Điều gì khiến truy vấn áp dụng chéo hoạt động rất kém trên tài liệu XML đơn giản này và hoạt động chậm hơn theo cấp số nhân khi tập dữ liệu phát triển?
Đây là việc sử dụng trục cha để lấy ID thuộc tính từ nút mục.
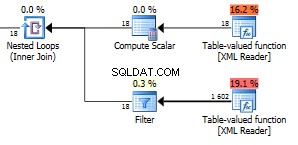
Đây là phần của kế hoạch truy vấn có vấn đề.

Lưu ý 423 hàng xuất phát từ hàm Giá trị bảng thấp hơn.
Chỉ thêm một nút mục nữa với ba nút trường sẽ mang lại cho bạn điều này.
732 hàng được trả về.
Điều gì sẽ xảy ra nếu chúng ta nhân đôi các nút từ truy vấn đầu tiên lên tổng số 6 nút mục?
Chúng tôi có tới 1602 hàng được trả lại.
Hình 18 trong hàm trên cùng là tất cả các nút trường trong XML của bạn. Chúng tôi có ở đây 6 mục với ba trường trong mỗi mục. 18 nút đó được sử dụng trong một vòng lặp lồng nhau tham gia chống lại chức năng khác, do đó 18 lần thực thi trả về 1602 hàng cho rằng nó đang trả về 89 hàng cho mỗi lần lặp. Đó chỉ là số lượng nút chính xác trong toàn bộ XML. Nó thực sự là một nhiều hơn tất cả các nút có thể nhìn thấy. Tôi không biết tại sao. Bạn có thể sử dụng truy vấn này để kiểm tra tổng số nút trong XML của mình.
select count(*)
from @XML.nodes('//*, //@*, //*/text()') as T(X)
Vì vậy, thuật toán được SQL Server sử dụng để lấy giá trị khi bạn sử dụng trục cha .. trong một hàm giá trị là lần đầu tiên nó tìm thấy tất cả các nút bạn đang băm nhỏ, 18 trong trường hợp cuối cùng. Đối với mỗi nút đó, nó sẽ chia nhỏ và trả về toàn bộ tài liệu XML và kiểm tra trong toán tử bộ lọc để tìm nút bạn thực sự muốn. Ở đó, bạn có sự phát triển theo cấp số nhân của mình. Thay vì sử dụng trục cha, bạn nên sử dụng thêm một áp dụng chéo. Đầu tiên cắt nhỏ trên vật phẩm và sau đó trên thực địa.
select I.X.value('@name', 'varchar(5)') as item_name,
F.X.value('@id', 'uniqueidentifier') as field_id,
F.X.value('@type', 'int') as field_type,
F.X.value('text()[1]', 'nvarchar(15)') as field_value
from #temp as T
cross apply T.x.nodes('/data/item') as I(X)
cross apply I.X.nodes('field') as F(X)
Tôi cũng đã thay đổi cách bạn truy cập giá trị văn bản của trường. Sử dụng . sẽ làm cho SQL Server đi tìm các nút con của trường field và nối các giá trị đó trong kết quả. Bạn không có giá trị con nào nên kết quả giống nhau nhưng bạn nên tránh để phần đó trong kế hoạch truy vấn (toán tử UDX).
Kế hoạch truy vấn không có vấn đề với trục mẹ nếu bạn đang sử dụng chỉ mục XML nhưng bạn vẫn sẽ được lợi từ việc thay đổi cách bạn tìm nạp giá trị trường.