Đây là bài viết đầu tiên trong loạt bài viết về OLTP trong bộ nhớ. Nó giúp bạn hiểu cách động cơ Hekaton mới hoạt động bên trong. Chúng tôi sẽ tập trung vào chi tiết của các bảng và chỉ mục được tối ưu hóa trong bộ nhớ. Đây là bài viết ở cấp độ đầu vào, có nghĩa là bạn không cần phải là một chuyên gia SQL Server, tuy nhiên, bạn cần phải có một số kiến thức cơ bản về công cụ SQL Server truyền thống.
Giới thiệu
Công cụ OLTP trong bộ nhớ SQL Server 2014 (dự án Hekaton) được tạo ra từ đầu để sử dụng hàng terabyte bộ nhớ có sẵn và số lượng lõi xử lý khổng lồ. OLTP trong bộ nhớ cho phép người dùng làm việc với các bảng và chỉ mục được tối ưu hóa bộ nhớ cũng như các thủ tục được lưu trữ được biên dịch nguyên bản. Bạn có thể sử dụng nó cùng với các bảng và chỉ mục dựa trên đĩa cũng như các thủ tục được lưu trữ T-SQL mà SQL Server luôn cung cấp.
Nội bộ và khả năng của công cụ OLTP trong bộ nhớ khác biệt đáng kể so với công cụ quan hệ tiêu chuẩn. Bạn cần sửa lại hầu hết mọi thứ bạn đã biết về cách xử lý nhiều quy trình đồng thời.
Công cụ SQL Server được tối ưu hóa để lưu trữ dựa trên đĩa. Nó đọc các trang dữ liệu 8KB vào bộ nhớ để xử lý và ghi các trang dữ liệu 8KB trở lại đĩa sau khi sửa đổi. Tất nhiên, SQL Server trước hết sẽ sửa các thay đổi đối với đĩa trong nhật ký giao dịch. Đọc các trang dữ liệu 8 KB từ đĩa và ghi lại, có thể tạo ra nhiều I / O và dẫn đến chi phí độ trễ cao hơn. Ngay cả khi dữ liệu trong bộ đệm ẩn bộ đệm, máy chủ SQL được thiết kế để giả định rằng không phải vậy, điều này dẫn đến việc sử dụng CPU không hiệu quả.
Xem xét những hạn chế của cấu trúc lưu trữ dựa trên đĩa truyền thống, nhóm SQL Server đã bắt đầu xây dựng một công cụ cơ sở dữ liệu được tối ưu hóa cho bộ nhớ chính lớn và CPU đa lõi. Nhóm đặt ra các mục tiêu sau:
- Được tối ưu hóa cho dữ liệu được lưu trữ hoàn toàn trong bộ nhớ nhưng cũng bền khi khởi động lại Máy chủ SQL
- Được tích hợp hoàn toàn vào công cụ SQL Server hiện có
- Hiệu suất rất cao cho các hoạt động OLTP
- Được thiết kế cho các CPU hiện đại
SQL Server In-Memory OLTP đáp ứng tất cả các mục tiêu này.
Giới thiệu về OLTP trong bộ nhớ
SQL Server 2014 In-Memory OLTP cung cấp một số công nghệ để làm việc với các bảng được tối ưu hóa bộ nhớ, cùng với các bảng dựa trên đĩa. Ví dụ, nó cho phép bạn truy cập dữ liệu trong bộ nhớ bằng cách sử dụng các giao diện tiêu chuẩn như T-SQL và SSMS. Hình minh họa sau minh họa các bảng và chỉ mục được tối ưu hóa bộ nhớ, như một phần của OLTP Trong Bộ nhớ (bên trái) và các bảng dựa trên đĩa (bên trái) yêu cầu đọc và ghi các trang dữ liệu 8KB. OLTP trong bộ nhớ cũng hỗ trợ các thủ tục được lưu trữ được biên dịch nguyên bản và cung cấp trình biên dịch OLTP trong bộ nhớ mới.
