Giới thiệu
Trong bài viết này, chúng ta sẽ thảo luận về các loại chỉ mục khác nhau trong các bảng được tối ưu hóa bộ nhớ SQL Server ảnh hưởng đến hiệu suất như thế nào. Chúng tôi sẽ xem xét các ví dụ về cách các loại chỉ mục khác nhau có thể ảnh hưởng đến hiệu suất của các bảng được tối ưu hóa bộ nhớ.
Để làm cho cuộc thảo luận chủ đề dễ dàng hơn, chúng tôi sẽ sử dụng một ví dụ khá lớn. Vì mục đích đơn giản, ví dụ này sẽ mô tả các bản sao khác nhau của một bảng duy nhất, dựa vào đó chúng tôi sẽ chạy các truy vấn khác nhau. Các bản sao này sẽ sử dụng các chỉ mục khác nhau hoặc hoàn toàn không có chỉ mục nào (tất nhiên là ngoại trừ khóa chính - PK).
Lưu ý rằng mục đích thực sự của bài viết này không phải để so sánh hiệu suất giữa các bảng dựa trên đĩa và được tối ưu hóa bộ nhớ trong SQL Server. Mục đích của nó là để kiểm tra xem các chỉ mục ảnh hưởng như thế nào đến hiệu suất trong các bảng được tối ưu hóa bộ nhớ. Tuy nhiên, để có bức tranh đầy đủ về các thử nghiệm, thời gian cũng được cung cấp cho các truy vấn bảng dựa trên đĩa tương ứng và tốc độ được tính bằng cách sử dụng cấu hình tối ưu nhất của bảng dựa trên đĩa làm đường cơ sở.
Tình huống
Dữ liệu mẫu cho kịch bản của chúng tôi dựa trên một bảng duy nhất được xác định như sau:
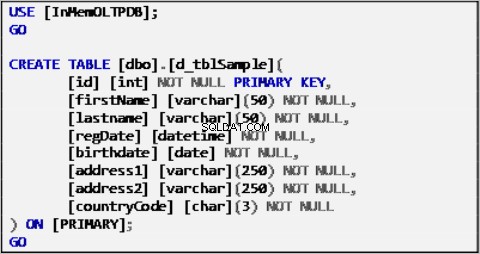
Liệt kê 1:Bảng nguồn dữ liệu mẫu.
Bảng ở trên đã được điền với dữ liệu mẫu và sẽ đóng vai trò là nguồn dữ liệu cho phần còn lại của các bảng.
Vì vậy, dựa trên bảng trên, chúng tôi tạo 9 biến thể bảng sau và điền chúng với cùng một dữ liệu mẫu:
- 3 bảng dựa trên đĩa:
- d_tblSample1
- Chỉ mục được phân nhóm trên cột "id" - khóa chính (PK)
- d_tblSample2
- Chỉ mục được phân nhóm trên cột "id" (PK)
- Chỉ mục không theo nhóm trên cột "Mã quốc gia"
- d_tblSample3
- Chỉ mục được phân nhóm trên cột "id" (PK)
- Các chỉ mục không phân cụm trên cột "regDate"
- Các chỉ mục không theo nhóm trên cột "Mã quốc gia"
- d_tblSample1
- 3 bảng được tối ưu hóa bộ nhớ (bộ 1:Chỉ mục băm):
- m1_tblSample1
- Chỉ mục băm không phân cụm trên cột "id" - khóa chính (PK)
- m1_tblSample2
- Chỉ mục băm không phân cụm trên cột "id" (PK)
- Chỉ mục băm trên cột "Mã quốc gia"
- m1_tblSample3
-
- Chỉ mục băm không phân cụm trên cột "id" (PK)
- Chỉ mục băm trên cột "regDate"
- Chỉ mục băm trên cột "Mã quốc gia"
-
- 3 bảng được tối ưu hóa bộ nhớ (bộ 2:Chỉ mục không được phân cụm):
- m2_tblSample1
- Chỉ mục không theo nhóm trên cột "id" - khóa chính (PK)
- m2_tblSample2
- Chỉ mục không theo nhóm trên cột "id" (PK)
- Chỉ mục không theo nhóm trên cột "Mã quốc gia"
- m2_tblSample3
- Chỉ mục không theo nhóm trên cột "id" (PK)
- Chỉ mục không theo nhóm trên cột "regDate"
- Chỉ mục không theo nhóm trên cột "Mã quốc gia"
- m2_tblSample1
- m1_tblSample1
Trong danh sách dưới đây, bạn có thể tìm thấy các định nghĩa cho các bảng trên.
Logic kịch bản là chúng tôi thực hiện các hoạt động cơ sở dữ liệu khác nhau dựa trên các biến thể của cùng một bảng (nhưng với các chỉ mục khác nhau) và quan sát hiệu suất bị ảnh hưởng như thế nào trong từng trường hợp.
