Giới thiệu
Hướng dẫn này bao gồm thông tin về SQL (DDL, DML) mà tôi đã thu thập được trong suốt cuộc đời làm việc của mình. Đây là điều tối thiểu bạn cần biết khi làm việc với cơ sở dữ liệu. Nếu có nhu cầu sử dụng các cấu trúc SQL phức tạp, thì thường tôi lướt thư viện MSDN, có thể dễ dàng tìm thấy trên internet. Theo suy nghĩ của tôi, rất khó để ghi nhớ mọi thứ trong đầu và nhân tiện, không cần thiết phải làm như vậy. Tôi khuyên bạn nên biết tất cả các cấu trúc chính được sử dụng trong hầu hết các cơ sở dữ liệu quan hệ như Oracle, MySQL và Firebird. Tuy nhiên, chúng có thể khác nhau về kiểu dữ liệu. Ví dụ:để tạo các đối tượng (bảng, ràng buộc, chỉ mục, v.v.), bạn có thể chỉ cần sử dụng môi trường phát triển tích hợp (IDE) để làm việc với cơ sở dữ liệu và không cần nghiên cứu các công cụ trực quan cho một loại cơ sở dữ liệu cụ thể (MS SQL, Oracle , MySQL, Firebird, v.v.). Điều này rất tiện lợi vì bạn có thể xem toàn bộ văn bản và bạn không cần phải xem qua nhiều tab để tạo, ví dụ, một chỉ mục hoặc một ràng buộc. Nếu bạn thường xuyên làm việc với cơ sở dữ liệu, việc tạo, sửa đổi và đặc biệt là xây dựng lại một đối tượng bằng cách sử dụng script nhanh hơn nhiều so với ở chế độ trực quan. Bên cạnh đó, theo tôi, ở chế độ script (với độ chính xác cao), việc xác định và kiểm soát các quy tắc đặt tên đối tượng sẽ dễ dàng hơn. Ngoài ra, rất tiện lợi khi sử dụng tập lệnh khi bạn cần chuyển các thay đổi cơ sở dữ liệu từ cơ sở dữ liệu thử nghiệm sang cơ sở dữ liệu sản xuất.
SQL được chia thành nhiều phần. Trong bài viết của tôi, tôi sẽ xem xét những điều quan trọng nhất:
DDL - Ngôn ngữ Định nghĩa Dữ liệu
DML - Ngôn ngữ thao tác dữ liệu, bao gồm các cấu trúc sau:
- SELECT - lựa chọn dữ liệu
- CHÈN - chèn dữ liệu mới
- CẬP NHẬT - cập nhật dữ liệu
- DELETE - xóa dữ liệu
- MERGE - hợp nhất dữ liệu
Tôi sẽ giải thích tất cả các cấu tạo trong các trường hợp nghiên cứu. Ngoài ra, tôi nghĩ rằng một ngôn ngữ lập trình, đặc biệt là SQL, nên được nghiên cứu trong thực tế để hiểu rõ hơn.
Đây là hướng dẫn từng bước, nơi bạn cần thực hiện các ví dụ trong khi đọc nó. Tuy nhiên, nếu bạn cần biết lệnh chi tiết, hãy lướt Internet, chẳng hạn như MSDN.
Khi tạo hướng dẫn này, tôi đã sử dụng cơ sở dữ liệu MS SQL Server, phiên bản 2014 và MS SQL Server Management Studio (SSMS) để thực thi các tập lệnh.
Tóm tắt về MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) là tiện ích Microsoft SQL Server để định cấu hình, quản lý và quản trị các thành phần cơ sở dữ liệu. Nó bao gồm một trình soạn thảo tập lệnh và một chương trình đồ họa hoạt động với các đối tượng và cài đặt máy chủ. Công cụ chính của SQL Server Management Studio là Object Explorer, cho phép người dùng xem, truy xuất và quản lý các đối tượng máy chủ. Văn bản này được lấy một phần từ Wikipedia.
Để tạo một trình chỉnh sửa tập lệnh mới, hãy sử dụng nút Truy vấn Mới:
Để chuyển từ cơ sở dữ liệu hiện tại, bạn có thể sử dụng trình đơn thả xuống:
Để thực hiện một lệnh cụ thể hoặc một tập hợp lệnh, hãy đánh dấu nó và nhấn nút Execute hoặc F5. Nếu chỉ có một lệnh trong trình chỉnh sửa hoặc bạn cần thực hiện tất cả các lệnh, thì không đánh dấu bất kỳ điều gì.
Sau khi bạn đã thực thi các tập lệnh tạo đối tượng (bảng, cột, chỉ mục), hãy chọn đối tượng tương ứng (ví dụ:Bảng hoặc Cột) rồi nhấp vào Làm mới trên menu lối tắt để xem các thay đổi.
Trên thực tế, đây là tất cả những gì bạn cần biết để thực hiện các ví dụ được cung cấp ở đây.
Lý thuyết
Cơ sở dữ liệu quan hệ là một tập hợp các bảng được liên kết với nhau. Nói chung, cơ sở dữ liệu là một tệp lưu trữ dữ liệu có cấu trúc.
Hệ thống quản lý cơ sở dữ liệu (DBMS) là một bộ công cụ để làm việc với các loại cơ sở dữ liệu cụ thể (MS SQL, Oracle, MySQL, Firebird, v.v.).
Lưu ý: Như trong cuộc sống hàng ngày của chúng ta, chúng ta nói “Oracle DB” hoặc chỉ “Oracle” thực sự có nghĩa là “Oracle DBMS”, thì trong hướng dẫn này, tôi sẽ sử dụng thuật ngữ “cơ sở dữ liệu”.
