Trong bài đăng trên blog này, chúng tôi sẽ phân tích 6 trường hợp lỗi khác nhau trong hệ thống cơ sở dữ liệu sản xuất, từ các vấn đề của một máy chủ đến các kế hoạch chuyển đổi dự phòng đa trung tâm dữ liệu. Chúng tôi sẽ hướng dẫn bạn các quy trình khôi phục và chuyển đổi dự phòng cho các trường hợp tương ứng. Hy vọng rằng điều này sẽ giúp bạn hiểu rõ về những rủi ro bạn có thể gặp phải và những điều cần cân nhắc khi thiết kế cơ sở hạ tầng của bạn.
Lược đồ cơ sở dữ liệu bị hỏng
Hãy bắt đầu với cài đặt một nút - một thiết lập cơ sở dữ liệu ở dạng đơn giản nhất. Dễ dàng thực hiện, với chi phí thấp nhất. Trong trường hợp này, bạn chạy nhiều ứng dụng trên một máy chủ trong đó mỗi lược đồ cơ sở dữ liệu thuộc về ứng dụng khác nhau. Cách tiếp cận để khôi phục một giản đồ sẽ phụ thuộc vào một số yếu tố.
- Tôi có bản sao lưu nào không?
- Tôi có bản sao lưu không và tôi có thể khôi phục bản sao lưu đó nhanh như thế nào?
- Loại công cụ lưu trữ nào đang được sử dụng?
- Tôi có bản sao lưu tương thích với PITR (khôi phục tại thời điểm) không?
Lỗi dữ liệu có thể được xác định bằng mysqlcheck.
mysqlcheck -uroot -p <DATABASE>Thay DATABASE bằng tên của cơ sở dữ liệu và thay TABLE bằng tên của bảng mà bạn muốn kiểm tra:
mysqlcheck -uroot -p <DATABASE> <TABLE>Mysqlcheck kiểm tra cơ sở dữ liệu và bảng được chỉ định. Nếu một bảng vượt qua kiểm tra, mysqlcheck hiển thị OK cho bảng. Trong ví dụ dưới đây, chúng ta có thể thấy rằng bảng lương yêu cầu khôi phục.
employees.departments OK
employees.dept_emp OK
employees.dept_manager OK
employees.employees OK
Employees.salaries
Warning : Tablespace is missing for table 'employees/salaries'
Error : Table 'employees.salaries' doesn't exist in engine
status : Operation failed
employees.titles OKĐối với cài đặt một nút không có máy chủ DR bổ sung, cách tiếp cận chính sẽ là khôi phục dữ liệu từ bản sao lưu. Nhưng đây không phải là điều duy nhất bạn cần xem xét. Có nhiều lược đồ cơ sở dữ liệu trong cùng một trường hợp gây ra sự cố khi bạn phải đưa máy chủ của mình xuống để khôi phục dữ liệu. Một câu hỏi khác là liệu bạn có đủ khả năng để khôi phục tất cả cơ sở dữ liệu của mình về bản sao lưu cuối cùng hay không. Trong hầu hết các trường hợp, điều đó sẽ không thể thực hiện được.
Có một số ngoại lệ ở đây. Có thể khôi phục một bảng hoặc cơ sở dữ liệu từ bản sao lưu cuối cùng khi không cần khôi phục tại thời điểm. Quá trình như vậy là phức tạp hơn. Nếu bạn có mysqldump, bạn có thể trích xuất cơ sở dữ liệu của mình từ đó. Nếu bạn chạy sao lưu nhị phân với xtradbackup hoặc mariabackup và bạn đã bật bảng trên mỗi tệp thì có thể thực hiện được.
Đây là cách kiểm tra xem bạn đã bật tùy chọn bảng trên mỗi tệp hay chưa.
mysql> SET GLOBAL innodb_file_per_table=1; Với việc kích hoạt innodb_file_per_table, bạn có thể lưu trữ các bảng InnoDB trong tệp tbl_name .ibd. Không giống như công cụ lưu trữ MyISAM, với các tệp tbl_name .MYD và tbl_name .MYI riêng biệt cho chỉ mục và dữ liệu, InnoDB lưu trữ dữ liệu và các chỉ mục cùng nhau trong một tệp .ibd duy nhất. Để kiểm tra công cụ lưu trữ của bạn, bạn cần chạy:
mysql> select table_name,engine from information_schema.tables where table_name='table_name' and table_schema='database_name';hoặc trực tiếp từ bảng điều khiển:
[example@sqldat.com ~]# mysql -u<username> -p -D<database_name> -e "show table status\G"
Enter password:
*************************** 1. row ***************************
Name: test1
Engine: InnoDB
Version: 10
Row_format: Dynamic
Rows: 12
Avg_row_length: 1365
Data_length: 16384
Max_data_length: 0
Index_length: 0
Data_free: 0
Auto_increment: NULL
Create_time: 2018-05-24 17:54:33
Update_time: NULL
Check_time: NULL
Collation: latin1_swedish_ci
Checksum: NULL
Create_options:
Comment: Để khôi phục bảng từ xtradbackup, bạn cần phải trải qua quá trình xuất. Cần chuẩn bị sao lưu trước khi có thể khôi phục. Việc xuất khẩu được thực hiện trong giai đoạn chuẩn bị. Khi một bản sao lưu đầy đủ được tạo, hãy chạy quy trình chuẩn bị tiêu chuẩn với cờ bổ sung --export:
innobackupex --apply-log --export /u01/backupThao tác này sẽ tạo các tệp xuất bổ sung mà bạn sẽ sử dụng sau này trong giai đoạn nhập. Để nhập một bảng vào một máy chủ khác, trước tiên hãy tạo một bảng mới có cùng cấu trúc với cấu trúc sẽ được nhập tại máy chủ đó:
mysql> CREATE TABLE corrupted_table (...) ENGINE=InnoDB;loại bỏ vùng bảng:
mysql> ALTER TABLE mydatabase.mytable DISCARD TABLESPACE;Sau đó, sao chép các tệp mytable.ibd và mytable.exp vào trang chủ của cơ sở dữ liệu và nhập vùng bảng của nó:
mysql> ALTER TABLE mydatabase.mytable IMPORT TABLESPACE;Tuy nhiên, để thực hiện điều này theo cách có kiểm soát hơn, khuyến nghị sẽ là khôi phục bản sao lưu cơ sở dữ liệu trong phiên bản / máy chủ khác và sao chép những gì cần thiết trở lại hệ thống chính. Để làm như vậy, bạn cần chạy cài đặt phiên bản mysql. Điều này có thể được thực hiện trên cùng một máy - nhưng đòi hỏi nhiều nỗ lực hơn để định cấu hình theo cách mà cả hai phiên bản có thể chạy trên cùng một máy - ví dụ:yêu cầu cài đặt giao tiếp khác nhau.
