Trong phần đầu tiên của loạt bài này, tôi đã giới thiệu các thuật ngữ cơ bản xung quanh việc ghi nhật ký, vì vậy tôi khuyên bạn nên đọc trước khi tiếp tục với bài đăng này. Mọi thứ khác mà tôi sẽ đề cập trong loạt bài này yêu cầu bạn phải biết một số kiến trúc của nhật ký giao dịch, vì vậy đó là những gì tôi sẽ thảo luận lần này. Ngay cả khi bạn không theo dõi loạt bài này, một số khái niệm tôi sẽ giải thích bên dưới rất đáng biết đối với các công việc hàng ngày mà DBA xử lý trong quá trình sản xuất.
Cấu trúc phân cấp
Nhật ký giao dịch được tổ chức nội bộ bằng cách sử dụng phân cấp ba cấp như thể hiện trong hình 1 bên dưới.
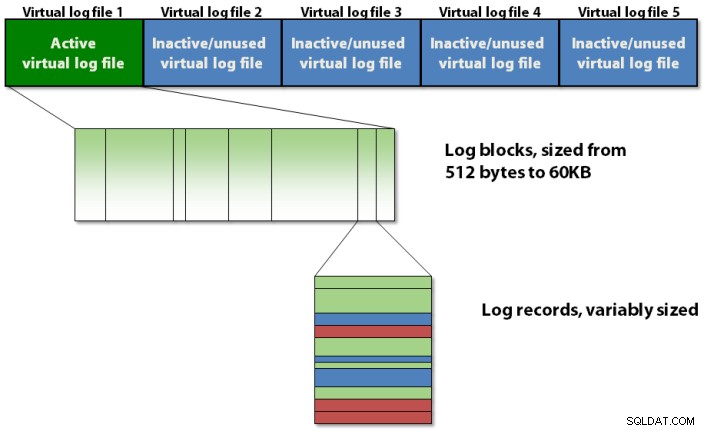 Hình 1:Cấu trúc phân cấp ba cấp của nhật ký giao dịch
Hình 1:Cấu trúc phân cấp ba cấp của nhật ký giao dịch
Nhật ký giao dịch chứa các tệp nhật ký ảo, chứa các khối nhật ký, lưu trữ các bản ghi nhật ký thực.
Tệp nhật ký ảo
Nhật ký giao dịch được chia thành các phần được gọi là tệp nhật ký ảo , thường được gọi là VLF . Điều này được thực hiện để giúp quản lý các hoạt động trong nhật ký giao dịch dễ dàng hơn cho trình quản lý nhật ký trong SQL Server. Bạn không thể chỉ định có bao nhiêu VLF được SQL Server tạo khi cơ sở dữ liệu được tạo lần đầu tiên hoặc tệp nhật ký tự động phát triển, nhưng bạn có thể ảnh hưởng đến nó. Thuật toán cho số lượng VLF được tạo như sau:
- Kích thước tệp nhật ký nhỏ hơn 64MB:tạo 4 VLF, mỗi VLF có kích thước khoảng 16 MB
- Kích thước tệp nhật ký từ 64MB đến 1GB:tạo 8 VLF, mỗi VLF chiếm khoảng 1/8 tổng kích thước
- Kích thước tệp nhật ký lớn hơn 1GB:tạo 16 VLF, mỗi VLF khoảng 1/16 tổng kích thước
Trước SQL Server 2014, khi tệp nhật ký tự động phát triển, số lượng VLF mới được thêm vào cuối tệp nhật ký được xác định bởi thuật toán ở trên, dựa trên kích thước tự động phát triển. Tuy nhiên, bằng cách sử dụng thuật toán này, nếu kích thước tự động tăng trưởng nhỏ và tệp nhật ký trải qua nhiều lần tự động tăng trưởng, thì có thể dẫn đến một số lượng rất lớn các VLF nhỏ (được gọi là phân mảnh VLF ) có thể là một vấn đề lớn về hiệu suất đối với một số hoạt động (xem tại đây).
