Mục tiêu thời gian khôi phục (RTO) là khoảng thời gian mà dịch vụ phải được khôi phục để tránh những hậu quả không thể chấp nhận được. Bằng cách tính toán thời gian có thể khôi phục sau sự cố cơ sở dữ liệu, chúng ta có thể biết mức độ chuẩn bị cần thiết. Nếu RTO là một vài phút, thì cần phải đầu tư đáng kể vào chuyển đổi dự phòng. RTO trong 36 giờ yêu cầu đầu tư thấp hơn đáng kể. Đây là lúc tự động chuyển đổi dự phòng xuất hiện.
Trong các blog trước đây của chúng tôi, chúng tôi đã thảo luận về chuyển đổi dự phòng cho MongoDB, MySQL / MariaDB / Percona, PostgreSQL hoặc TimeScaleDB. Tóm lại, " Chuyển đổi dự phòng "là khả năng hệ thống tiếp tục hoạt động ngay cả khi một số lỗi xảy ra. Nó gợi ý rằng các chức năng của hệ thống được đảm nhận bởi các thành phần thứ cấp nếu các thành phần chính bị lỗi. Chuyển đổi dự phòng là một phần tự nhiên của bất kỳ hệ thống có tính khả dụng cao nào và trong một số trường hợp , nó thậm chí phải được tự động hóa. Quá trình chuyển đổi dự phòng thủ công chỉ mất quá nhiều thời gian, nhưng có những trường hợp tự động hóa sẽ không hoạt động tốt - ví dụ như trong trường hợp bộ não phân chia nơi sao chép cơ sở dữ liệu bị hỏng và hai 'nửa' tiếp tục nhận các bản cập nhật, một cách hiệu quả dẫn đến các tập dữ liệu khác nhau và không nhất quán.
Trước đây chúng tôi đã viết về các nguyên tắc hướng dẫn đằng sau quy trình chuyển đổi dự phòng tự động ClusterControl. Nếu có thể, chuyển đổi dự phòng tự động mang lại hiệu quả vì nó cho phép khôi phục nhanh chóng các lỗi. Trong blog này, chúng ta sẽ xem xét cách đạt được chuyển đổi dự phòng tự động trong thiết lập sao chép master-slave (hoặc chính-standby) bằng cách sử dụng ClusterControl.
Yêu cầu về ngăn xếp công nghệ
Một ngăn xếp có thể được lắp ráp từ các thành phần Phần mềm nguồn mở và có sẵn một số tùy chọn - một số tùy chọn thích hợp hơn các tùy chọn khác tùy thuộc vào đặc điểm chuyển đổi dự phòng và cũng như mức độ chuyên môn có sẵn để quản lý và duy trì giải pháp. Phần cứng và mạng cũng là những khía cạnh quan trọng.
Phần mềm
Có rất nhiều tùy chọn có sẵn trong hệ sinh thái mã nguồn mở mà bạn có thể sử dụng để thực hiện chuyển đổi dự phòng. Đối với MySQL, bạn có thể tận dụng lợi thế của MHA, MMM, Maxscale / MRM, mysqlfailover hoặc Orchestrator. Blog trước này so sánh MaxScale với MHA với Maxscale / MRM. PostgreSQL có repmgr, Patroni, PostgreSQL Automatic Failover (PAF), pglookout, pgPool-II hoặc stolon. Các tùy chọn tính khả dụng cao khác nhau này đã được đề cập trước đây. MongoDB có các bộ bản sao với hỗ trợ chuyển đổi dự phòng tự động.
ClusterControl cung cấp chức năng chuyển đổi dự phòng tự động cho MySQL, MariaDB, PostgreSQL và MongoDB, chúng tôi sẽ đề cập sâu hơn. Đáng lưu ý là nó cũng có chức năng tự động khôi phục các nút hoặc cụm bị hỏng.
Phần cứng
Chuyển đổi dự phòng tự động thường được thực hiện bởi một máy chủ daemon riêng biệt được thiết lập trên phần cứng của chính nó - tách biệt với các nút cơ sở dữ liệu. Nó đang theo dõi trạng thái của cơ sở dữ liệu và sử dụng thông tin để đưa ra quyết định về cách phản ứng trong trường hợp thất bại.
