Độ bền bị trễ là một tính năng khá muộn nhưng thú vị trong SQL Server 2014; quảng cáo chiêu hàng cấp cao của đối tượng địa lý khá đơn giản là:
- "Đánh đổi độ bền cho hiệu suất."
Một số nền tảng đầu tiên. Theo mặc định, SQL Server sử dụng nhật ký ghi trước (WAL), có nghĩa là các thay đổi được ghi vào nhật ký trước khi chúng được phép thực hiện. Trong các hệ thống mà việc ghi nhật ký giao dịch trở thành nút thắt cổ chai và nơi có khả năng mất dữ liệu vừa phải , bây giờ bạn có tùy chọn tạm ngưng yêu cầu để đợi nhật ký xả và xác nhận. Điều này xảy ra theo đúng nghĩa đen lấy D ra khỏi ACID, ít nhất là đối với một phần nhỏ dữ liệu (sẽ nói thêm về điều này sau).
Bạn đã hy sinh điều này ngay bây giờ. Trong chế độ khôi phục hoàn toàn, luôn có một số rủi ro mất dữ liệu, nó chỉ được đo lường về mặt thời gian chứ không phải là kích thước. Ví dụ:nếu bạn sao lưu nhật ký giao dịch năm phút một lần, bạn có thể mất dữ liệu chỉ dưới 5 phút nếu điều gì đó thảm khốc xảy ra. Tôi không nói về chuyển đổi dự phòng đơn giản ở đây, nhưng giả sử máy chủ thực sự bốc cháy hoặc ai đó đi qua dây nguồn - cơ sở dữ liệu rất có thể không thể khôi phục được và bạn có thể phải quay lại thời điểm sao lưu nhật ký cuối cùng . Và đó là giả sử bạn thậm chí đang kiểm tra các bản sao lưu của mình bằng cách khôi phục chúng ở đâu đó - trong trường hợp xảy ra lỗi nghiêm trọng, bạn có thể không có điểm khôi phục như bạn nghĩ. Tất nhiên, chúng tôi có xu hướng không nghĩ đến tình huống này, bởi vì chúng tôi không bao giờ mong đợi những điều tồi tệ ™ sẽ xảy ra.
Cách thức hoạt động
Độ bền trì hoãn cho phép các giao dịch ghi tiếp tục chạy như thể nhật ký đã được chuyển vào đĩa; trong thực tế, việc ghi vào đĩa đã được nhóm lại và hoãn lại, để xử lý ở chế độ nền. Giao dịch là lạc quan; nó giả định rằng nhật ký tuôn ra sẽ xảy ra. Hệ thống sử dụng một đoạn 60KB của bộ đệm nhật ký và cố gắng xóa nhật ký vào đĩa khi khối 60KB này đầy (chậm nhất là - điều này có thể xảy ra và thường xuyên xảy ra trước đó). Bạn có thể đặt tùy chọn này ở cấp cơ sở dữ liệu, ở cấp giao dịch riêng lẻ, hoặc - trong trường hợp thủ tục được biên dịch nguyên bản trong OLTP trong bộ nhớ - ở cấp thủ tục. Cài đặt cơ sở dữ liệu thắng trong trường hợp có xung đột; ví dụ:nếu cơ sở dữ liệu được đặt thành tắt, việc cố gắng thực hiện một giao dịch bằng cách sử dụng tùy chọn bị trì hoãn sẽ đơn giản bị bỏ qua mà không có thông báo lỗi. Ngoài ra, một số giao dịch luôn hoàn toàn lâu bền, bất kể cài đặt cơ sở dữ liệu hoặc cài đặt cam kết; ví dụ:giao dịch hệ thống, giao dịch cơ sở dữ liệu chéo và các hoạt động liên quan đến FileTable, Theo dõi thay đổi, Thay đổi thu thập dữ liệu và sao chép.
Ở cấp độ cơ sở dữ liệu, bạn có thể sử dụng:
ALTER DATABASE dbname SET DELAYED_DURABILITY = DISABLED | ALLOWED | FORCED;
Nếu bạn đặt nó thành ALLOWED , điều này có nghĩa là bất kỳ giao dịch riêng lẻ nào cũng có thể sử dụng Độ bền bị hoãn; FORCED có nghĩa là tất cả các giao dịch có thể sử dụng Độ bền Chậm sẽ (các trường hợp ngoại lệ ở trên vẫn có liên quan trong trường hợp này). Bạn có thể sẽ muốn sử dụng ALLOWED chứ không phải FORCED - nhưng tùy chọn thứ hai có thể hữu ích trong trường hợp ứng dụng hiện có mà bạn muốn sử dụng tùy chọn này xuyên suốt và cũng giảm thiểu số lượng mã phải chạm vào. Một điều quan trọng cần lưu ý về ALLOWED là các giao dịch lâu bền hoàn toàn có thể phải đợi lâu hơn, vì chúng sẽ buộc xóa mọi giao dịch lâu bền bị trì hoãn trước.
Ở cấp độ giao dịch, bạn có thể nói:
COMMIT TRANSACTION WITH (DELAYED_DURABILITY = ON);
Và trong quy trình OLTP trong bộ nhớ được biên dịch tự nhiên, bạn có thể thêm tùy chọn sau vào BEGIN ATOMIC khối:
BEGIN ATOMIC WITH (DELAYED_DURABILITY = ON, ...)
