Chiến lược lập chỉ mục bảng là một trong những chìa khóa điều chỉnh và tối ưu hóa hiệu suất quan trọng nhất. Trong SQL Server, các chỉ mục (cả hai, theo cụm và không gộp) được tạo bằng cách sử dụng cấu trúc B-tree, trong đó mỗi trang hoạt động như một nút danh sách được liên kết kép, có thông tin về trang trước và trang tiếp theo. Cấu trúc B-tree này, được gọi là Forward Scan, giúp đọc các hàng từ chỉ mục dễ dàng hơn bằng cách quét hoặc tìm kiếm các trang của nó từ đầu đến cuối. Mặc dù quét chuyển tiếp là phương pháp quét chỉ mục mặc định và được biết đến nhiều, SQL Server cung cấp cho chúng ta khả năng quét các hàng chỉ mục trong cấu trúc B-tree từ cuối đến đầu. Khả năng này được gọi là Quét ngược. Trong bài viết này, chúng ta sẽ xem điều này xảy ra như thế nào và ưu nhược điểm của phương pháp quét ngược là gì.
SQL Server cung cấp cho chúng ta khả năng đọc dữ liệu từ chỉ mục bảng bằng cách quét các nút cấu trúc cây B chỉ mục từ đầu đến cuối bằng phương pháp Quét chuyển tiếp hoặc đọc các nút cấu trúc cây B từ cuối đến đầu bằng cách sử dụng Phương pháp quét ngược. Như tên cho biết, quét ngược được thực hiện trong khi đọc ngược lại với thứ tự của cột có trong chỉ mục, được thực hiện với tùy chọn DESC trong câu lệnh sắp xếp ORDER BY T-SQL, chỉ định hướng của hoạt động quét.
Trong các tình huống cụ thể, SQL Server Engine nhận thấy rằng việc đọc dữ liệu chỉ mục từ cuối đến đầu bằng phương pháp quét ngược nhanh hơn đọc theo thứ tự bình thường với phương pháp quét chuyển tiếp, điều này có thể yêu cầu quy trình sắp xếp tốn kém của SQL Động cơ. Các trường hợp như vậy bao gồm việc sử dụng hàm tổng hợp MAX () và các tình huống khi sắp xếp kết quả truy vấn ngược với thứ tự chỉ mục. Hạn chế chính của phương pháp quét ngược là Trình tối ưu hóa truy vấn SQL Server sẽ luôn chọn thực thi nó bằng cách sử dụng thực thi kế hoạch nối tiếp, mà không thể tận dụng lợi ích từ các kế hoạch thực thi song song.
Giả sử chúng ta có bảng sau chứa thông tin về nhân viên của công ty. Có thể tạo bảng bằng cách sử dụng câu lệnh T-SQL CREATE TABLE TABLE bên dưới:
CREATE TABLE [dbo].[CompanyEmployees](
[ID] [INT] IDENTITY (1,1) ,
[EmpID] [int] NOT NULL,
[Emp_First_Name] [nvarchar](50) NULL,
[Emp_Last_Name] [nvarchar](50) NULL,
[EmpDepID] [int] NOT NULL,
[Emp_Status] [int] NOT NULL,
[EMP_PhoneNumber] [nvarchar](50) NULL,
