Bạn có thể đã nghe nói về thuật ngữ “não phân chia”. Nó là gì? Nó ảnh hưởng đến các cụm của bạn như thế nào? Trong bài đăng blog này, chúng tôi sẽ thảo luận về chính xác nó là gì, nó có thể gây nguy hiểm gì cho cơ sở dữ liệu của bạn, cách chúng tôi có thể ngăn chặn nó và nếu mọi thứ xảy ra sai sót, làm thế nào để khôi phục từ nó.
Đã qua lâu rồi thời của những cá thể đơn lẻ, ngày nay hầu như tất cả các cơ sở dữ liệu đều chạy trong các nhóm hoặc cụm sao chép. Điều này là rất tốt cho tính khả dụng và khả năng mở rộng cao, nhưng cơ sở dữ liệu phân tán sẽ đưa ra những nguy cơ và hạn chế mới. Một trường hợp có thể gây chết người là chia tách mạng. Hãy tưởng tượng một cụm gồm nhiều nút, do sự cố mạng, được chia thành hai phần. Vì những lý do rõ ràng (tính nhất quán của dữ liệu), cả hai phần không nên xử lý lưu lượng truy cập cùng một lúc vì chúng bị tách biệt với nhau và không thể chuyển dữ liệu giữa chúng. Nó cũng sai từ quan điểm ứng dụng - ngay cả khi cuối cùng, sẽ có một cách để đồng bộ hóa dữ liệu (mặc dù việc đối chiếu 2 tập dữ liệu không phải là chuyện nhỏ). Trong một thời gian, một phần của ứng dụng sẽ không biết về những thay đổi được thực hiện bởi các máy chủ ứng dụng khác, máy chủ này truy cập vào phần khác của cụm cơ sở dữ liệu. Điều này có thể dẫn đến các vấn đề nghiêm trọng.
Điều kiện trong đó cụm được chia thành hai hoặc nhiều phần sẵn sàng chấp nhận ghi được gọi là "bộ não phân chia".
Vấn đề lớn nhất với bộ não phân tách là sự trôi dạt dữ liệu, khi việc ghi xảy ra trên cả hai phần của cụm. Không có phiên bản MySQL nào cung cấp các phương tiện tự động để hợp nhất các tập dữ liệu đã khác nhau. Bạn sẽ không tìm thấy tính năng như vậy trong MySQL replication, Group Replication hoặc Galera. Khi dữ liệu đã phân kỳ, tùy chọn duy nhất là sử dụng một trong các phần của cụm làm nguồn xác thực và loại bỏ các thay đổi được thực thi trên phần kia - trừ khi chúng ta có thể làm theo một số quy trình thủ công để hợp nhất dữ liệu.
Đây là lý do tại sao chúng ta sẽ bắt đầu với việc làm thế nào để ngăn chặn sự phân chia não xảy ra. Điều này dễ dàng hơn nhiều so với việc phải khắc phục bất kỳ sự khác biệt nào về dữ liệu.
Làm thế nào để ngăn chặn não phân chia
Giải pháp chính xác phụ thuộc vào loại cơ sở dữ liệu và thiết lập của môi trường. Chúng ta sẽ xem xét một số trường hợp phổ biến nhất đối với Galera Cluster và MySQL Replication.
Cụm Galera
Galera có một “bộ ngắt mạch” tích hợp để xử lý não bị chia rẽ:nó dựa trên cơ chế túc số. Nếu phần lớn (50% + 1) các nút có sẵn trong cụm, Galera sẽ hoạt động bình thường. Nếu không có đa số, Galera sẽ ngừng phục vụ lưu lượng truy cập và chuyển sang trạng thái được gọi là "không phải Chính". Đây là tất cả những gì bạn cần để đối phó với tình huống não bị chia rẽ khi sử dụng Galera. Chắc chắn, có những phương pháp thủ công để buộc Galera ở trạng thái "Chính" ngay cả khi không có đa số. Điều là, trừ khi bạn làm điều đó, bạn sẽ được an toàn.
