Đây là phần thứ hai của tài liệu dành riêng cho Tìm kiếm ngữ nghĩa của SQL Server . Trong bài viết trước, chúng ta đã tìm hiểu những kiến thức cơ bản. Bây giờ, chúng ta sẽ tập trung vào việc so sánh các tài liệu được lưu trữ trên Hệ thống tệp Windows và phân tích so sánh với Tìm kiếm ngữ nghĩa trong SQL Server.
Thực hiện phân tích so sánh các tài liệu dựa trên tên
Chúng tôi sẽ thực hiện phân tích so sánh các tài liệu dựa trên cách đặt tên tiêu chuẩn của chúng. Tại thời điểm này, hãy kiểm tra nhanh bằng cách truy vấn NVFilestreamSample cơ sở dữ liệu chúng tôi đã thiết lập trước đó:
-- View stored documents managed by File Table to check
SELECT stream_id
,[name]
,file_type
,creation_time
FROM EmployeesFilestreamSample.dbo.EmployeesDocumentStore
Kết quả phải hiển thị cho chúng tôi tài liệu được lưu trữ:
Danh sách kiểm tra tìm kiếm theo ngữ nghĩa
Chúng ta đã có cơ sở dữ liệu và hai tài liệu MS Word mẫu trên File System bằng File Table (bạn có thể tham khảo Phần 1 để cập nhật kiến thức nếu cần). Tuy nhiên, điều đó không tự động đủ điều kiện cho các tài liệu của chúng tôi cho tình huống Tìm kiếm ngữ nghĩa.
Tìm kiếm ngữ nghĩa có thể được bật theo một trong những cách sau:
- Nếu bạn đã thiết lập Tìm kiếm Toàn văn , bạn có thể bật Tìm kiếm ngữ nghĩa chỉ trong một bước.
- Bạn có thể thiết lập Tìm kiếm ngữ nghĩa trực tiếp, nhưng trước khi bạn phải thiết lập Tìm kiếm toàn văn bản.
Kiểm tra Tìm kiếm Toàn văn Trước khi Thiết lập Tìm kiếm Ngữ nghĩa
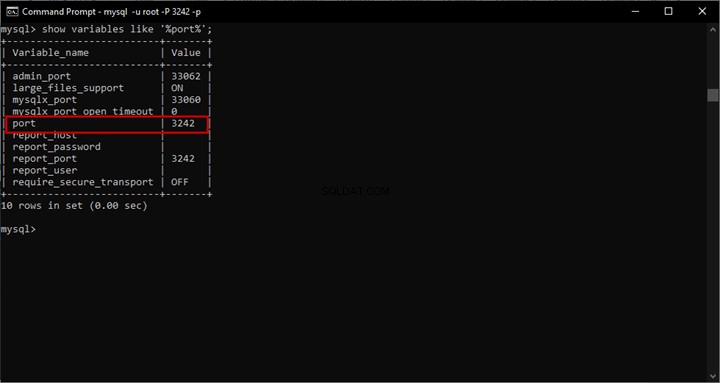
Nếu truy vấn toàn văn bản hoạt động, chúng tôi chỉ cần bật Tìm kiếm ngữ nghĩa. Để kiểm tra điều đó, hãy chạy truy vấn Toàn văn đối với bảng mong muốn:
-- Searching word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
Đầu ra:
Do đó, trước tiên chúng ta cần đáp ứng các yêu cầu của Tìm kiếm toàn văn bản và sau đó bật Tìm kiếm ngữ nghĩa.