Bảng là một tập hợp các cột. Thông thường, bạn có thể nghe thấy các định nghĩa sau về các thuật ngữ này:trường, hàng và bản ghi, có nghĩa là giống nhau.
Một bảng là đối tượng chính của cơ sở dữ liệu quan hệ. Tất cả dữ liệu được lưu trữ từng hàng trong các cột của bảng.
Đối với mỗi bảng cũng như các cột của nó, bạn cần chỉ định một tên, theo đó bạn có thể tìm thấy một mục bắt buộc.
Tên của đối tượng, bảng, cột và chỉ mục có thể có độ dài tối thiểu - 128 ký hiệu.
Lưu ý: Trong cơ sở dữ liệu Oracle, tên đối tượng có thể có độ dài tối thiểu - 30 ký hiệu. Do đó, trong một cơ sở dữ liệu cụ thể, cần phải tạo các quy tắc tùy chỉnh cho tên đối tượng.
SQL là một ngôn ngữ cho phép thực thi các truy vấn trong cơ sở dữ liệu thông qua DBMS. Trong một DBMS cụ thể, một ngôn ngữ SQL có thể có phương ngữ riêng của nó.
DDL và DML - ngôn ngữ con SQL:
- Ngôn ngữ DDL dùng để tạo và sửa đổi cấu trúc cơ sở dữ liệu (xóa bảng và liên kết);
- Ngôn ngữ DML cho phép thao tác dữ liệu bảng, các hàng của nó. Nó cũng dùng để chọn dữ liệu từ các bảng, thêm dữ liệu mới cũng như cập nhật và xóa dữ liệu hiện tại.
Có thể sử dụng hai loại chú thích trong SQL (một dòng và phân cách):
-- single-line comment
và
/* delimited comment */
Đó là tất cả về lý thuyết.
DDL - Ngôn ngữ Định nghĩa Dữ liệu
Hãy xem xét một bảng mẫu với dữ liệu về nhân viên được trình bày theo cách quen thuộc với một người không phải là lập trình viên.
| ID nhân viên | Tên đầy đủ | Ngày sinh | Vị trí | Bộ phận | |
| 1000 | John | 19.02.1955 | example@sqldat.com | Giám đốc điều hành | Quản trị |
| 1001 | Daniel | 03.12.1983 | example@sqldat.com | lập trình viên | CNTT |
| 1002 | Mike | 07.06.1976 | example@sqldat.com | Kế toán | Nợ tài khoản |
| 1003 | Jordan | 17.04.1982 | example@sqldat.com | Lập trình viên cao cấp | CNTT |
Trong trường hợp này, các cột có các tiêu đề sau:ID nhân viên, Họ tên, Ngày sinh, E-mail, Chức vụ và Phòng ban.
Chúng tôi có thể mô tả từng cột của bảng này theo kiểu dữ liệu của nó:
- ID nhân viên - số nguyên
- Họ và Tên - chuỗi
- Ngày sinh - ngày
- E-mail - chuỗi
- Vị trí - chuỗi
- Bộ phận - chuỗi
Loại cột là thuộc tính chỉ định loại dữ liệu mà mỗi cột có thể lưu trữ.
Để bắt đầu, bạn cần nhớ các kiểu dữ liệu chính được sử dụng trong MS SQL:
| Định nghĩa | Chỉ định trong MS SQL | Mô tả |
| Chuỗi có độ dài thay đổi | varchar (N) và nvarchar (N) | Sử dụng số N, chúng ta có thể chỉ định độ dài chuỗi lớn nhất có thể cho một cột cụ thể. Ví dụ:nếu chúng ta muốn nói rằng giá trị của cột Họ và Tên có thể chứa tối đa 30 ký hiệu (nhiều nhất), thì cần phải chỉ định loại nvarchar (30).
Sự khác biệt giữa varchar từ nvarchar là varchar cho phép lưu trữ các chuỗi ở định dạng ASCII, trong khi nvarchar lưu trữ các chuỗi ở định dạng Unicode, trong đó mỗi ký hiệu chiếm 2 byte. |
| Chuỗi có độ dài cố định | char (N) và nchar (N) | Kiểu này khác với chuỗi có độ dài thay đổi ở điểm sau:nếu độ dài chuỗi nhỏ hơn N ký hiệu, thì khoảng trắng luôn được thêm vào độ dài N ở bên phải. Do đó, trong cơ sở dữ liệu, cần chính xác N ký hiệu, trong đó một ký hiệu chiếm 1 byte cho char và 2 byte cho nchar. Trong thực tế của tôi, loại này không được sử dụng nhiều. Tuy nhiên, nếu ai đó sử dụng nó, thì loại này thường có định dạng char (1), tức là khi một trường được xác định bằng 1 ký hiệu. |
| Số nguyên | int | Kiểu này cho phép chúng ta chỉ sử dụng số nguyên (cả dương và âm) trong một cột. Lưu ý:một dải số cho loại này như sau:từ 2 147 483 648 đến 2 147 483 647. Thông thường, nó là loại chính được sử dụng để вуашту định danh. |
| Số dấu phẩy động | float | Các số có dấu thập phân. |
| Ngày | ngày | Nó chỉ được sử dụng để lưu trữ một ngày (ngày, tháng và năm) trong một cột. Ví dụ:15/02/2014. Loại này có thể được sử dụng cho các cột sau:ngày nhận, ngày sinh, v.v., khi bạn chỉ cần chỉ định một ngày hoặc khi thời gian không quan trọng đối với chúng tôi và chúng tôi có thể loại bỏ nó. |
| Thời gian | thời gian | Bạn có thể sử dụng loại này nếu cần lưu trữ thời gian:giờ, phút, giây và mili giây. Ví dụ:bạn có 17:38:31.3231603 hoặc bạn cần thêm thời gian khởi hành của chuyến bay. |
| Ngày và giờ | datetime | Loại này cho phép người dùng lưu trữ cả ngày và giờ. Ví dụ:bạn có sự kiện vào ngày 15/02/2014 17:38:31.323. |
| Chỉ báo | bit | Bạn có thể sử dụng loại này để lưu trữ các giá trị như "Có" / "Không", trong đó "Có" là 1 và "Không" là 0. |
Ngoài ra, không cần thiết phải chỉ định giá trị trường, trừ khi nó bị cấm. Trong trường hợp này, bạn có thể sử dụng NULL.