Định nghĩa
Bảng dựa trên đĩa
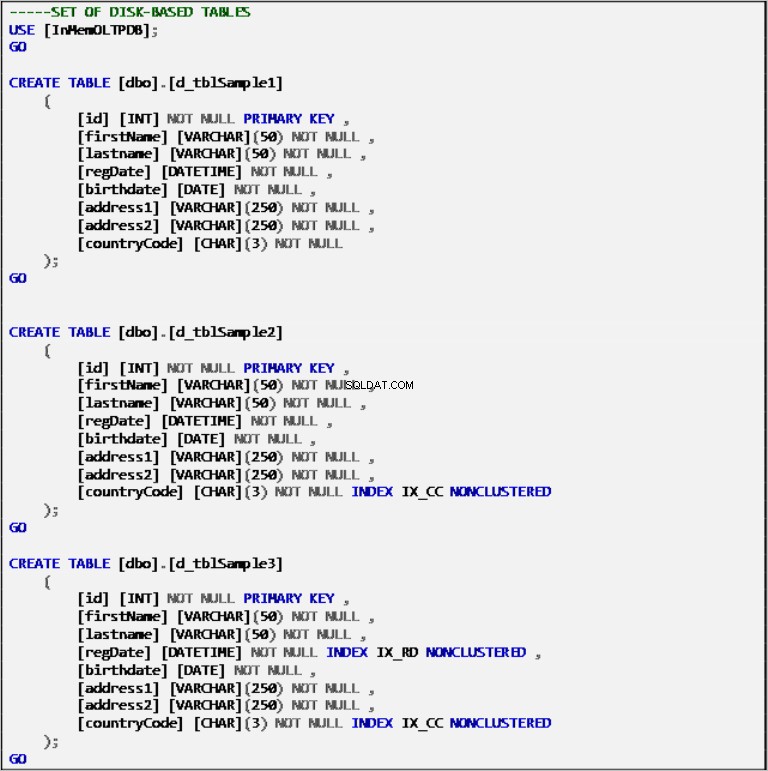
Liệt kê 2:Định nghĩa bảng dựa trên đĩa.
Bảng được tối ưu hóa bộ nhớ (Bộ 1:Chỉ mục băm)

Liệt kê 3:Bảng được tối ưu hóa bộ nhớ - Bộ 1 (Chỉ mục băm).
Bảng được tối ưu hóa bộ nhớ (Bộ 2:Chỉ mục không được phân cụm)

Liệt kê 4:Bảng được tối ưu hóa bộ nhớ - Bộ 2 (Chỉ mục không được phân cụm).
Sau đó, chúng tôi điền vào tất cả các bảng trên với cùng một dữ liệu mẫu, có tổng cộng 5 triệu bản ghi trong mỗi bảng.
Đây là kết quả đầu ra của lệnh count cho mỗi nhóm bảng:
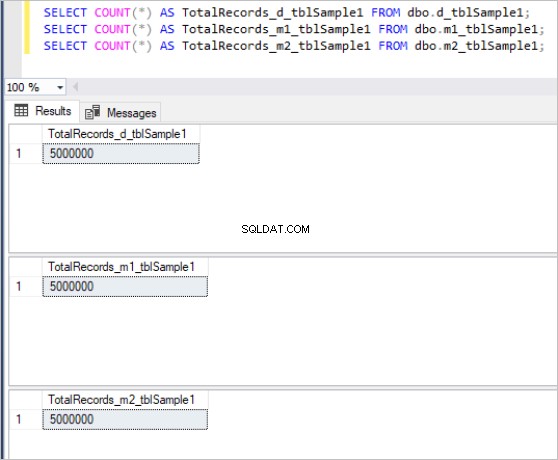
Hình 1:Tổng số bản ghi cho tập hợp bảng đầu tiên.
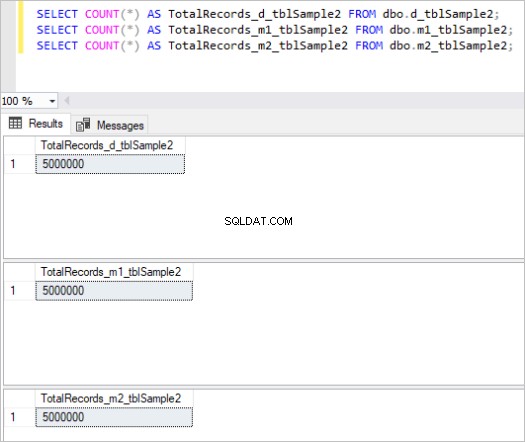
Hình 2:Tổng số bản ghi cho tập hợp bảng thứ hai.
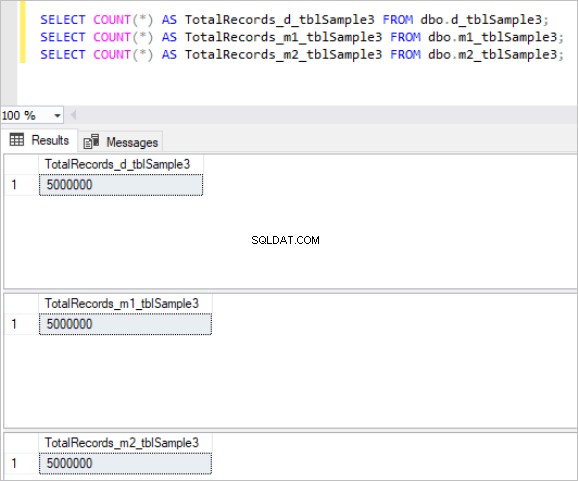
Hình 3:Tổng số bản ghi cho Bộ bảng thứ ba.
Truy vấn và Thực thi Kịch bản
Bây giờ, chúng ta sẽ chạy một tập hợp các truy vấn đối với các bảng trên và xem mỗi bảng hoạt động như thế nào.