Bạn có thể kết hợp cả khôi phục tác vụ và cài đặt bằng ClusterControl.
ClusterControl sẽ hướng dẫn bạn qua các bản sao lưu có sẵn tại chỗ hoặc trên đám mây, cho phép bạn chọn thời gian chính xác để khôi phục hoặc vị trí nhật ký chính xác và cài đặt phiên bản cơ sở dữ liệu mới nếu cần.
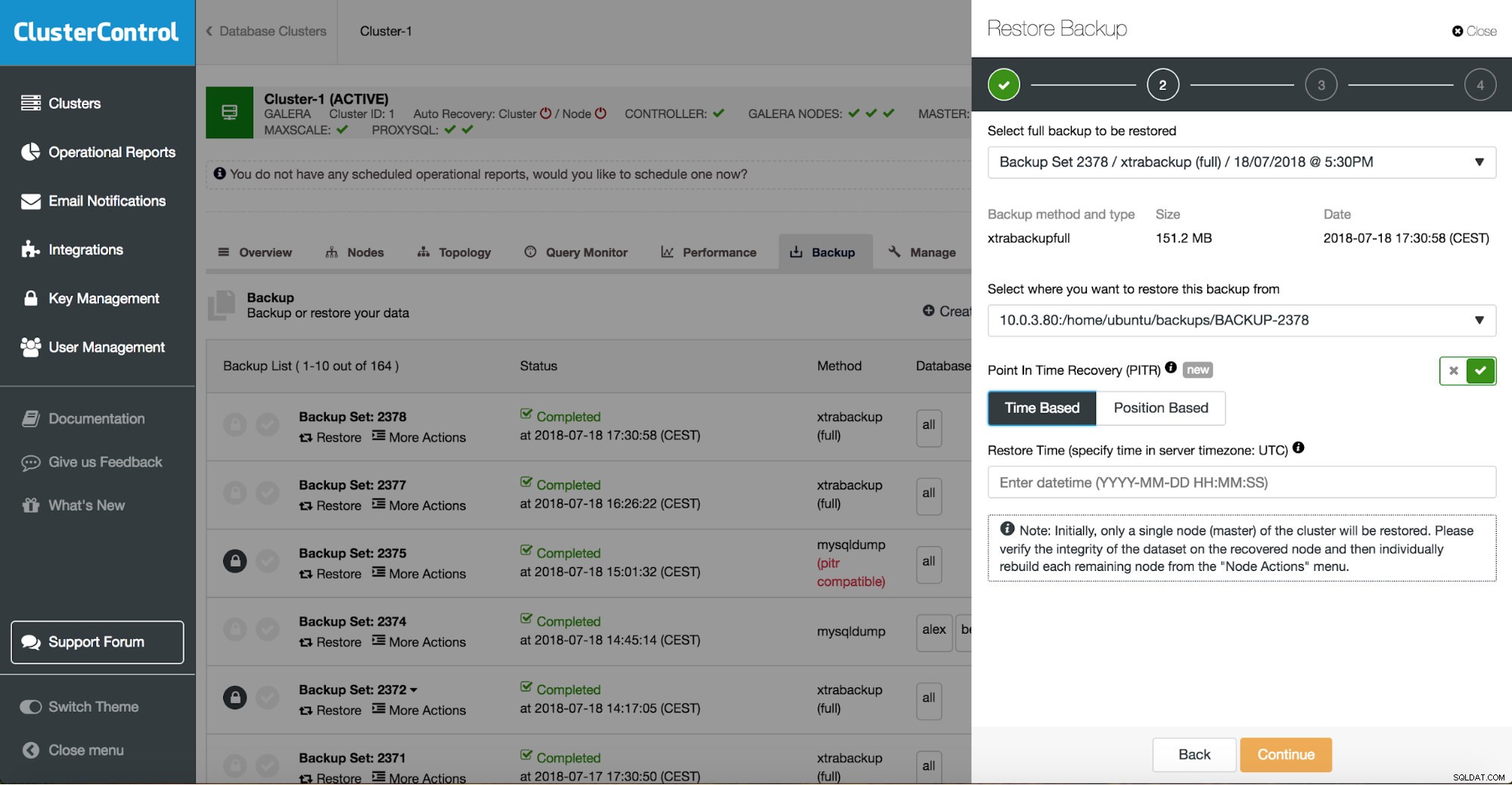 Khôi phục thời điểm ClusterControl
Khôi phục thời điểm ClusterControl 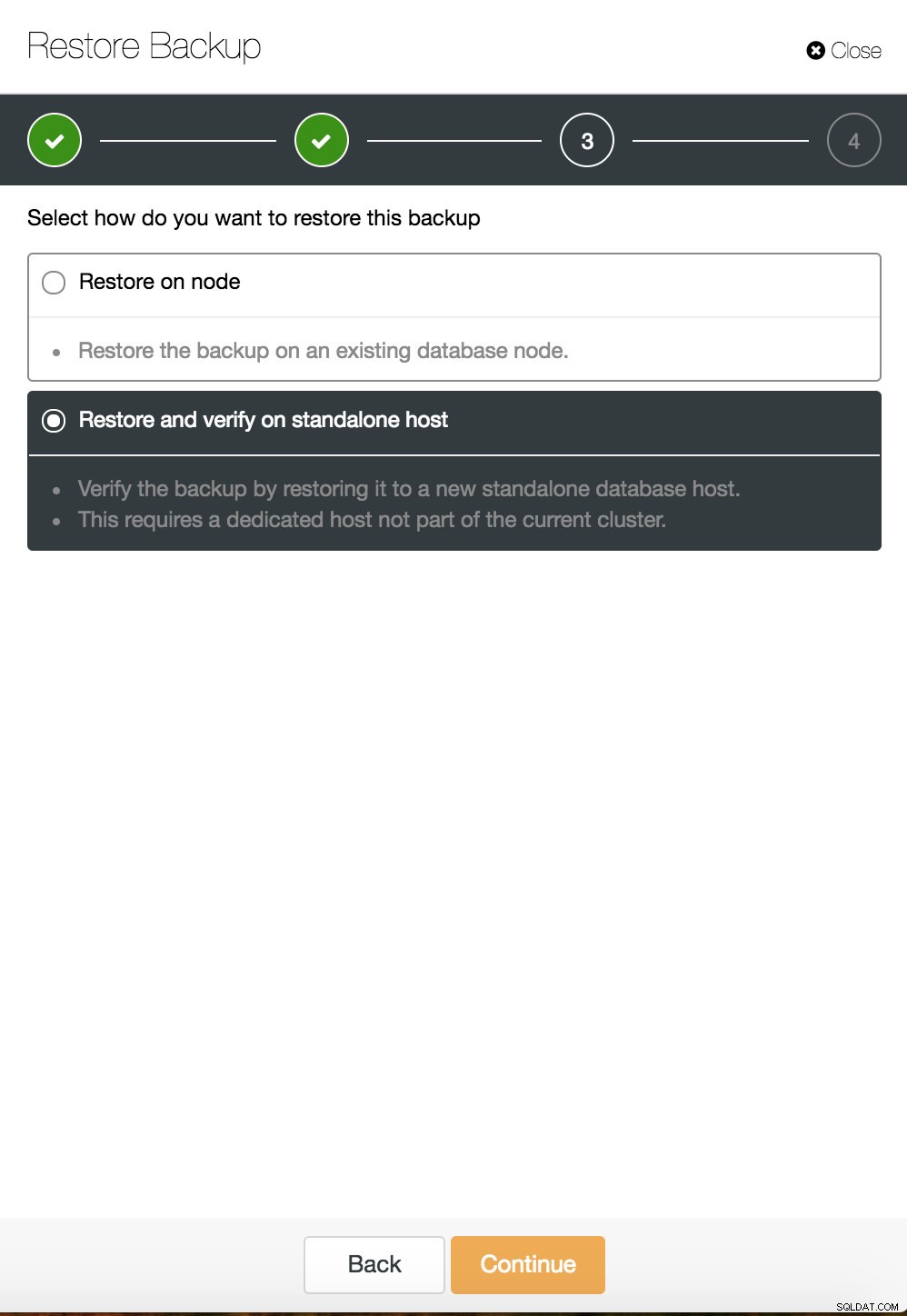 Khôi phục và xác minh ClusterControl trên một máy chủ độc lập
Khôi phục và xác minh ClusterControl trên một máy chủ độc lập 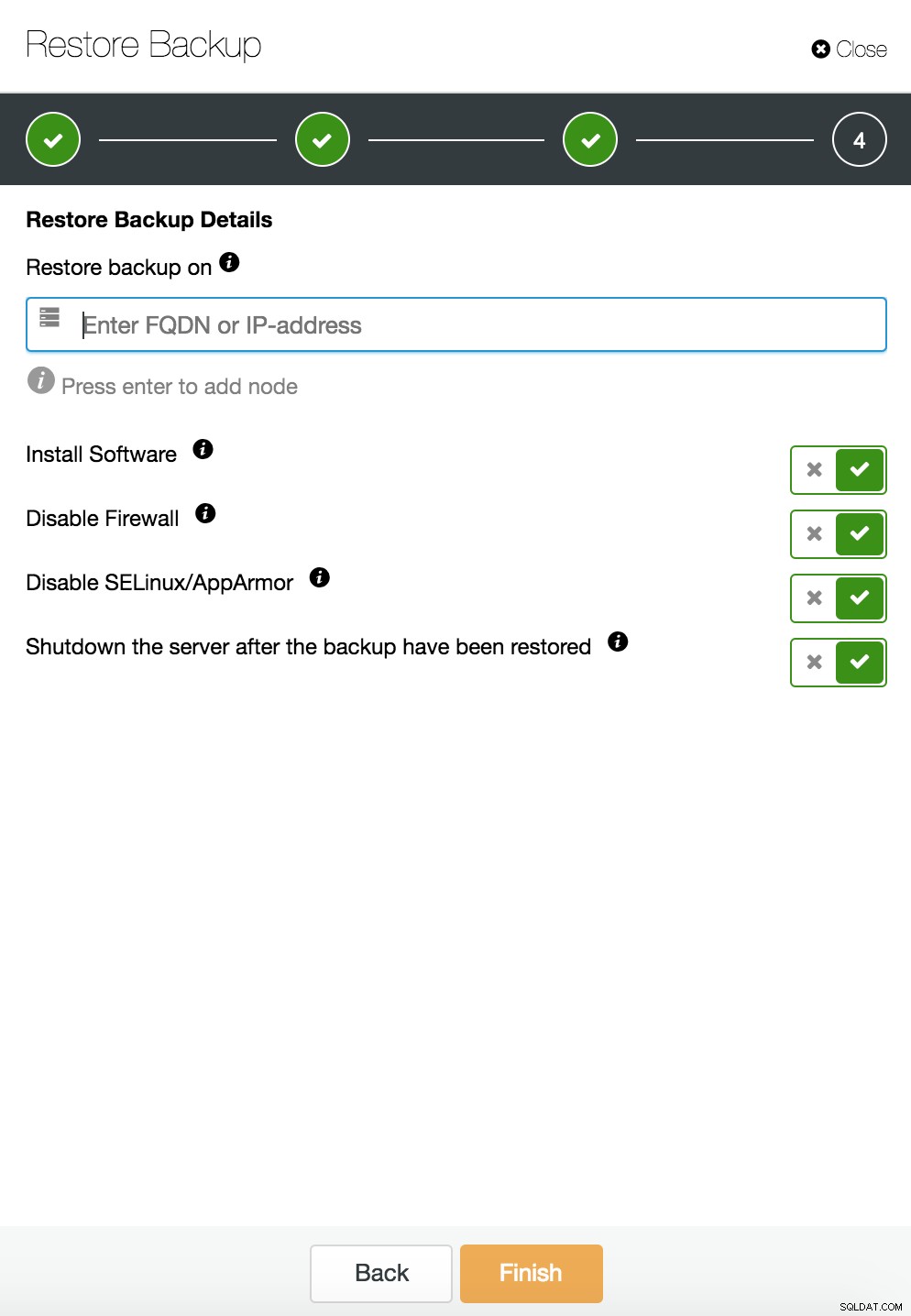 CusterControl khôi phục và xác minh trên một máy chủ độc lập. Các tùy chọn cài đặt.
CusterControl khôi phục và xác minh trên một máy chủ độc lập. Các tùy chọn cài đặt. Bạn có thể tìm thêm thông tin về khôi phục dữ liệu trong blog Cơ sở dữ liệu MySQL của tôi bị hỏng ... Tôi phải làm gì bây giờ?
Phiên bản cơ sở dữ liệu bị hỏng trên máy chủ chuyên dụng
