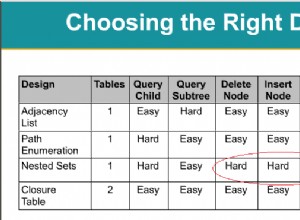
Đồng ý với Marc và Unkown ở trên ... 6 chỉ mục trong nhóm chỉ mục là quá nhiều, đặc biệt là trên một bảng chỉ có 14 cột. Bạn không nên có nhiều hơn 3 hoặc 4, nếu điều đó, tôi sẽ nói là 1 hoặc có thể là 2. Bạn có thể biết rằng chỉ mục được phân cụm là bảng thực tế trên đĩa vì vậy khi một bản ghi được chèn vào, công cụ cơ sở dữ liệu phải sắp xếp nó và đặt nó vào nơi có tổ chức được sắp xếp của nó trên đĩa. Các chỉ mục không được phân cụm thì không, chúng đang hỗ trợ 'bảng' tra cứu. Các VLDB của tôi được trình bày trên đĩa (CHỈ SỐ ĐƯỢC ĐIỀU CHỈNH) theo điểm đầu tiên bên dưới.
- Giảm chỉ mục nhóm của bạn xuống 1 hoặc 2. Các lựa chọn trường tốt nhất là IDENTITY (INT), nếu bạn có một hoặc trường ngày trong đó các trường đang được thêm vào cơ sở dữ liệu hoặc một số trường khác là sắp xếp tự nhiên về cách dữ liệu của bạn được thêm vào cơ sở dữ liệu. Vấn đề là bạn đang cố gắng giữ dữ liệu đó ở cuối bảng ... hoặc đặt nó trên đĩa theo cách tốt nhất (90% +) mà bạn sẽ đọc các bản ghi. Điều này làm cho nó để không có bắt đầu lại đang diễn ra hoặc chỉ mất một và chỉ một lần truy cập để đưa dữ liệu vào đúng vị trí để đọc tốt nhất. Đảm bảo đặt các trường đã loại bỏ vào các chỉ mục không phân cụm để bạn không mất hiệu quả tra cứu. Tôi KHÔNG BAO GIỜ đặt nhiều hơn 4 trường trên VLDB của mình. Nếu bạn có các trường đang được cập nhật thường xuyên và chúng được bao gồm trong chỉ mục nhóm của bạn, OUCH, điều đó sẽ tổ chức lại bản ghi trên đĩa và gây ra phân mảnh CHI PHÍ.
- Kiểm tra hệ số điền trên các chỉ mục của bạn. Hệ số lấp đầy (100) càng lớn thì các trang dữ liệu và trang chỉ mục sẽ càng đầy đủ. Liên quan đến số lượng bản ghi bạn có và số lượng bản ghi bạn đang chèn, bạn sẽ thay đổi hệ số điền # (+ hoặc -) của các chỉ mục không phân cụm của bạn để cho phép khoảng trống khi một bản ghi được chèn vào. Nếu bạn thay đổi chỉ mục nhóm của mình thành một trường dữ liệu tuần tự, thì điều này sẽ không quan trọng nhiều đối với chỉ mục được phân nhóm. Quy tắc ngón tay cái (IMO), hệ số điền 60-70 cho ghi nhiều, 70-90 cho ghi trung bình và 90-100 cho đọc cao / ghi thấp. Bằng cách giảm hệ số điền của bạn xuống 70, có nghĩa là cứ 100 bản ghi trên một trang, 70 bản ghi được viết, điều này sẽ để lại không gian trống của 30 bản ghi cho các bản ghi mới hoặc được tổ chức lại. Tăng thêm dung lượng, nhưng chắc chắn nó sẽ đánh bại việc phải DEFRAG mỗi đêm (xem 4 bên dưới)
- Đảm bảo các thống kê tồn tại trên bảng. Nếu bạn muốn quét cơ sở dữ liệu để tạo thống kê bằng cách sử dụng "sp_createstats 'indexonly'", thì SQL Server sẽ tạo tất cả thống kê trên tất cả các chỉ mục mà công cụ đã tích lũy khi yêu cầu thống kê. Tuy nhiên, đừng bỏ qua thuộc tính 'indexonly' nếu không bạn sẽ thêm số liệu thống kê cho mọi trường, điều đó sẽ không tốt.
- Kiểm tra bảng / chỉ mục bằng cách sử dụng DBCC SHOWCONTIG để xem chỉ mục nào đang bị phân mảnh nhiều nhất. Tôi sẽ không đi vào chi tiết ở đây, chỉ biết rằng bạn cần phải làm điều đó. Sau đó, dựa trên thông tin đó, hãy thay đổi hệ số lấp đầy lên hoặc xuống liên quan đến những thay đổi mà chỉ mục đang trải qua sự thay đổi và tốc độ (theo thời gian).
- Thiết lập một lịch trình công việc sẽ thực hiện trực tuyến (DBCC INDEXDEFRAG) hoặc ngoại tuyến (DBCC DBREINDEX) trên các chỉ mục riêng lẻ để phân mảnh chúng. Cảnh báo:không thực hiện DBCC DBREINDEX trên phần lớn này của bảng mà không có nó trong thời gian bảo trì vì nó sẽ làm cho các ứng dụng ngừng hoạt động ... đặc biệt là trên CHỈ SỐ ĐƯỢC ĐIỀU CHỈNH. Mày đã được cảnh báo. Kiểm tra và thử nghiệm phần này.
- Sử dụng các kế hoạch thực thi để xem những gì SCANS và FAT PIPES tồn tại và điều chỉnh các chỉ mục, sau đó chống phân mảnh và viết lại các procs đã lưu trữ để loại bỏ các điểm nóng đó. Nếu bạn thấy một đối tượng ĐỎ trong kế hoạch thực hiện của mình, đó là do không có số liệu thống kê về trường đó. Điều đó thật xấu. Bước này mang tính "nghệ thuật hơn là khoa học".
- Vào thời gian thấp điểm, hãy chạy THỐNG KÊ CẬP NHẬT VỚI FULLSCAN để cung cấp cho công cụ truy vấn càng nhiều thông tin về phân phối dữ liệu càng tốt. Nếu không, hãy làm THỐNG KÊ CẬP NHẬT tiêu chuẩn (với quét 10% tiêu chuẩn) trên các bảng trong các đêm trong tuần hoặc thường xuyên hơn khi bạn thấy phù hợp với quan sát của mình để đảm bảo công cụ có thêm thông tin về các phân phối dữ liệu để truy xuất dữ liệu một cách hiệu quả.
Xin lỗi vì điều này quá dài, nhưng nó cực kỳ quan trọng. Tôi chỉ cung cấp cho bạn ở đây thông tin tối thiểu nhưng sẽ giúp ích rất nhiều. Có một số cảm nhận và quan sát thực tế liên quan đến các chiến lược được sử dụng bởi những điểm này sẽ đòi hỏi thời gian và thử nghiệm của bạn.
Không cần phải chuyển đến phiên bản Enterprise. Tôi đã làm như vậy để có được các tính năng đã nói trước đó với phân vùng. Nhưng tôi đã làm ĐẶC BIỆT để có khả năng phân luồng mult tốt hơn nhiều với việc tìm kiếm và DEFRAGING và bảo trì trực tuyến ... Trong phiên bản Enterprise, nó tốt hơn và thân thiện hơn nhiều với VLDB. Phiên bản tiêu chuẩn cũng không xử lý việc thực hiện DBCC INDEXDEFRAG với cơ sở dữ liệu trực tuyến.