Để thực thi các ví dụ, chúng tôi sẽ tạo một cơ sở dữ liệu thử nghiệm có tên là ‘Thử nghiệm’.
Để tạo một cơ sở dữ liệu đơn giản mà không có bất kỳ thuộc tính bổ sung nào, hãy chạy lệnh sau:
CREATE DATABASE Test
Để xóa cơ sở dữ liệu, hãy thực hiện lệnh này:
DROP DATABASE Test
Để chuyển sang cơ sở dữ liệu của chúng tôi, hãy sử dụng lệnh:
USE Test
Ngoài ra, bạn có thể chọn Cơ sở dữ liệu thử nghiệm từ trình đơn thả xuống trong khu vực trình đơn SSMS.
Bây giờ, chúng ta có thể tạo một bảng trong cơ sở dữ liệu của mình bằng cách sử dụng mô tả, dấu cách và ký hiệu Cyrillic:
CREATE TABLE [Employees]( [EmployeeID] int, [FullName] nvarchar(30), [Birthdate] date, [E-mail] nvarchar(30), [Position] nvarchar(30), [Department] nvarchar(30) )
Trong trường hợp này, chúng ta cần đặt tên trong dấu ngoặc vuông […].
Tuy nhiên, tốt hơn là chỉ định tất cả các tên đối tượng bằng tiếng Latinh và không sử dụng dấu cách trong tên. Trong trường hợp này, mọi từ đều bắt đầu bằng một chữ cái viết hoa. Ví dụ:đối với trường “EmployeeID”, chúng tôi có thể chỉ định tên PersonnelNumber. Bạn cũng có thể sử dụng các số trong tên, ví dụ:PhoneNumber1.
Lưu ý: Trong một số DBMS, việc sử dụng định dạng tên sau «PHONE_NUMBER» sẽ thuận tiện hơn. Ví dụ:bạn có thể thấy định dạng này trong cơ sở dữ liệu ORACLE. Ngoài ra, tên trường không được trùng với các từ khóa được sử dụng trong DBMS.
Vì lý do này, bạn có thể quên cú pháp dấu ngoặc vuông và có thể xóa bảng Nhân viên:
DROP TABLE [Employees]
Ví dụ:bạn có thể đặt tên bảng có nhân viên là “Nhân viên” và đặt các tên sau cho các trường của bảng:
- ID
- Tên
- Ngày sinh
- Vị trí
- Bộ phận
Rất thường xuyên, chúng tôi sử dụng 'ID' cho trường số nhận dạng.
Bây giờ, hãy tạo một bảng:
CREATE TABLE Employees( ID int, Name nvarchar(30), Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Để đặt các cột bắt buộc, bạn có thể sử dụng tùy chọn NOT NULL.
Đối với bảng hiện tại, bạn có thể xác định lại các trường bằng các lệnh sau:
-- ID field update ALTER TABLE Employees ALTER COLUMN ID int NOT NULL -- Name field update ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NOT NULL
Lưu ý: Khái niệm chung về ngôn ngữ SQL đối với hầu hết các DBMS là giống nhau (theo kinh nghiệm của riêng tôi). Sự khác biệt giữa các DDL trong các DBMS khác nhau chủ yếu là ở các kiểu dữ liệu (chúng có thể khác nhau không chỉ bởi tên mà còn bởi cách triển khai cụ thể của chúng). Ngoài ra, cách triển khai SQL cụ thể (các lệnh) đều giống nhau, nhưng có thể có một chút khác biệt về phương ngữ. Biết cơ bản về SQL, bạn có thể dễ dàng chuyển từ DBMS này sang DBMS khác. Trong trường hợp này, bạn sẽ chỉ cần hiểu các chi tiết cụ thể của việc triển khai các lệnh trong DBMS mới.
So sánh các lệnh giống nhau trong ORACLE DBMS:
-- create table CREATE TABLE Employees( ID int, -- In ORACLE the int type is a value for number(38) Name nvarchar2(30), -- in ORACLE nvarchar2 is identical to nvarchar in MS SQL Birthday date, Email nvarchar2(30), Position nvarchar2(30), Department nvarchar2(30) ); -- ID and Name field update (here we use MODIFY(…) instead of ALTER COLUMN ALTER TABLE Employees MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- add PK (in this case the construction is the same as in the MS SQL) ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);
ORACLE khác ở chỗ triển khai kiểu varchar2. Định dạng của nó phụ thuộc vào cài đặt DB và bạn có thể lưu một văn bản, ví dụ, trong UTF-8. Ngoài ra, bạn có thể chỉ định độ dài trường theo byte và ký hiệu. Để thực hiện việc này, bạn cần sử dụng các giá trị BYTE và CHAR theo sau là trường độ dài. Ví dụ:
NAME varchar2(30 BYTE) – field capacity equals 30 bytes NAME varchar2(30 CHAR) -- field capacity equals 30 symbols
Giá trị (BYTE hoặc CHAR) được sử dụng theo mặc định khi bạn chỉ chỉ ra varchar2 (30) trong ORACLE sẽ phụ thuộc vào cài đặt DB. Thông thường, bạn có thể dễ bị nhầm lẫn. Vì vậy, tôi khuyên bạn nên chỉ định rõ ràng CHAR khi bạn sử dụng kiểu varchar2 (ví dụ:với UTF-8) trong ORACLE (vì sẽ thuận tiện hơn khi đọc độ dài chuỗi trong ký hiệu).