Máy chủ hàng hóa có thể hoạt động tốt, trừ khi máy chủ đang theo dõi một số lượng lớn các trường hợp. Thông thường, kiểm tra hệ thống và phân tích tình trạng nhẹ về mặt xử lý. Tuy nhiên, nếu bạn có một số lượng lớn các nút cần kiểm tra, thì CPU và bộ nhớ lớn là điều bắt buộc, đặc biệt khi việc kiểm tra phải được xếp hàng đợi vì nó cố gắng ping và thu thập thông tin từ các máy chủ. Các nút đang được theo dõi và giám sát đôi khi có thể bị ngưng trệ do sự cố mạng, tải cao hoặc trong trường hợp tệ hơn, chúng có thể ngừng hoạt động do lỗi phần cứng hoặc một số máy chủ VM bị hỏng. Vì vậy, máy chủ chạy kiểm tra tình trạng và hệ thống sẽ có thể chịu được các lỗi như vậy, vì rất có thể việc xử lý hàng đợi có thể tăng lên vì phản hồi cho từng nút được giám sát có thể mất thời gian cho đến khi được xác minh rằng nó không còn khả dụng hoặc hết thời gian chờ đã đạt được.
Đối với các môi trường dựa trên đám mây, có những dịch vụ cung cấp chuyển đổi dự phòng tự động. Ví dụ:Amazon RDS sử dụng DRBD để sao chép bộ nhớ sang một nút chờ. Hoặc nếu bạn đang lưu trữ các tập của mình trong EBS, thì những tập này sẽ được sao chép trong nhiều vùng.
Mạng
Phần mềm chuyển đổi dự phòng tự động thường dựa vào các tác nhân được thiết lập trên các nút cơ sở dữ liệu. Tác nhân thu thập thông tin cục bộ từ cá thể cơ sở dữ liệu và gửi đến máy chủ, bất cứ khi nào được yêu cầu.
Về yêu cầu mạng, hãy đảm bảo rằng bạn có băng thông tốt và kết nối mạng ổn định. Việc kiểm tra cần được thực hiện thường xuyên và việc bỏ lỡ nhịp tim do mạng không ổn định có thể dẫn đến việc phần mềm chuyển đổi dự phòng (sai) suy ra rằng một nút bị lỗi.
ClusterControl không yêu cầu bất kỳ tác nhân nào được cài đặt trên các nút cơ sở dữ liệu, vì nó sẽ SSH vào mỗi nút cơ sở dữ liệu theo khoảng thời gian đều đặn và thực hiện một số kiểm tra.
Chuyển đổi dự phòng tự động với ClusterControl
ClusterControl cung cấp khả năng thực hiện chuyển đổi dự phòng thủ công cũng như tự động. Hãy xem cách này có thể được thực hiện như thế nào.