Một câu hỏi phổ biến là xung quanh những gì xảy ra với ngữ nghĩa khóa và cô lập. Không có gì thay đổi, thực sự. Việc khóa và chặn vẫn diễn ra và các giao dịch được cam kết theo cùng một cách và cùng các quy tắc. Sự khác biệt duy nhất là, bằng cách cho phép thực hiện cam kết mà không cần đợi nhật ký chuyển vào đĩa, mọi khóa liên quan sẽ được phát hành sớm hơn nhiều.
Khi nào bạn nên sử dụng nó
Ngoài lợi ích bạn nhận được từ việc cho phép các giao dịch tiến hành mà không cần đợi ghi nhật ký xảy ra, bạn cũng nhận được ít lần ghi nhật ký hơn với kích thước lớn hơn. Điều này có thể hoạt động rất tốt nếu hệ thống của bạn có tỷ lệ cao các giao dịch thực sự nhỏ hơn 60KB và đặc biệt là khi đĩa ghi chậm (mặc dù tôi đã tìm thấy lợi ích tương tự trên SSD và HDD truyền thống). Nó không hoạt động tốt như vậy nếu các giao dịch của bạn, phần lớn, lớn hơn 60KB, nếu chúng thường hoạt động lâu dài hoặc nếu bạn có thông lượng cao và đồng thời cao. Điều có thể xảy ra ở đây là bạn có thể lấp đầy toàn bộ bộ đệm nhật ký trước khi quá trình xả kết thúc, điều này chỉ có nghĩa là chuyển hàng đợi của bạn sang một tài nguyên khác và cuối cùng, không cải thiện hiệu suất mà người dùng ứng dụng nhận thấy.
Nói cách khác, nếu nhật ký giao dịch của bạn hiện không phải là nút cổ chai, đừng bật tính năng này. Làm thế nào bạn có thể biết được liệu nhật ký giao dịch của mình có phải là nút cổ chai hay không? Chỉ báo đầu tiên sẽ là WRITELOG cao đang đợi, đặc biệt khi được kết hợp với PAGEIOLATCH_** . Paul Randal (@PaulRandal) có một loạt bài gồm bốn phần tuyệt vời về xác định các vấn đề trong nhật ký giao dịch, cũng như định cấu hình để có hiệu suất tối ưu:
- Cắt bớt chất béo trong nhật ký giao dịch
- Cắt bớt chất béo trong nhật ký giao dịch
- Các vấn đề về cấu hình nhật ký giao dịch
- Giám sát Nhật ký Giao dịch
Ngoài ra, hãy xem bài đăng trên blog này của Kimberly Tripp (@KimberlyLTripp), 8 bước để có thông lượng nhật ký giao dịch tốt hơn và bài đăng trên blog của nhóm SQL CAT, Chẩn đoán các vấn đề và giới hạn về hiệu suất nhật ký giao dịch của Trình quản lý nhật ký.
Cuộc điều tra này có thể dẫn bạn đến kết luận rằng Độ bền bị trì hoãn đáng được xem xét; nó có thể không. Kiểm tra khối lượng công việc của bạn sẽ là cách đáng tin cậy nhất để biết chắc chắn. Giống như nhiều bổ sung khác trong các phiên bản gần đây của SQL Server ( * ho * Hekaton ), tính năng này KHÔNG được thiết kế để cải thiện từng khối lượng công việc - và như đã lưu ý ở trên, nó thực sự có thể làm cho một số khối lượng công việc trở nên tồi tệ hơn. Hãy xem bài đăng trên blog này của Simon Harvey để biết một số câu hỏi khác mà bạn nên tự hỏi về khối lượng công việc của mình để xác định xem liệu có khả thi khi hy sinh một số độ bền để đạt được hiệu suất tốt hơn không.
Khả năng mất dữ liệu
Tôi sẽ đề cập đến vấn đề này vài lần và nhấn mạnh mỗi khi tôi làm vậy: Bạn cần phải chấp nhận việc mất dữ liệu . Dưới một đĩa hoạt động tốt, số tiền tối đa bạn có thể bị mất trong một thảm họa - hoặc thậm chí là tắt máy theo kế hoạch và duyên dáng - là tối đa một khối đầy đủ (60KB). Tuy nhiên, trong trường hợp hệ thống con I / O của bạn không thể theo kịp, có thể bạn sẽ mất nhiều nhất là toàn bộ bộ đệm nhật ký (~ 7MB).
Để làm rõ, từ tài liệu (tôi nhấn mạnh):
Đối với độ bền bị trì hoãn, không có sự khác biệt giữa việc tắt đột ngột và tắt / khởi động lại SQL Server dự kiến . Giống như các sự kiện thảm khốc, bạn nên lập kế hoạch cho việc mất dữ liệu . Trong một kế hoạch tắt / khởi động lại, một số giao dịch chưa được ghi vào đĩa trước tiên có thể được lưu vào đĩa, nhưng bạn không nên lập kế hoạch trên đó. Lập kế hoạch như thể tắt máy / khởi động lại, cho dù có kế hoạch hay ngoài kế hoạch, sẽ mất dữ liệu giống như một sự kiện thảm khốc.Vì vậy, điều rất quan trọng là bạn phải cân nhắc giữa rủi ro mất dữ liệu với nhu cầu của mình để giảm bớt các vấn đề về hiệu suất nhật ký giao dịch. Nếu bạn điều hành một ngân hàng hoặc bất cứ thứ gì liên quan đến tiền, việc di chuyển nhật ký của mình sang đĩa nhanh hơn có thể an toàn và thích hợp hơn nhiều so với việc tung xúc xắc bằng tính năng này. Nếu bạn đang cố gắng cải thiện thời gian phản hồi trong ứng dụng Phòng trò chuyện Web Gamerz của mình, có thể rủi ro sẽ ít nghiêm trọng hơn.
