Chi phí cây con nên được tính với một lượng muối lớn (và đặc biệt là như vậy khi bạn có sai số lớn về số lượng). SET STATISTICS IO ON; SET STATISTICS TIME ON; đầu ra là một chỉ báo tốt hơn về hiệu suất thực tế.
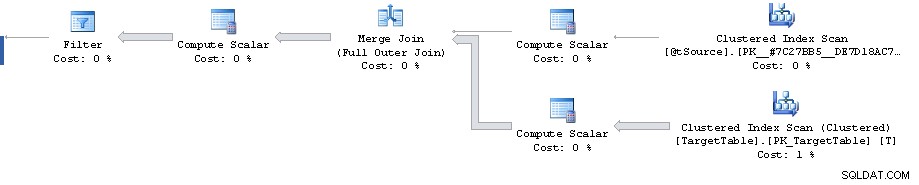
Sắp xếp hàng 0 không chiếm 87% tài nguyên. Vấn đề này trong kế hoạch của bạn là một trong những ước tính thống kê. Các chi phí thể hiện trong kế hoạch thực tế vẫn là chi phí ước tính. Nó không điều chỉnh chúng để tính đến những gì thực sự đã xảy ra.
Có một điểm trong kế hoạch mà bộ lọc giảm 1.911.721 hàng xuống 0 nhưng số hàng ước tính trong tương lai là 1.860.310. Sau đó, tất cả các chi phí đều không có thật với đỉnh điểm là chi phí ước tính 87% là 3.348.560 hàng loại.
Lỗi ước tính bản số có thể được sao chép bên ngoài Merge tuyên bố bằng cách xem kế hoạch ước tính cho Full Outer Join với các vị từ tương đương (đưa ra ước tính 1.860.310 hàng giống nhau).
SELECT *
FROM TargetTable T
FULL OUTER JOIN @tSource S
ON S.Key1 = T.Key1 and S.Key2 = T.Key2
WHERE
CASE WHEN S.Key1 IS NOT NULL
/*Matched by Source*/
THEN CASE WHEN T.Key1 IS NOT NULL
/*Matched by Target*/
THEN CASE WHEN [T].[Data1]<>S.[Data1] OR
[T].[Data2]<>S.[Data2] OR
[T].[Data3]<>S.[Data3]
THEN (1)
END
/*Not Matched by Target*/
ELSE (4)
END
/*Not Matched by Source*/
ELSE CASE WHEN [T].[Key1]example@sqldat.com
THEN (3)
END
END IS NOT NULL
Tuy nhiên, điều đó nói lên rằng kế hoạch lên đến bộ lọc tự nó trông khá tối ưu. Nó đang thực hiện quét chỉ mục theo cụm đầy đủ khi có lẽ bạn muốn một kế hoạch với 2 phạm vi chỉ mục được phân cụm tìm kiếm. Một để truy xuất hàng đơn được khớp với khóa chính từ kết hợp trên nguồn và một để truy xuất T.Key1 = @id phạm vi (mặc dù có thể điều này là để tránh phải sắp xếp theo thứ tự khóa nhóm sau này?)
Có lẽ bạn có thể thử viết lại này và xem nó hoạt động tốt hơn hay tệ hơn
;WITH FilteredTarget AS
(
SELECT T.*
FROM TargetTable AS T WITH (FORCESEEK)
JOIN @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
OR T.Key1 = @id
)
MERGE FilteredTarget AS T
USING @tSource S
ON (T.Key1 = S.Key1
AND S.Key2 = T.Key2)
-- Only update if the Data columns do not match
WHEN MATCHED AND S.Key1 = T.Key1 AND S.Key2 = T.Key2 AND
(T.Data1 <> S.Data1 OR
T.Data2 <> S.Data2 OR
T.Data3 <> S.Data3) THEN
UPDATE SET T.Data1 = S.Data1,
T.Data2 = S.Data2,
T.Data3 = S.Data3
-- Note from original poster: This extra "safety clause" turned out not to
-- affect the behavior or the execution plan, so I removed it and it works
-- just as well without, but if you find yourself in a similar situation
-- you might want to give it a try.
-- WHEN MATCHED AND (S.Key1 <> T.Key1 OR S.Key2 <> T.Key2) AND T.Key1 = @id THEN
-- DELETE
-- Insert when missing in the target
WHEN NOT MATCHED BY TARGET THEN
INSERT (Key1, Key2, Data1, Data2, Data3)
VALUES (Key1, Key2, Data1, Data2, Data3)
WHEN NOT MATCHED BY SOURCE AND T.Key1 = @id THEN
DELETE;