Các khiếm khuyết trong nền tảng cơ bản thường là nguyên nhân gây ra hỏng cơ sở dữ liệu. Phiên bản MySQL của bạn dựa vào một số thứ để lưu trữ và truy xuất dữ liệu - hệ thống con đĩa, bộ điều khiển, kênh giao tiếp, trình điều khiển và phần sụn. Sự cố có thể ảnh hưởng đến các phần dữ liệu của bạn, mã nhị phân mysql hoặc thậm chí các tệp sao lưu mà bạn lưu trữ trên hệ thống. Để tách các ứng dụng khác nhau, bạn có thể đặt chúng trên các máy chủ chuyên dụng.
Các lược đồ ứng dụng khác nhau trên các hệ thống riêng biệt là một ý tưởng hay nếu bạn có đủ khả năng. Người ta có thể nói rằng đây là một sự lãng phí tài nguyên, nhưng có khả năng là tác động kinh doanh sẽ ít hơn nếu chỉ một trong số chúng đi xuống. Nhưng ngay cả khi đó, bạn cũng cần bảo vệ cơ sở dữ liệu của mình khỏi bị mất dữ liệu. Lưu trữ bản sao lưu trên cùng một máy chủ không phải là một ý tưởng tồi miễn là bạn có một bản sao ở một nơi khác. Ngày nay, lưu trữ đám mây là một giải pháp thay thế tuyệt vời cho sao lưu băng.