Chuyển đổi dự phòng trong ClusterControl có thể được định cấu hình thành tự động hoặc không. Nếu bạn muốn thực hiện chuyển đổi dự phòng theo cách thủ công, bạn có thể tắt khôi phục cụm tự động. Khi thực hiện chuyển đổi dự phòng thủ công, bạn có thể đi tới Cụm → Cấu trúc liên kết trong ClusterControl. Xem ảnh chụp màn hình bên dưới:
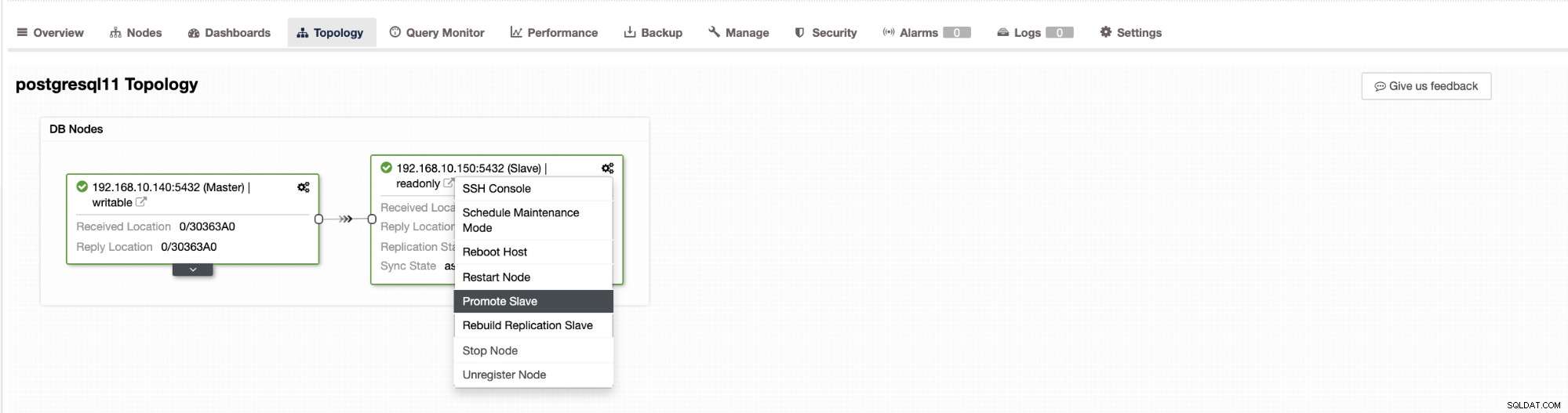
Theo mặc định, khôi phục cụm được bật và chuyển đổi dự phòng tự động được sử dụng. Sau khi bạn thực hiện các thay đổi trong giao diện người dùng, cấu hình thời gian chạy sẽ thay đổi. Nếu bạn muốn cài đặt tồn tại khi khởi động lại bộ điều khiển, thì hãy đảm bảo rằng bạn cũng thực hiện thay đổi trong cấu hình cmon, tức là /etc/cmon.d/cmon_

Trong máy chủ MySQL / MariaDB / Percona, chuyển đổi dự phòng tự động được khởi tạo bởi ClusterControl khi phát hiện không có máy chủ nào có read_only cờ bị vô hiệu hóa. Điều này có thể xảy ra bởi vì chính (có read_only đặt thành 0) không khả dụng hoặc nó có thể được kích hoạt bởi người dùng hoặc một số phần mềm bên ngoài đã thay đổi cờ này trên trang cái. Nếu bạn thực hiện các thay đổi thủ công đối với các nút cơ sở dữ liệu hoặc có phần mềm có thể làm khó cài đặt read_only, thì bạn nên tắt chuyển đổi dự phòng tự động. Chuyển đổi dự phòng tự động của ClusterControl chỉ được thử một lần, do đó, chuyển đổi dự phòng không thành công sẽ không được thực hiện lại bởi chuyển đổi dự phòng tiếp theo - không cho đến khi cmon được khởi động lại.
Đối với PostgreSQL, ClusterControl sẽ chọn nô lệ nâng cao nhất, sử dụng cho mục đích này là pg_current_xlog_location (PostgreSQL 9+) hoặc pg_current_wal_lsn (PostgreSQL 10+) tùy thuộc vào phiên bản cơ sở dữ liệu của chúng tôi. ClusterControl cũng thực hiện một số kiểm tra trong quá trình chuyển đổi dự phòng, để tránh một số lỗi phổ biến. Một ví dụ là nếu chúng tôi quản lý để khôi phục trang cái cũ bị lỗi, nó sẽ " không "được tự động giới thiệu lại với cụm, không phải với tư cách là chủ cũng như không phải là nô lệ. Chúng tôi cần làm điều đó theo cách thủ công. Điều này sẽ tránh khả năng mất dữ liệu hoặc không nhất quán trong trường hợp nô lệ của chúng tôi (mà chúng tôi đã quảng bá) bị trì hoãn vào thời điểm đó của lỗi. Chúng tôi cũng có thể muốn phân tích vấn đề chi tiết trước khi giới thiệu lại vấn đề với thiết lập sao chép, vì vậy chúng tôi muốn lưu giữ thông tin chẩn đoán.