Cách tính đại số được tính có những ảnh hưởng quan trọng - ở một cấp trung tâm dữ liệu, bạn muốn có một số nút lẻ. Ba nút cung cấp cho bạn khả năng chịu lỗi của một nút (2 nút phù hợp với yêu cầu của hơn 50% số nút trong cụm có sẵn). Năm nút sẽ cung cấp cho bạn khả năng chịu lỗi của hai nút (5 - 2 =3, hơn 50% từ 5 nút). Mặt khác, việc sử dụng bốn nút sẽ không cải thiện khả năng chịu đựng của bạn đối với cụm ba nút. Nó vẫn sẽ chỉ xử lý lỗi một nút (4 - 1 =3, hơn 50% từ 4) trong khi lỗi hai nút sẽ khiến cụm không sử dụng được (4 - 2 =2, chỉ 50%, không nhiều hơn).
Trong khi triển khai cụm Galera trong một trung tâm dữ liệu, hãy lưu ý rằng, lý tưởng nhất là bạn muốn phân phối các nút trên nhiều vùng khả dụng (nguồn điện riêng biệt, mạng, v.v.) - miễn là chúng tồn tại trong trung tâm dữ liệu của bạn, nghĩa là . Một thiết lập đơn giản có thể giống như sau:
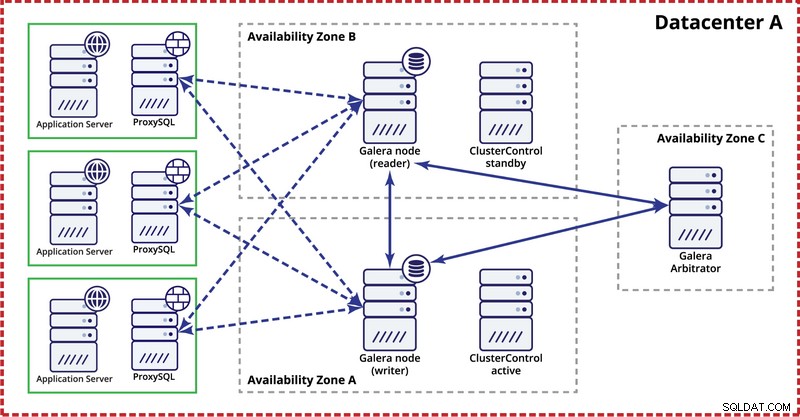
Ở cấp độ đa trung tâm dữ liệu, những cân nhắc đó cũng có thể áp dụng được. Nếu bạn muốn cụm Galera tự động xử lý các lỗi trung tâm dữ liệu, bạn nên sử dụng một số lẻ trung tâm dữ liệu. Để giảm chi phí, bạn có thể sử dụng trọng tài Galera ở một trong số họ thay vì nút cơ sở dữ liệu. Trọng tài viên Galera (garbd) là một quy trình tham gia vào tính toán số đại biểu nhưng nó không chứa bất kỳ dữ liệu nào. Điều này làm cho nó có thể sử dụng nó ngay cả trên các trường hợp rất nhỏ vì nó không tốn nhiều tài nguyên - mặc dù kết nối mạng phải tốt vì nó "nhìn thấy" tất cả lưu lượng sao chép. Thiết lập mẫu có thể giống như trên sơ đồ bên dưới:
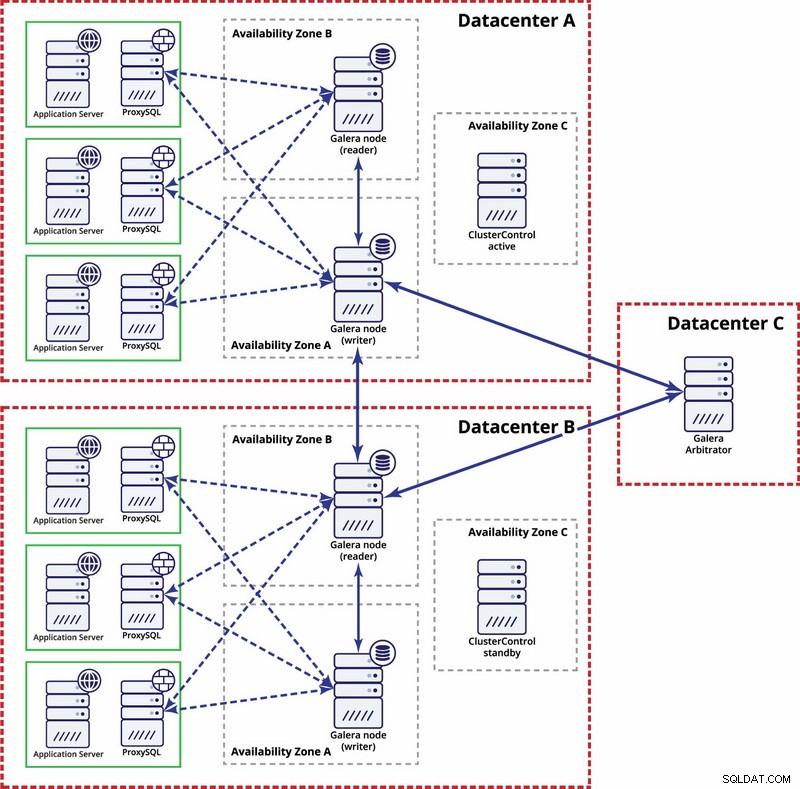
Bản sao MySQL
Với bản sao MySQL, vấn đề lớn nhất là không có nội trang cơ chế đại biểu, như trong cụm Galera. Do đó, cần thực hiện thêm các bước để đảm bảo rằng thiết lập của bạn sẽ không bị ảnh hưởng bởi bộ não phân chia.
Một phương pháp là tránh chuyển đổi dự phòng tự động giữa các trung tâm dữ liệu. Bạn có thể định cấu hình giải pháp chuyển đổi dự phòng của mình (có thể thông qua ClusterControl hoặc MHA hoặc Orchestrator) để chỉ chuyển đổi dự phòng trong một trung tâm dữ liệu. Nếu toàn bộ trung tâm dữ liệu bị ngừng hoạt động, quản trị viên sẽ quyết định cách chuyển đổi dự phòng và cách đảm bảo rằng các máy chủ trong trung tâm dữ liệu bị lỗi sẽ không được sử dụng.
Có các tùy chọn để làm cho nó tự động hơn. Bạn có thể sử dụng Consul để lưu trữ dữ liệu về các nút trong thiết lập sao chép và nút nào trong số chúng là nút chính. Sau đó, sẽ tùy thuộc vào quản trị viên (hoặc thông qua một số tập lệnh) để cập nhật mục nhập này và chuyển các ghi vào trung tâm dữ liệu thứ hai. Bạn có thể hưởng lợi từ thiết lập Orchestrator / Raft trong đó các nút của Orchestrator có thể được phân phối trên nhiều trung tâm dữ liệu và phát hiện bộ não bị phân chia. Dựa trên điều này, bạn có thể thực hiện các hành động khác nhau như, như chúng tôi đã đề cập trước đây, cập nhật các mục nhập trong Lãnh sự của chúng tôi hoặc v.v. Vấn đề là đây là một môi trường phức tạp hơn nhiều để thiết lập và tự động hóa so với cụm Galera. Dưới đây, bạn có thể tìm thấy ví dụ về thiết lập đa trung tâm dữ liệu để nhân rộng MySQL.