Tuy nhiên, trong trường hợp này, nếu có bất kỳ dữ liệu nào trong bảng, thì để thực hiện thành công lệnh, cần phải điền vào các trường ID và Tên trong tất cả các hàng của bảng.
Tôi sẽ chỉ ra nó trong một ví dụ cụ thể.
Hãy chèn dữ liệu vào các trường ID, Chức vụ và Phòng ban bằng cách sử dụng tập lệnh sau:
INSERT Employees(ID,Position,Department) VALUES (1000,’CEO,N'Administration'), (1001,N'Programmer',N'IT'), (1002,N'Accountant',N'Accounts dept'), (1003,N'Senior Programmer',N'IT')
Trong trường hợp này, lệnh INSERT cũng trả về một lỗi. Điều này xảy ra vì chúng tôi chưa chỉ định giá trị cho Tên trường bắt buộc.
Nếu có một số dữ liệu trong bảng ban đầu, thì lệnh “ALTER TABLE Nhân viên ALTER COLUMN ID int NOT NULL” sẽ hoạt động, trong khi lệnh “ALTER TABLE Nhân viên ALTER COLUMN Name int NOT NULL” sẽ trả về lỗi mà trường Tên mắc phải Giá trị NULL.
Hãy thêm các giá trị vào trường Tên:
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel'), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior Programmer',N'IT',N'Jordan’)
Ngoài ra, bạn có thể sử dụng NOT NULL khi tạo bảng mới bằng câu lệnh CREATE TABLE.
Đầu tiên, hãy xóa một bảng:
DROP TABLE Employees
Bây giờ, chúng ta sẽ tạo một bảng với các trường bắt buộc ID và Tên:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Ngoài ra, bạn có thể chỉ định NULL sau tên cột ngụ ý rằng giá trị NULL được phép. Điều này không bắt buộc vì tùy chọn này được đặt theo mặc định.
Nếu bạn cần đặt cột hiện tại không bắt buộc, hãy sử dụng cú pháp sau:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NULL
Ngoài ra, bạn có thể sử dụng lệnh này:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30)
Ngoài ra, với lệnh này, chúng ta có thể sửa đổi loại trường thành một loại tương thích khác hoặc thay đổi độ dài của nó. Ví dụ:hãy mở rộng trường Tên thành 50 ký hiệu:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(50)
Khóa chính
Khi tạo bảng, bạn cần chỉ định một cột hoặc một tập hợp các cột duy nhất cho mỗi hàng. Sử dụng giá trị duy nhất này, bạn có thể xác định một bản ghi. Giá trị này được gọi là khóa chính. Cột ID (chứa «số cá nhân của nhân viên» - trong trường hợp của chúng tôi, đây là giá trị duy nhất cho mỗi nhân viên và không thể trùng lặp) có thể là khóa chính cho bảng Nhân viên của chúng tôi.
Bạn có thể sử dụng lệnh sau để tạo khóa chính cho bảng:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
‘PK_Eprisees’ là tên ràng buộc xác định khóa chính. Thông thường, tên của khóa chính bao gồm tiền tố ‘PK_’ và tên bảng.
Nếu khóa chính chứa một số trường, thì bạn cần liệt kê các trường này trong dấu ngoặc vuông được phân tách bằng dấu phẩy:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY(field1,field2,…)
Hãy nhớ rằng trong MS SQL, tất cả các trường của khóa chính KHÔNG được NULL.
Bên cạnh đó, bạn có thể xác định khóa chính khi tạo bảng. Hãy xóa bảng:
DROP TABLE Employees
Sau đó, tạo một bảng bằng cú pháp sau:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), CONSTRAINT PK_Employees PRIMARY KEY(ID) – describe PK after all the fileds as a constraint )
Thêm dữ liệu vào bảng:
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel'), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior programmer',N'IT',N'Jordan')
Trên thực tế, bạn không cần phải chỉ định tên ràng buộc. Trong trường hợp này, một tên hệ thống sẽ được chỉ định. Ví dụ:«PK__Eprisee__3214EC278DA42077»:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), PRIMARY KEY(ID) )
hoặc
CREATE TABLE Employees( ID int NOT NULL PRIMARY KEY, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Cá nhân tôi khuyên bạn nên chỉ định rõ ràng tên ràng buộc cho các bảng vĩnh viễn, vì sẽ dễ dàng hơn khi làm việc với hoặc xóa một giá trị được xác định rõ ràng và rõ ràng trong tương lai. Ví dụ:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
Tuy nhiên, sẽ thoải mái hơn khi áp dụng cú pháp ngắn này, không có tên ràng buộc khi tạo bảng cơ sở dữ liệu tạm thời (tên của bảng tạm thời bắt đầu bằng # hoặc ##.
