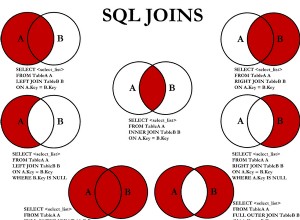
Trình tối ưu hóa SQL Server không chứa logic để loại bỏ các liên kết thừa, nhưng có những hạn chế và các liên kết phải có thể dư thừa . Tóm lại, một phép nối có thể có bốn tác dụng:
- Nó có thể thêm các cột bổ sung (từ bảng đã kết hợp)
- Nó có thể thêm các hàng bổ sung (bảng đã kết hợp có thể khớp với một hàng nguồn nhiều hơn một lần)
- Nó có thể xóa các hàng (bảng đã tham gia có thể không khớp)
- Nó có thể giới thiệu
NULLs (cho mộtRIGHThoặcFULL JOIN)
Để loại bỏ thành công một phép nối thừa, truy vấn (hoặc chế độ xem) phải tính đến cả bốn khả năng. Khi điều này được thực hiện một cách chính xác, hiệu quả có thể đáng kinh ngạc. Ví dụ:
USE AdventureWorks2012;
GO
CREATE VIEW dbo.ComplexView
AS
SELECT
pc.ProductCategoryID, pc.Name AS CatName,
ps.ProductSubcategoryID, ps.Name AS SubCatName,
p.ProductID, p.Name AS ProductName,
p.Color, p.ListPrice, p.ReorderPoint,
pm.Name AS ModelName, pm.ModifiedDate
FROM Production.ProductCategory AS pc
FULL JOIN Production.ProductSubcategory AS ps ON
ps.ProductCategoryID = pc.ProductCategoryID
FULL JOIN Production.Product AS p ON
p.ProductSubcategoryID = ps.ProductSubcategoryID
FULL JOIN Production.ProductModel AS pm ON
pm.ProductModelID = p.ProductModelID
Trình tối ưu hóa có thể đơn giản hóa thành công truy vấn sau:
SELECT
c.ProductID,
c.ProductName
FROM dbo.ComplexView AS c
WHERE
c.ProductName LIKE N'G%';
Tới:

Rob Farley đã viết chuyên sâu về những ý tưởng này trong cuốn sách Ban đầu của MVP Deep Dives và có một ghi lại cảnh anh ấy trình bày về chủ đề này tại SQLBits.
Các hạn chế chính là mối quan hệ khóa ngoại phải dựa trên một khóa duy nhất để đóng góp vào quá trình đơn giản hóa và thời gian biên dịch cho các truy vấn đối với chế độ xem như vậy có thể trở nên khá lâu, đặc biệt là khi số lượng liên kết tăng lên. Nó có thể là một thách thức khá lớn để viết một chế độ xem 100 bảng có tất cả các ngữ nghĩa chính xác. Tôi có xu hướng tìm một giải pháp thay thế, có lẽ bằng cách sử dụng SQL động .
Điều đó nói rằng, các chất lượng cụ thể của bảng không chuẩn hóa của bạn có thể có nghĩa là chế độ xem khá đơn giản để lắp ráp, chỉ yêu cầu FOREIGN KEYs được thực thi non- NULL các cột có thể tham chiếu và UNIQUE thích hợp các ràng buộc để làm cho giải pháp này hoạt động như bạn mong đợi, mà không có chi phí của 100 toán tử kết hợp vật lý trong kế hoạch.