Ngoài ra, nếu chuyển đổi dự phòng không thành công, không có nỗ lực nào khác được thực hiện (điều này áp dụng cho cả hai cụm dựa trên PostgreSQL và MySQL), cần có sự can thiệp thủ công để phân tích sự cố và thực hiện các hành động tương ứng. Điều này là để tránh trường hợp ClusterControl, xử lý chuyển đổi dự phòng tự động, cố gắng thúc đẩy nô lệ tiếp theo và nô lệ tiếp theo. Có thể đã xảy ra sự cố và chúng tôi không muốn làm mọi thứ tồi tệ hơn bằng cách thử nhiều lần chuyển dự phòng.
ClusterControl đưa ra danh sách trắng và danh sách đen của một tập hợp các máy chủ mà bạn muốn tham gia vào quá trình chuyển đổi dự phòng hoặc loại trừ là ứng cử viên.
Đối với các cụm kiểu MySQL, ClusterControl xây dựng một danh sách các nô lệ có thể được thăng cấp thành chủ. Hầu hết thời gian, nó sẽ chứa tất cả các nô lệ trong cấu trúc liên kết nhưng người dùng có một số quyền kiểm soát bổ sung đối với nó. Có hai biến bạn có thể đặt trong cấu hình cmon:
replication_failover_whitelistvà
replication_failover_blacklistĐối với biến cấu hình replication_failover_whitelist, nó chứa danh sách IP hoặc tên máy chủ của các nô lệ sẽ được sử dụng làm ứng viên chính tiềm năng. Nếu biến này được đặt, chỉ những máy chủ đó mới được xem xét. Đối với biến replication_failover_blacklist, nó chứa danh sách các máy chủ sẽ không bao giờ được coi là ứng cử viên chính. Bạn có thể sử dụng nó để liệt kê các nô lệ được sử dụng để sao lưu hoặc truy vấn phân tích. Nếu phần cứng khác nhau giữa các nô lệ, bạn có thể muốn đặt ở đây các nô lệ sử dụng phần cứng chậm hơn.
replication_failover_whitelist được ưu tiên hơn, nghĩa là replication_failover_blacklist bị bỏ qua nếu replication_failover_whitelist được đặt.
Khi danh sách các nô lệ có thể được thăng cấp thành chủ đã sẵn sàng, ClusterControl bắt đầu so sánh trạng thái của chúng, tìm kiếm nô lệ cập nhật nhất. Ở đây, việc xử lý các thiết lập dựa trên MariaDB và MySQL khác nhau. Đối với thiết lập MariaDB, ClusterControl chọn một nô lệ có độ trễ sao chép thấp nhất trong tất cả các nô lệ hiện có. Đối với các thiết lập MySQL, ClusterControl cũng chọn một nô lệ như vậy nhưng sau đó nó sẽ kiểm tra các giao dịch bổ sung, bị thiếu có thể đã được thực hiện trên một số nô lệ còn lại. Nếu một giao dịch như vậy được tìm thấy, ClusterControl sẽ xóa ứng viên chính khỏi máy chủ đó để truy xuất tất cả các giao dịch bị thiếu. Bạn có thể bỏ qua quá trình này và chỉ sử dụng nô lệ nâng cao nhất bằng cách đặt biến replication_skip_apply_missing_txs trong cấu hình CMON của mình:
ví dụ:
replication_skip_apply_missing_txs=1Kiểm tra tài liệu của chúng tôi tại đây để biết thêm thông tin với các biến.
