Minh chứng cho lời giải thích khả thi.
Tạo tập lệnh bảng
SELECT *
INTO #T
FROM master.dbo.spt_values
CREATE NONCLUSTERED INDEX [IX_T] ON #T ([name] DESC,[number] DESC);
Truy vấn một (Trả về 35 kết quả)
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Truy vấn thứ hai (Tương tự như trước đây nhưng thêm c2. [type] vào danh sách chọn khiến nó trả về 0 kết quả) ;
WITH cte AS
(
SELECT *, ROW_NUMBER() OVER (ORDER BY NAME) AS rn
FROM #T
)
SELECT c1.number,c1.[type] ,c2.[type]
FROM cte c1
JOIN cte c2 ON c1.rn=c2.rn AND c1.number <> c2.number
Tại sao?
row_number () cho các NAME trùng lặp không được chỉ định vì vậy nó chỉ chọn bất kỳ cái nào phù hợp với kế hoạch thực thi tốt nhất cho các cột đầu ra được yêu cầu. Trong truy vấn thứ hai, điều này giống nhau đối với cả hai lệnh gọi cte, trong truy vấn đầu tiên, nó chọn một đường dẫn truy cập khác với kết quả là row_numbering khác nhau.
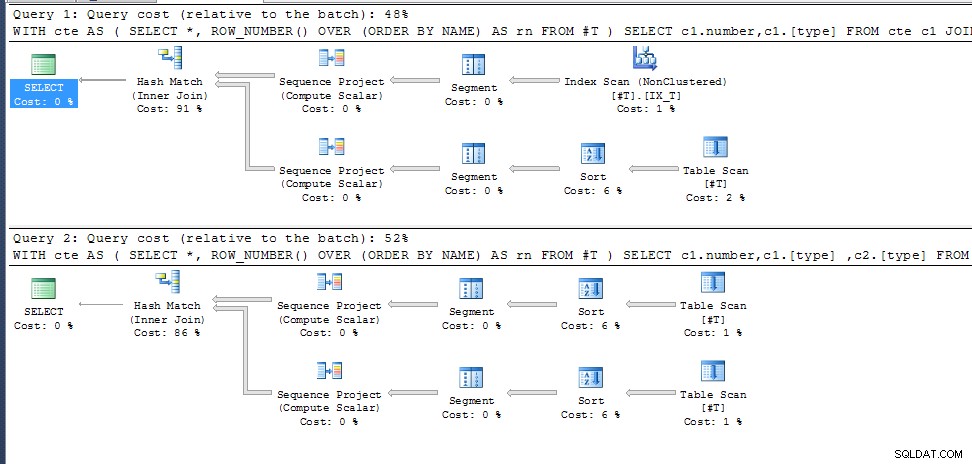
Giải pháp được đề xuất
Bạn đang tự tham gia CTE trên ROW_NUMBER() over (order by t.[Date])
Trái ngược với những gì có thể mong đợi, CTE có thể sẽ không được hiện thực hóa
điều này sẽ đảm bảo tính nhất quán cho tự kết hợp và do đó bạn giả sử có mối tương quan giữa ROW_NUMBER() ở cả hai mặt mà có thể không tồn tại đối với các bản ghi có [Date] trùng lặp tồn tại trong dữ liệu.
Điều gì sẽ xảy ra nếu bạn thử ROW_NUMBER() over (order by t.[Date], t.[id]) để đảm bảo rằng trong trường hợp các ngày bị ràng buộc, đánh số hàng theo thứ tự nhất quán được đảm bảo. (Hoặc một số cột / tổ hợp cột khác có thể phân biệt các bản ghi nếu id không thực hiện được)