Tóm tắt:
Chúng tôi đã phân tích các lệnh sau:
- TẠO BẢNG tên_bảng (danh sách các trường và kiểu của chúng, cũng như các ràng buộc) - phục vụ cho việc tạo một bảng mới trong cơ sở dữ liệu hiện tại;
- BẢNG HIỆU QUẢ tên_bảng - phục vụ cho việc xoá một bảng khỏi cơ sở dữ liệu hiện tại;
- BẢNG ALTER table_name ALTER COLUMN column_name… - phục vụ cho việc cập nhật loại cột hoặc sửa đổi cài đặt của nó (ví dụ:khi bạn cần đặt NULL hoặc NOT NULL);
- BẢNG ALTER table_name ADD CONSTRAINT binding_name KHÓA CHÍNH (field1, field2,…) - được sử dụng để thêm khóa chính vào bảng hiện tại;
- BẢNG ALTER table_name DROP CONSTRAINT tên_kèm_làm - được sử dụng để xoá một ràng buộc khỏi bảng.
Bảng tạm thời
Tóm tắt từ MSDN. Có hai loại bảng tạm thời trong MS SQL Server:cục bộ (#) và toàn cục (##). Các bảng tạm thời cục bộ chỉ hiển thị với người tạo của chúng trước khi phiên bản SQL Server bị ngắt kết nối. Chúng tự động bị xóa sau khi người dùng bị ngắt kết nối khỏi phiên bản SQL Server. Các bảng tạm thời chung được hiển thị cho tất cả người dùng trong bất kỳ phiên kết nối nào sau khi tạo các bảng này. Các bảng này sẽ bị xóa sau khi người dùng bị ngắt kết nối khỏi phiên bản của SQL Server.
Các bảng tạm thời được tạo trong cơ sở dữ liệu hệ thống tempdb, có nghĩa là chúng ta không làm ngập cơ sở dữ liệu chính. Ngoài ra, bạn có thể xóa chúng bằng lệnh DROP TABLE. Rất thường xuyên, các bảng tạm thời cục bộ (#) được sử dụng.
Để tạo một bảng tạm thời, bạn có thể sử dụng lệnh CREATE TABLE:
CREATE TABLE #Temp( ID int, Name nvarchar(30) )
Bạn có thể xóa bảng tạm thời bằng lệnh DROP TABLE:
DROP TABLE #Temp
Ngoài ra, bạn có thể tạo một bảng tạm thời và điền dữ liệu vào nó bằng cú pháp SELECT… INTO:
SELECT ID,Name INTO #Temp FROM Employees
Lưu ý: Trong các DBMS khác nhau, việc triển khai cơ sở dữ liệu tạm thời có thể khác nhau. Ví dụ:trong ORACLE và Firebird DBMS, cấu trúc của các bảng tạm thời phải được xác định trước bằng lệnh CREATE GLOBAL TEMPORARY TABLE. Ngoài ra, bạn cần chỉ định cách lưu trữ dữ liệu. Sau đó, người dùng nhìn thấy nó trong số các bảng thông thường và làm việc với nó như với một bảng thông thường.
Chuẩn hóa cơ sở dữ liệu:chia thành các bảng con (bảng tham chiếu) và xác định mối quan hệ bảng
Bảng Nhân viên hiện tại của chúng tôi có một nhược điểm:người dùng có thể nhập bất kỳ văn bản nào vào các trường Chức vụ và Phòng ban, điều này có thể trả về lỗi, đối với một nhân viên, anh ta có thể chỉ định “CNTT” là một bộ phận, trong khi đối với một nhân viên khác, anh ta có thể chỉ định “CNTT Phòng ban". Kết quả là người dùng sẽ không hiểu rõ ý của người dùng là những nhân viên này có làm việc cho cùng một bộ phận hay có lỗi chính tả hay không và có 2 bộ phận khác nhau. Hơn nữa, trong trường hợp này, chúng tôi sẽ không thể nhóm dữ liệu một cách chính xác cho một báo cáo, nơi chúng tôi cần hiển thị số lượng nhân viên cho từng bộ phận.
Một nhược điểm khác là dung lượng lưu trữ và sự trùng lặp của nó, tức là bạn cần chỉ định tên đầy đủ của bộ phận cho mỗi nhân viên, điều này cần có không gian trong cơ sở dữ liệu để lưu trữ từng ký hiệu của tên bộ phận.
Nhược điểm thứ ba là sự phức tạp của việc cập nhật dữ liệu trường khi bạn cần sửa đổi tên của bất kỳ vị trí nào - từ lập trình viên đến lập trình viên cấp dưới. Trong trường hợp này, bạn sẽ cần thêm dữ liệu mới vào mỗi hàng trong bảng có Vị trí là "Người lập trình".
Để tránh những trường hợp như vậy, bạn nên sử dụng chuẩn hóa cơ sở dữ liệu - chia thành các bảng phụ - bảng tham chiếu.
Hãy tạo 2 bảng tham chiếu “Vị trí” và “Phòng ban”:
CREATE TABLE Positions( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY, Name nvarchar(30) NOT NULL ) CREATE TABLE Departments( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY, Name nvarchar(30) NOT NULL )
Lưu ý rằng ở đây chúng tôi đã sử dụng thuộc tính IDENTITY mới. Có nghĩa là dữ liệu trong cột ID sẽ được tự động liệt kê bắt đầu bằng 1. Do đó, khi thêm các bản ghi mới, các giá trị 1, 2, 3, v.v. sẽ được gán tuần tự. Thông thường, những trường này được gọi là trường tự động tăng. Chỉ một trường có thuộc tính IDENTITY có thể được xác định làm khóa chính trong bảng. Thông thường, nhưng không phải luôn luôn, trường như vậy là khóa chính của bảng.
Lưu ý: Trong các DBMS khác nhau, việc triển khai các trường với bộ tăng có thể khác nhau. Trong MySQL, ví dụ, một trường như vậy được xác định bởi thuộc tính AUTO_INCREMENT. Trong ORACLE và Firebird, bạn có thể mô phỏng chức năng này theo trình tự (SEQUENCE). Nhưng theo những gì tôi biết, thuộc tính GENERATED AS IDENTITY đã được thêm vào ORACLE.