Bạn có thể kiểm soát hành vi này ở một mức độ nào đó để giảm thiểu nguy cơ mất dữ liệu. Bạn có thể buộc tất cả các giao dịch lâu bền bị trì hoãn được chuyển vào đĩa theo một trong hai cách:
- Cam kết mọi giao dịch hoàn toàn lâu dài.
- Gọi
sys.sp_flush_logthủ công.
Điều này cho phép bạn quay lại kiểm soát việc mất dữ liệu về mặt thời gian, thay vì kích thước; chẳng hạn, bạn có thể lên lịch xả 5 giây một lần. Nhưng bạn sẽ muốn tìm thấy điểm ngọt ngào của mình ở đây; xả nước quá thường xuyên có thể bù đắp lợi ích Độ bền bị Trễ ngay từ đầu. Trong mọi trường hợp, bạn vẫn cần phải chấp nhận việc mất dữ liệu , ngay cả khi nó chỉ có giá trị
Bạn sẽ nghĩ rằng CHECKPOINT có thể hữu ích ở đây, nhưng thao tác này thực sự không đảm bảo về mặt kỹ thuật, nhật ký sẽ được chuyển vào đĩa.
Tương tác với HA / DR
Bạn có thể tự hỏi làm thế nào Độ trễ bị trễ hoạt động với các tính năng HA / DR như vận chuyển nhật ký, sao chép và Nhóm sẵn sàng. Với hầu hết những điều này, nó hoạt động không thay đổi. Việc vận chuyển và nhân bản nhật ký sẽ phát lại các bản ghi nhật ký đã được làm cứng, do đó, khả năng mất dữ liệu tương tự cũng tồn tại ở đó. Với AG ở chế độ không đồng bộ, chúng tôi không chờ đợi xác nhận thứ cấp, vì vậy nó sẽ hoạt động giống như ngày hôm nay. Tuy nhiên, với đồng bộ, chúng tôi không thể cam kết trên giao dịch chính cho đến khi giao dịch được cam kết và cố định vào nhật ký từ xa. Ngay cả trong trường hợp đó, chúng tôi có thể có một số lợi ích cục bộ bằng cách không phải đợi ghi nhật ký cục bộ, chúng tôi vẫn phải đợi hoạt động từ xa. Vì vậy, trong kịch bản đó có ít lợi ích hơn, và có khả năng là không; ngoại trừ có lẽ trong một trường hợp hiếm hoi khi đĩa nhật ký của chính thực sự chậm và đĩa nhật ký của phụ thực sự nhanh. Tôi nghi ngờ các điều kiện tương tự cũng đúng đối với phản chiếu đồng bộ / không đồng bộ, nhưng bạn sẽ không nhận được bất kỳ cam kết chính thức nào từ tôi về cách một tính năng mới sáng bóng hoạt động với một tính năng không dùng nữa. :-)
Quan sát Hiệu suất
Đây sẽ không phải là một bài đăng ở đây nếu tôi không hiển thị một số quan sát hiệu suất thực tế. Tôi thiết lập 8 cơ sở dữ liệu để kiểm tra tác động của hai mẫu khối lượng công việc khác nhau với các thuộc tính sau:
- Mô hình khôi phục:đơn giản so với đầy đủ
- Vị trí nhật ký:SSD so với HDD
- Độ bền:bị trì hoãn so với độ bền hoàn toàn
Tôi thực sự, thực sự, thực sự lười biếng hiệu quả về loại điều này. Vì tôi muốn tránh lặp lại các thao tác giống nhau trong mỗi cơ sở dữ liệu, tôi đã tạm thời tạo bảng sau trong model :
USE model; GO CREATE TABLE dbo.TheTable ( TheID INT IDENTITY(1,1) PRIMARY KEY, TheDate DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP, RowGuid UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID() );
Sau đó, tôi đã tạo một tập hợp lệnh SQL động để xây dựng 8 cơ sở dữ liệu này, thay vì tạo các cơ sở dữ liệu riêng lẻ rồi kết hợp với các cài đặt:
-- C and D are SSD, G is HDD
DECLARE @sql NVARCHAR(MAX) = N'';
;WITH l AS (SELECT l FROM (VALUES('D'),('G')) AS l(l)),
r AS (SELECT r FROM (VALUES('FULL'),('SIMPLE')) AS r(r)),
d AS (SELECT d FROM (VALUES('FORCED'),('DISABLED')) AS d(d)),
x AS (SELECT l.l, r.r, d.d, n = CONVERT(CHAR(1),ROW_NUMBER() OVER
(ORDER BY d.d DESC, l.l)) FROM l CROSS JOIN r CROSS JOIN d)
SELECT @sql += N'
CREATE DATABASE dd' + n + ' ON '
+ '(name = ''dd' + n + '_data'','
+ ' filename = ''C:\SQLData\dd' + n + '.mdf'', size = 1024MB)
LOG ON (name = ''dd' + n + '_log'','
+ ' filename = ''' + l + ':\SQLLog\dd' + n + '.ldf'', size = 1024MB);
ALTER DATABASE dd' + n + ' SET RECOVERY ' + r + ';
ALTER DATABASE dd' + n + ' SET DELAYED_DURABILITY = ' + d + ';'
FROM x ORDER BY d, l;
PRINT @sql;
-- EXEC sp_executesql @sql;
Hãy tự chạy mã này (với EXEC vẫn nhận xét ra) để thấy rằng điều này sẽ tạo ra 4 cơ sở dữ liệu với Độ bền trễ bị TẮT (hai trong phục hồi ĐẦY ĐỦ, hai trong SIMPLE, một trong số đó có nhật ký trên đĩa chậm và một trong mỗi cơ sở có nhật ký trên SSD). Lặp lại mô hình đó cho 4 cơ sở dữ liệu có Độ bền trễ bị FORCED - Tôi đã làm điều này để đơn giản hóa mã trong thử nghiệm, thay vì để phản ánh những gì tôi sẽ làm trong cuộc sống thực (nơi tôi có thể muốn coi một số giao dịch là quan trọng và một số như, tốt, ít hơn quan trọng).