Ví dụ
Sử dụng mười bảng thay vì một trăm bảng:
-- Referenced tables
CREATE TABLE dbo.Ref01 (col01 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref02 (col02 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref03 (col03 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref04 (col04 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref05 (col05 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref06 (col06 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref07 (col07 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref08 (col08 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref09 (col09 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
CREATE TABLE dbo.Ref10 (col10 tinyint PRIMARY KEY, item varchar(50) NOT NULL UNIQUE);
Định nghĩa bảng mẹ (với nén trang):
CREATE TABLE dbo.Normalized
(
pk integer IDENTITY NOT NULL,
col01 tinyint NOT NULL REFERENCES dbo.Ref01,
col02 tinyint NOT NULL REFERENCES dbo.Ref02,
col03 tinyint NOT NULL REFERENCES dbo.Ref03,
col04 tinyint NOT NULL REFERENCES dbo.Ref04,
col05 tinyint NOT NULL REFERENCES dbo.Ref05,
col06 tinyint NOT NULL REFERENCES dbo.Ref06,
col07 tinyint NOT NULL REFERENCES dbo.Ref07,
col08 tinyint NOT NULL REFERENCES dbo.Ref08,
col09 tinyint NOT NULL REFERENCES dbo.Ref09,
col10 tinyint NOT NULL REFERENCES dbo.Ref10,
CONSTRAINT PK_Normalized
PRIMARY KEY CLUSTERED (pk)
WITH (DATA_COMPRESSION = PAGE)
);
Chế độ xem:
CREATE VIEW dbo.Denormalized
WITH SCHEMABINDING AS
SELECT
item01 = r01.item,
item02 = r02.item,
item03 = r03.item,
item04 = r04.item,
item05 = r05.item,
item06 = r06.item,
item07 = r07.item,
item08 = r08.item,
item09 = r09.item,
item10 = r10.item
FROM dbo.Normalized AS n
JOIN dbo.Ref01 AS r01 ON r01.col01 = n.col01
JOIN dbo.Ref02 AS r02 ON r02.col02 = n.col02
JOIN dbo.Ref03 AS r03 ON r03.col03 = n.col03
JOIN dbo.Ref04 AS r04 ON r04.col04 = n.col04
JOIN dbo.Ref05 AS r05 ON r05.col05 = n.col05
JOIN dbo.Ref06 AS r06 ON r06.col06 = n.col06
JOIN dbo.Ref07 AS r07 ON r07.col07 = n.col07
JOIN dbo.Ref08 AS r08 ON r08.col08 = n.col08
JOIN dbo.Ref09 AS r09 ON r09.col09 = n.col09
JOIN dbo.Ref10 AS r10 ON r10.col10 = n.col10;
Đánh cắp số liệu thống kê để làm cho trình tối ưu hóa nghĩ rằng bảng rất lớn:
UPDATE STATISTICS dbo.Normalized WITH ROWCOUNT = 100000000, PAGECOUNT = 5000000;
Truy vấn người dùng mẫu:
SELECT
d.item06,
d.item07
FROM dbo.Denormalized AS d
WHERE
d.item08 = 'Banana'
AND d.item01 = 'Green';
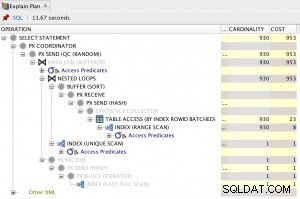
Cung cấp cho chúng tôi kế hoạch thực hiện này:
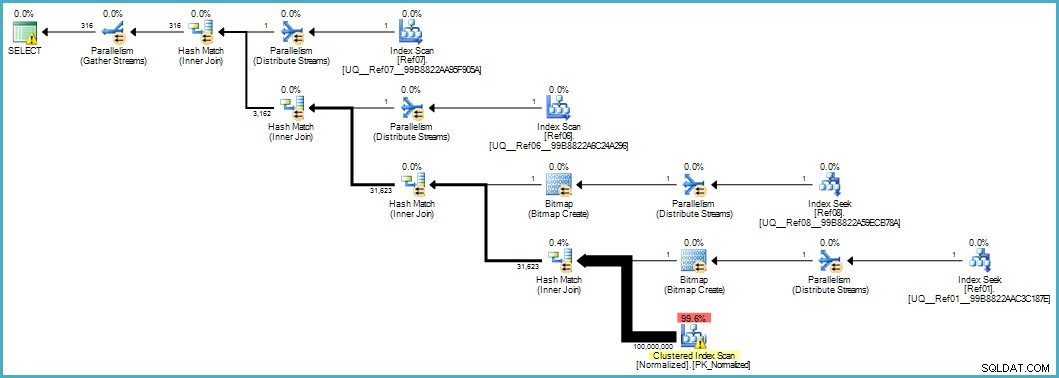
Quá trình quét bảng Chuẩn hóa trông có vẻ tệ, nhưng cả hai bản đồ bitmap của bộ lọc Bloom đều được áp dụng trong quá trình quét bởi công cụ lưu trữ (vì vậy các hàng không khớp thậm chí không hiển thị xa như bộ xử lý truy vấn). Điều này có thể đủ để mang lại hiệu suất có thể chấp nhận được trong trường hợp của bạn và chắc chắn tốt hơn so với việc quét bảng gốc với các cột tràn của nó.