Bật Tìm kiếm Ngữ nghĩa để Sử dụng
Ít nhất hai điểm sau đây là cần thiết để sử dụng Tìm kiếm ngữ nghĩa:
- Chỉ số Duy nhất
- Danh mục toàn văn bản
- Chỉ mục Toàn văn
Thực thi tập lệnh T-SQL sau để tạo một chỉ mục duy nhất:
-- Create unique index required for Semantic Search
CREATE UNIQUE INDEX UQ_Stream_Id
ON EmployeesDocumentStore(stream_id)
GO
Tạo danh mục Toàn văn dựa trên chỉ mục duy nhất mới được tạo. Và sau đó, tạo chỉ mục Toàn văn như được hiển thị bên dưới:
-- Getting Semantic Search ready to be used with File Table
CREATE FULLTEXT CATALOG EmployeesFileTableCatalog WITH ACCENT_SENSITIVITY = ON;
CREATE FULLTEXT INDEX ON EmployeesDocumentStore
(
name LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_type LANGUAGE 1033 STATISTICAL_SEMANTICS,
file_stream TYPE COLUMN file_type LANGUAGE 1033 STATISTICAL_SEMANTICS
)
KEY INDEX UQ_Stream_Id
ON EmployeesFileTableCatalog WITH CHANGE_TRACKING AUTO, STOPLIST=SYSTEM;
Kết quả:
Kiểm tra Tìm kiếm Toàn văn Sau khi Thiết lập Tìm kiếm Ngữ nghĩa
Hãy để chúng tôi chạy cùng một truy vấn Toàn văn để tìm kiếm từ Nhân viên trong các tài liệu được lưu trữ:
-- Searching (after Semantic Search setup) word Employee using Full-Text search against EmployeesDocumentStore File Table
SELECT [name]
FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore]
WHERE CONTAINS(name,'Employee')
Đầu ra:
Các truy vấn Toàn văn bản có thể hoạt động dựa trên Bảng Tệp trong khi chúng tôi chuẩn bị sẵn sàng cho Tìm kiếm Ngữ nghĩa.
Thêm các tài liệu MS Word khác
Chúng tôi đi đến Nhân viênDocumentStore Bảng Tệp và nhấp vào Khám phá Thư mục Bảng Tệp :
Tạo và lưu trữ một tài liệu mới có tên Nhân viên hợp đồng Sadaf :
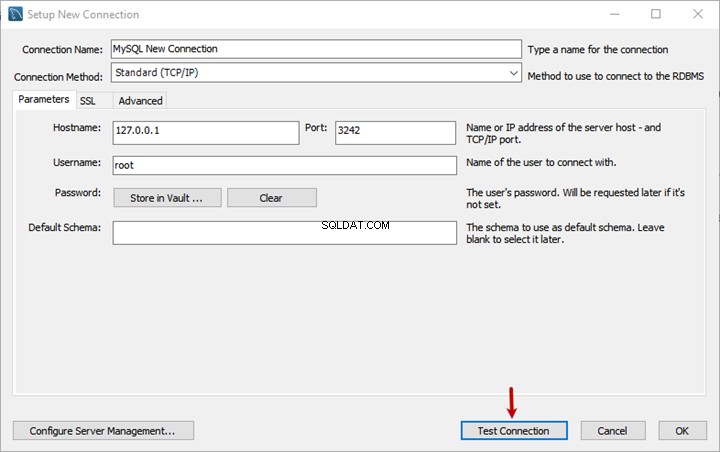
Tiếp theo, thêm văn bản sau vào tài liệu mới tạo. Dòng đầu tiên phải là tiêu đề của tài liệu!
Nhân viên hợp đồng Sadaf (chức danh)
Sadaf là một nhà phân tích kinh doanh rất hiệu quả, người thực hiện công việc dựa trên liên hệ. Cô ấy hoàn toàn có khả năng xử lý các yêu cầu kinh doanh và biến chúng thành các thông số kỹ thuật để các nhà phát triển làm việc. Cô ấy là một nhà phân tích kinh doanh rất giàu kinh nghiệm.
Thêm một tài liệu khác có tên Mike Permanent Employee :
Cập nhật tài liệu bằng văn bản sau:
Nhân viên thường trực của Mike (Tiêu đề của tài liệu)
Mike là một lập trình viên mới có chuyên môn bao gồm phát triển web. Anh ấy là một người học hỏi nhanh và vui vẻ làm việc trong bất kỳ dự án nào. Anh ấy có kỹ năng giải quyết vấn đề mạnh mẽ nhưng anh ấy có ít kiến thức kinh doanh hơn. Anh ấy yêu cầu sự hỗ trợ từ các nhà phát triển hoặc nhà phân tích kinh doanh khác để hiểu vấn đề và đáp ứng các yêu cầu.