Để kiểm tra sự tỉnh táo, tôi đã chạy truy vấn sau để đảm bảo rằng cơ sở dữ liệu có ma trận thuộc tính phù hợp:
SELECT d.name, d.recovery_model_desc, d.delayed_durability_desc, log_disk = CASE WHEN mf.physical_name LIKE N'D%' THEN 'SSD' else 'HDD' END FROM sys.databases AS d INNER JOIN sys.master_files AS mf ON d.database_id = mf.database_id WHERE d.name LIKE N'dd[1-8]' AND mf.[type] = 1; -- log
Kết quả:
| tên | recovery_model | delay_durability | log_disk |
|---|---|---|---|
| dd1 | ĐẦY ĐỦ | BỊ CẮT | SSD |
| dd2 | ĐƠN GIẢN | BỊ CẮT | SSD |
| dd3 | ĐẦY ĐỦ | BỊ CẮT | Ổ cứng |
| dd4 | ĐƠN GIẢN | BỊ CẮT | Ổ cứng |
| dd5 | ĐẦY ĐỦ | BỊ TẮT | SSD |
| dd6 | ĐƠN GIẢN | BỊ TẮT | SSD |
| dd7 | ĐẦY ĐỦ | BỊ TẮT | Ổ cứng |
| dd8 | ĐƠN GIẢN | BỊ TẮT | Ổ cứng |
Cấu hình có liên quan của 8 cơ sở dữ liệu thử nghiệm
Tôi cũng đã chạy thử nghiệm nhiều lần để đảm bảo rằng tệp dữ liệu 1 GB và tệp nhật ký 1 GB sẽ đủ để chạy toàn bộ khối lượng công việc mà không đưa bất kỳ sự kiện tự động phát triển nào vào phương trình. Như một phương pháp hay nhất, tôi thường cố gắng đảm bảo hệ thống của khách hàng có đủ không gian được phân bổ (và các cảnh báo thích hợp được tích hợp sẵn) để không có sự kiện tăng trưởng nào xảy ra vào thời điểm không mong muốn. Trong thế giới thực, tôi biết điều này không phải lúc nào cũng xảy ra, nhưng đó là điều lý tưởng.
Tôi thiết lập hệ thống được giám sát bằng SQL Sentry - điều này sẽ cho phép tôi dễ dàng hiển thị hầu hết các số liệu hiệu suất mà tôi muốn làm nổi bật. Nhưng tôi cũng đã tạo một bảng tạm thời để lưu trữ số liệu hàng loạt bao gồm thời lượng và đầu ra rất cụ thể từ sys.dm_io_virtual_file_stats:
SELECT test = 1, cycle = 1, start_time = GETDATE(), *
INTO #Metrics
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2) WHERE 1 = 0; Điều này sẽ cho phép tôi ghi lại thời gian bắt đầu và kết thúc của từng lô riêng lẻ và đo các delta trong DMV giữa thời gian bắt đầu và thời gian kết thúc (chỉ đáng tin cậy trong trường hợp này vì tôi biết mình là người dùng duy nhất trên hệ thống).