ClusterControl cho phép bạn giữ một bản sao lưu của mình trên đám mây. Nó hỗ trợ tải lên 3 nhà cung cấp đám mây hàng đầu - Amazon AWS, Google Cloud và Microsoft Azure.
Khi bạn đã khôi phục toàn bộ bản sao lưu của mình, bạn có thể muốn khôi phục bản sao lưu đó vào một thời điểm nhất định. Khôi phục theo thời gian sẽ đưa máy chủ cập nhật vào thời điểm gần đây hơn so với thời điểm sao lưu đầy đủ được thực hiện. Để làm như vậy, bạn cần bật nhật ký nhị phân của mình. Bạn có thể kiểm tra nhật ký nhị phân có sẵn bằng:
mysql> SHOW BINARY LOGS;Và tệp nhật ký hiện tại với:
SHOW MASTER STATUS;Sau đó, bạn có thể nắm bắt dữ liệu gia tăng bằng cách chuyển các bản ghi nhị phân vào tệp sql. Các thao tác bị thiếu sau đó có thể được thực thi lại.
mysqlbinlog --start-position='14231131' --verbose /var/lib/mysql/binlog.000010 /var/lib/mysql/binlog.000011 /var/lib/mysql/binlog.000012 /var/lib/mysql/binlog.000013 /var/lib/mysql/binlog.000015 > binlog.outĐiều tương tự cũng có thể được thực hiện trong ClusterControl.