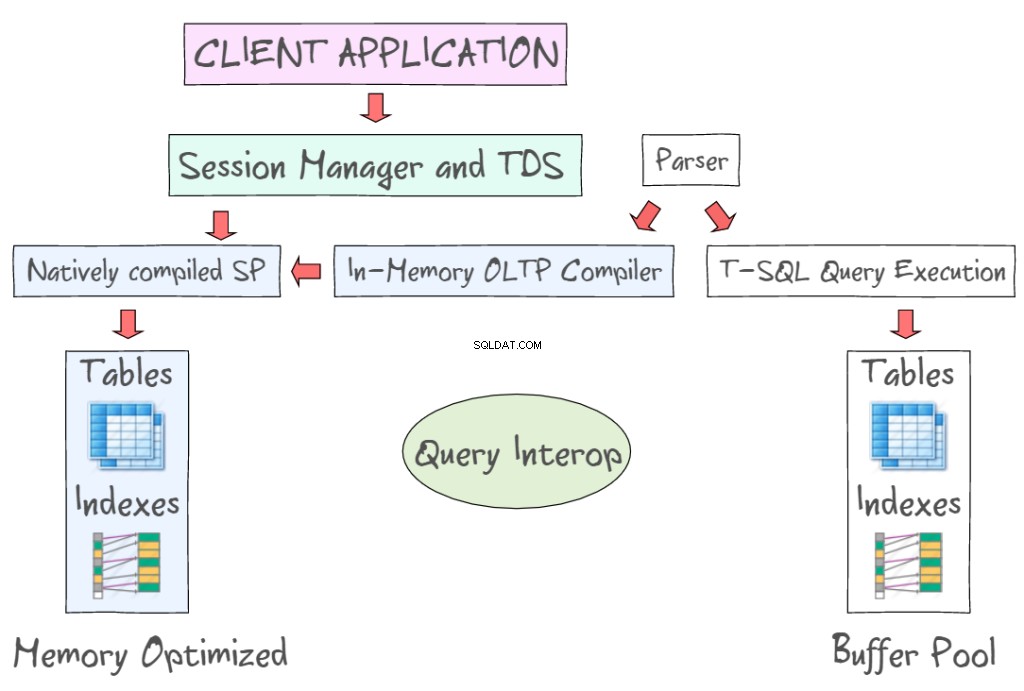
Truy vấn Interop cho phép thông dịch T-SQL để tham chiếu các bảng được tối ưu hóa bộ nhớ. Nếu một giao dịch tham chiếu đến cả bảng được tối ưu hóa bộ nhớ và bảng dựa trên đĩa, nó có thể được gọi là giao dịch chéo vùng chứa. Ứng dụng khách sử dụng Luồng dữ liệu dạng bảng - một giao thức lớp ứng dụng được sử dụng để truyền dữ liệu giữa máy chủ cơ sở dữ liệu và máy khách. Ban đầu, nó được thiết kế và phát triển bởi Sybase Inc. cho công cụ cơ sở dữ liệu quan hệ Sybase SQL Server của họ vào năm 1984, và sau đó là bởi Microsoft trong Microsoft SQL Server.
Bảng được tối ưu hóa bộ nhớ
Trong khi truy cập các bảng dựa trên đĩa, dữ liệu được yêu cầu có thể đã có trong bộ nhớ mặc dù có thể không. Nếu dữ liệu không có trong bộ nhớ, SQL Server cần đọc nó từ đĩa. Sự khác biệt cơ bản nhất khi sử dụng các bảng được tối ưu hóa bộ nhớ là toàn bộ bảng và các chỉ mục của nó luôn được lưu trữ trong bộ nhớ . Các hoạt động dữ liệu đồng thời không yêu cầu khóa hoặc chốt.
