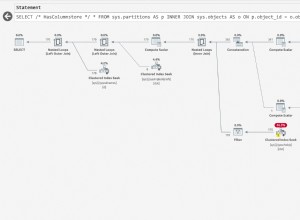
Tôi đã thử một vài SELECT COUNT(*) FROM MyTable so với SELECT COUNT(SomeColumn) FROM MyTable với nhiều kích thước bảng khác nhau và nơi SomeColumn một lần là cột khóa phân cụm, một khi nó nằm trong chỉ mục không phân cụm và một khi nó không nằm trong chỉ mục nào cả.
Trong mọi trường hợp, với tất cả các kích thước của bảng (từ 300000 hàng đến 170 triệu hàng), tôi không bao giờ thấy bất kỳ sự khác biệt nào về tốc độ cũng như kế hoạch thực thi - trong mọi trường hợp, COUNT được xử lý bằng cách thực hiện quét chỉ mục theo cụm -> về cơ bản, tức là quét toàn bộ bảng. Nếu có liên quan đến chỉ mục không phân cụm, thì quá trình quét sẽ nằm trên chỉ mục đó - ngay cả khi thực hiện SELECT COUNT(*) !
Dường như không có bất kỳ sự khác biệt nào về tốc độ hoặc cách tiếp cận cách đếm những thứ đó - để đếm tất cả, SQL Server chỉ cần quét toàn bộ bảng - khoảng thời gian.
Các thử nghiệm đã được thực hiện trên SQL Server 2008 R2 Developer Edition