Rất nhiều giao dịch nhỏ
Thử nghiệm đầu tiên tôi muốn thực hiện là rất nhiều giao dịch nhỏ. Đối với mỗi cơ sở dữ liệu, tôi muốn kết thúc với 500.000 lô riêng biệt với mỗi phần chèn duy nhất:
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
Hãy nhớ rằng, tôi cố gắng lười biếng hiệu quả về loại điều này. Vì vậy, để tạo mã cho tất cả 8 cơ sở dữ liệu, tôi đã chạy điều này:
;WITH x AS
(
SELECT TOP (8) number FROM master..spt_values
WHERE type = N'P' ORDER BY number
)
SELECT CONVERT(NVARCHAR(MAX), N'') + N'
INSERT #Metrics SELECT 1, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);
GO
INSERT dbo.TheTable DEFAULT VALUES;
GO 500000
INSERT #Metrics SELECT 1, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Tôi đã chạy thử nghiệm này và sau đó xem xét #Metrics bảng với truy vấn sau:
SELECT
[database] = db_name(m1.database_id),
num_writes = m2.num_of_writes - m1.num_of_writes,
write_bytes = m2.num_of_bytes_written - m1.num_of_bytes_written,
bytes_per_write = (m2.num_of_bytes_written - m1.num_of_bytes_written)*1.0
/(m2.num_of_writes - m1.num_of_writes),
io_stall_ms = m2.io_stall_write_ms - m1.io_stall_write_ms,
m1.start_time,
end_time = m2.start_time,
duration = DATEDIFF(SECOND, m1.start_time, m2.start_time)
FROM #Metrics AS m1
INNER JOIN #Metrics AS m2
ON m1.database_id = m2.database_id
WHERE m1.cycle = 1 AND m2.cycle = 2
AND m1.test = 1 AND m2.test = 1; Điều này mang lại các kết quả sau (và tôi đã xác nhận qua nhiều thử nghiệm rằng các kết quả là nhất quán):
| cơ sở dữ liệu | viết | byte | byte / ghi | io_stall_ms | start_time | end_time | thời lượng (giây) |
|---|---|---|---|---|---|---|---|
| dd1 | 8.068 | 261.894.656 | 32.460,91 | 6.232 | 2014-04-26 17:20:00 | 2014-04-26 17:21:08 | 68 |
| dd2 | 8.072 | 261.682.688 | 32.418,56 | 2.740 | 2014-04-26 17:21:08 | 2014-04-26 17:22:16 | 68 |
| dd3 | 8.246 | 262.254.592 | 31.803,85 | 3.996 | 2014-04-26 17:22:16 | 2014-04-26 17:23:24 | 68 |
| dd4 | 8.055 | 261.688.320 | 32.487,68 | 4,231 | 2014-04-26 17:23:24 | 2014-04-26 17:24:32 | 68 |
| dd5 | 500.012 | 526.448.640 | 1.052,87 | 35.593 | 2014-04-26 17:24:32 | 2014-04-26 17:26:32 | 120 |
| dd6 | 500.014 | 525.870.080 | 1.051,71 | 35.435 | 2014-04-26 17:26:32 | 2014-04-26 17:28:31 | 119 |
| dd7 | 500.015 | 526.120.448 | 1,052,20 | 50,857 | 2014-04-26 17:28:31 | 2014-04-26 17:30:45 | 134 |
| dd8 | 500.017 | 525.886.976 | 1.051,73 | 49.680 | | | 133 |
Các giao dịch nhỏ:Thời lượng và kết quả từ sys.dm_io_virtual_file_stats
Chắc chắn là một số quan sát thú vị ở đây:
- Số lượng các thao tác ghi riêng lẻ là rất nhỏ đối với cơ sở dữ liệu Độ bền bị Trễ (~ 60X đối với truyền thống).
- Tổng số byte được viết đã bị cắt giảm một nửa bằng cách sử dụng Độ bền trễ (tôi đoán là vì tất cả các lần ghi trong trường hợp truyền thống đều chứa rất nhiều không gian lãng phí).
- Số byte mỗi lần ghi cao hơn rất nhiều đối với Độ bền bị Trễ. Điều này không quá ngạc nhiên vì toàn bộ mục đích của tính năng này là tập hợp các bài viết lại với nhau thành các lô lớn hơn.
- Tổng thời lượng của các gian hàng I / O có thể thay đổi, nhưng gần như thấp hơn về độ lớn đối với Độ bền bị trì hoãn. Các quầy giao dịch hoàn toàn lâu bền nhạy cảm hơn nhiều với loại đĩa.
- Nếu cho đến nay vẫn chưa thuyết phục được bạn, thì cột thời lượng sẽ rất hữu ích. Các mẻ hoàn toàn bền mất từ hai phút trở lên được cắt gần một nửa.