Trong khi người dùng sửa đổi dữ liệu trong bộ nhớ, SQL Server thực hiện một số I / O đĩa cho bất kỳ bảng nào cần bền, nói cách khác, nơi chúng ta cần một bảng để giữ lại dữ liệu trong bộ nhớ tại thời điểm máy chủ gặp sự cố hoặc khởi động lại.
Cấu trúc lưu trữ dựa trên hàng
Một sự khác biệt đáng kể khác là cấu trúc lưu trữ cơ bản. Các bảng dựa trên đĩa được tối ưu hóa cho block-addressable lưu trữ đĩa, trong khi các bảng được tối ưu hóa trong bộ nhớ được tối ưu hóa cho byte-addressable bộ nhớ lưu trữ.
SQL Server giữ các hàng dữ liệu trong các trang dữ liệu 8K, với sự phân bổ không gian từ các phần mở rộng cho các bảng dựa trên đĩa. Trang dữ liệu là đơn vị cơ bản của ổ đĩa và bộ nhớ lưu trữ. Trong khi đọc và ghi dữ liệu từ đĩa, SQL Server chỉ đọc và ghi các trang dữ liệu có liên quan. Một trang dữ liệu sẽ chỉ chứa dữ liệu từ một bảng hoặc chỉ mục. Các quy trình ứng dụng sửa đổi các hàng trên các trang dữ liệu khác nhau theo yêu cầu. Sau đó, trong hoạt động CHECKPOINT, SQL Server đầu tiên sẽ sửa các bản ghi nhật ký vào đĩa và sau đó ghi tất cả các trang bẩn vào đĩa. Thao tác này thường gây ra nhiều I / O vật lý ngẫu nhiên.
Đối với các bảng được tối ưu hóa bộ nhớ, không có trang dữ liệu cũng như không có phạm vi. Chỉ có các hàng dữ liệu được ghi tuần tự vào bộ nhớ, theo thứ tự các giao dịch xảy ra. Mỗi hàng chứa một con trỏ chỉ mục đến hàng tiếp theo. Tất cả I / O là quét trong bộ nhớ của các cấu trúc này. Không có khái niệm về các hàng dữ liệu được ghi vào một vị trí cụ thể thuộc về một đối tượng được chỉ định. Mặc dù, bạn không cần phải nghĩ rằng các bảng được tối ưu hóa bộ nhớ được lưu trữ dưới dạng tập hợp các hàng dữ liệu không được tổ chức (tương tự như heap dựa trên đĩa). Mỗi câu lệnh CREATE TABLE cho bảng được tối ưu hóa bộ nhớ tạo ít nhất một chỉ mục mà SQL Server sử dụng để liên kết tất cả các hàng dữ liệu trong bảng đó với nhau.
Mỗi hàng dữ liệu bao gồm tiêu đề hàng và trọng tải là dữ liệu cột thực tế. Tiêu đề lưu trữ thông tin về câu lệnh đã tạo hàng, con trỏ cho mỗi chỉ mục trên bảng đích và giá trị dấu thời gian. Dấu thời gian cho biết thời gian một giao dịch được chèn và xóa một hàng. Bản ghi SQL Server được cập nhật bằng cách chèn một phiên bản hàng mới và đánh dấu phiên bản cũ là đã bị xóa. Một số phiên bản của cùng một hàng có thể tồn tại bất kỳ lúc nào. Điều này cho phép truy cập đồng thời vào cùng một hàng trong quá trình sửa đổi dữ liệu. SQL Server hiển thị phiên bản hàng có liên quan đến từng giao dịch theo thời gian giao dịch bắt đầu liên quan đến dấu thời gian của phiên bản hàng. Đây là cốt lõi của điều khiển đồng thời nhiều phiên bản mới cơ chế cho các bảng trong bộ nhớ.
Nhân tiện, Oracle có một hệ thống điều khiển đa phiên bản tuyệt vời. Về cơ bản, nó hoạt động như sau:
- Người dùng A bắt đầu một giao dịch và cập nhật 1000 hàng với một số giá trị tại thời điểm T1.
