2Galera Cache (bộ nhớ đệm)
Galera sử dụng một tệp được phân bổ trước với kích thước cụ thể được gọi là gcache, trong đó một nút Galera giữ một bản sao của các tệp ghi theo kiểu bộ đệm tròn. Theo mặc định, kích thước của nó là 128MB, khá nhỏ. Chuyển trạng thái tăng dần (IST) là một phương pháp để chuẩn bị một trình kết hợp bằng cách chỉ gửi các bản ghi còn thiếu có sẵn trong gcache của nhà tài trợ. IST nhanh hơn truyền ảnh chụp nhanh trạng thái (SST), nó không bị chặn và không có tác động đáng kể đến hiệu suất đối với nhà tài trợ. Nó nên là tùy chọn ưu tiên bất cứ khi nào có thể.
IST chỉ có thể đạt được nếu tất cả các thay đổi mà trình kết hợp bỏ qua vẫn còn trong tệp gcache của nhà tài trợ. Cài đặt được khuyến nghị cho điều này là phải lớn bằng toàn bộ tập dữ liệu MySQL. Nếu dung lượng ổ đĩa bị hạn chế hoặc tốn kém, việc xác định kích thước phù hợp của kích thước gcache là rất quan trọng, vì nó có thể ảnh hưởng đến hiệu suất đồng bộ hóa dữ liệu giữa các nút Galera.
Câu lệnh dưới đây sẽ cung cấp cho chúng ta ý tưởng về lượng dữ liệu được sao chép bởi Galera. Chạy câu lệnh sau trên một trong các nút Galera trong giờ cao điểm (được thử nghiệm trên MariaDB> 10.0 và PXC> 5.6, galera> 3.x):
mysql> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;
+--------+---------+-----------------+-----------------------+
| MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) |
+--------+---------+-----------------+-----------------------+
| 7.95 | 477.00 | 128 | 16.10 |
+--------+---------+-----------------+-----------------------+
Chúng tôi có thể ước tính rằng nút Galera có thể có khoảng 16 phút ngừng hoạt động mà không yêu cầu SST tham gia (trừ khi Galera không thể xác định trạng thái kết hợp). Nếu thời gian này quá ngắn và bạn có đủ dung lượng đĩa trên các nút của mình, bạn có thể thay đổi wsrep_provider_options ="gcache.size =
Bạn cũng nên sử dụng gcache.recover =yes trong wsrep_provider_options (Galera> 3,19), trong đó Galera sẽ cố gắng khôi phục tệp gcache về trạng thái có thể sử dụng khi khởi động thay vì xóa nó, do đó bảo toàn khả năng có IST và tránh SST nhiều nhất có thể. Codership và Percona đã đề cập chi tiết điều này trong các blog của họ. IST luôn là phương pháp tốt nhất để đồng bộ hóa sau khi một nút tham gia lại vào cụm. Nó nhanh hơn 50% so với xtrabackup hoặc mariabackup và nhanh hơn 5 lần so với mysqldump.
Nô lệ không đồng bộ
Các nút Galera được liên kết chặt chẽ với nhau, trong đó hiệu suất sao chép nhanh như nút chậm nhất. Galera sử dụng cơ chế kiểm soát luồng, để kiểm soát luồng sao chép giữa các thành viên và loại bỏ bất kỳ độ trễ nào của nô lệ. Quá trình sao chép có thể nhanh hoặc chậm trên mọi nút và được điều chỉnh tự động bởi Galera. Nếu bạn muốn biết về kiểm soát luồng, hãy đọc bài đăng trên blog này của Jay Janssen từ Percona.
Trong hầu hết các trường hợp, các hoạt động nặng như phân tích chạy lâu (đọc chuyên sâu) và sao lưu (đọc chuyên sâu, khóa) thường không thể tránh khỏi, điều này có thể làm giảm hiệu suất của cụm. Cách tốt nhất để thực hiện loại truy vấn này là gửi chúng đến một máy chủ bản sao được ghép nối lỏng lẻo, chẳng hạn như một máy chủ không đồng bộ.