Các cột thời gian bắt đầu / kết thúc cho phép tôi tập trung vào trang tổng quan Cố vấn hiệu suất trong khoảng thời gian chính xác nơi các giao dịch này đang diễn ra, nơi chúng tôi có thể vẽ thêm rất nhiều chỉ báo trực quan:
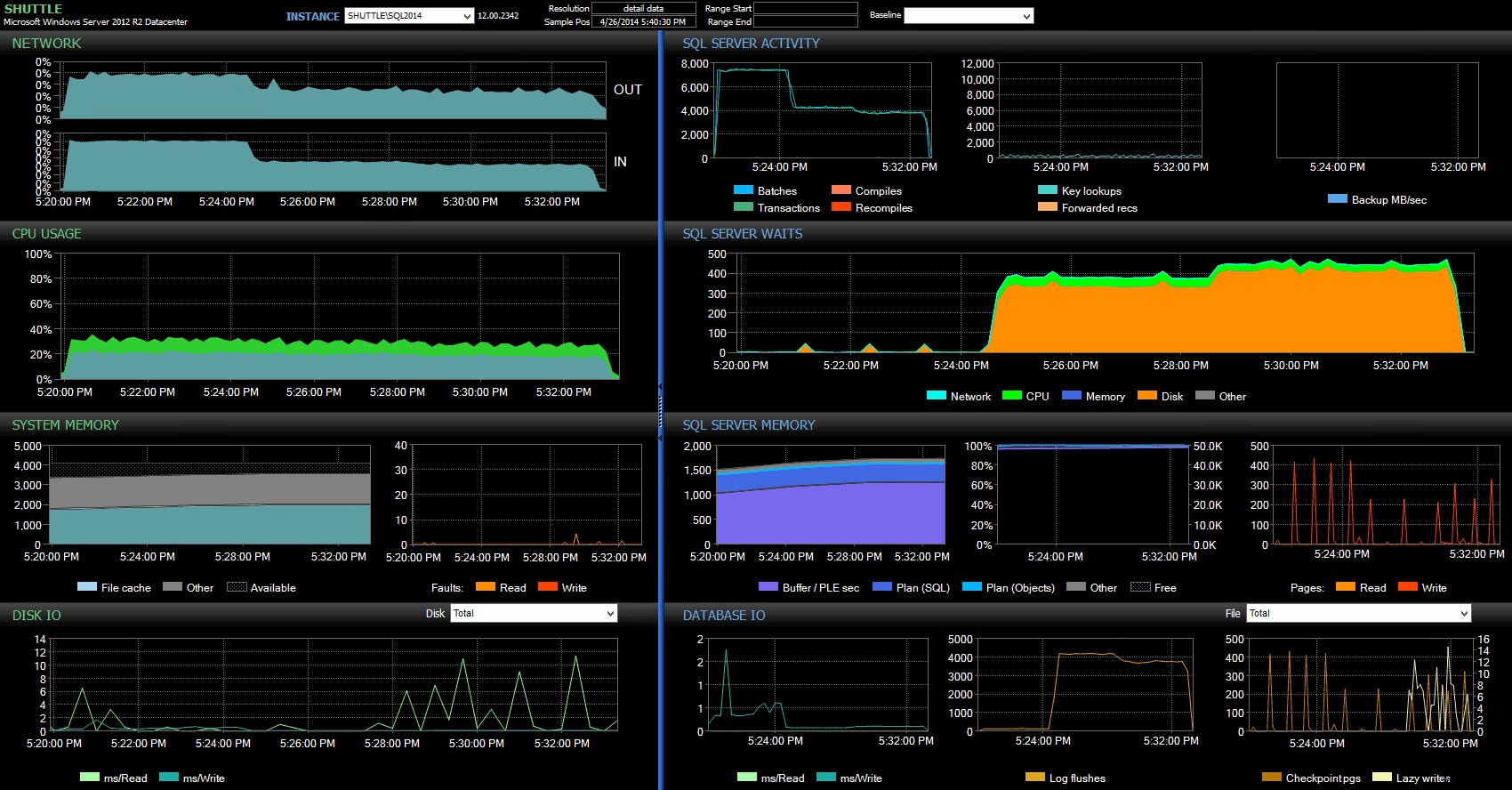
Bảng điều khiển SQL Sentry - nhấp để phóng to
Các quan sát thêm tại đây:
- Trên một số biểu đồ, bạn có thể thấy rõ chính xác khi nào phần Độ bền không bị trì hoãn của lô được tiếp nhận (~ 5:24:32 CH).
- Không có tác động nào có thể quan sát được đối với CPU hoặc bộ nhớ khi sử dụng Độ bền bị trễ.
- Bạn có thể thấy tác động to lớn đến các lô / giao dịch mỗi giây trong biểu đồ đầu tiên trong Hoạt động máy chủ SQL.
- SQL Server chờ đợi thông qua mái nhà khi các giao dịch hoàn toàn bền vững bắt đầu. Chúng hầu như chỉ bao gồm
WRITELOGđang đợi, với một số lượng nhỏPAGEIOLOATCH_EXvàPAGEIOLATCH_UPchờ biện pháp tốt.