- Người dùng B đọc 1000 hàng giống nhau tại thời điểm T2.
- Người dùng A cập nhật hàng 565 với giá trị Y (giá trị ban đầu là X).
- Người dùng B đến hàng 565 và nhận thấy rằng một giao dịch đang hoạt động kể từ Thời gian T1.
- Cơ sở dữ liệu trả về bản ghi chưa được sửa đổi từ các bản ghi. Giá trị trả về là giá trị được cam kết tại thời điểm nhỏ hơn hoặc bằng T2.
- Nếu không thể truy xuất bản ghi từ các bản ghi làm lại, điều đó có nghĩa là cơ sở dữ liệu không được thiết lập thích hợp. Cần phải phân bổ thêm dung lượng cho các nhật ký.
- Kết quả trả về luôn giống nhau đối với thời gian bắt đầu của giao dịch. Vì vậy, trong giao dịch, tính nhất quán của việc đọc sẽ đạt được.
Các bảng được biên dịch nguyên bản
Sự khác biệt chính cuối cùng là các bảng được tối ưu hóa trong bộ nhớ được biên dịch nguyên bản . Khi người dùng tạo bảng hoặc chỉ mục được tối ưu hóa bộ nhớ, SQL Server sẽ lưu trữ cấu trúc của mọi bảng (cùng với tất cả các chỉ mục) trong siêu dữ liệu. Sau đó, SQL Server sử dụng siêu dữ liệu đó để biên dịch thành DDL một tập hợp các quy trình ngôn ngữ mẹ đẻ để truy cập bảng. DDL như vậy được liên kết với cơ sở dữ liệu nhưng không thực sự là một phần của nó.
Nói cách khác, SQL Server lưu giữ trong bộ nhớ không chỉ các bảng và chỉ mục mà còn cả DDL để truy cập và sửa đổi các cấu trúc này. Sau khi một bảng đã được thay đổi, SQL Server cần tạo lại tất cả DDL cho các hoạt động của bảng. Đó là lý do tại sao bạn không thể thay đổi một bảng sau khi được tạo. Những hoạt động này là ẩn đối với người dùng.
Các thủ tục được lưu trữ được biên dịch nguyên bản
Hiệu suất tốt nhất đạt được khi sử dụng các thủ tục được lưu trữ được biên dịch nguyên bản để truy cập các bảng được biên dịch nguyên bản. Các thủ tục này chứa các lệnh của bộ xử lý và có thể được CPU thực thi trực tiếp mà không cần biên dịch thêm. Tuy nhiên, có một số hạn chế đối với cấu trúc T-SQL đối với các thủ tục được lưu trữ được biên dịch nguyên bản (so với mã được diễn giải theo cách truyền thống). Một điểm quan trọng khác là các thủ tục được lưu trữ được biên dịch tự nhiên chỉ có thể truy cập các bảng được tối ưu hóa bộ nhớ.
Không có khóa
OLTP trong bộ nhớ là một hệ thống không có khóa. Điều này có thể thực hiện được vì SQL Server không bao giờ sửa đổi bất kỳ hàng hiện có nào. Thao tác UPDATE tạo ra phiên bản mới và đánh dấu phiên bản trước đó là đã bị xóa, sau đó sẽ chèn một phiên bản hàng mới với dữ liệu mới vào bên trong.
Chỉ mục
Như bạn có thể đoán, lập chỉ mục rất khác so với các chỉ mục truyền thống. Các bảng được tối ưu hóa trong bộ nhớ không có trang nào. SQL Server sử dụng các chỉ mục để liên kết tất cả các hàng thuộc bảng thành một cấu trúc duy nhất. Chúng tôi không thể sử dụng câu lệnh CREATE INDEX để tạo chỉ mục cho bảng được tối ưu hóa trong bộ nhớ. Khi bạn đã tạo KHÓA CHÍNH trên một cột, SQL Server sẽ tự động tạo một chỉ mục duy nhất trên cột đó. Trên thực tế, nó là chỉ mục duy nhất được phép duy nhất. Bạn có thể tạo tối đa tám chỉ mục trên bảng được tối ưu hóa bộ nhớ.