Một nô lệ không đồng bộ sao chép từ một nút Galera bằng cách sử dụng giao thức sao chép không đồng bộ MySQL tiêu chuẩn. Không có giới hạn về số lượng nô lệ có thể được kết nối với một nút Galera và cũng có thể xâu chuỗi nó với một chủ trung gian. Các hoạt động MySQL thực thi trên máy chủ này sẽ không ảnh hưởng đến hiệu suất của cụm, ngoài giai đoạn đồng bộ hóa ban đầu, nơi phải thực hiện sao lưu đầy đủ trên nút Galera để tạo giai đoạn nô lệ trước khi thiết lập liên kết sao chép (mặc dù ClusterControl cho phép bạn xây dựng không đồng bộ nô lệ từ bản sao lưu hiện có trước, trước khi kết nối nó với cụm).
GTID (Mã định danh giao dịch toàn cầu) cung cấp ánh xạ giao dịch tốt hơn giữa các nút và được hỗ trợ trong MySQL 5.6 và MariaDB 10.0. Với GTID, thao tác chuyển đổi dự phòng trên một nô lệ sang một chủ khác (một nút Galera khác) được đơn giản hóa mà không cần tìm ra vị trí và tệp nhật ký chính xác. Galera cũng đi kèm với triển khai GTID của riêng mình nhưng hai thứ này độc lập với nhau.
Mở rộng quy mô nô lệ không đồng bộ chỉ bằng một cú nhấp chuột nếu bạn đang sử dụng ClusterControl -> Thêm tính năng Replication Slave:
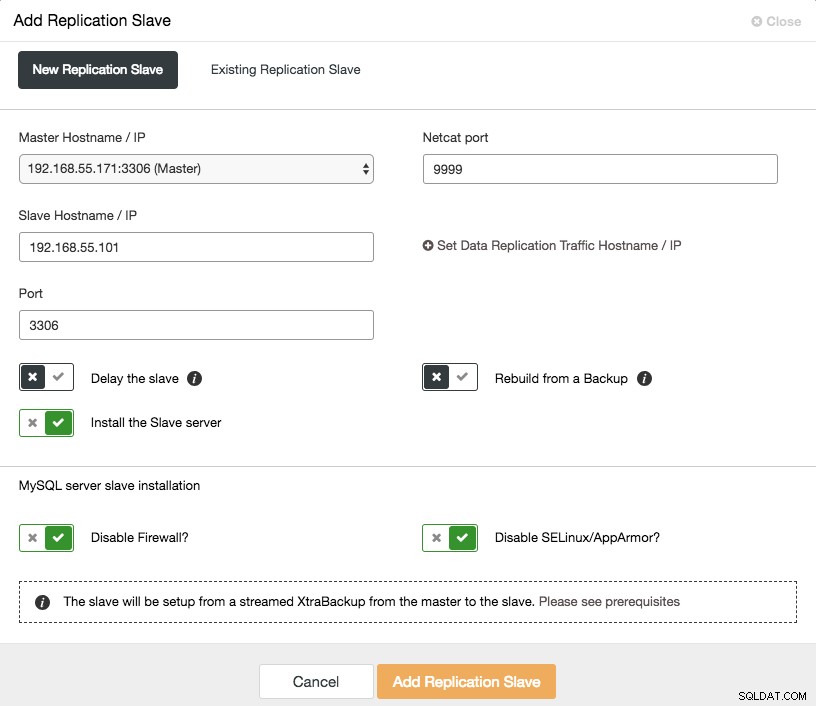
Lưu ý rằng nhật ký nhị phân phải được bật trên bản chính (nút Galera đã chọn) trước khi chúng tôi có thể tiến hành thiết lập này. Chúng tôi cũng đã đề cập đến cách thủ công trong bài đăng trước này.