Lưu ý là bạn chỉ được đặt điều này nếu bạn biết mình đang làm gì, vì có thể có các giao dịch sai sót. Những điều này có thể khiến quá trình sao chép bị phá vỡ, cũng như dữ liệu không nhất quán trên toàn bộ cụm. Nếu giao dịch sai lầm đã xảy ra trong quá khứ, nó có thể không còn tồn tại trong nhật ký nhị phân. Trong trường hợp đó, quá trình sao chép sẽ bị hỏng vì các nô lệ sẽ không thể truy xuất dữ liệu bị thiếu. Do đó, ClusterControl, theo mặc định, kiểm tra bất kỳ giao dịch sai sót nào trước khi nó thúc đẩy một ứng cử viên chính trở thành bậc thầy. Nếu sự cố như vậy được phát hiện, công tắc chính sẽ bị hủy bỏ và ClusterControl cho phép người dùng khắc phục sự cố theo cách thủ công.
Nếu bạn muốn chắc chắn 100% rằng ClusterControl sẽ quảng bá một cái chính mới ngay cả khi một số vấn đề được phát hiện, bạn có thể làm điều đó bằng cách sử dụng biến replication_stop_on_error. Xem bên dưới:
ví dụ:
replication_stop_on_error=0Đặt biến này trong tệp cấu hình cmon của bạn. Như đã đề cập trước đó, nó có thể dẫn đến các vấn đề với sao chép vì các nô lệ có thể bắt đầu yêu cầu sự kiện nhật ký nhị phân không còn khả dụng nữa. Để xử lý những trường hợp như vậy, chúng tôi đã thêm hỗ trợ thử nghiệm cho việc xây dựng lại nô lệ. Nếu bạn đặt biến
replication_auto_rebuild_slave=1trong cấu hình cmon và nếu nô lệ của bạn bị đánh dấu là không hoạt động với lỗi sau trong MySQL:
Got fatal error 1236 from master when reading data from binary log: 'The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires.'ClusterControl sẽ cố gắng xây dựng lại nô lệ bằng cách sử dụng dữ liệu từ chính. Cài đặt như vậy có thể không phải lúc nào cũng phù hợp vì quá trình xây dựng lại sẽ tạo ra tải trọng tăng lên đối với bản chính. Cũng có thể do tập dữ liệu của bạn rất lớn và việc xây dựng lại thông thường không phải là một tùy chọn - đó là lý do tại sao hành vi này bị tắt theo mặc định.
Một khi chúng tôi đảm bảo rằng không có giao dịch sai sót nào tồn tại và chúng tôi có thể tiếp tục, vẫn còn một vấn đề nữa mà chúng tôi cần phải xử lý bằng cách nào đó - có thể xảy ra trường hợp tất cả nô lệ đều tụt hậu so với chủ.
Như bạn có thể biết, sao chép trong MySQL hoạt động theo một cách khá đơn giản. Các cửa hàng tổng thể ghi vào nhật ký nhị phân. Luồng I / O của nô lệ kết nối với chủ và kéo bất kỳ sự kiện nhật ký nhị phân nào mà nó bị thiếu. Sau đó, nó lưu trữ chúng dưới dạng nhật ký chuyển tiếp. Chuỗi SQL phân tích cú pháp chúng và áp dụng các sự kiện. Slave lag là một điều kiện trong đó luồng SQL (hoặc các luồng) không thể đối phó với số lượng sự kiện và không thể áp dụng chúng ngay khi chúng được luồng I / O kéo từ cái chính. Tình huống như vậy có thể xảy ra bất kể bạn đang sử dụng loại sao chép nào. Ngay cả khi bạn sử dụng sao chép bán đồng bộ, nó chỉ có thể đảm bảo rằng tất cả các sự kiện từ chính được lưu trữ trên một trong các nô lệ trong nhật ký chuyển tiếp. Nó không nói gì về việc áp dụng những sự kiện đó cho nô lệ.
Vấn đề ở đây là, nếu một nô lệ được thăng cấp thành chủ, các bản ghi chuyển tiếp sẽ bị xóa sổ. Nếu nô lệ bị trễ và chưa áp dụng tất cả các giao dịch, nó sẽ mất dữ liệu - các sự kiện chưa được áp dụng từ nhật ký chuyển tiếp sẽ bị mất vĩnh viễn.