Hãy tự động điền vào các bảng này dựa trên dữ liệu hiện tại trong các trường Chức vụ và Phòng ban của bảng Nhân viên:
-- fill in the Name field of the Positions table with unique values from the Position field of the Employees table INSERT Positions(Name) SELECT DISTINCT Position FROM Employees WHERE Position IS NOT NULL – drop records where a position is not specified
Bạn cần thực hiện các bước tương tự đối với bảng Phòng ban:
INSERT Departments(Name) SELECT DISTINCT Department FROM Employees WHERE Department IS NOT NULL
Bây giờ, nếu chúng ta mở bảng Vị trí và Phòng ban, thì chúng ta sẽ thấy danh sách các giá trị được đánh số trong trường ID:
SELECT * FROM Positions
| ID | Tên |
| 1 | Kế toán |
| 2 | Giám đốc điều hành |
| 3 | Lập trình viên |
| 4 | Lập trình viên cao cấp |
SELECT * FROM Departments
| ID | Tên |
| 1 | Quản trị |
| 2 | Nợ tài khoản |
| 3 | CNTT |
Các bảng này sẽ là bảng tham chiếu để xác định các chức vụ và phòng ban. Bây giờ, chúng ta sẽ đề cập đến các định danh của các chức vụ và phòng ban. Đầu tiên, hãy tạo các trường mới trong bảng Nhân viên để lưu trữ các số nhận dạng:
-- add a field for the ID position ALTER TABLE Employees ADD PositionID int -- add a field for the ID department ALTER TABLE Employees ADD DepartmentID int
Loại trường tham chiếu phải giống như trong bảng tham chiếu, trong trường hợp này, nó là int.
Ngoài ra, bạn có thể thêm nhiều trường bằng một lệnh bằng cách liệt kê các trường được phân tách bằng dấu phẩy:
ALTER TABLE Employees ADD PositionID int, DepartmentID int
Bây giờ, chúng tôi sẽ thêm các ràng buộc tham chiếu (NGOẠI KHÓA) vào các trường này, để người dùng không thể thêm bất kỳ giá trị nào không phải là giá trị ID của bảng tham chiếu.
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID)
Các bước tương tự phải được thực hiện cho trường thứ hai:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
Bây giờ, người dùng chỉ có thể chèn vào các trường này các giá trị ID từ bảng tham chiếu tương ứng. Do đó, để sử dụng một phòng ban hoặc chức vụ mới, người dùng phải thêm một bản ghi mới trong bảng tham chiếu tương ứng. Vì các vị trí và phòng ban được lưu trữ trong các bảng tham chiếu trong một bản sao, nên để thay đổi tên của chúng, bạn chỉ cần thay đổi tên đó trong bảng tham chiếu.
Tên của một ràng buộc tham chiếu thường là tên ghép. Nó bao gồm tiền tố «FK» theo sau là tên bảng và tên trường tham chiếu đến mã định danh bảng tham chiếu.
Giá trị nhận dạng (ID) thường là giá trị nội bộ chỉ được sử dụng cho các liên kết. Nó có giá trị gì không quan trọng. Do đó, đừng cố gắng loại bỏ khoảng trống trong chuỗi giá trị xuất hiện khi bạn làm việc với bảng, chẳng hạn như khi bạn xóa bản ghi khỏi bảng tham chiếu.
Trong một số trường hợp, có thể tạo tham chiếu từ một số trường:
ALTER TABLE table ADD CONSTRAINT constraint_name FOREIGN KEY(field1,field2,…) REFERENCES reference table(field1,field2,…)
Trong trường hợp này, khóa chính được biểu thị bằng một tập hợp nhiều trường (field1, field2,…) trong bảng “reference_table”.
Bây giờ, hãy cập nhật các trường PositionID và DepartmentID bằng các giá trị ID từ các bảng tham chiếu.
Để làm điều này, chúng tôi sẽ sử dụng lệnh UPDATE:
UPDATE e SET PositionID=(SELECT ID FROM Positions WHERE Name=e.Position), DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department) FROM Employees e
Chạy truy vấn sau:
SELECT * FROM Employees
| ID | Tên | Ngày sinh | Vị trí | Bộ phận | ID vị trí | DepartmentID | |
| 1000 | John | NULL | NULL | Giám đốc điều hành | Quản trị | 2 | 1 |
| 1001 | Daniel | NULL | NULL | Lập trình viên | CNTT | 3 | 3 |
| 1002 | Mike | NULL | NULL | Kế toán | Nợ tài khoản | 1 | 2 |
| 1003 | Jordan | NULL | NULL | Lập trình viên cao cấp | CNTT | 4 | 3 |
Như bạn có thể thấy, các trường PositionID và DepartmentID khớp với các vị trí và phòng ban. Do đó, bạn có thể xóa các trường Chức vụ và Phòng ban trong bảng Nhân viên bằng cách thực hiện lệnh sau:
ALTER TABLE Employees DROP COLUMN Position,Department
Bây giờ, hãy chạy câu lệnh này:
SELECT * FROM Employees
| ID | Tên | Ngày sinh | ID vị trí | DepartmentID | |
| 1000 | John | NULL | NULL | 2 | 1 |
| 1001 | Daniel | NULL | NULL | 3 | 3 |
| 1002 | Mike | NULL | NULL | 1 | 2 |
| 1003 | Jordan | NULL | NULL | 4 | 3 |
Therefore, we do not have information overload. We can define the names of positions and departments by their identifiers using the values in the reference tables:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON d.ID=e.DepartmentID LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
| 1000 | John | CEO | Administration |
| 1001 | Daniel | Programmer | IT |
| 1002 | Mike | Accountant | Accounts dept |
| 1003 | Jordan | Senior programmer | IT |
In the object inspector, we can see all the objects created for this table. Here we can also manipulate these objects in different ways, for example, rename or delete the objects.