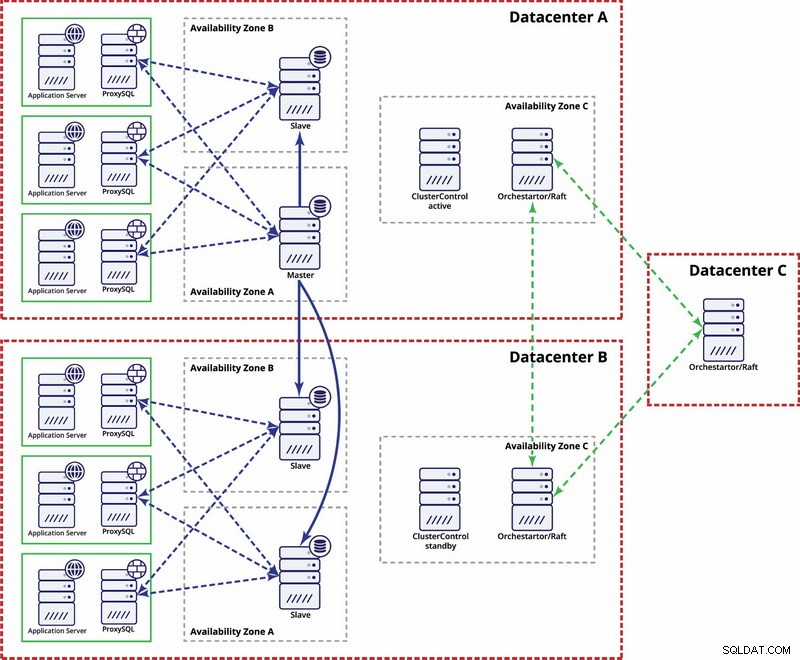
Xin lưu ý rằng bạn vẫn phải tạo các tập lệnh để làm cho nó hoạt động, tức là theo dõi các nút của Bộ điều phối cho một bộ não phân chia và thực hiện các hành động cần thiết để triển khai STONITH và đảm bảo rằng cái chính trong trung tâm dữ liệu A sẽ không được sử dụng khi mạng hội tụ và kết nối sẽ được khôi phục.
Đã xảy ra sự phân chia não bộ - Làm gì tiếp theo?
Trường hợp xấu nhất đã xảy ra và chúng tôi bị trôi dữ liệu. Chúng tôi sẽ cố gắng cung cấp cho bạn một số gợi ý những gì có thể được thực hiện ở đây. Thật không may, các bước chính xác sẽ phụ thuộc chủ yếu vào thiết kế giản đồ của bạn, vì vậy sẽ không thể viết hướng dẫn thực hiện chính xác.
Điều bạn phải ghi nhớ là mục đích cuối cùng sẽ là sao chép dữ liệu từ cái này sang cái khác và tạo lại tất cả các mối quan hệ giữa các bảng.
Trước hết, bạn phải xác định nút nào sẽ tiếp tục cung cấp dữ liệu dưới dạng chính. Đây là tập dữ liệu mà bạn sẽ hợp nhất dữ liệu được lưu trữ trên phiên bản "chính" khác. Sau khi hoàn tất, bạn phải xác định dữ liệu từ trang cái cũ bị thiếu trên trang cái hiện tại. Đây sẽ là công việc thủ công. Nếu bạn có dấu thời gian trong bảng của mình, bạn có thể tận dụng chúng để xác định dữ liệu bị thiếu. Cuối cùng, nhật ký nhị phân sẽ chứa tất cả các sửa đổi dữ liệu để bạn có thể dựa vào chúng. Bạn cũng có thể phải dựa vào kiến thức của mình về cấu trúc dữ liệu và mối quan hệ giữa các bảng. Nếu dữ liệu của bạn được chuẩn hóa, một bản ghi trong một bảng có thể liên quan đến các bản ghi trong các bảng khác. Ví dụ:ứng dụng của bạn có thể chèn dữ liệu vào bảng “người dùng” có liên quan đến bảng “địa chỉ” bằng cách sử dụng user_id. Bạn sẽ phải tìm tất cả các hàng có liên quan và trích xuất chúng.
Bước tiếp theo sẽ là tải dữ liệu này vào trang cái mới. Đây là một phần phức tạp - nếu bạn đã chuẩn bị các thiết lập của mình từ trước, điều này có thể chỉ đơn giản là chạy một vài lần chèn. Nếu không, điều này có thể khá phức tạp. Đó là tất cả về khóa chính và giá trị chỉ mục duy nhất. Nếu các giá trị khóa chính của bạn được tạo là duy nhất trên mỗi máy chủ bằng cách sử dụng một số loại trình tạo UUID hoặc sử dụng cài đặt auto_increment_increment và auto_increment_offset trong MySQL, bạn có thể chắc chắn rằng dữ liệu từ cái chính cũ mà bạn phải chèn sẽ không gây ra khóa chính hoặc duy nhất xung đột chính với dữ liệu trên trang cái mới. Nếu không, bạn có thể phải sửa đổi thủ công dữ liệu từ bản gốc cũ để đảm bảo nó có thể được chèn chính xác. Nghe có vẻ phức tạp, vì vậy hãy xem một ví dụ.