Các truy vấn này thực hiện các hoạt động sau:
- Truy vấn 1:Tổng hợp (GROUP BY)
- Truy vấn 2:Tìm kiếm chỉ mục trên các vị từ bằng nhau
- Truy vấn 3:Chỉ mục tìm kiếm các vị từ bình đẳng và bất bình đẳng
Kế hoạch là thực hiện các truy vấn như sau:
Truy vấn 1 - Thực thi đối với các bảng sau:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (không có chỉ mục trên các cột mục tiêu)
- m2_tblSample1 (không có chỉ mục trên các cột mục tiêu)
Truy vấn 2 - Thực thi đối với các bảng sau:
- d_tblSample2
- m1_tblSample2
- m2_tblSample2
- m1_tblSample1 (không có chỉ mục trên các cột mục tiêu)
- m2_tblSample1 (không có chỉ mục trên các cột mục tiêu)
Truy vấn 3 - Thực thi đối với các bảng sau:
- d_tblSample3
- m1_tblSample3
- m2_tblSample3
- m1_tblSample1 (không có chỉ mục trên các cột mục tiêu)
- m2_tblSample1 (không có chỉ mục trên các cột mục tiêu)
Lưu ý :Mặc dù định nghĩa cho d_tblSample1 bảng dựa trên đĩa được bao gồm trong các định nghĩa bảng ở trên, nó không được sử dụng trong các truy vấn được cung cấp trong bài viết này. Lý do là, trong mỗi trường hợp, cấu hình tối ưu nhất có thể cho bảng dựa trên đĩa được sử dụng, vì chúng tôi muốn đường cơ sở của mình nhanh nhất có thể khi chúng tôi so sánh với hiệu suất của các bảng được tối ưu hóa bộ nhớ. Để đạt được mục tiêu này, d_tblSample1 bảng chỉ được trình bày cho mục đích thông tin.
Dưới đây, bạn có thể tìm thấy các tập lệnh T-SQL cho ba truy vấn cùng với các cơ chế đo thời gian thực thi.

Liệt kê 5:Truy vấn 1 - Tổng hợp (có chỉ mục).
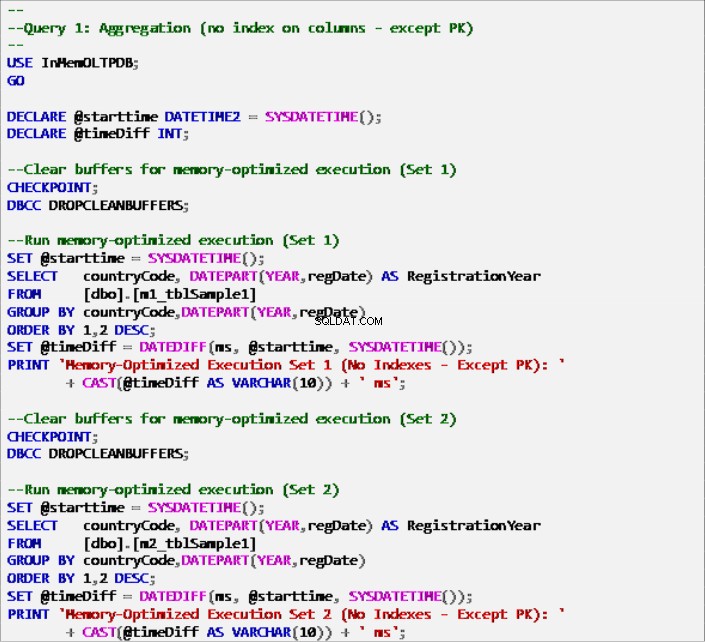
Liệt kê 6:Truy vấn 1 - Tổng hợp (không có chỉ mục - Ngoại trừ Khóa chính).
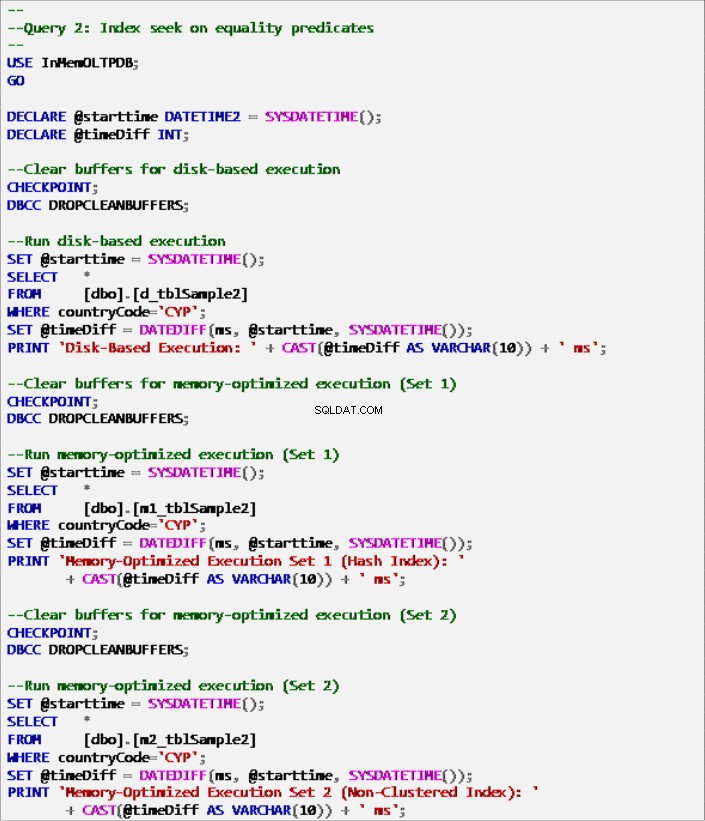
Liệt kê 7:Truy vấn 2 - Tìm kiếm chỉ mục về các dự đoán bình đẳng (có chỉ mục).