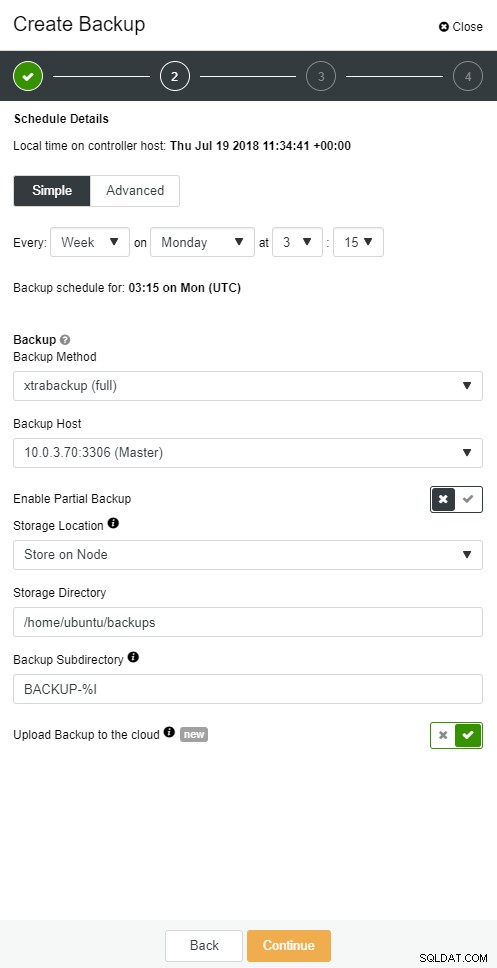 Sao lưu đám mây ClusterControl
Sao lưu đám mây ClusterControl 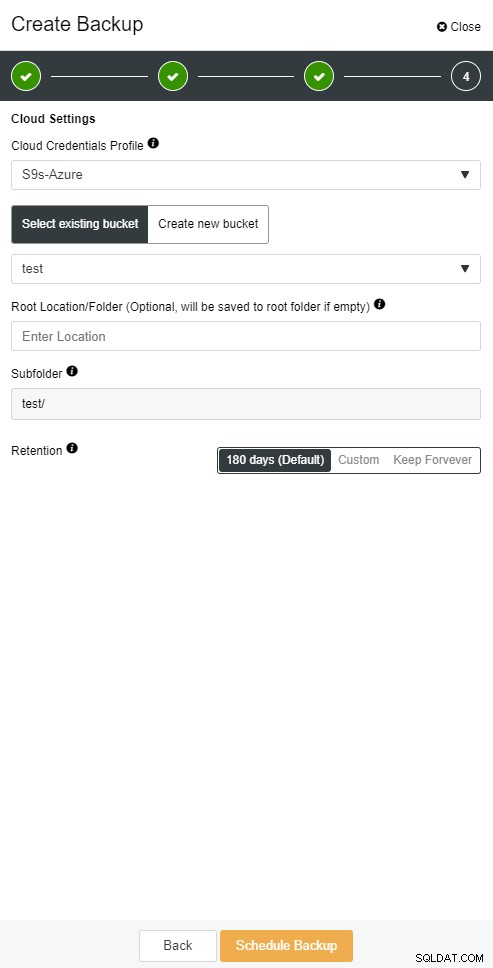 Sao lưu đám mây ClusterControl
Sao lưu đám mây ClusterControl Nô lệ cơ sở dữ liệu ngừng hoạt động
Ok, vậy là bạn đã có cơ sở dữ liệu của mình đang chạy trên một máy chủ chuyên dụng. Bạn đã tạo một lịch trình sao lưu phức tạp với sự kết hợp của các bản sao lưu đầy đủ và tăng dần, tải chúng lên đám mây và lưu trữ bản sao lưu mới nhất trên các đĩa cục bộ để khôi phục nhanh. Bạn có các chính sách lưu giữ bản sao lưu khác nhau - ngắn hơn cho các bản sao lưu được lưu trữ trên trình điều khiển đĩa cục bộ và mở rộng cho các bản sao lưu đám mây của bạn.
Có vẻ như bạn đã chuẩn bị tốt cho một kịch bản thảm họa. Nhưng khi nói đến thời gian khôi phục, nó có thể không đáp ứng được nhu cầu kinh doanh của bạn.
Bạn cần một chức năng chuyển đổi dự phòng nhanh chóng. Một máy chủ sẽ được thiết lập và chạy áp dụng các bản ghi nhị phân từ máy chủ nơi ghi xảy ra. Bản sao Master / Slave bắt đầu một chương mới trong kịch bản chuyển đổi dự phòng. Đó là một phương pháp nhanh chóng để làm cho ứng dụng của bạn hoạt động trở lại nếu bạn thành thạo.
Nhưng có một số điều cần xem xét trong kịch bản chuyển đổi dự phòng. Một là thiết lập nô lệ sao chép bị trì hoãn, vì vậy bạn có thể phản ứng với các lệnh ngón tay béo được kích hoạt trên máy chủ chính. Máy chủ phụ có thể tụt hậu so với máy chủ ít nhất trong một khoảng thời gian nhất định. Độ trễ mặc định là 0 giây. Sử dụng tùy chọn MASTER_DELAY cho CHANGE MASTER TO để đặt độ trễ thành N giây:
CHANGE MASTER TO MASTER_DELAY = N;Thứ hai là kích hoạt chuyển đổi dự phòng tự động. Có rất nhiều giải pháp chuyển đổi dự phòng tự động trên thị trường. Bạn có thể thiết lập chuyển đổi dự phòng tự động bằng các công cụ dòng lệnh như MHA, MRM, mysqlfailover hoặc GUI Orchestrator và ClusterControl. Khi nó được thiết lập đúng cách, nó có thể giảm đáng kể tình trạng ngừng hoạt động của bạn.
ClusterControl hỗ trợ chuyển đổi dự phòng tự động cho các bản sao MySQL, PostgreSQL và MongoDB cũng như các giải pháp cụm đa tổng thể Galera và NDB.