[Emp_Adress] [nvarchar](max) NULL,
[Emp_EmploymentDate] [DATETIME] NULL,
PRIMARY KEY CLUSTERED
(
[ID] ASC
)ON [PRIMARY]))
Sau khi tạo bảng, chúng tôi sẽ điền vào bảng đó với 10K bản ghi giả, sử dụng câu lệnh INSERT bên dưới:
INSERT INTO [dbo].[CompanyEmployees]
([EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate])
VALUES
(1,'AAA','BBB',4,1,9624488779,'AMM','2006-10-15')
GO 10000 Nếu chúng ta thực hiện câu lệnh SELECT bên dưới để truy xuất dữ liệu từ bảng đã tạo trước đó, các hàng sẽ được sắp xếp theo giá trị cột ID theo thứ tự tăng dần, giống như thứ tự chỉ mục được phân nhóm:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] ASC
Sau đó, kiểm tra kế hoạch thực thi cho truy vấn đó, một quá trình quét sẽ được thực hiện trên chỉ mục được phân nhóm để lấy dữ liệu được sắp xếp từ chỉ mục như được hiển thị trong kế hoạch thực thi bên dưới:
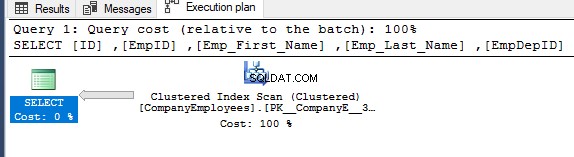
Để biết hướng quét được thực hiện trên chỉ mục được phân cụm, hãy bấm chuột phải vào nút quét chỉ mục để duyệt qua các thuộc tính của nút. Từ thuộc tính nút Quét chỉ mục theo cụm, thuộc tính Hướng quét sẽ hiển thị hướng quét được thực hiện trên chỉ mục trong truy vấn đó, là Quét chuyển tiếp như được hiển thị trong ảnh chụp nhanh bên dưới:
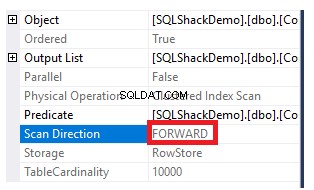
Hướng quét chỉ mục cũng có thể được truy xuất từ kế hoạch thực thi XML từ thuộc tính ScanDirection trong nút IndexScan, như được hiển thị bên dưới:

Giả sử rằng chúng ta cần truy xuất giá trị ID tối đa từ bảng CompanyE Employees đã tạo trước đó, bằng cách sử dụng truy vấn T-SQL bên dưới:
SELECT MAX([ID]) FROM [dbo].[CompanyEmployees]
Sau đó, xem lại kế hoạch thực thi được tạo ra từ việc thực hiện truy vấn đó. Bạn sẽ thấy rằng quá trình quét sẽ được thực hiện trên chỉ mục được phân nhóm như được hiển thị trong kế hoạch thực thi bên dưới:
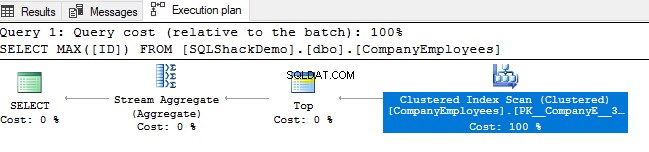
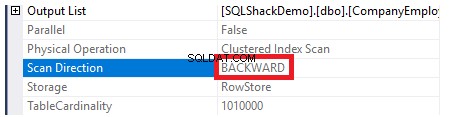
Để kiểm tra hướng quét chỉ mục, chúng ta sẽ duyệt qua các thuộc tính của nút Quét chỉ mục theo cụm. Kết quả sẽ cho chúng ta thấy rằng, SQL Server Engine thích quét chỉ mục theo cụm từ cuối đến đầu, điều này sẽ nhanh hơn trong trường hợp này, để có được giá trị lớn nhất của cột ID, do thực tế là chỉ mục đã được sắp xếp theo cột ID, như được hiển thị bên dưới:
Ngoài ra, nếu chúng tôi cố gắng truy xuất dữ liệu bảng đã tạo trước đó bằng cách sử dụng câu lệnh SELECT sau đây, các bản ghi sẽ được sắp xếp theo giá trị cột ID, nhưng lần này, ngược lại với thứ tự chỉ mục nhóm, bằng cách chỉ định tùy chọn sắp xếp DESC trong ORDER Mệnh đề BY hiển thị bên dưới:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
ORDER BY [ID] DESC
Nếu bạn kiểm tra kế hoạch thực thi được tạo sau khi thực hiện truy vấn SELECT trước đó, bạn sẽ thấy rằng quá trình quét sẽ được thực hiện trên chỉ mục được phân cụm để lấy các bản ghi được yêu cầu của bảng, như được hiển thị bên dưới:
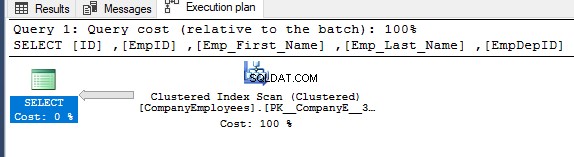
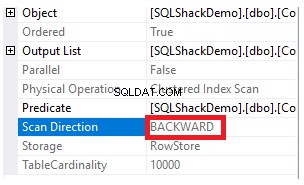
Các thuộc tính của nút Clustered Index Scan sẽ cho thấy hướng quét mà SQL Server Engine thích thực hiện là hướng Backward Scan, nhanh hơn trong trường hợp này, do sắp xếp dữ liệu ngược lại với cách sắp xếp thực của chỉ mục được phân nhóm, lưu ý rằng chỉ mục đã được sắp xếp theo thứ tự tăng dần theo cột ID, như được hiển thị bên dưới:
So sánh Hiệu suất
Giả sử rằng chúng ta có các câu lệnh SELECT dưới đây truy xuất thông tin về tất cả nhân viên đã được thuê kể từ năm 2010, hai lần; lần đầu tiên tập hợp kết quả trả về sẽ được sắp xếp theo thứ tự tăng dần theo các giá trị cột ID và lần thứ hai, tập kết quả trả về sẽ được sắp xếp theo thứ tự giảm dần theo các giá trị cột ID bằng cách sử dụng các câu lệnh T-SQL bên dưới:
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] ASC
OPTION (MAXDOP 1)
GO
SELECT [ID]
,[EmpID]
,[Emp_First_Name]
,[Emp_Last_Name]
,[EmpDepID]
,[Emp_Status]
,[EMP_PhoneNumber]
,[Emp_Adress]
,[Emp_EmploymentDate]
FROM [SQLShackDemo].[dbo].[CompanyEmployees]
WHERE Emp_EmploymentDate >='2010-01-01'
ORDER BY [ID] DESC
OPTION (MAXDOP 1)
GO
Kiểm tra các kế hoạch thực thi được tạo bằng cách thực hiện hai truy vấn SELECT, kết quả sẽ cho thấy rằng quá trình quét sẽ được thực hiện trên chỉ mục được phân cụm trong hai truy vấn để lấy dữ liệu, nhưng hướng quét trong truy vấn đầu tiên sẽ là Chuyển tiếp Quét do sắp xếp dữ liệu ASC và Quét ngược trong truy vấn thứ hai do sử dụng sắp xếp dữ liệu DESC, để thay thế nhu cầu sắp xếp lại dữ liệu, như được hiển thị bên dưới:
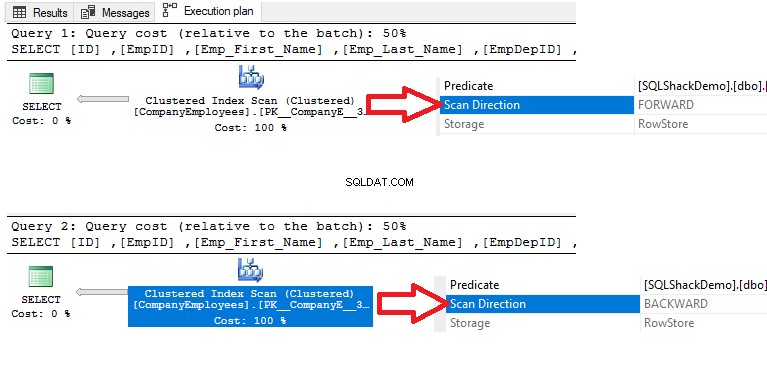
Ngoài ra, nếu chúng ta kiểm tra thống kê thực thi IO và TIME của hai truy vấn, chúng ta sẽ thấy rằng cả hai truy vấn đều thực hiện các hoạt động IO giống nhau và sử dụng gần các giá trị thực thi và thời gian CPU.
