Các từ khá logic và bạn sẽ học chúng khá nhanh. :)
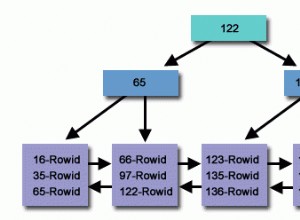
Theo thuật ngữ của giáo dân, SEEK ngụ ý tìm kiếm các vị trí chính xác cho các bản ghi, đó là những gì Máy chủ SQL thực hiện khi cột bạn đang tìm kiếm được lập chỉ mục và bộ lọc của bạn (điều kiện WHERE) đủ tích lũy.
SCAN có nghĩa là một phạm vi hàng lớn hơn trong đó công cụ lập kế hoạch thực thi truy vấn ước tính việc tìm nạp toàn bộ phạm vi nhanh hơn thay vì tìm kiếm từng giá trị riêng lẻ.
Và vâng, bạn có thể có nhiều chỉ mục trên cùng một trường, và đôi khi đó có thể là một ý tưởng rất hay. Chơi với các chỉ mục và sử dụng công cụ lập kế hoạch thực thi truy vấn để xác định điều gì sẽ xảy ra (phím tắt trong SSMS:Ctrl + M). Bạn thậm chí có thể chạy hai phiên bản của cùng một truy vấn và công cụ lập kế hoạch thực thi sẽ dễ dàng hiển thị cho bạn lượng tài nguyên và thời gian được sử dụng cho mỗi phiên bản, làm cho việc tối ưu hóa trở nên khá dễ dàng.
Nhưng để mở rộng những điều này một chút, giả sử bạn có một bảng địa chỉ như vậy và nó có hơn 1 tỷ bản ghi:
CREATE TABLE ADDRESS
(ADDRESS_ID INT -- CLUSTERED primary key ADRESS_PK_IDX
, PERSON_ID INT -- FOREIGN KEY, NONCLUSTERED INDEX ADDRESS_PERSON_IDX
, CITY VARCHAR(256)
, MARKED_FOR_CHECKUP BIT
, **+n^10 different other columns...**)
Bây giờ, nếu bạn muốn tìm tất cả thông tin địa chỉ của người 12345, chỉ mục trên PERSON_ID là hoàn hảo. Vì bảng có vô số dữ liệu khác trên cùng một hàng, sẽ không hiệu quả và tốn không gian để tạo chỉ mục không phân biệt để bao gồm tất cả các cột khác cũng như PERSON_ID. Trong trường hợp này, SQL Server sẽ thực thi một chỉ mục SEEK trên chỉ mục trong PERSON_ID, sau đó sử dụng chỉ mục đó để thực hiện Tra cứu khóa trên chỉ mục được nhóm trong ADDRESS_ID và từ đó trả về tất cả dữ liệu trong tất cả các cột khác trên cùng hàng đó.
Tuy nhiên, giả sử bạn muốn tìm kiếm tất cả những người trong một thành phố, nhưng bạn không cần thông tin địa chỉ khác. Lần này, cách hiệu quả nhất là tạo chỉ mục trên CITY và sử dụng tùy chọn INCLUDE để bao gồm cả PERSON_ID. Bằng cách đó, một lần tìm kiếm / quét chỉ mục sẽ trả về tất cả thông tin bạn cần mà không cần phải kiểm tra chỉ mục CLUSTERED cho dữ liệu PERSON_ID trên cùng một hàng.
Bây giờ, giả sử cả hai truy vấn đó đều được yêu cầu nhưng vẫn khá nặng do có 1 tỷ bản ghi. Nhưng có một truy vấn đặc biệt cần phải thực sự nhanh. Truy vấn đó muốn tất cả những người có địa chỉ đã được MARKED_FOR_CHECKUP và những người phải sống ở New York (bỏ qua bất kỳ ý nghĩa kiểm tra nào, điều đó không quan trọng). Bây giờ, bạn có thể muốn tạo chỉ mục thứ ba, được lọc trên MARKED_FOR_CHECKUP và CITY, với BAO GỒM bao gồm PERSON_ID và với bộ lọc có nội dung CITY ='New York' và MARKED_FOR_CHECKUP =1. Chỉ mục này sẽ cực kỳ nhanh, vì nó chỉ bao gồm các truy vấn đáp ứng các điều kiện chính xác đó và do đó có một phần nhỏ dữ liệu phải đi qua so với các chỉ mục khác.
(Tuyên bố từ chối trách nhiệm ở đây, hãy nhớ rằng công cụ lập kế hoạch thực thi truy vấn không ngu ngốc, nó có thể sử dụng nhiều chỉ mục không phân biệt với nhau để tạo ra kết quả chính xác, vì vậy các ví dụ trên có thể không phải là những ví dụ tốt nhất có sẵn vì rất khó hình dung khi nào bạn cần 3 chỉ mục khác nhau bao gồm cùng một cột, nhưng tôi chắc rằng bạn hiểu rõ.)
Các loại chỉ mục, cột của chúng, cột được bao gồm, thứ tự sắp xếp, bộ lọc, v.v. phụ thuộc hoàn toàn vào tình huống. Bạn sẽ cần tạo các chỉ mục bao trùm để đáp ứng một số loại truy vấn khác nhau, cũng như các chỉ mục tùy chỉnh được tạo riêng cho các truy vấn quan trọng, đơn lẻ. Mỗi chỉ mục chiếm dung lượng trên ổ cứng nên việc tạo các chỉ mục vô dụng là lãng phí và cần bảo trì thêm bất cứ khi nào mô hình dữ liệu thay đổi, đồng thời lãng phí thời gian trong các hoạt động chống phân mảnh và cập nhật thống kê ... vì vậy bạn không muốn chỉ dùng một chỉ mục trên mọi thứ một trong hai.
Thử nghiệm, tìm hiểu và tìm ra cách nào phù hợp nhất với nhu cầu của bạn.