Do sự cố này, trong SQL Server 2014, thuật toán đã thay đổi để tự động phát triển tệp nhật ký. Nếu kích thước tự động phát triển nhỏ hơn 1/8 tổng kích thước tệp nhật ký, chỉ một VLF mới được tạo, nếu không, thuật toán cũ sẽ được sử dụng. Điều này làm giảm đáng kể số lượng VLF cho một tệp nhật ký đã trải qua một lượng lớn tự động tăng trưởng. Tôi đã giải thích một ví dụ về sự khác biệt trong bài đăng trên blog này.
Mỗi VLF có một số thứ tự xác định duy nhất nó và được sử dụng ở nhiều nơi, mà tôi sẽ giải thích bên dưới và trong các bài đăng trong tương lai. Bạn nghĩ rằng các số thứ tự sẽ bắt đầu bằng 1 đối với cơ sở dữ liệu hoàn toàn mới, nhưng không phải vậy.
Trên phiên bản SQL Server 2019, tôi đã tạo cơ sở dữ liệu mới mà không chỉ định bất kỳ kích thước tệp nào, sau đó kiểm tra các VLF bằng mã bên dưới:
CREATE DATABASE NewDB;
GO
SELECT
[file_id],
[vlf_begin_offset],
[vlf_size_mb],
[vlf_sequence_number]
FROM
sys.dm_db_log_info (DB_ID (N'NewDB'));
Lưu ý sys.dm_db_log_info DMV đã được thêm vào SQL Server 2016 SP2. Trước đó (và ngày nay, vì nó vẫn tồn tại), bạn có thể sử dụng DBCC LOGINFO không có giấy tờ nhưng bạn không thể cung cấp cho nó một danh sách lựa chọn — chỉ cần thực hiện DBCC LOGINFO(N'NewDB'); và số thứ tự VLF nằm trong FSeqNo cột của tập hợp kết quả.
Dù sao, kết quả từ truy vấn sys.dm_db_log_info là:
file_id vlf_begin_offset vlf_size_mb vlf_sequence_number ------- ---------------- ----------- ------------------- 2 8192 1.93 37 2 2039808 1.93 0 2 4071424 1.93 0 2 6103040 2.17 0
Lưu ý rằng VLF đầu tiên bắt đầu ở độ lệch 8,192 byte vào tệp nhật ký. Điều này là do tất cả các tệp cơ sở dữ liệu, bao gồm cả nhật ký giao dịch, có trang tiêu đề tệp chiếm 8KB đầu tiên và lưu trữ các siêu dữ liệu khác nhau về tệp.
Vậy tại sao SQL Server lại chọn 37 chứ không phải 1 cho số thứ tự VLF đầu tiên? Nó tìm số thứ tự VLF cao nhất trong model cơ sở dữ liệu và sau đó, đối với bất kỳ cơ sở dữ liệu mới nào, VLF đầu tiên của nhật ký giao dịch sử dụng số đó cộng với 1 cho số thứ tự của nó. Tôi không biết tại sao thuật toán này lại được chọn trở lại trong thời gian ngắn, nhưng nó đã diễn ra như vậy kể từ ít nhất là SQL Server 7.0.
Để chứng minh điều đó, tôi đã chạy mã này:
SELECT
MAX ([vlf_sequence_number]) AS [Max_VLF_SeqNo]
FROM
sys.dm_db_log_info (DB_ID (N'model')); Và kết quả là:
Max_VLF_SeqNo -------------------- 36
Vậy là bạn đã có nó.
Còn nhiều điều cần thảo luận về VLF và cách chúng được sử dụng, nhưng bây giờ đủ để biết mỗi VLF có một số thứ tự, số thứ tự sẽ tăng lên một cho mỗi VLF.