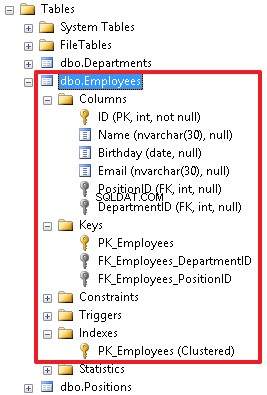
In addition, it should be noted that it is possible to create a recursive reference.
Let’s consider this particular example.
Let’s add the ManagerID field to the table with employees. This new field will define an employee to whom this employee is subordinated.
ALTER TABLE Employees ADD ManagerID int
This field permits the NULL value as well.
Now, we will create a FOREIGN KEY for the Employees table:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
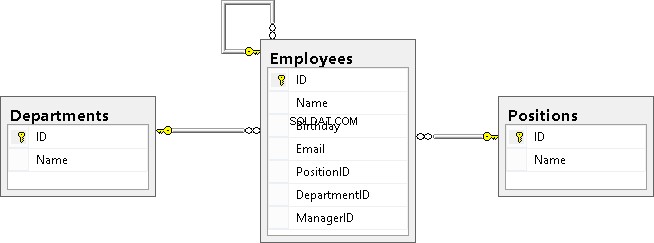
Then create a diagram and check how our tables are linked:
As you can see, the Employees table is linked with the Positions and Departments tables and is a recursive reference.
Finally, I would like to note that reference keys can include additional properties such as ON DELETE CASCADE and ON UPDATE CASCADE. They define the behavior when deleting or updating a record that is referenced from the reference table. If these properties are not specified, then we cannot change the ID of the record in the reference table referenced from the other table. Also, we cannot delete this record from the reference table until we remove all the rows that refer to this record or update the references to another value in these rows.
For example, let’s re-create the table and specify the ON DELETE CASCADE property for FK_Employees_DepartmentID:
DROP TABLE Employees CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID) ON DELETE CASCADE, CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID) ) INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Let’s delete the department with identifier ‘3’ from the Departments table:
DELETE Departments WHERE ID=3
Let’s view the data in table Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
| 1000 | John | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Mike | 1976-06-07 | NULL | 1 | 2 | 1000 |
As you can see, data of Department ‘3’ has been deleted from the Employees table as well.
The ON UPDATE CASCADE property has similar behavior, but it works when updating the ID value in the reference table. For example, if we change the position ID in the Positions reference table, then DepartmentID in the Employees table will receive a new value, which we have specified in the reference table. But in this case this cannot be demonstrated, because the ID column in the Departments table has the IDENTITY property, which will not allow us to execute the following query (change the department identifier from 3 to 30):
UPDATE Departments SET ID=30 WHERE ID=3
The main point is to understand the essence of these 2 options ON DELETE CASCADE and ON UPDATE CASCADE. I apply these options very rarely, and I recommend that you think carefully before you specify them in the reference constraint, because If an entry is accidentally deleted from the reference table, this can lead to big problems and create a chain reaction.
Let’s restore department ‘3’:
-- we permit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments ON INSERT Departments(ID,Name) VALUES(3,N'IT') -- we prohibit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments OFF
We completely clear the Employees table using the TRUNCATE TABLE command:
TRUNCATE TABLE Employees
Again, we will add data using the INSERT command:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Tóm tắt:
We have described the following DDL commands:
• Adding the IDENTITY property to a field allows to make this field automatically populated (count field) for the table;
• ALTER TABLE table_name ADD field_list with_features – allows you to add new fields to the table;
• ALTER TABLE table_name DROP COLUMN field_list – allows you to delete fields from the table;
• ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (fields) REFERENCES reference_table – allows you to determine the relationship between a table and a reference table.
Other constraints – UNIQUE, DEFAULT, CHECK
Using the UNIQUE constraint, you can say that the values for each row in a given field or in a set of fields must be unique. In the case of the Employees table, we can apply this restriction to the Email field. Let’s first fill the Email values, if they are not yet defined:
UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1000 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1001 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1002 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1003
Now, you can impose the UNIQUE constraint on this field:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Thus, a user will not be able to enter the same email for several employees.
The UNIQUE constraint has the following structure:the «UQ» prefix followed by the table name and a field name (after the underscore), to which the restriction applies.
When you need to add the UNIQUE constraint for the set of fields, we will list them separated by commas:
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(field1,field2,…)
By adding a DEFAULT constraint to a field, we can specify a default value that will be inserted if, when inserting a new record, this field is not listed in the list of fields in the INSERT command. You can set this restriction when creating a table.
Let’s add the HireDate field to the Employees table and set the current date as a default value:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
If the HireDate column already exists, then we can use the following syntax:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
To specify the default value, execute the following command:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
As there was no such column before, then when adding it, the current date will be inserted into each entry of the HireDate field.
When creating a new record, the current date will be also automatically added, unless we explicitly specify it, i.e. specify in the list of columns. Let’s demonstrate this with an example, where we will not specify the HireDate field in the list of the values added:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Ostin',' example@sqldat.com')
To check the result, run the command:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Ostin | NULL | example@sqldat.com | NULL | NULL | NULL | 2015-04-08 |
The CHECK constraint is used when it is necessary to check the values being inserted in the fields. For example, let’s impose this constraint on the identification number field, which is an employee ID (ID). Let’s limit the identification numbers to be in the range from 1000 to 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
The constraint name is usually as follows:the «CK_» prefix first followed by the table name and a field name, for which constraint is imposed.