Nếu bạn có thể nâng cấp lên SQL Server 2012 Enterprise ở một số giai đoạn, bạn có một tùy chọn khác:tạo chỉ mục lưu trữ cột trên bảng Chuẩn hóa:
CREATE NONCLUSTERED COLUMNSTORE INDEX cs
ON dbo.Normalized (col01,col02,col03,col04,col05,col06,col07,col08,col09,col10);
Kế hoạch thực hiện là:
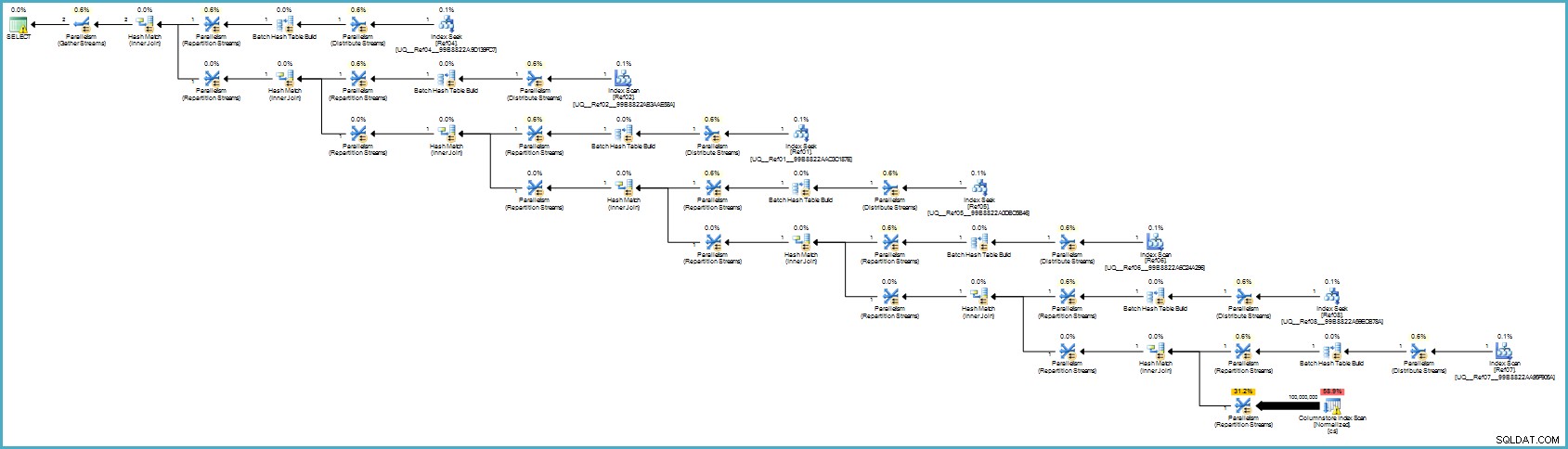
Điều đó có thể trông tệ hơn đối với bạn, nhưng lưu trữ cột cung cấp khả năng nén đặc biệt và toàn bộ kế hoạch thực thi chạy ở Chế độ hàng loạt với bộ lọc cho tất cả các cột đóng góp. Nếu máy chủ có đủ luồng và bộ nhớ, giải pháp thay thế này thực sự có thể hoạt động.
Cuối cùng, tôi không chắc việc chuẩn hóa này là cách tiếp cận chính xác khi xét đến số lượng bảng và khả năng nhận được một kế hoạch thực thi kém hoặc yêu cầu quá nhiều thời gian biên dịch. Tôi có thể sẽ sửa giản đồ của bảng không chuẩn hóa trước (các kiểu dữ liệu thích hợp, v.v.), có thể áp dụng nén dữ liệu ... những điều thông thường.
Nếu dữ liệu thực sự thuộc về lược đồ hình sao, nó có thể cần nhiều công việc thiết kế hơn là chỉ tách các phần tử dữ liệu lặp lại thành các bảng riêng biệt.