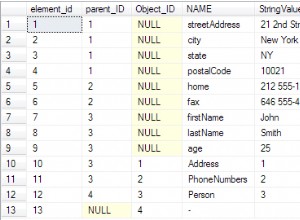
Ký tự ® có giá trị mã thập phân 174 và do đó không phải là ASCII ký tự mà tất cả đều có giá trị mã trong phạm vi từ 0 đến 127.
® là ký tự ® được lưu trữ trong tệp văn bản được mã hóa bằng Unicode mã hóa UTF-8 , nhưng được hiển thị dưới dạng ANSI ký tự sử dụng trang mã Windows 1252 hoặc ISO 8859-1 .
Vì vậy, việc xuất sự khác biệt được thực hiện tốt và tệp được tạo (tệp văn bản?) Là ổn. Bạn chỉ phải mở tệp được mã hóa UTF-8 này trong trình chỉnh sửa / trình xem văn bản của mình bằng cách sử dụng UTF-8 nếu trình chỉnh sửa / trình xem không tự động phát hiện mã hóa UTF-8.
Bạn có thể chèn vào đầu tệp văn bản  là hệ thập lục phân EF BB BF là dấu thứ tự byte
( BOM
) cho UTF-8. Điều đó sẽ giúp người chỉnh sửa / người xem văn bản phát hiện nhanh hơn rằng tệp văn bản được mã hóa bằng UTF-8. Nhưng một số ứng dụng không diễn giải 3 byte đó ở đầu tệp văn bản là BOM.
Bây giờ khi biết rằng vấn đề của bạn là do mã hóa khác nhau của các ký tự không phải ASCII, bạn có thể tìm kiếm các trang liên quan. Xem ví dụ Mô tả lưu trữ dữ liệu UTF-8 trong SQL Server . Tôi khuyên bạn nên tìm kiếm bằng các từ Unicode UTF-8 SQL Server .