Anh ấy rất giỏi khi làm các dự án nhỏ nhưng anh ấy gặp khó khăn nếu được giao một dự án lớn hoặc phức tạp.
Chúng tôi có bốn tài liệu được lưu trữ trên Hệ thống tệp của Windows được quản lý bởi Bảng tệp. Những tài liệu này sẽ được sử dụng bởi Tìm kiếm ngữ nghĩa (bao gồm cả Tìm kiếm toàn văn bản).
Quan trọng:Mặc dù chúng tôi vừa lưu trữ bốn tài liệu MS Word trong thư mục làm mẫu, nhưng bạn có thể hình dung tầm quan trọng của việc sử dụng Tìm kiếm ngữ nghĩa khi hàng trăm tài liệu như vậy được duy trì bởi cơ sở dữ liệu SQL Server và bạn cần truy vấn những tài liệu đó để tìm thông tin có giá trị.
Việc đặt tên tiêu chuẩn cho tài liệu có ý nghĩa rất quan trọng đối với việc triển khai thành công phương pháp này.
Đếm tài liệu đơn giản
Chúng tôi có thể so sánh các tài liệu này và xác định sự khác biệt và tương đồng dựa trên cách đặt tên tiêu chuẩn của chúng bằng cách sử dụng Tìm kiếm ngữ nghĩa. Ví dụ:một truy vấn đơn giản có thể cho chúng tôi biết tổng số tài liệu được lưu trữ trong Thư mục Windows:
-- Getting total number of stored documents
SELECT COUNT(*) AS Total_Documents FROM EmployeesDocumentStore

So sánh nhân viên thường trực và nhân viên dựa trên hợp đồng
Lần này, chúng tôi đang sử dụng Tìm kiếm ngữ nghĩa để so sánh số lượng nhân viên cố định và nhân viên làm việc theo hợp đồng trong tổ chức của chúng tôi:
-- Creating a summary table variable
DECLARE @Documents TABLE
(DocumentType VARCHAR(100),
DocumentsCount INT)
INSERT INTO @Documents -- Storing total number of stored documents into summary table
SELECT 'Total Documents',COUNT(*) AS Total_Documents FROM EmployeesDocumentStore
INSERT INTO @Documents -- Storing total number of permanent employees documents stored into summary table
SELECT 'Total Permanent Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Permanent'
INSERT INTO @Documents --Storing total number of permanent employees documents stored
SELECT 'Total Contract Employees',COUNT(*)
FROM semantickeyphrasetable (EmployeesDocumentStore, *)
WHERE keyphrase = 'Contract'
SELECT DocumentType,DocumentsCount FROM @Documents
Đầu ra:
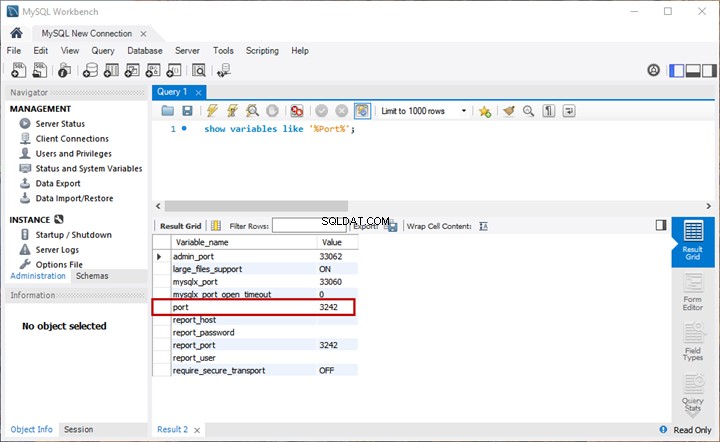
Hãy để chúng tôi chạy một truy vấn Tìm kiếm ngữ nghĩa đơn giản (dựa trên tên tài liệu) để xem cụm từ khóa và điểm số tương đối cho mỗi tài liệu:
-- Getting keyphrase and relative score for all the documents
SELECT * FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
ORDER BY score
Đầu ra:
Hãy để chúng tôi thêm chi tiết vào tên tài liệu. Chúng tôi sẽ đổi tên chúng như sau:
- Nhân viên thường trực của Asif - Người quản lý dự án có kinh nghiệm
- Nhân viên cố định của Mike - Lập trình viên mới
- Nhân viên Thường trực của Peter - Giám đốc Dự án Mới
- Nhân viên hợp đồng Sadaf - Nhà phân tích kinh doanh có kinh nghiệm