Liệt kê 8:Truy vấn 2 - Tìm kiếm chỉ mục về các dự đoán ngang bằng (không có chỉ mục - ngoại trừ Khóa chính).
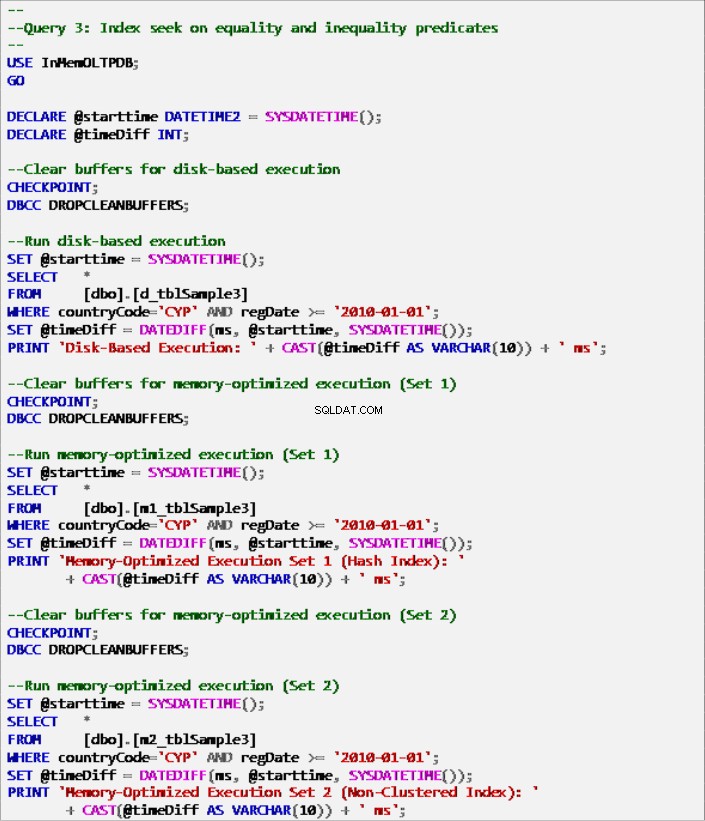
Liệt kê 9:Truy vấn 3 - Tìm kiếm chỉ mục về các dự đoán bình đẳng và bất bình đẳng (có chỉ mục).

Liệt kê 10:Truy vấn 3 - Tìm kiếm chỉ mục về các dự đoán bình đẳng và bất bình đẳng (không có chỉ mục - Ngoại trừ khóa chính).
Ảnh chụp màn hình bên dưới hiển thị kết quả của mỗi lần thực thi truy vấn:
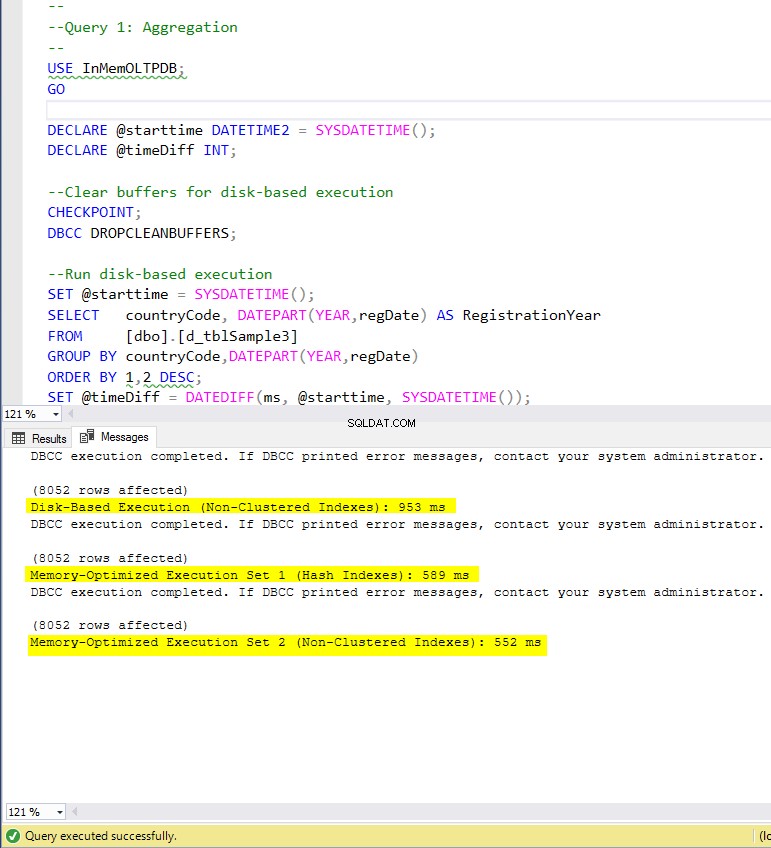
Hình 4:Thời gian thực thi truy vấn 1 (có chỉ mục).