Khối nhật ký
Mỗi VLF chứa một tiêu đề siêu dữ liệu nhỏ và phần còn lại của không gian được lấp đầy bởi các khối nhật ký. Mỗi khối nhật ký bắt đầu từ 512 byte và sẽ phát triển theo gia số 512 byte đến kích thước tối đa là 60KB, tại thời điểm đó, nó phải được ghi vào đĩa. Một khối nhật ký có thể được ghi vào đĩa trước khi đạt đến kích thước tối đa nếu một trong những điều sau đây xảy ra:
- Giao dịch cam kết và độ bền bị trì hoãn không được sử dụng cho giao dịch này, vì vậy khối nhật ký phải được ghi vào đĩa để giúp giao dịch lâu bền
- Độ bền bị trì hoãn đang được sử dụng và tác vụ hẹn giờ 1ms trong nền "chuyển khối nhật ký hiện tại vào đĩa" sẽ kích hoạt
- Trang tệp dữ liệu đang được ghi vào đĩa bởi một điểm kiểm tra hoặc trình ghi lười biếng và có một hoặc nhiều bản ghi nhật ký trong khối nhật ký hiện tại ảnh hưởng đến trang sắp được ghi (hãy nhớ ghi nhật ký phải được đảm bảo)
Bạn có thể coi khối nhật ký giống như một trang có kích thước thay đổi lưu trữ các bản ghi nhật ký theo thứ tự chúng được tạo bằng các giao dịch thay đổi cơ sở dữ liệu. Không có khối nhật ký cho mỗi giao dịch; các bản ghi nhật ký cho nhiều giao dịch đồng thời có thể được xen kẽ trong một khối nhật ký. Bạn có thể nghĩ rằng điều này sẽ gây khó khăn cho các hoạt động cần tìm tất cả các bản ghi nhật ký cho một giao dịch duy nhất, nhưng điều đó không xảy ra, như tôi sẽ giải thích khi tôi đề cập đến cách hoạt động của tính năng khôi phục giao dịch trong một bài đăng sau.
Hơn nữa, khi một khối nhật ký được ghi vào đĩa, hoàn toàn có thể nó chứa các bản ghi nhật ký từ các giao dịch chưa được cam kết. Đây cũng không phải là vấn đề vì cách khôi phục sự cố hoạt động — đây là một vài bài đăng tốt trong tương lai của loạt bài này.
Số thứ tự nhật ký
Các khối nhật ký có một ID trong một VLF, bắt đầu từ 1 và tăng 1 cho mỗi khối nhật ký mới trong VLF. Bản ghi nhật ký cũng có một ID trong khối nhật ký, bắt đầu từ 1 và tăng 1 cho mỗi bản ghi nhật ký mới trong khối nhật ký. Vì vậy, cả ba phần tử trong phân cấp cấu trúc của nhật ký giao dịch đều có một ID và chúng được kéo lại với nhau thành một mã định danh ba bên được gọi là số thứ tự nhật ký , thường được gọi đơn giản hơn là LSN .
LSN được định nghĩa là <VLF sequence number>:<log block ID>:<log record ID> (4 byte:4 byte:2 byte) và xác định duy nhất một bản ghi nhật ký duy nhất. Đó là một số nhận dạng ngày càng tăng, bởi vì số thứ tự VLF tăng lên mãi mãi.
Đã xong!
Mặc dù các VLF rất quan trọng cần biết, nhưng theo tôi LSN là khái niệm quan trọng nhất để hiểu về việc triển khai ghi nhật ký của SQL Server vì các LSN là nền tảng để xây dựng quá trình khôi phục giao dịch và khôi phục sự cố, và các LSN sẽ xuất hiện lặp đi lặp lại như Tôi tiến bộ qua loạt bài. Trong bài đăng tiếp theo, tôi sẽ đề cập đến việc cắt ngắn nhật ký và bản chất vòng tròn của nhật ký giao dịch, tất cả đều liên quan đến VLF và cách chúng được sử dụng lại.