Tương tự với các bảng, SQL Server giữ các chỉ mục được tối ưu hóa bộ nhớ trong bộ nhớ. Tuy nhiên, SQL Server không bao giờ ghi lại các hoạt động trên các chỉ mục. SQL Server duy trì các chỉ mục tự động trong quá trình sửa đổi bảng.
Các bảng được tối ưu hóa bộ nhớ hỗ trợ hai loại chỉ mục: chỉ mục băm và chỉ mục phạm vi . Cả hai đều là cấu trúc không phân cụm.
Chỉ mục băm là một loại chỉ mục mới, được thiết kế đặc biệt cho các bảng được tối ưu hóa bộ nhớ. Nó cực kỳ hữu ích để thực hiện tra cứu các giá trị cụ thể. Bản thân chỉ mục được lưu trữ dưới dạng bảng băm. Nó là một mảng các nhóm băm, trong đó mỗi nhóm là một con trỏ đến một hàng.
Chỉ mục phạm vi (không phân cụm) hữu ích để truy xuất các phạm vi giá trị.
Khôi phục
Cơ chế khôi phục cơ bản cho cơ sở dữ liệu có bảng được tối ưu hóa bộ nhớ cũng giống như cơ chế khôi phục của cơ sở dữ liệu có bảng dựa trên đĩa. Tuy nhiên, việc khôi phục các bảng được tối ưu hóa bộ nhớ bao gồm bước tải các bảng được tối ưu hóa bộ nhớ vào bộ nhớ trước khi cơ sở dữ liệu có sẵn để người dùng truy cập.
Khi SQL Server khởi động lại, mọi cơ sở dữ liệu đều trải qua các giai đoạn sau của quá trình khôi phục: phân tích , làm lại và hoàn tác .
Trong giai đoạn phân tích, công cụ OLTP trong bộ nhớ xác định khoảng không quảng cáo điểm kiểm tra để tải và tải trước các mục nhật ký bảng hệ thống của nó. Nó cũng sẽ xử lý một số bản ghi nhật ký cấp phát tệp.
Trong giai đoạn làm lại, dữ liệu từ các cặp tệp dữ liệu và tệp delta được tải vào bộ nhớ. Sau đó, dữ liệu được cập nhật từ nhật ký giao dịch đang hoạt động dựa trên điểm kiểm tra lâu bền cuối cùng và các bảng trong bộ nhớ được điền và xây dựng lại các chỉ mục. Trong giai đoạn này, khôi phục bảng dựa trên đĩa và bộ nhớ được tối ưu hóa chạy đồng thời.
Giai đoạn hoàn tác không cần thiết đối với các bảng được tối ưu hóa bộ nhớ vì OLTP trong bộ nhớ không ghi lại bất kỳ giao dịch nào chưa được cam kết cho các bảng được tối ưu hóa bộ nhớ.
Khi tất cả các thao tác hoàn tất, cơ sở dữ liệu có sẵn để truy cập.
Tóm tắt
Trong bài viết này, chúng tôi đã giới thiệu nhanh về công cụ SQL Server In-Memory OLTP. Chúng ta đã biết rằng các cấu trúc tối ưu hóa bộ nhớ được lưu trữ trong bộ nhớ. Các quy trình ứng dụng có thể tìm thấy dữ liệu cần thiết bằng cách truy cập các cấu trúc này trong bộ nhớ mà không cần I / O đĩa. Trong các bài viết tiếp theo, chúng ta sẽ xem xét cách tạo và truy cập cơ sở dữ liệu và bảng OLTP trong bộ nhớ.
Đọc thêm
OLTP trong bộ nhớ:Có gì mới trong SQL Server 2016
Sử dụng chỉ mục trong bảng được tối ưu hóa bộ nhớ máy chủ SQL



