Bổ sung: SQL Server 2012 cho thấy một số cải thiện hiệu suất trong lĩnh vực này nhưng dường như không giải quyết được các vấn đề cụ thể được lưu ý bên dưới. Vấn đề rõ ràng nên được sửa trong phiên bản chính tiếp theo sau SQL Server 2012!
Kế hoạch của bạn cho thấy các phần chèn đơn đang sử dụng các thủ tục được tham số hóa (có thể được tham số hóa tự động) vì vậy thời gian phân tích cú pháp / biên dịch cho các phần này phải là tối thiểu.
Tôi nghĩ rằng tôi sẽ xem xét vấn đề này nhiều hơn một chút, vì vậy hãy thiết lập một vòng lặp (tập lệnh) và thử điều chỉnh số lượng VALUES các mệnh đề và ghi lại thời gian biên dịch.
Sau đó, tôi chia thời gian biên dịch cho số hàng để có được thời gian biên dịch trung bình cho mỗi mệnh đề. Kết quả ở bên dưới
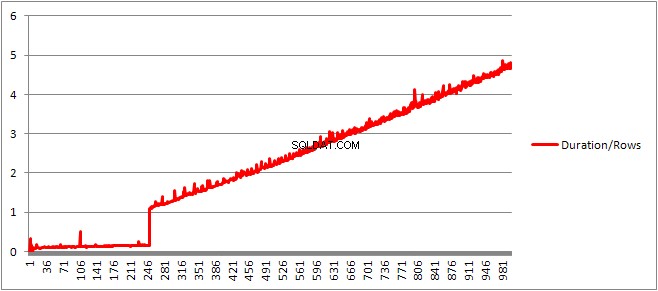
Lên đến 250 VALUES các mệnh đề hiện thời gian biên dịch / số lượng các mệnh đề có xu hướng tăng nhẹ nhưng không có gì quá kịch tính.
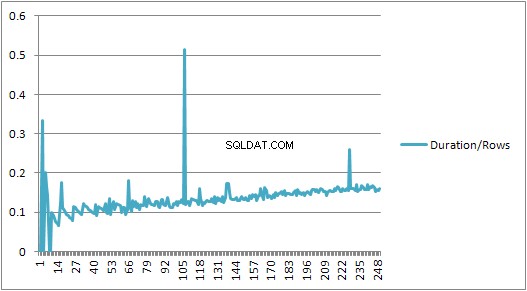
Nhưng sau đó có một sự thay đổi đột ngột.
Phần dữ liệu đó được hiển thị bên dưới.
+------+----------------+-------------+---------------+---------------+
| Rows | CachedPlanSize | CompileTime | CompileMemory | Duration/Rows |
+------+----------------+-------------+---------------+---------------+
| 245 | 528 | 41 | 2400 | 0.167346939 |
| 246 | 528 | 40 | 2416 | 0.162601626 |
| 247 | 528 | 38 | 2416 | 0.153846154 |
| 248 | 528 | 39 | 2432 | 0.157258065 |
| 249 | 528 | 39 | 2432 | 0.156626506 |
| 250 | 528 | 40 | 2448 | 0.16 |
| 251 | 400 | 273 | 3488 | 1.087649402 |
| 252 | 400 | 274 | 3496 | 1.087301587 |
| 253 | 400 | 282 | 3520 | 1.114624506 |
| 254 | 408 | 279 | 3544 | 1.098425197 |
| 255 | 408 | 290 | 3552 | 1.137254902 |
+------+----------------+-------------+---------------+---------------+
Kích thước kế hoạch được lưu trong bộ nhớ cache đang tăng lên một cách tuyến tính đột nhiên giảm xuống nhưng CompileTime tăng gấp 7 lần và CompileMemory tăng lên. Đây là điểm cắt giữa kế hoạch được tham số hóa tự động (với 1.000 tham số) với kế hoạch không được tham số hóa. Sau đó, nó dường như trở nên kém hiệu quả hơn về mặt tuyến tính (về số lượng mệnh đề giá trị được xử lý trong một thời gian nhất định).
Không chắc chắn tại sao điều này nên được. Có lẽ khi nó đang biên soạn một kế hoạch cho các giá trị chữ cụ thể, nó phải thực hiện một số hoạt động không quy mô tuyến tính (chẳng hạn như sắp xếp).
Nó dường như không ảnh hưởng đến kích thước của kế hoạch truy vấn được lưu trong bộ nhớ cache khi tôi thử truy vấn bao gồm hoàn toàn các hàng trùng lặp và không ảnh hưởng đến thứ tự đầu ra của bảng hằng số (và khi bạn đang chèn vào một đống thời gian dành cho sắp xếp dù sao cũng sẽ là vô nghĩa ngay cả khi nó đã xảy ra).
Hơn nữa, nếu một chỉ mục được phân nhóm được thêm vào bảng, kế hoạch vẫn hiển thị một bước sắp xếp rõ ràng vì vậy nó dường như không sắp xếp tại thời điểm biên dịch để tránh sắp xếp trong thời gian chạy.

Tôi đã cố gắng xem điều này trong trình gỡ lỗi nhưng các ký hiệu công khai cho phiên bản SQL Server 2008 của tôi dường như không có sẵn vì vậy thay vào đó tôi phải xem UNION ALL tương đương xây dựng trong SQL Server 2005.