Hãy tưởng tượng chúng ta chèn các hàng bằng auto_increment trên nút A, nút này là nút chính. Vì đơn giản, chúng tôi sẽ chỉ tập trung vào một hàng duy nhất. Có các cột "id" và "value".
Nếu chúng tôi chèn nó mà không có bất kỳ thiết lập cụ thể nào, chúng tôi sẽ thấy các mục nhập như bên dưới:
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’Những thứ đó sẽ sao chép sang nô lệ (B). Nếu bộ não phân tách xảy ra và việc ghi sẽ được thực hiện trên cả bản gốc cũ và mới, chúng ta sẽ gặp phải tình huống sau:
Đ
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’B
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’Như bạn có thể thấy, không có cách nào để kết xuất các bản ghi có id là 1004, 1005 và 1006 từ nút A và lưu trữ chúng trên nút B vì chúng ta sẽ có các mục nhập khóa chính bị trùng lặp. Việc cần làm là thay đổi các giá trị của cột id trong các hàng sẽ được chèn vào một giá trị lớn hơn giá trị lớn nhất của cột id từ bảng. Đây là tất cả những gì cần thiết cho các hàng đơn. Đối với các mối quan hệ phức tạp hơn, trong đó có nhiều bảng, bạn có thể phải thực hiện các thay đổi ở nhiều vị trí.
Mặt khác, nếu chúng tôi đã lường trước được vấn đề tiềm ẩn này và định cấu hình các nút của mình để lưu trữ id lẻ trên nút A và id chẵn trên nút B, thì vấn đề sẽ dễ giải quyết hơn rất nhiều.
Nút A đã được định cấu hình với auto_increment_offset =1 và auto_increment_increment =2
Nút B đã được định cấu hình với auto_increment_offset =2 và auto_increment_increment =2
Đây là cách dữ liệu sẽ trông như thế nào trên nút A trước khi bộ não phân chia:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’Khi não bị phân tách xảy ra, nó sẽ giống như bên dưới.
Nút A:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Nút B:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’Giờ đây, chúng tôi có thể dễ dàng sao chép dữ liệu bị thiếu từ nút A:
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’Và tải nó vào nút B kết thúc với tập dữ liệu sau:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’Chắc chắn, các hàng không theo thứ tự ban đầu, nhưng điều này sẽ ổn. Trong trường hợp xấu nhất, bạn sẽ phải sắp xếp theo cột "giá trị" trong các truy vấn và có thể thêm chỉ mục vào đó để sắp xếp nhanh chóng.
Bây giờ, hãy tưởng tượng hàng trăm hoặc hàng nghìn hàng và cấu trúc bảng được chuẩn hóa cao - để khôi phục một hàng có thể có nghĩa là bạn sẽ phải khôi phục một số hàng trong số đó trong các bảng bổ sung. Với nhu cầu thay đổi id (vì bạn không có cài đặt bảo vệ) trên tất cả các hàng liên quan và tất cả đều là công việc thủ công, bạn có thể tưởng tượng rằng đây không phải là tình huống tốt nhất. Cần thời gian để khôi phục và nó là một quá trình dễ xảy ra lỗi. May mắn thay, như chúng ta đã thảo luận ở phần đầu, có những phương tiện để giảm thiểu khả năng bộ não bị chia cắt sẽ ảnh hưởng đến hệ thống của bạn hoặc giảm bớt công việc cần phải thực hiện để đồng bộ hóa các nút của bạn. Hãy chắc chắn rằng bạn sử dụng chúng và luôn chuẩn bị.