Các giá trị này cho chúng ta thấy SQL Server Engine thông minh như thế nào khi chọn hướng quét chỉ mục phù hợp nhất và nhanh nhất để truy xuất dữ liệu cho người dùng, đó là Quét chuyển tiếp trong trường hợp đầu tiên và Quét ngược trong trường hợp thứ hai, như rõ ràng từ thống kê bên dưới :

Hãy để chúng tôi thăm lại ví dụ MAX trước đó. Giả sử rằng chúng ta cần truy xuất ID tối đa của những nhân viên đã được thuê trong năm 2010 trở về sau. Đối với điều này, chúng tôi sẽ sử dụng các câu lệnh SELECT sau đây sẽ sắp xếp dữ liệu đọc theo giá trị cột ID với sắp xếp ASC trong truy vấn đầu tiên và sắp xếp DESC trong truy vấn thứ hai:
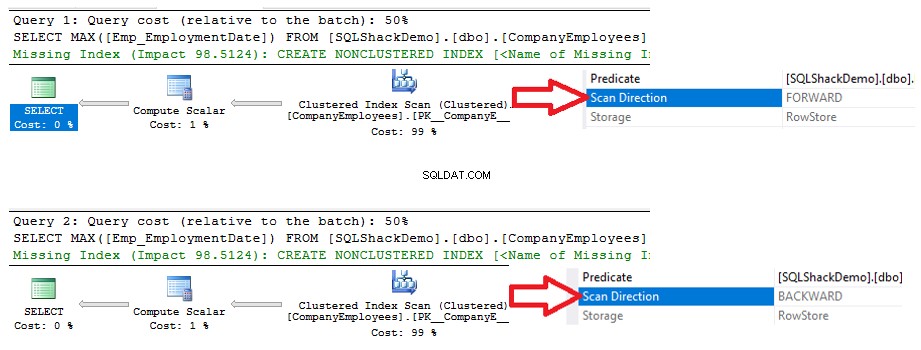
SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
Bạn sẽ thấy từ các kế hoạch thực thi được tạo ra từ việc thực hiện hai câu lệnh SELECT, rằng cả hai truy vấn sẽ thực hiện thao tác quét trên chỉ mục được phân cụm để lấy giá trị ID tối đa, nhưng theo các hướng quét khác nhau; Quét chuyển tiếp trong truy vấn đầu tiên và quét ngược trong truy vấn thứ hai, do các tùy chọn sắp xếp ASC và DESC, như được hiển thị bên dưới:
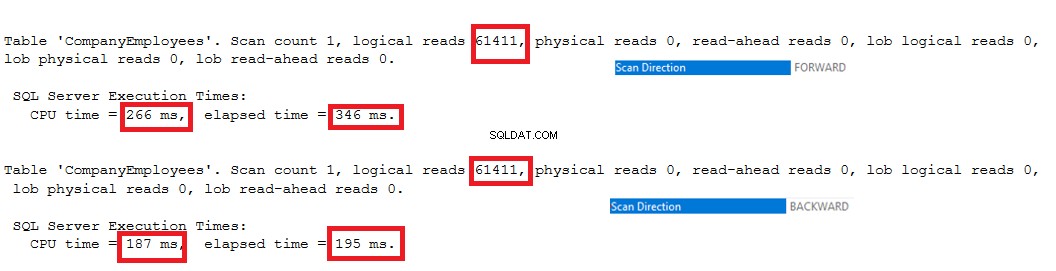
Thống kê IO được tạo bởi hai truy vấn sẽ không cho thấy sự khác biệt giữa hai hướng quét. Nhưng thống kê TIME cho thấy sự khác biệt lớn giữa việc tính ID tối đa của các hàng khi các hàng này được quét từ đầu đến cuối bằng phương pháp Quét chuyển tiếp và quét từ cuối đến đầu bằng phương pháp Quét ngược. Từ kết quả dưới đây, rõ ràng là phương pháp Quét ngược là phương pháp quét tối ưu để có được giá trị ID lớn nhất:
Tối ưu hóa Hiệu suất
Như tôi đã đề cập ở phần đầu của bài viết này, lập chỉ mục truy vấn là chìa khóa quan trọng nhất trong quá trình điều chỉnh và tối ưu hóa hiệu suất. Trong truy vấn trước, nếu chúng tôi sắp xếp để thêm chỉ mục không phân cụm trên cột Ngày tuyển dụng của bảng CompanyE Employees, sử dụng câu lệnh CREATE INDEX T-SQL bên dưới:
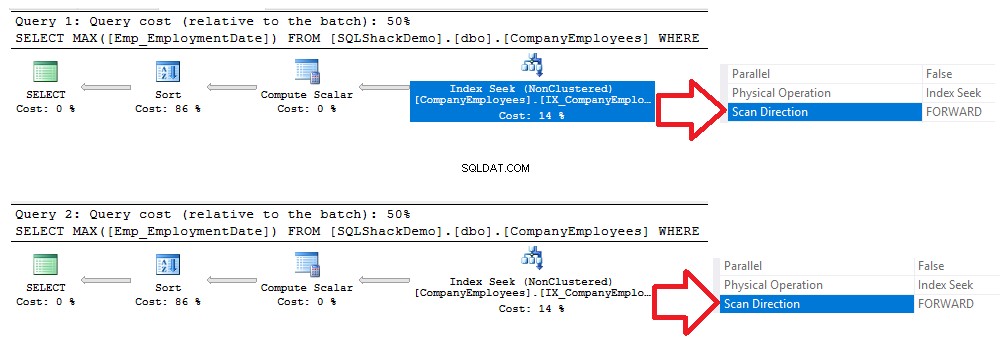
CREATE NONCLUSTERED INDEX IX_CompanyEmployees_Emp_EmploymentDate ON CompanyEmployees (Emp_EmploymentDate) After that, we will execute the same previous queries as shown below: SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] ASC OPTION (MAXDOP 1) GO SELECT MAX([Emp_EmploymentDate]) FROM [SQLShackDemo].[dbo].[CompanyEmployees] WHERE [Emp_EmploymentDate] >='2017-01-01' GROUP BY ID ORDER BY [ID] DESC OPTION (MAXDOP 1) GO
Kiểm tra các kế hoạch thực thi được tạo sau khi thực hiện hai truy vấn, bạn sẽ thấy rằng một tìm kiếm sẽ được thực hiện trên chỉ mục không phân tán mới được tạo và cả hai truy vấn sẽ quét chỉ mục từ đầu đến cuối bằng phương pháp Quét chuyển tiếp mà không cần để thực hiện Quét ngược để tăng tốc độ truy xuất dữ liệu, mặc dù chúng tôi đã sử dụng tùy chọn sắp xếp DESC trong truy vấn thứ hai. Điều này xảy ra do tìm kiếm chỉ mục trực tiếp mà không cần thực hiện quét toàn bộ chỉ mục, như được hiển thị trong so sánh kế hoạch thực thi bên dưới:
Kết quả tương tự có thể được lấy từ thống kê IO và TIME được tạo từ hai truy vấn trước đó, trong đó hai truy vấn sẽ sử dụng cùng một lượng thời gian thực thi, hoạt động của CPU và IO, với một sự khác biệt rất nhỏ, như được hiển thị trong ảnh chụp nhanh thống kê bên dưới :

Liên kết hữu ích:
- Mô tả các chỉ mục được phân nhóm và không gộp chung
- Tạo các chỉ mục không phân biệt
- Điều chỉnh hiệu suất máy chủ SQL:Quét ngược chỉ mục
Công cụ hữu ích:
dbForge Index Manager - phần bổ trợ SSMS tiện dụng để phân tích trạng thái của chỉ mục SQL và khắc phục sự cố với phân mảnh chỉ mục.