Tìm nhân viên mới (Tài liệu)
Tìm các tài liệu liên quan đến nhân viên mới dựa trên chức danh của họ (đặt tên chuẩn):
-- Getting document name-based scoring to find fresh employees for a new project
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName
,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) where keyphrase='fresh'
order by DocumentName desc
Kết quả:
Tìm nhân viên có kinh nghiệm (Tài liệu)
Giả sử chúng ta muốn nhanh chóng xem xét tất cả các chi tiết của các nhân viên có kinh nghiệm cho dự án phức tạp phía trước. Sử dụng truy vấn Tìm kiếm Ngữ nghĩa sau:
-- Getting document name-based scoring to find all experienced employees
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='experienced' order by DocumentName
Đầu ra:
Tìm tất cả Người quản lý dự án (Tài liệu)
Cuối cùng, nếu chúng ta muốn xem nhanh các tài liệu cho tất cả các nhà quản lý dự án, chúng ta cần truy vấn Tìm kiếm ngữ nghĩa sau:
-- Getting document name-based scoring to find all project managers
SELECT (SELECT name from EmployeesDocumentStore where path_locator=document_key) as DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)
where keyphrase='Project'
Kết quả:
Sau khi thực hiện hướng dẫn, bạn có thể lưu trữ thành công dữ liệu phi cấu trúc, chẳng hạn như tài liệu MS Word, trong Thư mục Windows bằng cách sử dụng Bảng Tệp.
Đánh giá phân tích dựa trên tên
Cho đến nay, chúng tôi đã học cách thực hiện phân tích dựa trên tên của các tài liệu được lưu trữ trong Bảng Tệp bằng cách sử dụng Tìm kiếm ngữ nghĩa. Tuy nhiên, chúng tôi cần đáp ứng các điều kiện sau:
- Nên đặt tên chuẩn.
- Tên phải cung cấp thông tin cần thiết để phân tích.
Những điều kiện này cũng là hạn chế của phân tích dựa trên tên. Nhưng điều này không có nghĩa là chúng ta không thể làm được gì nhiều với nó.
Trọng tâm của chúng tôi vẫn là phương pháp Tìm kiếm ngữ nghĩa dựa trên tên / cột.
Xem các Cột Tên của Tài liệu
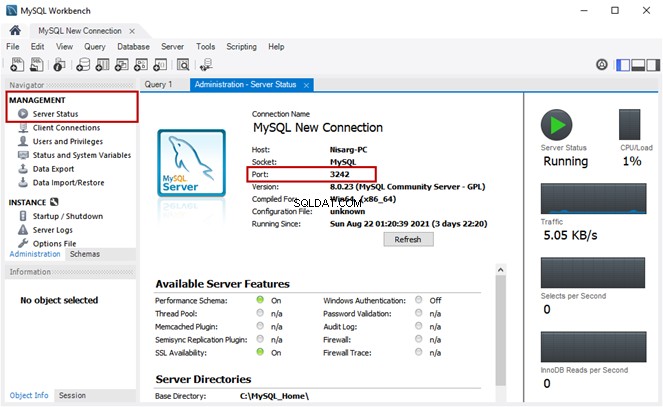
Hãy để chúng tôi xem một số cột chính của bảng Tài liệu bao gồm Tên cột:
USE EmployeesFilestreamSample
-- View name column with the file types of the stored documents in File Table for analysis
SELECT name,file_type
FROM dbo.EmployeesDocumentStore
Đầu ra:
Hiểu chức năng SEMANTICKEYPHRASETABLE
SQL Server cung cấp SEMANTICKEYPHRASETABLE chức năng phân tích tài liệu với Tìm kiếm ngữ nghĩa. Cú pháp như sau:
SEMANTICKEYPHRASETABLE
(
table,
{ column | (column_list) | * }
[ , source_key ]
)
Chức năng này cung cấp cho chúng tôi các cụm từ chính liên quan đến tài liệu. Chúng tôi có thể sử dụng chúng để phân tích tài liệu dựa trên tên hoặc nội dung của chúng. Trong trường hợp của chúng tôi, chúng tôi không chỉ cần sử dụng chức năng này mà còn phải hiểu cách sử dụng nó đúng cách.