Ảnh chụp màn hình sau đây từ ClusterControl cho thấy cấu trúc liên kết cụm, nó minh họa kiến trúc Cụm Galera của chúng tôi với một nô lệ không đồng bộ:
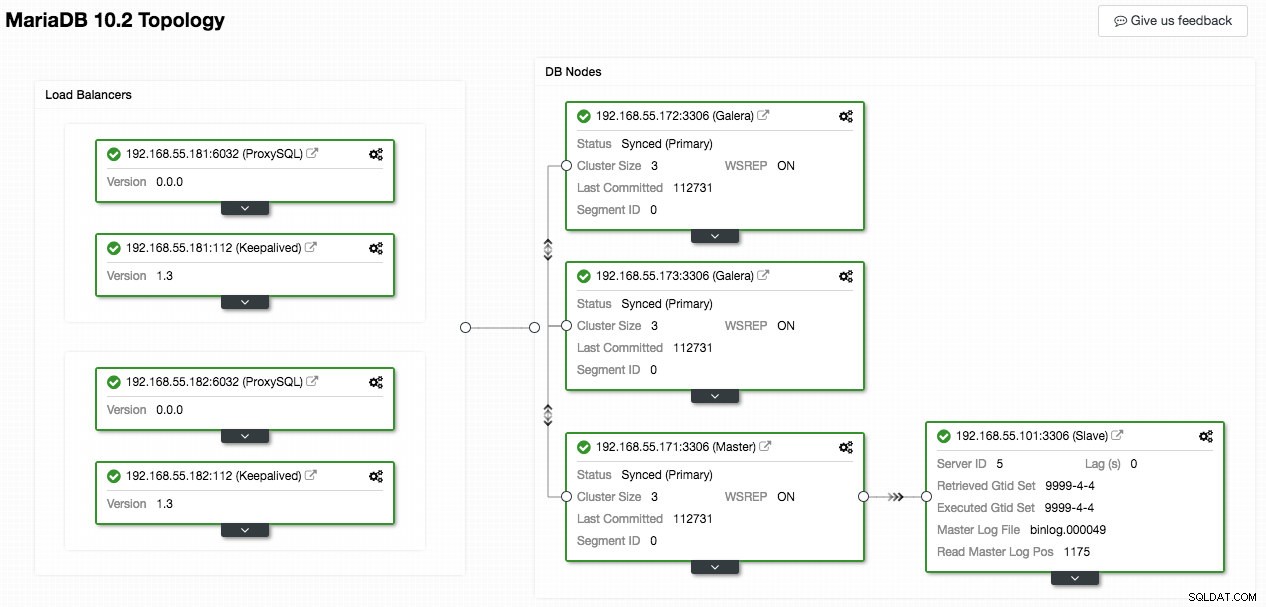
ClusterControl tự động khám phá cấu trúc liên kết và tạo ra một sơ đồ tuyệt vời như trên. Bạn cũng có thể thực hiện các tác vụ quản trị trực tiếp từ trang này bằng cách nhấp vào biểu tượng bánh răng trên cùng bên phải của mỗi hộp.
Proxy đảo ngược nhận biết SQL
ProxySQL và MariaDB MaxScale là các proxy ngược thông minh hiểu giao thức MySQL và có khả năng hoạt động như một cổng, bộ định tuyến, bộ cân bằng tải và tường lửa trước các nút Galera của bạn. Với sự trợ giúp của nhà cung cấp Địa chỉ IP ảo như LVS hoặc Keepalived và kết hợp điều này với công nghệ sao chép đa tổng thể của Galera, chúng tôi có thể có một dịch vụ cơ sở dữ liệu có tính khả dụng cao, loại bỏ tất cả các điểm lỗi (SPOF) có thể xảy ra từ điểm ứng dụng -của tầm nhìn. Điều này chắc chắn sẽ cải thiện tính khả dụng và độ tin cậy của toàn bộ kiến trúc.
Một lợi thế khác với cách tiếp cận này là bạn sẽ có khả năng theo dõi, viết lại hoặc định tuyến lại các truy vấn SQL đến dựa trên một bộ quy tắc trước khi chúng truy cập vào máy chủ cơ sở dữ liệu thực tế, giảm thiểu các thay đổi trên ứng dụng hoặc phía máy khách và định tuyến các truy vấn tới một nút phù hợp hơn để có hiệu suất tối ưu. Có thể ngăn chặn các truy vấn rủi ro cho Galera như BẢNG KHÓA và BẢNG CHỨNG MINH BẰNG KHÓA ĐỌC trước khi chúng gây ra sự tàn phá cho hệ thống, đồng thời tác động đến các truy vấn như truy vấn "điểm phát sóng" (một hàng mà các truy vấn khác nhau muốn truy cập cùng một lúc) có thể được viết lại hoặc được chuyển hướng đến một nút Galera duy nhất để giảm nguy cơ xung đột giao dịch. Đối với các truy vấn chỉ đọc nặng như OLAP hoặc sao lưu, bạn có thể định tuyến chúng đến máy chủ không đồng bộ nếu có.