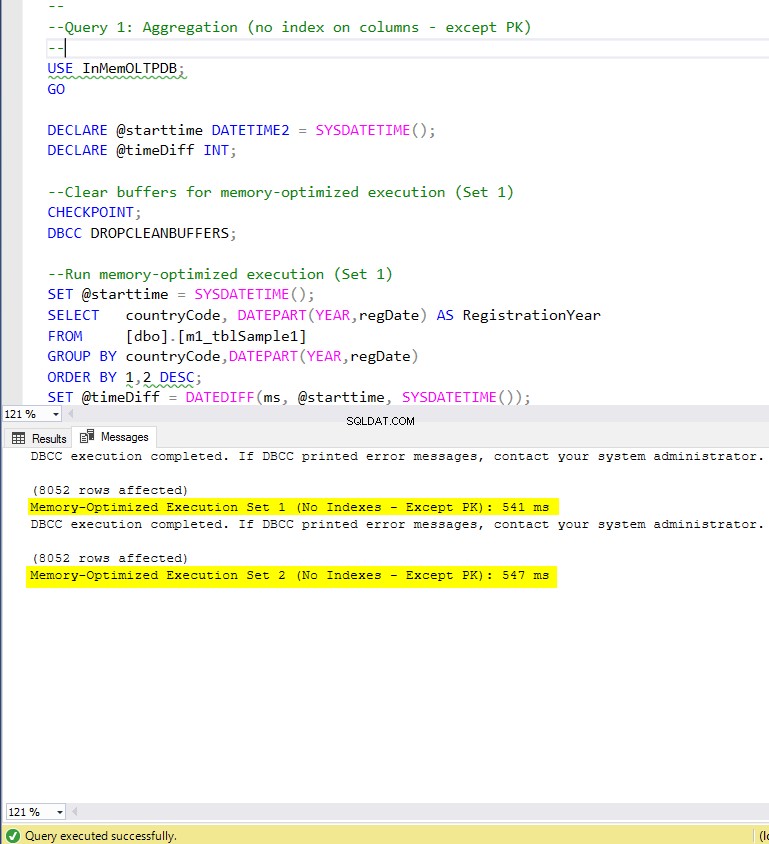
Hình 5:Thời gian thực thi truy vấn 1 (không có chỉ mục - ngoại trừ PK).
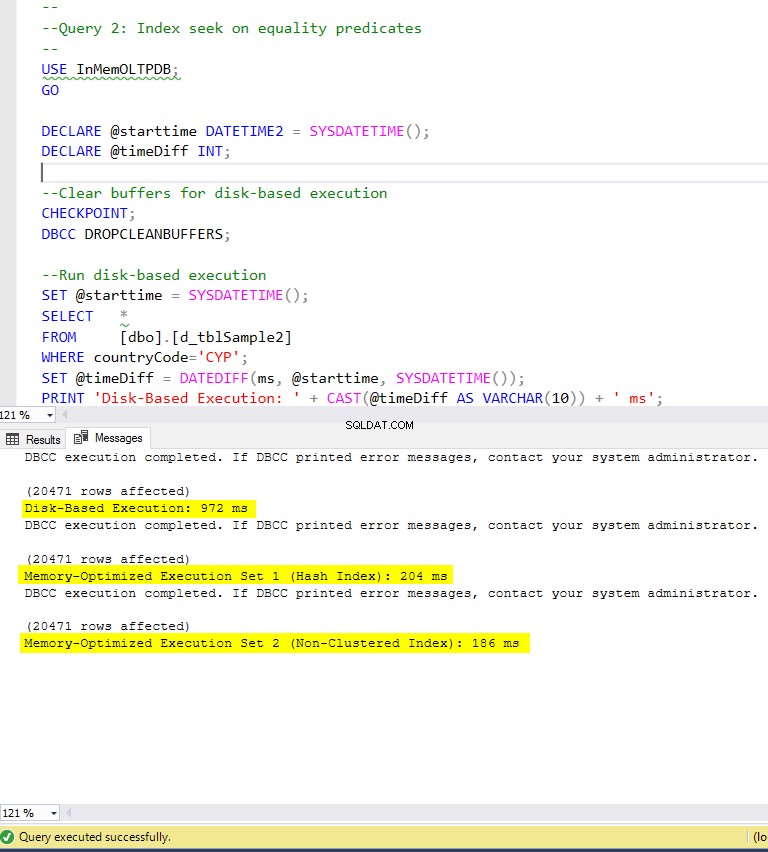
Hình 6:Thời gian thực thi truy vấn 2 (có chỉ mục).
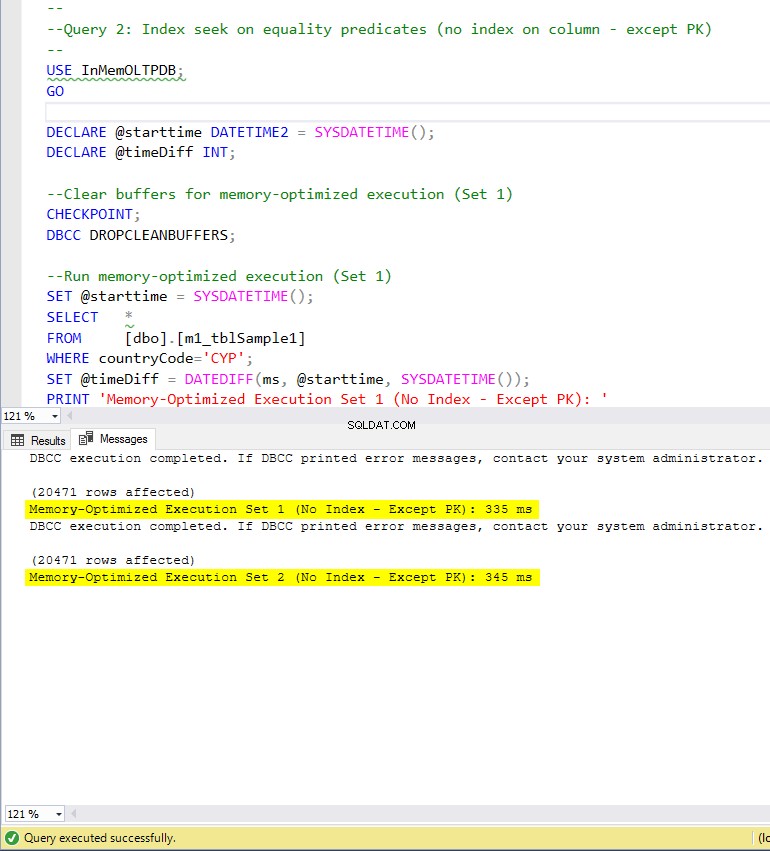
Hình 7:Thời gian thực thi truy vấn 2 (không có chỉ mục - ngoại trừ PK).
