Đây là một phần của loạt bài toán tử có vấn đề về nội bộ máy chủ SQL. Hãy nhớ đọc bài đăng đầu tiên và bài đăng thứ hai của Kalen về chủ đề này.
SQL Server đã được hơn 30 năm và tôi đã làm việc với SQL Server gần như lâu rồi. Tôi đã thấy rất nhiều thay đổi trong nhiều năm (và nhiều thập kỷ!) Và các phiên bản của sản phẩm đáng kinh ngạc này. Trong các bài đăng này, tôi sẽ chia sẻ với bạn cách tôi xem xét một số tính năng hoặc khía cạnh của SQL Server, đôi khi cùng với một chút quan điểm lịch sử.
Lần trước, tôi đã nói về băm trong kế hoạch truy vấn SQL Server như một toán tử có khả năng có vấn đề trong chẩn đoán máy chủ SQL. Hashing thường được sử dụng để nối và tổng hợp khi không có chỉ mục hữu ích. Và giống như quét (mà tôi đã nói trong bài đầu tiên của loạt bài này), có những lúc băm thực sự là một lựa chọn tốt hơn các lựa chọn thay thế. Đối với tham gia băm, một trong những lựa chọn thay thế là LOOP JOIN, điều mà tôi cũng đã nói với bạn lần trước.
Trong bài đăng này, tôi sẽ cho bạn biết về một giải pháp thay thế khác cho băm. Hầu hết các lựa chọn thay thế cho băm đều yêu cầu dữ liệu phải được sắp xếp, vì vậy hoặc gói cần phải bao gồm toán tử SORT hoặc dữ liệu bắt buộc phải được sắp xếp do các chỉ mục hiện có.
Các kiểu kết hợp khác nhau để chẩn đoán máy chủ SQL
Đối với các hoạt động JOIN, loại JOIN phổ biến và hữu ích nhất là LOOP JOIN. Tôi đã mô tả thuật toán cho LOOP JOIN trong bài trước. Mặc dù bản thân dữ liệu không cần phải được sắp xếp cho LOOP JOIN, nhưng sự hiện diện của một chỉ mục trên bảng bên trong làm cho việc kết hợp hiệu quả hơn nhiều và như bạn nên biết, sự hiện diện của một chỉ mục ngụ ý một số cách sắp xếp. Trong khi một chỉ mục được phân nhóm tự sắp xếp dữ liệu, thì một chỉ mục không phân nhóm sẽ sắp xếp các cột chính của chỉ mục. Trên thực tế, trong hầu hết các trường hợp, không có chỉ mục, trình tối ưu hóa của SQL Server sẽ chọn sử dụng thuật toán HASH JOIN. Chúng ta đã thấy điều này trong ví dụ lần trước, rằng không có chỉ mục, HASH JOIN được chọn và với các chỉ mục, chúng ta có LOOP JOIN.
Kiểu tham gia thứ ba là MERGE JOIN. Thuật toán này hoạt động trên hai tập dữ liệu đã được sắp xếp. Nếu chúng ta đang cố gắng kết hợp (hoặc JOIN) hai tập dữ liệu đã được sắp xếp, thì chỉ cần một lần chuyển qua mỗi tập để tìm các hàng phù hợp. Đây là mã giả cho thuật toán kết hợp hợp nhất:
get first row R1 from input 1
get first row R2 from input 2
while not at the end of either input
begin
if R1 joins with R2
begin
output (R1, R2)
get next row R2 from input 2
end
else if R1 < R2
get next row R1 from input 1
else
get next row R2 from input 2
end
Mặc dù MERGE JOIN là một thuật toán rất hiệu quả, nhưng nó yêu cầu cả hai tập dữ liệu đầu vào phải được sắp xếp theo khóa tham gia, điều này thường có nghĩa là có một chỉ mục được phân cụm trên khóa tham gia cho cả hai bảng. Vì bạn chỉ nhận được một chỉ mục được phân cụm cho mỗi bảng, nên việc chọn cột khóa được phân cụm chỉ để cho phép MERGE JOINS xảy ra có thể không phải là lựa chọn tổng thể tốt nhất cho khóa phân cụm.