Let’s add an invalid record to check if the constraint is working properly (we will get the corresponding error):
INSERT Employees(ID,Email) VALUES(2000,'example@sqldat.com')
Now, let’s change the value being inserted to 1500 and make sure that the record is inserted:
INSERT Employees(ID,Email) VALUES(1500,'example@sqldat.com')
We can also create UNIQUE and CHECK constraints without specifying a name:
ALTER TABLE Employees ADD UNIQUE(Email) ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Still, this is a bad practice and it is desirable to explicitly specify the constraint name so that users can see what each object defines:
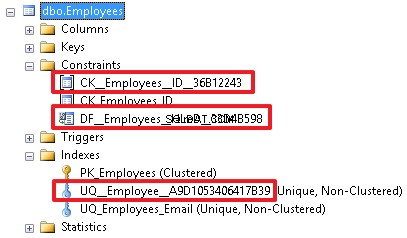
A good name gives us more information about the constraint. And, accordingly, all these restrictions can be specified when creating a table, if it does not exist yet.
Let’s delete the table:
DROP TABLE Employees
Let’s re-create the table with all the specified constraints using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME(), -- I have an exception for DEFAULT CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT UQ_Employees_Email UNIQUE (Email), CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999) )
Finally, let’s insert our employees in the table:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3), (1002,N'Mike','19760607',' example@sqldat.com ',1,2), (1003,N'Jordan','19820417',' example@sqldat.com',4,3)
Some words about the indexes created with the PRIMARY KEY and UNIQUE constraints
When creating the PRIMARY KEY and UNIQUE constraints, the indexes with the same names (PK_Employees and UQ_Employees_Email) are automatically created. By default, the index for the primary key is defined as CLUSTERED, and for other indexes, it is set as NONCLUSTERED.
It should be noted that the clustered index is not used in all DBMSs. A table can have only one clustered (CLUSTERED) index. It means that the records of the table will be ordered by this index. In addition, we can say that this index has direct access to all the data in the table. This is the main index of the table. A clustered index can help with the optimization of queries. If we want to set the clustered index for another index, then when creating the primary key, we should specify the NONCLUSTERED property:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY NONCLUSTERED(field1,field2,…)
Let’s specify the PK_Employees constraint index as nonclustered, while the UQ_Employees_Email constraint index – as clustered. At first, delete these constraints:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
Now, create them with the CLUSTERED and NONCLUSTERED indexes:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID) ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Once it is done, you can see that records have been sorted by the UQ_Employees_Email clustered index:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 2015-04-08 |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 3 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 2015-04-08 |
For reference tables, it is better when a clustered index is built on the primary key, as in queries we often refer to the identifier of the reference table to obtain a name (Position, Department). The clustered index has direct access to the rows of the table, and hence it follows that we can get the value of any column without additional overhead.
It is recommended that the clustered index should be applied to the fields that you use for selection very often.
Sometimes in tables, a key is created by the stubbed field. In this case, it is a good idea to specify the CLUSTERED index for an appropriate index and specify the NONCLUSTERED index when creating the stubbed field.
Summary:
We have analyzed all the constraint types that are created with the «ALTER TABLE table_name ADD CONSTRAINT constraint_name …» command:
- PRIMARY KEY;
- FOREIGN KEY controls links and data referential integrity;
- UNIQUE – serves for setting a unique value;
- CHECK – allows monitoring the correctness of added data;
- DEFAULT – allows specifying a default value;
- The «ALTER TABLE table_name DROP CONSTRAINT constraint_name» command allows deleting all the constraints.
Additionally, we have reviewed the indexes:CLUSTERED and UNCLUSTERED.
Creating unique indexes
I am going to analyze indexes created not for the PRIMARY KEY or UNIQUE constraints.
It is possible to set indexes by a field or a set of fields using the following command:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Also, you can add the CLUSTERED, NONCLUSTERED, and UNIQUE properties as well as specify the order:ASC (by default) or DESC.
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
When creating the nonclustered index, the NONCLUSTERED property can be dropped as it is set by default.
To delete the index, use the command:
DROP INDEX IDX_Employees_Name ON Employees
You can create simple indexes and constraints with the CREATE TABLE command.
At first, delete the table:
DROP TABLE Employees
Then, create the table with all the constraints and indexes using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID), CONSTRAINT UQ_Employees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999), INDEX IDX_Employees_Name(Name) )
Finally, add information about our employees:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1,NULL), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3,1003), (1002,N'Mike','19760607',' example@sqldat.com ',1,2,1000), (1003,N'Jordan','19820417',' example@sqldat.com',4,3,1000)
Keep in mind that it is possible to add values with the INCLUDE command in the nonclustered index. Thus, in this case, the INCLUDE index is a clustered index where the necessary values are linked to the index, rather than to the table. These indexes can improve the SELECT query performance if there are all the required fields in the index. However, it may lead to increasing the index size, as field values are duplicated in the index.
Abstract from MSDN. Here is how the syntax of the command to create indexes looks:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column [ ASC | DESC ] [ ,...n ] ) [ INCLUDE ( column_name [ ,...n ] ) ]
Tóm tắt
Indexes can simultaneously improve the SELECT query performance and lead to poor speed for modifying table data. This happens, as you need to rebuild all the indexes for a particular table after each system modification.
The strategy on creating indexes may depend on many factors such as frequency of data modifications in the table.
Conclusion
As you can see, the DDL language is not as difficult as it may seem. I have provided almost all the main constructions. I wish you good luck with studying the SQL language.