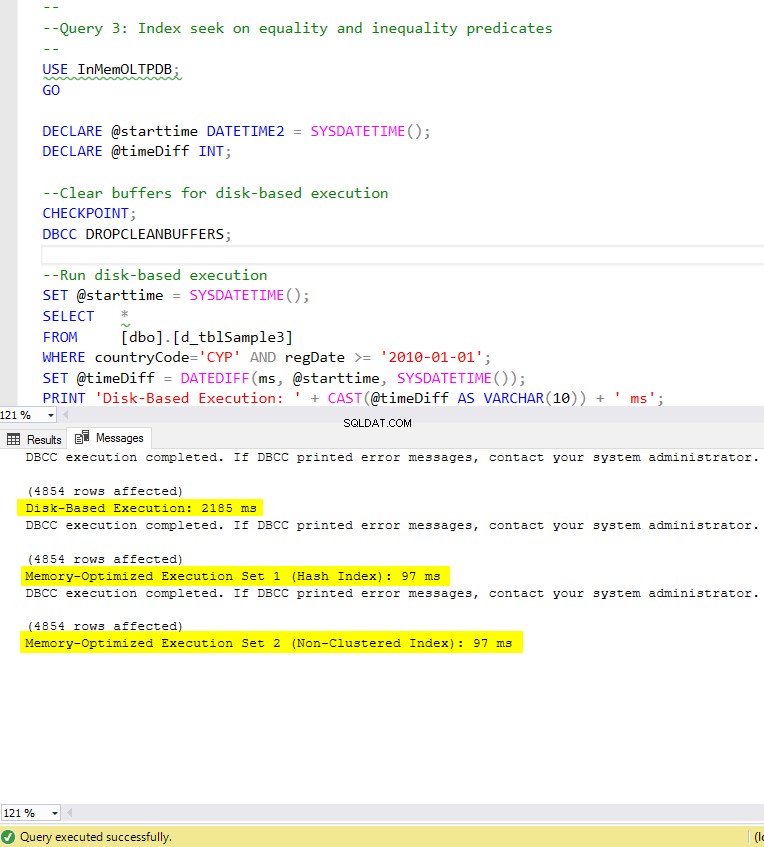
Hình 8:Thời gian thực thi truy vấn 3 (có chỉ mục).
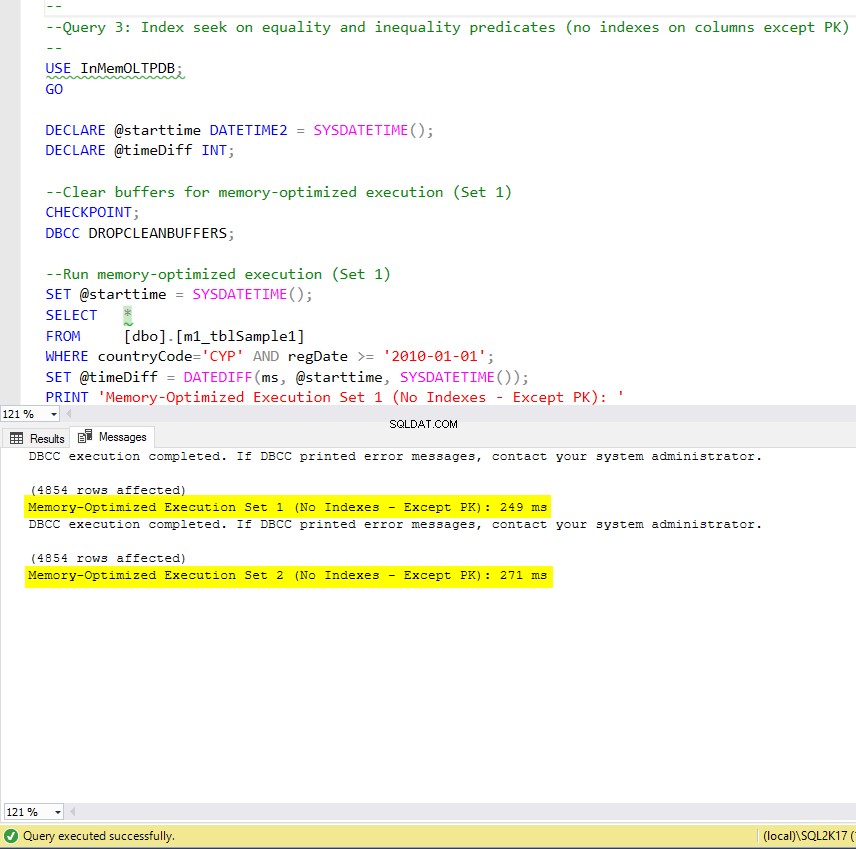
Hình 9:Thời gian thực thi truy vấn 3 (không có chỉ mục - ngoại trừ PK).