Vì vậy, thông thường, tôi không khuyên bạn nên cố gắng tạo chỉ mục chỉ cho mục đích MERGE JOINS, nhưng nếu cuối cùng bạn nhận được MERGE JOIN do các chỉ mục đã tồn tại, đó thường là một điều tốt. Ngoài việc yêu cầu sắp xếp cả hai tập dữ liệu đầu vào, MERGE JOIN cũng yêu cầu ít nhất một trong các tập dữ liệu có giá trị duy nhất cho khóa kết hợp.
Hãy xem một ví dụ. Đầu tiên, chúng tôi sẽ tạo lại Tiêu đề và Chi tiết bảng:
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
CREATE CLUSTERED INDEX Header_index on Headers(SalesOrderID);
GO
CREATE CLUSTERED INDEX Detail_index on Details(SalesOrderID);
GO
Tiếp theo, hãy xem kế hoạch kết hợp giữa các bảng sau:
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID;
GO
Đây là kế hoạch:

Lưu ý rằng ngay cả với một chỉ mục được phân nhóm trên cả hai bảng, chúng ta vẫn nhận được HASH JOIN. Chúng ta có thể xây dựng lại một trong các chỉ mục để trở thành DUY NHẤT. Trong trường hợp này, nó phải là chỉ mục trên Tiêu đề vì đó là bảng duy nhất có giá trị duy nhất cho SalesOrderID.
CREATE UNIQUE CLUSTERED INDEX Header_index on Headers(SalesOrderID) WITH DROP_EXISTING;
GO
Bây giờ, hãy chạy lại truy vấn và lưu ý rằng kế hoạch hoạt động như thế nào một MERGE JOIN.

Các kế hoạch này được hưởng lợi từ việc dữ liệu đã được sắp xếp trong một chỉ mục, vì kế hoạch thực thi có thể tận dụng lợi thế của việc sắp xếp. Nhưng đôi khi, SQL Server phải thực hiện sắp xếp như một phần của quá trình thực thi truy vấn của nó. Đôi khi, bạn có thể thấy toán tử SORT hiển thị trong một kế hoạch ngay cả khi bạn không yêu cầu đầu ra được sắp xếp. Nếu SQL Server cho rằng MERGE JOIN có thể là một lựa chọn tốt, nhưng một trong các bảng không có chỉ mục được phân nhóm thích hợp và nó đủ nhỏ để làm cho việc sắp xếp rất rẻ, thì một SORT có thể được thực hiện để cho phép MERGE JOIN. đã qua sử dụng.
Nhưng thông thường, toán tử SORT hiển thị trong các truy vấn mà chúng tôi đã yêu cầu dữ liệu được sắp xếp với ORDER BY, như trong ví dụ sau.
SELECT * FROM Details
ORDER BY ProductID;
GO

Chỉ mục nhóm được quét (giống như quét bảng) và sau đó các hàng được sắp xếp theo yêu cầu.
Xử lý chỉ mục theo cụm đã được sắp xếp
Nhưng điều gì sẽ xảy ra nếu dữ liệu đã được sắp xếp trong một chỉ mục được phân cụm và truy vấn bao gồm một LỆNH THEO trên cột khóa được phân nhóm? Trong ví dụ trên, chúng tôi đã xây dựng một chỉ mục theo cụm trên SalesOrderID trong bảng Chi tiết. Hãy xem hai truy vấn sau:
SELECT * FROM Details;
GO
SELECT * FROM Details
ORDER BY SalesOrderID;
GO
Nếu chúng tôi chạy các truy vấn này cùng nhau, thì Cửa sổ phân tích gói điều chỉnh tiêu điểm nhiệm vụ chỉ ra rằng hai kế hoạch có chi phí ngang nhau; mỗi cái là 50% tổng số. Vậy, sự khác biệt thực sự giữa chúng là gì?
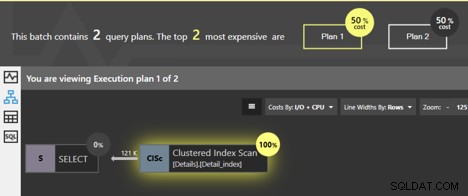
Cả hai truy vấn đều đang quét chỉ mục được phân cụm và SQL Server biết rằng nếu các trang của cấp độ lá được tuân theo thứ tự, dữ liệu sẽ quay trở lại theo thứ tự khóa được phân cụm. Không cần sắp xếp bổ sung, vì vậy không có toán tử SORT nào được thêm vào kế hoạch. Nhưng có một sự khác biệt. Chúng ta có thể nhấp vào toán tử Quét chỉ mục theo cụm và sẽ nhận được một số thông tin chi tiết.