Ít giao dịch hơn, lớn hơn
Đối với thử nghiệm tiếp theo, tôi muốn xem điều gì sẽ xảy ra nếu chúng tôi thực hiện ít thao tác hơn, nhưng đảm bảo rằng mỗi câu lệnh sẽ ảnh hưởng đến lượng dữ liệu lớn hơn. Tôi muốn lô này chạy trên từng cơ sở dữ liệu:
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.Rnd AS r
ON t.TheID = r.TheID
WHERE r.batch = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.Rnd WHERE batch = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.Rnd WHERE batch = 3);
GO
INSERT #Metrics SELECT 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID('dd1'), 2); Vì vậy, một lần nữa, tôi đã sử dụng phương pháp lazy để tạo ra 8 bản sao của tập lệnh này, một bản cho mỗi cơ sở dữ liệu:
;WITH x AS (SELECT TOP (8) number FROM master..spt_values WHERE type = N'P' ORDER BY number)
SELECT N'
USE dd' + RTRIM(Number+1) + ';
GO
CREATE TABLE dbo.Rnd
(
batch TINYINT,
TheID INT
);
INSERT dbo.Rnd SELECT TOP (1000) 1, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (10) 2, TheID FROM dbo.TheTable ORDER BY NEWID();
INSERT dbo.Rnd SELECT TOP (300) 3, TheID FROM dbo.TheTable ORDER BY NEWID();
GO
INSERT #Metrics SELECT 2, 1, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + ''', 2);
GO
UPDATE t SET TheDate = DATEADD(MINUTE, 1, TheDate)
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 1;
GO 10000
UPDATE t SET RowGuid = NEWID()
FROM dbo.TheTable AS t
INNER JOIN dbo.rnd AS r
ON t.TheID = r.TheID
WHERE r.cycle = 2;
GO 10000
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID+1 FROM dbo.rnd WHERE cycle = 3);
DELETE dbo.TheTable WHERE TheID IN (SELECT TheID-1 FROM dbo.rnd WHERE cycle = 3);
GO
INSERT #Metrics SELECT 2, 2, GETDATE(), *
FROM sys.dm_io_virtual_file_stats(DB_ID(''dd' + RTRIM(number+1) + '''), 2);'
FROM x;
Tôi đã chạy lô này, sau đó thay đổi truy vấn đối với #Metrics ở trên để xem xét thử nghiệm thứ hai thay vì thử nghiệm đầu tiên. Kết quả:
| cơ sở dữ liệu | viết | byte | byte / ghi | io_stall_ms | start_time | end_time | thời lượng (giây) |
|---|---|---|---|---|---|---|---|
| dd1 | 20,970 | 1.271.911.936 | 60,653.88 | 12.577 | 2014-04-26 17:41:21 | 2014-04-26 17:43:46 | 145 |
| dd2 | 20.997 | 1.272.145.408 | 60.587,00 | 14.698 | 2014-04-26 17:43:46 | 2014-04-26 17:46:11 | 145 |
| dd3 | 20,973 | 1.272.982.016 | 60.696,22 | 12.085 | 2014-04-26 17:46:11 | 2014-04-26 17:48:33 | 142 |
| dd4 | 20,958 | 1.272.064.512 | 60.695,89 | 11.795 | | | 143 |
| dd5 | 30.138 | 1,282,231,808 | 42.545,35 | 7.402 | 2014-04-26 17:50:56 | 2014-04-26 17:53:23 | 147 |
| dd6 | 30.138 | 1.282.260.992 | 42.546,31 | 7.806 | 2014-04-26 17:53:23 | 2014-04-26 17:55:53 | 150 |
| dd7 | 30.129 | 1.281.575.424 | 42.536,27 | 9.888 | 2014-04-26 17:55:53 | 2014-04-26 17:58:25 | 152 |
| dd8 | 30.130 | 1.281.449.472 | 42.530,68 | 11.452 | 2014-04-26 17:58:25 | 2014-04-26 18:00:55 | 150 |