Không có một cách phù hợp nào để giải quyết tình huống này. ClusterControl cung cấp cho người dùng quyền kiểm soát về cách nó phải được thực hiện, duy trì các mặc định an toàn. Nó được thực hiện trong cấu hình cmon bằng cách sử dụng cài đặt sau:
replication_failover_wait_to_apply_timeout=-1Theo mặc định, nó nhận giá trị là ‘-1’, có nghĩa là chuyển đổi dự phòng sẽ không xảy ra ngay lập tức nếu một ứng viên chính bị trễ, vì vậy nó được đặt để chờ mãi mãi trừ khi ứng viên đó đã bắt kịp. ClusterControl sẽ đợi vô thời hạn để nó áp dụng tất cả các giao dịch bị thiếu từ nhật ký chuyển tiếp của nó. Điều này là an toàn, nhưng, nếu vì lý do nào đó, nô lệ cập nhật nhất bị chậm một cách trầm trọng, quá trình chuyển đổi dự phòng có thể mất hàng giờ để hoàn thành. Ở phía bên kia của phổ đang đặt nó thành ‘0’ - có nghĩa là chuyển đổi dự phòng xảy ra ngay lập tức, bất kể ứng viên chính có bị tụt lại hay không. Bạn cũng có thể đi theo cách giữa và đặt nó thành một số giá trị. Điều này sẽ đặt thời gian tính bằng giây, ví dụ:30 giây, vì vậy hãy đặt biến thành,
replication_failover_wait_to_apply_timeout=30Khi được đặt thành> 0, ClusterControl sẽ đợi một ứng cử viên chính áp dụng các giao dịch bị thiếu từ nhật ký chuyển tiếp của nó cho đến khi giá trị được đáp ứng (trong ví dụ là 30 giây). Chuyển đổi dự phòng xảy ra sau thời gian xác định hoặc khi ứng viên chính sẽ bắt kịp việc nhân rộng, tùy điều kiện nào xảy ra trước. Đây có thể là một lựa chọn tốt nếu ứng dụng của bạn có các yêu cầu cụ thể về thời gian ngừng hoạt động và bạn phải chọn một chủ mới trong khoảng thời gian ngắn.
Để biết thêm chi tiết về cách ClusterControl hoạt động với chuyển đổi dự phòng tự động trong PostgreSQL và MySQL, hãy xem các blog trước đây của chúng tôi có tiêu đề "Chuyển đổi dự phòng cho PostgreSQL Replication 101" và "Chuyển đổi dự phòng tự động của MySQL Replication - Mới trong ClusterControl 1.4".
Kết luận
Chuyển đổi dự phòng tự động là một tính năng có giá trị, đặc biệt đối với các doanh nghiệp yêu cầu hoạt động 24/7 với thời gian ngừng hoạt động tối thiểu. Doanh nghiệp phải xác định mức độ kiểm soát được trao cho quá trình tự động hóa trong thời gian ngừng hoạt động ngoài kế hoạch. Một giải pháp có tính khả dụng cao như ClusterControl cung cấp mức độ tương tác có thể tùy chỉnh trong xử lý chuyển đổi dự phòng. Đối với một số tổ chức, chuyển đổi dự phòng tự động có thể không phải là một tùy chọn, mặc dù tương tác của người dùng trong quá trình chuyển đổi dự phòng có thể tiêu tốn thời gian và ảnh hưởng đến RTO. Giả định là quá rủi ro trong trường hợp chuyển đổi dự phòng tự động không hoạt động chính xác hoặc thậm chí tệ hơn, nó dẫn đến dữ liệu bị rối và thiếu một phần (mặc dù người ta có thể lập luận rằng con người cũng có thể mắc sai lầm tai hại dẫn đến hậu quả tương tự). Những người thích kiểm soát chặt chẽ cơ sở dữ liệu của họ có thể chọn bỏ qua chuyển đổi dự phòng tự động và thay vào đó sử dụng quy trình thủ công. Quá trình như vậy mất nhiều thời gian hơn, nhưng nó cho phép quản trị viên có kinh nghiệm đánh giá trạng thái của hệ thống và thực hiện các hành động khắc phục dựa trên những gì đã xảy ra.