Bây giờ, hãy tóm tắt các kết quả thu được ở trên. Bảng sau đây hiển thị thời gian thực thi được đo cho tất cả các truy vấn và kết hợp bảng / chỉ mục ở trên.
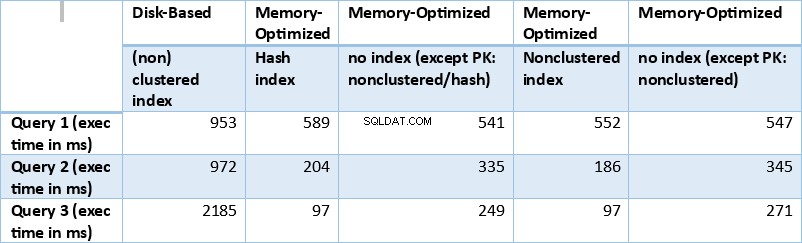
Bảng 1:Tóm tắt Thời gian Thực thi (mili giây) cho tất cả các Truy vấn.
Thảo luận
Nếu chúng ta xem xét các kết quả thực hiện được tóm tắt trong bảng trên, chúng ta có thể đi đến kết luận nhất định. Hãy vẽ từng kết quả truy vấn thành một biểu đồ. Các biểu đồ bên dưới minh họa thời gian thực thi, cũng như tốc độ tăng tốc của các bảng được tối ưu hóa bộ nhớ so với các bảng dựa trên đĩa.
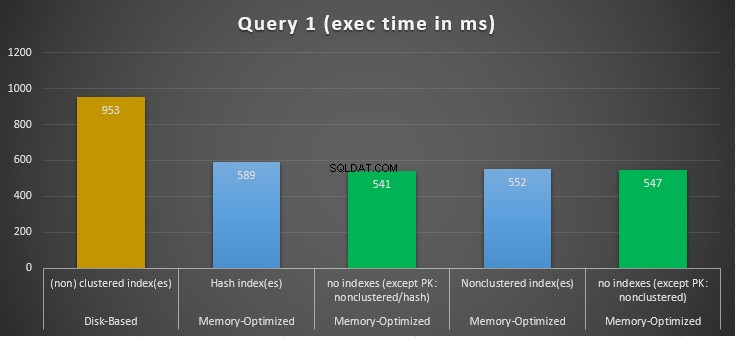
Hình 10:So sánh thời gian thực thi truy vấn 1.
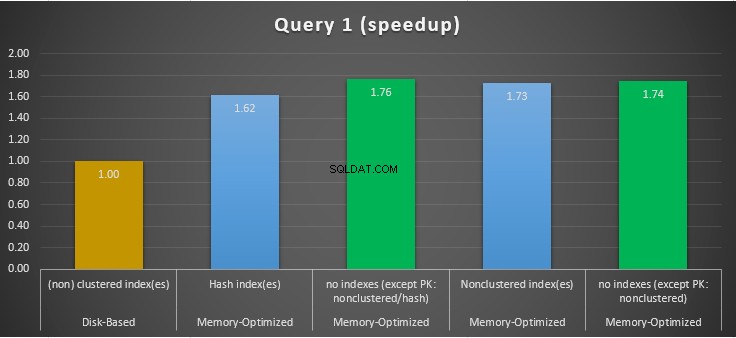
Hình 11:So sánh tốc độ truy vấn 1.
Về Truy vấn 1, là một tập hợp GROUP BY, chúng ta có thể thấy rằng cả hai phiên bản (có chỉ mục so với không có chỉ mục) của các bảng được tối ưu hóa bộ nhớ, hoạt động gần như giống nhau khi có tốc độ tăng tốc trên bảng dựa trên đĩa (được kích hoạt với chỉ mục) giữa 1,62 và nhanh hơn 1,76 lần.
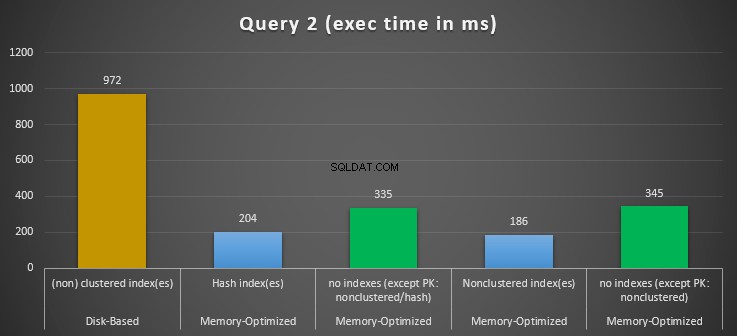
Hình 12:So sánh thời gian thực thi truy vấn 2.
Hình 13:So sánh tốc độ truy vấn 2.
Về Truy vấn 2, liên quan đến tìm kiếm chỉ mục trên các vị từ bình đẳng, chúng ta có thể thấy rằng các bảng được tối ưu hóa bộ nhớ có chỉ mục hoạt động tốt hơn nhiều so với các bảng được tối ưu hóa bộ nhớ không có chỉ mục. Hơn nữa, chúng tôi nhận thấy rằng bảng được tối ưu hóa bộ nhớ với chỉ mục không phân cụm trong cột được sử dụng làm vị từ hoạt động tốt hơn bảng có chỉ mục băm.