Reverse proxy cũng giám sát trạng thái cơ sở dữ liệu, các truy vấn và các biến để hiểu các thay đổi về cấu trúc liên kết và đưa ra quyết định định tuyến chính xác đến các máy chủ phụ trợ. Một cách gián tiếp, nó tập trung vào việc giám sát các nút và tổng quan về cụm mà không cần phải kiểm tra từng nút Galera thường xuyên. Ảnh chụp màn hình sau đây cho thấy bảng điều khiển giám sát ProxySQL trong ClusterControl:
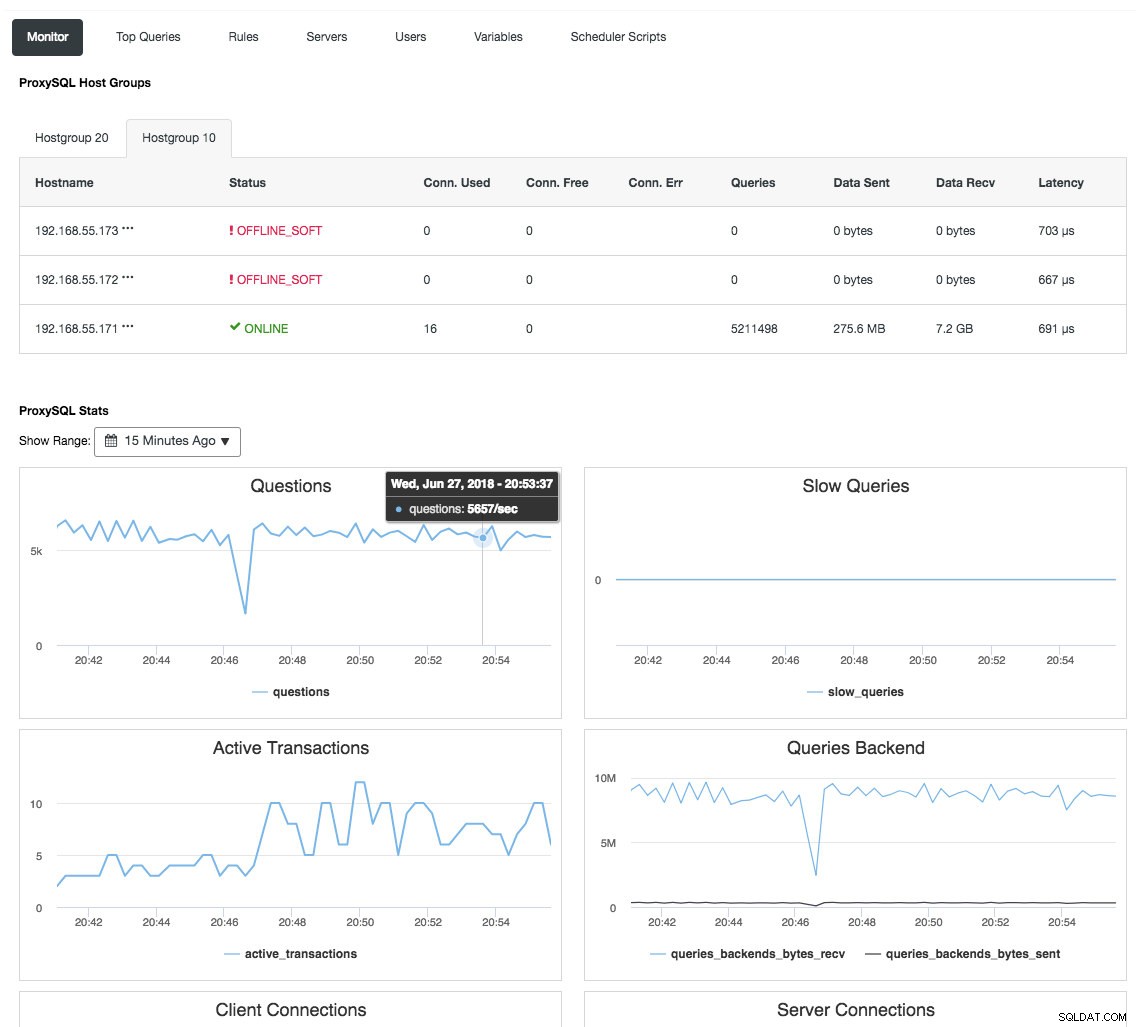
Ngoài ra còn có nhiều lợi ích khác mà bộ cân bằng tải có thể mang lại để cải thiện đáng kể Galera Cluster, như được trình bày chi tiết trong bài đăng blog này, Trở thành DBA ClusterControl:Tạo thành phần DB của bạn HA thông qua Load Balancers.
Lời kết
Với sự hiểu biết tốt về cách Galera Cluster hoạt động nội bộ, chúng tôi có thể khắc phục một số hạn chế và cải thiện dịch vụ cơ sở dữ liệu. Chúc các bạn thành nhóm vui vẻ!