Trước tiên, hãy xem thông tin chi tiết cho kế hoạch đầu tiên, cho truy vấn không có ĐẶT HÀNG BẰNG CÁCH.

Các chi tiết cho chúng tôi biết rằng thuộc tính "Đã đặt hàng" là Sai. Không có yêu cầu nào ở đây rằng dữ liệu phải được trả về theo thứ tự được sắp xếp. Nó chỉ ra rằng trong hầu hết các trường hợp, cách dễ nhất để truy xuất dữ liệu là theo dõi các trang của chỉ mục nhóm, vì vậy dữ liệu sẽ được trả về theo thứ tự, nhưng không có gì đảm bảo. Thuộc tính False có nghĩa là không có yêu cầu SQL Server tuân theo các trang được sắp xếp để trả về kết quả. Trên thực tế, có những cách khác mà SQL Server có thể lấy tất cả các hàng cho bảng mà không cần tuân theo chỉ mục được phân nhóm. Nếu trong khi thực thi, SQL Server chọn sử dụng một phương pháp khác để lấy các hàng, chúng tôi sẽ không thấy kết quả theo thứ tự.
Đối với truy vấn thứ hai, các chi tiết giống như sau:
 Bởi vì truy vấn bao gồm ORDER BY, có yêu cầu rằng dữ liệu phải được trả về theo thứ tự đã sắp xếp và SQL Server sẽ theo dõi các trang của chỉ mục được nhóm theo thứ tự.
Bởi vì truy vấn bao gồm ORDER BY, có yêu cầu rằng dữ liệu phải được trả về theo thứ tự đã sắp xếp và SQL Server sẽ theo dõi các trang của chỉ mục được nhóm theo thứ tự.
Điều quan trọng nhất cần nhớ ở đây là KHÔNG đảm bảo dữ liệu được sắp xếp nếu bạn không bao gồm ORDER BY trong truy vấn của mình. Chỉ vì bạn có một chỉ mục theo nhóm, vẫn không có gì đảm bảo! Ngay cả khi mỗi lần trong năm ngoái mà bạn chạy truy vấn, bạn đã lấy lại dữ liệu theo thứ tự mà không cần ORDER BY, không có gì đảm bảo rằng bạn sẽ tiếp tục lấy lại dữ liệu theo thứ tự. Sử dụng ORDER BY là cách duy nhất để đảm bảo thứ tự trả về kết quả của bạn.
Mẹo Sử dụng Thao tác Sắp xếp
Vì vậy, SORT có phải là một thao tác cần tránh trong chẩn đoán máy chủ SQL không? Cũng giống như các phép toán quét và băm, câu trả lời tất nhiên là "nó phụ thuộc". Việc sắp xếp có thể rất tốn kém, đặc biệt là trên các bộ dữ liệu lớn. Việc lập chỉ mục phù hợp sẽ giúp SQL Server tránh thực hiện các thao tác SORT vì một chỉ mục về cơ bản có nghĩa là dữ liệu của bạn đã được sắp xếp trước. Nhưng lập chỉ mục đi kèm với một chi phí. Có chi phí lưu trữ, ngoài chi phí bảo trì, cho mỗi chỉ mục. Nếu dữ liệu của bạn được cập nhật nhiều, bạn cần giữ số lượng chỉ mục ở mức tối thiểu.
Nếu bạn thấy rằng một số truy vấn chạy chậm của mình hiển thị các hoạt động SORT trong kế hoạch của chúng và nếu các SORT đó là một trong những toán tử đắt nhất trong kế hoạch, bạn có thể xem xét việc xây dựng các chỉ mục cho phép SQL Server tránh việc sắp xếp. Nhưng bạn sẽ cần thực hiện kiểm tra kỹ lưỡng để đảm bảo rằng các chỉ mục bổ sung không làm chậm các truy vấn khác quan trọng đối với hiệu suất ứng dụng tổng thể của bạn.