Hàm yêu cầu dữ liệu sau:
- Tên của Bảng Tệp sẽ được sử dụng để phân tích Tìm kiếm Ngữ nghĩa.
- Tên của cột được sử dụng để phân tích Tìm kiếm theo ngữ nghĩa.
Sau đó, nó trả về dữ liệu sau:
- Column_id - số cột
- Document_Key - khóa chính mặc định cho tài liệu Bảng Tệp
- Cụm từ khóa - là một cụm từ mà Tìm kiếm ngữ nghĩa quyết định lập chỉ mục để phân tích. Nó áp dụng cho cả tên và nội dung của tài liệu tùy thuộc vào cột mà chúng ta muốn xem các cụm từ khóa cho
- Điểm - xác định độ mạnh của một cụm từ khóa được liên kết với một tài liệu, chẳng hạn như cách một tài liệu được nhận biết tốt nhất bởi cụm từ khóa của nó. Điểm số có thể nằm trong khoảng từ 0,0 đến 1,0.
Phân tích tất cả tài liệu bằng chức năng SEMANTICKEYPHRASETABLE
Chúng tôi sử dụng SEMANTICKEYPHRASETABLE chức năng để phân tích dựa trên tên của các tài liệu được lưu trữ trong thư mục Windows do Bảng Tệp quản lý.
Thực thi tập lệnh T-SQL sau:
USE EmployeesFilestreamSample
-- View key phrases and their score for the name column
SELECT * FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name)
order by score desc
Đầu ra:
Chúng tôi có một danh sách tất cả các cụm từ chính được đính kèm với tất cả các tài liệu và điểm của chúng. column_id 3 ở hàng trên cùng là tên cột. Ngoài ra, chúng tôi cũng gọi hàm bằng cách cung cấp cột này (tên):
Bạn có thể tìm thấy document_key : 0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260 đang chạy tập lệnh sau (mặc dù rõ ràng rằng tài liệu này là tài liệu có tên chứa cụm từ khóa sadaf ):
USE EmployeesFilestreamSample
-- Finding document name by its key (path_locator)
SELECT name,path_locator FROM dbo.EmployeesDocumentStore
WHERE path_locator=0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260
Đầu ra:
Cụm từ khóa sadaf đã được cho điểm tốt nhất : 1,0 .
Do đó, trong trường hợp đặt tên tài liệu chuẩn với đầy đủ thông tin cho phân tích Tìm kiếm ngữ nghĩa, cụm từ khóa sadaf của chúng tôi là kết quả phù hợp nhất cho tên tài liệu cụ thể đó.
Phân tích tài liệu cụ thể bằng chức năng SEMANTICKEYPHRASETABLE
Chúng tôi có thể thu hẹp phân tích Tìm kiếm theo ngữ nghĩa của mình dựa trên tên cột. Ví dụ:chúng tôi chỉ cần xem cột tên- dựa trên cụm từ chính của một tài liệu cụ thể. Chúng tôi có thể chỉ định khóa tài liệu trong SEMANTICKEYPHRASETABLE Chức năng.