Vì vậy, đối với truy vấn 2, bảng chiến thắng là bảng được tối ưu hóa bộ nhớ với chỉ mục không phân cụm, có tốc độ tổng thể là 5,23 nhanh hơn nhiều lần so với thực thi dựa trên đĩa.
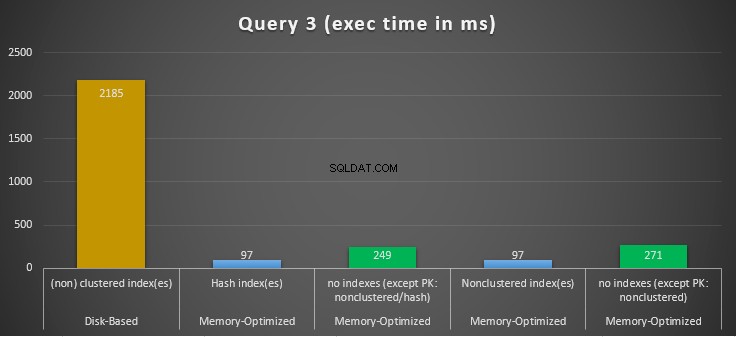
Hình 14:So sánh thời gian thực thi truy vấn 3.
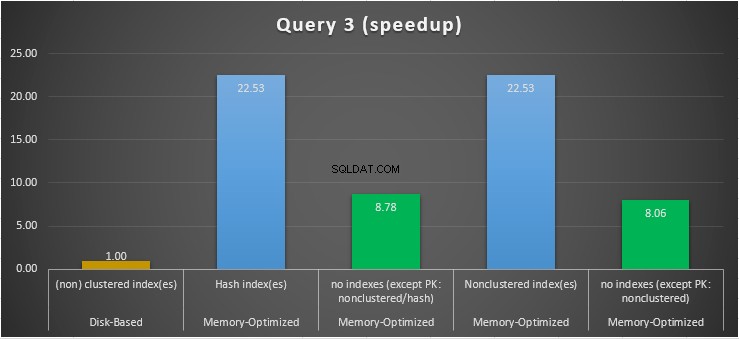
Hình 15:So sánh tốc độ truy vấn 3.
Về Truy vấn 3, liên quan đến tìm kiếm chỉ mục trên các vị từ bình đẳng và bất bình đẳng được kết hợp, chúng ta có thể thấy rằng các bảng được tối ưu hóa bộ nhớ có chỉ mục, hoạt động tốt hơn so với các bảng được tối ưu hóa bộ nhớ không có chỉ mục. Hơn nữa, chúng tôi nhận thấy rằng bảng được tối ưu hóa bộ nhớ với chỉ mục không phân cụm trong cột được sử dụng làm vị từ được thực hiện giống như bảng có chỉ mục băm.
Cuối cùng, chúng ta có thể thấy rằng cả hai bảng được tối ưu hóa bộ nhớ sử dụng chỉ mục trong các cột được sử dụng làm vị từ, hoạt động nhanh hơn so với bảng không có chỉ mục và đạt được tốc độ nhanh hơn 22,53 lần qua thực thi dựa trên đĩa.
Kết luận
Trong bài viết này, chúng tôi đã xem xét việc sử dụng các chỉ mục trong các bảng được tối ưu hóa bộ nhớ trong SQL Server. Chúng tôi đã sử dụng làm đường cơ sở cho mỗi truy vấn, cấu hình bảng dựa trên đĩa tốt nhất có thể và sau đó chúng tôi so sánh hiệu suất của ba truy vấn với các bảng dựa trên đĩa và 4 biến thể của bảng được tối ưu hóa bộ nhớ. Hai trong số bốn bảng được tối ưu hóa bộ nhớ đã sử dụng chỉ mục (băm / không phân cụm) và hai bảng còn lại không sử dụng chỉ mục, ngoại trừ những bảng được sử dụng cho khóa chính.
Kết luận chung là bạn luôn cần kiểm tra xem các chỉ mục ảnh hưởng như thế nào đến hiệu suất, không chỉ đối với các bảng được tối ưu hóa bộ nhớ mà còn đối với các bảng dựa trên đĩa và bất cứ khi nào bạn xác định rằng chúng cải thiện hiệu suất, hãy sử dụng chúng. Các phát hiện về ví dụ của bài viết này cho thấy rằng nếu bạn sử dụng các chỉ mục thích hợp trong các bảng được tối ưu hóa bộ nhớ, bạn có thể đạt được hiệu suất tốt hơn nhiều cho các truy vấn tương tự như các truy vấn được sử dụng trong bài viết này khi so sánh với việc chỉ sử dụng các bảng được tối ưu hóa bộ nhớ mà không có chỉ mục .
Tài liệu tham khảo và Đọc thêm:
- Microsoft Documents:Bảng Tối ưu hoá Bộ nhớ
- Microsoft Docs:Nguyên tắc sử dụng chỉ mục trên bảng được tối ưu hóa bộ nhớ
- Microsoft Docs:Lập chỉ mục trên các bảng được tối ưu hóa bộ nhớ
Công cụ hữu ích:
dbForge Index Manager - phần bổ trợ SSMS tiện dụng để phân tích trạng thái của chỉ mục SQL và khắc phục sự cố với phân mảnh chỉ mục.