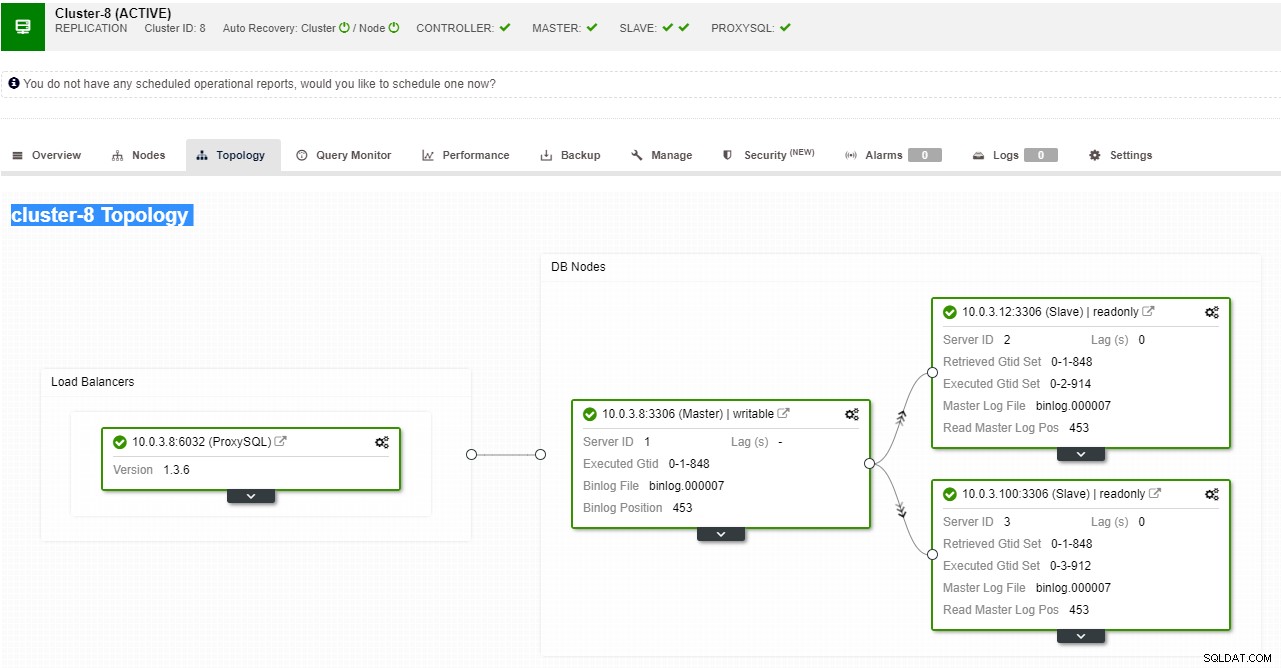 Chế độ xem cấu trúc liên kết sao chép ClusterControl
Chế độ xem cấu trúc liên kết sao chép ClusterControl Khi một nút nô lệ gặp sự cố và máy chủ bị tụt hậu nghiêm trọng, bạn có thể muốn xây dựng lại máy chủ nô lệ của mình. Quá trình xây dựng lại nô lệ tương tự như khôi phục từ bản sao lưu.
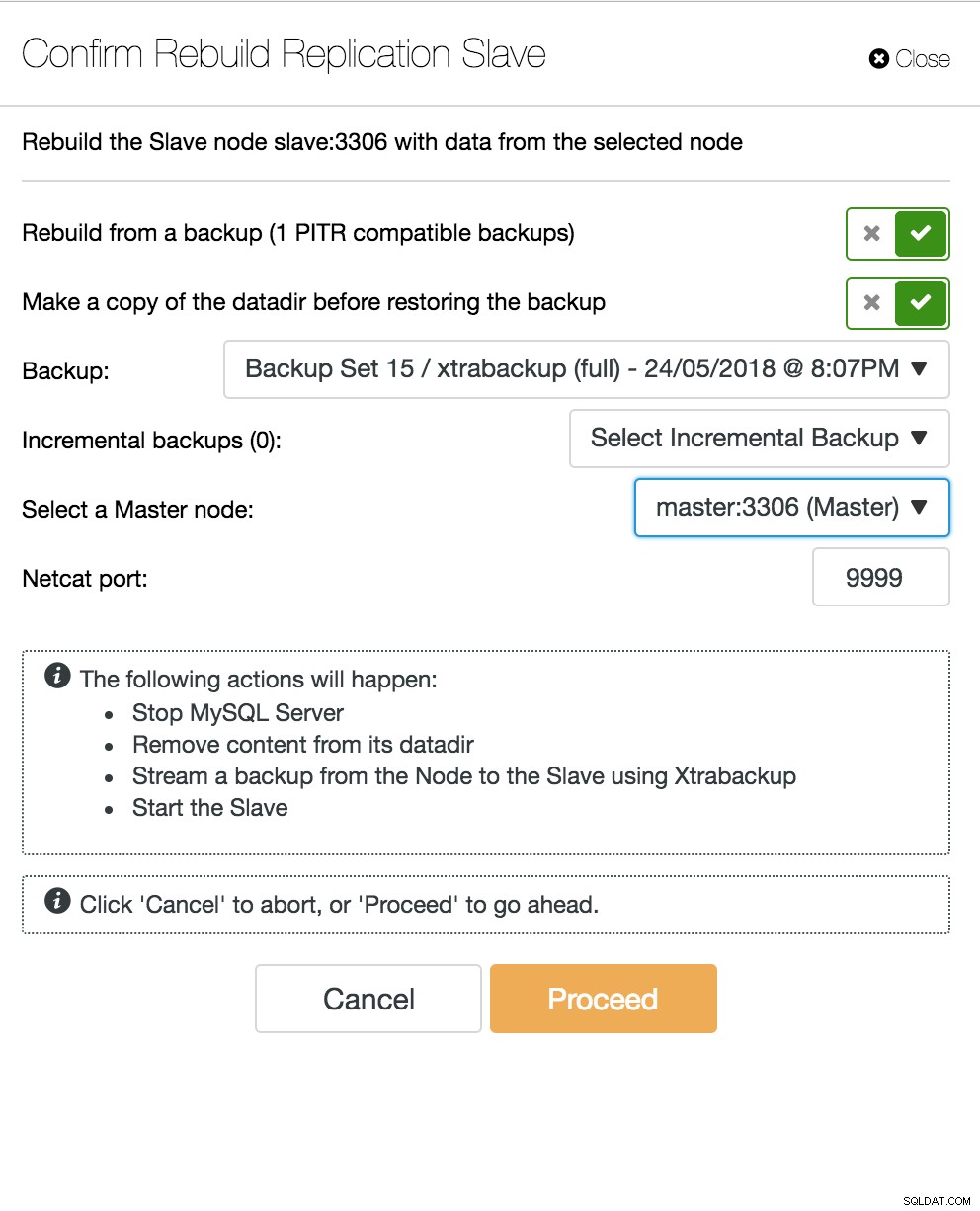 nô lệ xây dựng lại ClusterControl
nô lệ xây dựng lại ClusterControl Máy chủ đa cơ sở dữ liệu ngừng hoạt động
Giờ đây, khi bạn có máy chủ nô lệ hoạt động như một nút DR và quá trình chuyển đổi dự phòng của bạn được kiểm tra và tự động hóa tốt, cuộc sống DBA của bạn sẽ trở nên thoải mái hơn. Điều đó đúng, nhưng có một số câu đố cần giải quyết. Sức mạnh máy tính không miễn phí và nhóm kinh doanh của bạn có thể yêu cầu bạn sử dụng phần cứng của mình tốt hơn, bạn có thể muốn sử dụng máy chủ nô lệ của mình không chỉ làm máy chủ thụ động mà còn để phục vụ các hoạt động ghi.
Sau đó, bạn có thể muốn điều tra một giải pháp sao chép đa tổng thể. Galera Cluster đã trở thành một lựa chọn chính cho MySQL và MariaDB có tính khả dụng cao. Và mặc dù bây giờ nó được biết đến như một sự thay thế đáng tin cậy cho các kiến trúc chủ-nô MySQL truyền thống, nhưng nó không phải là một sự thay thế thả xuống.
Cụm Galera có kiến trúc không chia sẻ gì cả. Thay vì các đĩa dùng chung, Galera sử dụng sao chép dựa trên chứng nhận với giao tiếp nhóm và sắp xếp giao dịch để đạt được sự nhân rộng đồng bộ. Một cụm cơ sở dữ liệu sẽ có thể tồn tại khi mất một nút, mặc dù nó đạt được theo những cách khác nhau. Trong trường hợp của Galera, khía cạnh quan trọng là số lượng nút. Galera yêu cầu một số đại biểu để duy trì hoạt động. Một cụm ba nút có thể tồn tại sau sự cố của một nút. Với nhiều nút hơn trong cụm của bạn, bạn có thể tồn tại nhiều thất bại hơn.
Quá trình khôi phục được tự động hóa nên bạn không cần thực hiện bất kỳ hoạt động chuyển đổi dự phòng nào. Tuy nhiên, phương pháp hay là giết các nút và xem bạn có thể đưa chúng trở lại nhanh như thế nào. Để làm cho hoạt động này hiệu quả hơn, bạn có thể sửa đổi kích thước bộ nhớ cache của galera. Nếu kích thước bộ nhớ cache của galera không được quy hoạch đúng cách, nút khởi động tiếp theo của bạn sẽ phải thực hiện một bản sao lưu đầy đủ thay vì chỉ thiếu các bộ ghi trong bộ nhớ cache.