Đầu tiên, chúng tôi xác định khóa tài liệu cho tài liệu đó mà chúng tôi muốn xem tất cả các cụm từ khóa. Chạy tập lệnh T-SQL sau:
-- Find document_key of the document where the name contains Peter
SELECT name,path_locator as document_key From EmployeesDocumentStore
WHERE name like '%Peter%'
Khóa tài liệu là 0xFF6A92952500812FF013376870181CFA6D7C070220
Bây giờ, chúng ta hãy xem tài liệu này liên quan đến tất cả các cụm từ khóa có thể xác định tên tài liệu:
-- View all the key phrases and their score for a document related to Peter permanent employee
SELECT column_id,name,keyphrase,score FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220)
INNER JOIN dbo.EmployeesDocumentStore on path_locator=document_key
order by score desc
Kết quả:
Cụm từ khóa nhân viên đạt điểm cao nhất trong tài liệu này. Chúng ta có thể thấy rằng tất cả các từ của cột đều là những cụm từ chính xác định ý nghĩa của tài liệu.
Hiểu chức năng SEMANTICSIMILARITYTABLE
Chức năng này giúp chúng tôi so sánh một tài liệu với tất cả các tài liệu khác dựa trên các cụm từ khóa. Cú pháp của hàm này như sau:
SEMANTICSIMILARITYTABLE
(
table,
{ column | (column_list) | * },
source_key
)
Nó yêu cầu tên của bảng, cột và khóa tài liệu phải khớp với các tài liệu khác. Ví dụ:chúng tôi có thể tuyên bố rằng hai tài liệu tương tự nhau nếu chúng có điểm đối sánh cụm từ khóa tốt.
So sánh tài liệu bằng chức năng SEMANTICSIMILARITYTABLE
Hãy so sánh một tài liệu với các tài liệu khác bằng cách sử dụng SEMANTICSIMILARITYTABLE Chức năng.
So sánh tất cả tài liệu của người quản lý dự án
Chúng tôi cần xem tất cả các tài liệu liên quan đến người quản lý dự án. Từ các ví dụ trên, chúng tôi biết rằng khóa tài liệu cho tài liệu được chỉ định là 0xFF6A92952500812FF013376870181CFA6D7C070220 . Do đó, chúng tôi có thể sử dụng khóa này để tìm các kết quả phù hợp khác bao gồm cả người quản lý dự án:
USE EmployeesFilestreamSample
-- View all the documents closely related to Peter project manager
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
Đầu ra:
Tài liệu liên quan chặt chẽ nhất là Asif Permanent Employee - Người quản lý dự án có kinh nghiệm.docx . Điều đó có ý nghĩa vì cả hai nhân viên đều là công nhân cố định và cả hai đều là quản lý dự án.
So sánh tài liệu của nhà phân tích kinh doanh có kinh nghiệm
Bây giờ, chúng ta sẽ so sánh các tài liệu liên quan đến nhà phân tích kinh doanh có kinh nghiệm s và tìm kết quả phù hợp nhất bằng Tìm kiếm ngữ nghĩa. Chúng tôi chỉ giới hạn trong phân tích dựa trên tên tài liệu:
USE EmployeesFilestreamSample
-- Finding document_key for experienced business analyst
select name,path_locator as document_key from EmployeesDocumentStore
where name like '%experienced business analyst%'
-- View all the documents closely related to experienced business analyst
SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260) SST
INNER JOIN dbo.EmployeesDocumentStore EDS on EDS.path_locator=SST.matched_document_key
order by score desc
Đầu ra:
Như chúng ta có thể thấy từ kết quả ở trên, kết quả phù hợp nhất với tài liệu liên quan đến nhà phân tích kinh doanh có kinh nghiệm là tài liệu của người quản lý dự án giàu kinh nghiệm bởi vì cả hai đều có kinh nghiệm . Tuy nhiên, điểm 0,3 cho thấy không có nhiều điểm chung giữa hai tài liệu này.
Kết luận
Xin chúc mừng! Chúng tôi đã học thành công cách lưu trữ tài liệu trong các thư mục Windows và phân tích chúng bằng Tìm kiếm ngữ nghĩa. Chúng tôi cũng tìm hiểu các chức năng để sử dụng trong thực tế. Bây giờ bạn có thể áp dụng kiến thức mới và thử các bài tập sau để
Hãy theo dõi các tài liệu khác!