Giao dịch lớn hơn:Thời lượng và kết quả từ sys.dm_io_virtual_file_stats
Lần này, tác động của Độ bền trễ ít được chú ý hơn nhiều. Chúng tôi thấy số lượng thao tác ghi ít hơn một chút, với số byte mỗi lần ghi lớn hơn một chút, với tổng số byte được viết gần như giống hệt nhau. Trong trường hợp này, chúng tôi thực sự thấy các gian hàng I / O cao hơn đối với Độ bền bị trễ và điều này có thể giải thích cho thực tế là các khoảng thời gian gần như giống hệt nhau.
Từ bảng điều khiển Cố vấn hiệu suất, chúng tôi có một số điểm tương đồng với thử nghiệm trước và một số điểm khác biệt rõ rệt:
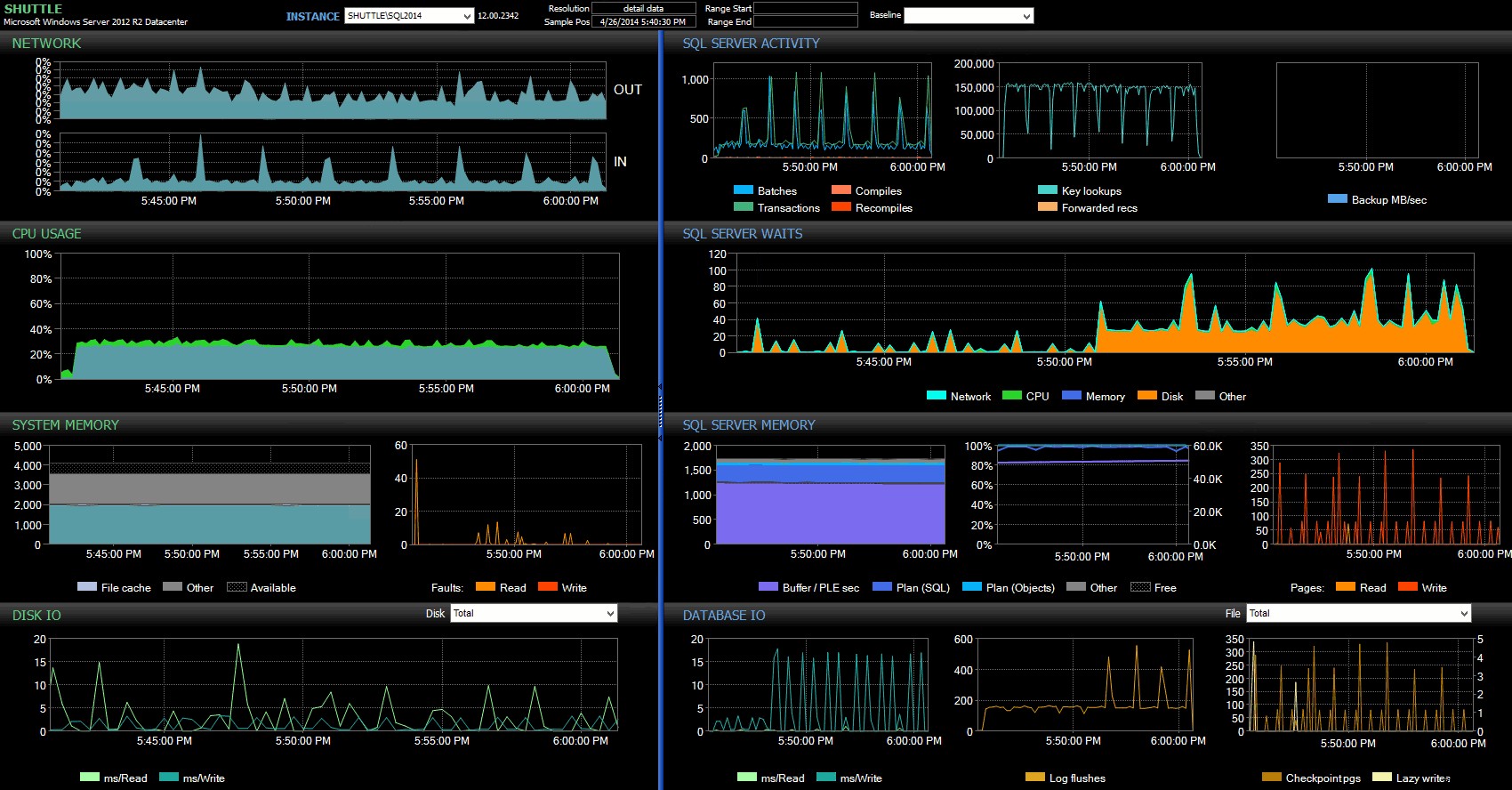
Bảng điều khiển SQL Sentry - nhấp để phóng to
Một trong những điểm khác biệt lớn cần chỉ ra ở đây là số liệu thống kê về delta trong thời gian chờ không rõ rệt như với thử nghiệm trước - vẫn có tần suất WRITELOG cao hơn nhiều chờ đợi các lô hoàn toàn lâu bền, nhưng không ở gần mức được thấy với các giao dịch nhỏ hơn. Một điều khác mà bạn có thể nhận ra ngay lập tức là tác động được quan sát trước đây đối với các lô và giao dịch mỗi giây không còn nữa. Và cuối cùng, mặc dù có nhiều lần đổ nhật ký hơn với các giao dịch hoàn toàn lâu bền so với khi bị trì hoãn, sự chênh lệch này ít rõ rệt hơn so với các giao dịch nhỏ hơn.
Kết luận
Cần phải rõ rằng có một số loại khối lượng công việc nhất định có thể được hưởng lợi rất nhiều từ Độ bền bị trễ - tất nhiên, miễn là bạn có khả năng chịu đựng việc mất dữ liệu . Tính năng này không bị giới hạn đối với OLTP trong bộ nhớ, có sẵn trên tất cả các phiên bản của SQL Server 2014 và có thể được triển khai với ít hoặc không có thay đổi mã. Nó chắc chắn có thể là một kỹ thuật mạnh mẽ nếu khối lượng công việc của bạn có thể hỗ trợ nó. Tuy nhiên, một lần nữa, bạn sẽ cần phải kiểm tra khối lượng công việc của mình để chắc chắn rằng nó sẽ được hưởng lợi từ tính năng này và cũng cần cân nhắc kỹ lưỡng xem điều này có làm tăng nguy cơ mất dữ liệu của bạn hay không.
Ngoài ra, điều này đối với đám đông SQL Server có vẻ như là một ý tưởng mới mẻ, nhưng sự thật thì Oracle đã giới thiệu đây là "Cam kết không đồng bộ" vào năm 2006 (xem COMMIT WRITE ... NOWAIT như được ghi lại ở đây và được viết trên blog vào năm 2007). Và bản thân ý tưởng đã có gần 3 thập kỷ; xem biên niên sử ngắn gọn của Hal Berenson về lịch sử của nó.
Lần tới
Một ý tưởng mà tôi đã đề cập là cố gắng cải thiện hiệu suất của tempdb bằng cách buộc Độ bền bị hoãn ở đó. Một thuộc tính đặc biệt của tempdb khiến nó trở thành một ứng cử viên hấp dẫn vì bản chất nó chỉ là thoáng qua - bất cứ thứ gì trong tempdb được thiết kế, rõ ràng, để có thể lật được sau nhiều sự kiện hệ thống. Tôi đang nói điều này ngay bây giờ mà không có bất kỳ ý tưởng nào nếu có một hình dạng khối lượng công việc mà điều này sẽ hoạt động tốt; nhưng tôi dự định sẽ dùng thử, và nếu tôi thấy bất kỳ điều gì thú vị, bạn có thể chắc chắn rằng tôi sẽ đăng về nó ở đây.