Kịch bản chuyển đổi dự phòng đơn giản như bắt đầu ý định. Dựa trên dữ liệu trong bộ nhớ cache của galera, nút khởi động sẽ điều chỉnh SST (khôi phục từ bản sao lưu đầy đủ) hoặc IST (áp dụng các bộ ghi bị thiếu). Tuy nhiên, điều này thường liên quan đến sự can thiệp của con người. Nếu bạn muốn tự động hóa toàn bộ quy trình chuyển đổi dự phòng, bạn có thể sử dụng chức năng tự động khôi phục của ClusterControl (cấp độ nút và cụm).
 Tự động khôi phục cụm ClusterControl
Tự động khôi phục cụm ClusterControl Ước tính kích thước bộ nhớ cache của galera:
MariaDB [(none)]> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;Để làm cho chuyển đổi dự phòng nhất quán hơn, bạn nên bật gcache.recover =yes trong mycnf. Tùy chọn này sẽ phục hồi galera-cache khi khởi động lại. Điều này có nghĩa là nút có thể hoạt động như một DONOR và dịch vụ thiếu bộ ghi (tạo điều kiện cho IST, thay vì sử dụng SST).
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Quorum results:
version = 4,
component = PRIMARY,
conf_id = 2,
members = 2/3 (joined/total),
act_id = 12810,
last_appl. = 0,
protocols = 0/7/3 (gcs/repl/appl),
group UUID = 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Flow-control interval: [28, 28]
2018-07-20 8:59:44 139656049956608 [Note] WSREP: Trying to continue unpaused monitor
2018-07-20 8:59:44 139657311033088 [Note] WSREP: New cluster view: global state: 49eca8f8-0e3a-11e8-be4a-e7e3fe48cb69:12810, view# 3: Primary, number of nodes: 3, my index: 1, protocol version 3Nút proxy SQL bị hỏng
Nếu bạn có thiết lập IP ảo, tất cả những gì bạn phải làm là trỏ ứng dụng của mình đến địa chỉ IP ảo và mọi thứ phải là kết nối chính xác. Việc có các phiên bản cơ sở dữ liệu của bạn trải dài trên nhiều trung tâm dữ liệu là chưa đủ, bạn vẫn cần các ứng dụng của mình để truy cập chúng. Giả sử bạn đã mở rộng số lượng bản sao đã đọc, bạn có thể muốn triển khai IP ảo cho mỗi bản sao đã đọc đó vì lý do bảo trì hoặc tính khả dụng. Nó có thể trở thành một tập hợp các IP ảo cồng kềnh mà bạn phải quản lý. Nếu một trong những bản sao đã đọc đó gặp sự cố, bạn cần gán lại IP ảo cho máy chủ khác, nếu không ứng dụng của bạn sẽ kết nối với máy chủ bị hỏng hoặc trong trường hợp xấu nhất là máy chủ bị chậm với dữ liệu cũ.