Dưới đây là một dấu vết ngăn xếp điển hình
sqlservr.exe!FastDBCSToUnicode() + 0xac bytes
sqlservr.exe!nls_sqlhilo() + 0x35 bytes
sqlservr.exe!CXVariant::CmpCompareStr() + 0x2b bytes
sqlservr.exe!CXVariantPerformCompare<167,167>::Compare() + 0x18 bytes
sqlservr.exe!CXVariant::CmpCompare() + 0x11f67d bytes
sqlservr.exe!CConstraintItvl::PcnstrItvlUnion() + 0xe2 bytes
sqlservr.exe!CConstraintProp::PcnstrUnion() + 0x35e bytes
sqlservr.exe!CLogOp_BaseSetOp::PcnstrDerive() + 0x11a bytes
sqlservr.exe!CLogOpArg::PcnstrDeriveHandler() + 0x18f bytes
sqlservr.exe!CLogOpArg::DeriveGroupProperties() + 0xa9 bytes
sqlservr.exe!COpArg::DeriveNormalizedGroupProperties() + 0x40 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x18a bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!COptExpr::DeriveGroupProperties() + 0x146 bytes
sqlservr.exe!CQuery::PqoBuild() + 0x3cb bytes
sqlservr.exe!CStmtQuery::InitQuery() + 0x167 bytes
sqlservr.exe!CStmtDML::InitNormal() + 0xf0 bytes
sqlservr.exe!CStmtDML::Init() + 0x1b bytes
sqlservr.exe!CCompPlan::FCompileStep() + 0x176 bytes
sqlservr.exe!CSQLSource::FCompile() + 0x741 bytes
sqlservr.exe!CSQLSource::FCompWrapper() + 0x922be bytes
sqlservr.exe!CSQLSource::Transform() + 0x120431 bytes
sqlservr.exe!CSQLSource::Compile() + 0x2ff bytes
Vì vậy, việc loại bỏ các tên trong dấu vết ngăn xếp, có vẻ như sẽ tốn rất nhiều thời gian để so sánh các chuỗi.
Bài viết KB này chỉ ra rằng DeriveNormalizedGroupProperties được liên kết với những gì từng được gọi là giai đoạn chuẩn hóa của quá trình xử lý truy vấn
Giai đoạn này bây giờ được gọi là ràng buộc hoặc đại số hóa và nó lấy đầu ra của cây phân tích cú pháp biểu thức từ giai đoạn phân tích cú pháp trước đó và xuất ra cây biểu thức được đại số hóa (cây xử lý truy vấn) để chuyển sang tối ưu hóa (tối ưu hóa kế hoạch tầm thường trong trường hợp này) [ref].
Tôi đã thử một thử nghiệm nữa (Tập lệnh) để chạy lại thử nghiệm ban đầu nhưng xem xét ba trường hợp khác nhau.
- Họ và Tên Chuỗi có độ dài 10 ký tự không trùng lặp.
- Họ và Tên Chuỗi có độ dài 50 ký tự không trùng lặp.
- Họ và Tên Chuỗi có độ dài 10 ký tự với tất cả các ký tự trùng lặp.
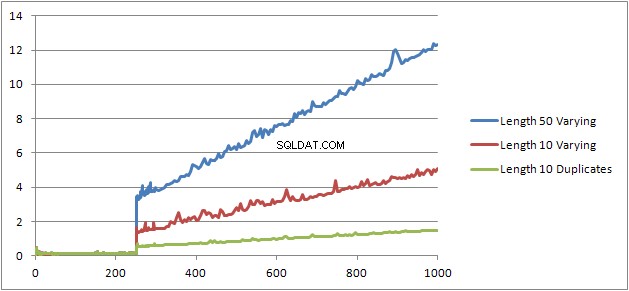
Có thể thấy rõ ràng rằng các chuỗi càng dài thì mọi thứ càng trở nên tồi tệ và ngược lại, càng nhiều bản sao thì mọi thứ càng tốt hơn. Như đã đề cập trước đây, các bản sao không ảnh hưởng đến kích thước kế hoạch được lưu trong bộ nhớ cache, vì vậy tôi cho rằng phải có một quy trình nhận dạng trùng lặp khi xây dựng chính cây biểu thức được đại số hóa.
Chỉnh sửa
Một nơi mà thông tin này được tận dụng được hiển thị bởi @Lieven tại đây
SELECT *
FROM (VALUES ('Lieven1', 1),
('Lieven2', 2),
('Lieven3', 3))Test (name, ID)
ORDER BY name, 1/ (ID - ID)
Bởi vì tại thời điểm biên dịch, nó có thể xác định rằng Name cột không có bản sao nó bỏ qua thứ tự theo 1/ (ID - ID) phụ biểu thức tại thời điểm chạy (sắp xếp trong kế hoạch chỉ có một ORDER BY cột) và không có lỗi chia cho không được nâng lên. Nếu các bản sao được thêm vào bảng thì toán tử sắp xếp sẽ hiển thị hai thứ tự theo cột và lỗi dự kiến sẽ xuất hiện.