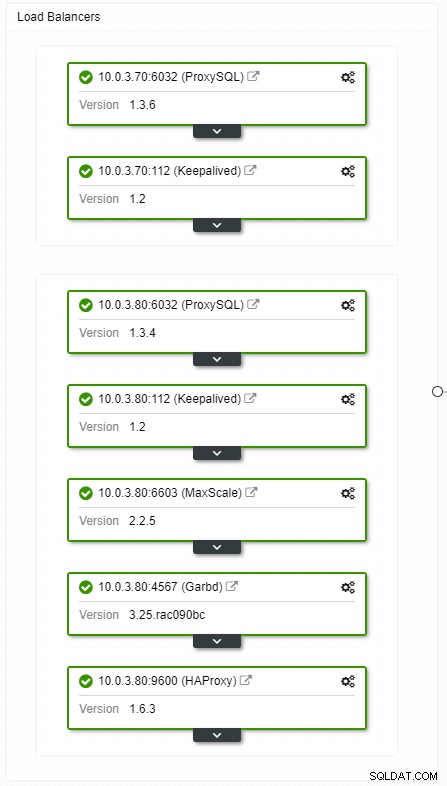 Chế độ xem cấu trúc liên kết bộ cân bằng tải ClusterControl HA
Chế độ xem cấu trúc liên kết bộ cân bằng tải ClusterControl HA Sự cố không thường xuyên nhưng có thể xảy ra nhiều hơn so với việc máy chủ gặp sự cố. Nếu vì bất cứ lý do gì, một nô lệ gặp sự cố, một thứ gì đó như ProxySQL sẽ chuyển hướng tất cả lưu lượng đến chủ, với nguy cơ làm quá tải nó. Khi nô lệ phục hồi, lưu lượng truy cập sẽ được chuyển hướng trở lại nó. Thông thường, thời gian ngừng hoạt động như vậy sẽ không kéo dài quá vài phút, do đó mức độ nghiêm trọng tổng thể là trung bình, mặc dù xác suất cũng ở mức trung bình.
Để dự phòng các thành phần của bộ cân bằng tải, bạn có thể sử dụng keepalived.
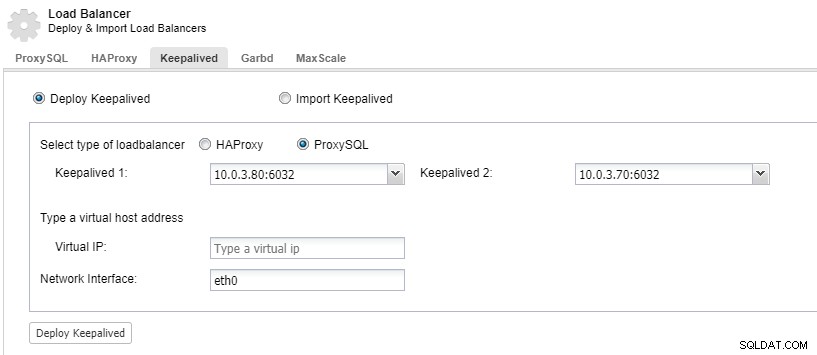 ClusterControl:Triển khai keepalived cho bộ cân bằng tải ProxySQL
ClusterControl:Triển khai keepalived cho bộ cân bằng tải ProxySQL Trung tâm dữ liệu đi xuống
Vấn đề chính của việc nhân rộng là không có cơ chế đa số nào để phát hiện lỗi trung tâm dữ liệu và phục vụ chủ mới. Một trong những giải pháp là sử dụng Orchestrator / Raft. Orchestrator là một trình giám sát cấu trúc liên kết có thể kiểm soát chuyển đổi dự phòng. Khi được sử dụng cùng với Raft, Orchestrator sẽ trở nên nhận biết theo túc số. Một trong các phiên bản Orchestrator được bầu làm lãnh đạo và thực hiện các nhiệm vụ khôi phục. Kết nối giữa nút dàn nhạc không tương quan với cam kết cơ sở dữ liệu giao dịch và rất thưa thớt.
Orchestrator / Raft có thể sử dụng các trường hợp bổ sung để giám sát cấu trúc liên kết hiệu quả. Trong trường hợp phân vùng mạng, các bản sao của Bộ điều phối được phân vùng sẽ không thực hiện bất kỳ hành động nào. Phần của cụm Orchestrator có số đại biểu sẽ chọn một cái mới và thực hiện các thay đổi cấu trúc liên kết cần thiết.
ClusterControl được sử dụng để quản lý, mở rộng quy mô và điều quan trọng nhất là khôi phục nút - Orchestrator sẽ xử lý các chuyển đổi dự phòng, nhưng nếu nô lệ gặp sự cố, ClusterControl sẽ đảm bảo rằng nó sẽ được khôi phục. Orchestrator và ClusterControl sẽ được đặt trong cùng một vùng khả dụng, tách biệt với các nút MySQL, để đảm bảo hoạt động của chúng sẽ không bị ảnh hưởng bởi sự phân chia mạng giữa các vùng khả dụng trong trung tâm dữ liệu.



