Chà, phân tích sự lây lan của coronavirus SARS-CoV-2 không phải là trường hợp sử dụng trong mơ của tôi . Nhưng dựa trên các phản hồi cho bài viết Theo dõi Coronavirus COVID-19 Gần thời gian thực với SAP HANA XSA của Ferry Djaja, tôi cũng đã quyết định thêm hai trò chơi groszy của mình.
[ Cập nhật vào ngày 20-03-30 với các liên kết đã thay đổi đến dữ liệu nguồn; và đầu ra bản đồ mới dựa trên mức độ chi tiết của dữ liệu mới. Cảm ơn Douglas Maltby vì nhận xét của bạn!]
Trong bài đăng trên blog của mình, Ferry đã sử dụng JavaScript trong SAP HANA XSA để lấy dữ liệu từ các tệp CSV được Đại học Johns Hopkins cập nhật hàng ngày.
Tôi muốn chỉ cho bạn cách bạn có thể kéo và tải các tệp này vào SAP HANA chỉ bằng một vài dòng mã nhờ SAP HANA Python Client API cho Máy học (hana_ml gói).
Một số người đã nhầm lẫn với hình ảnh trực quan trên bản đồ ở phần cuối - xin lưu ý rằng bài viết này tập trung vào trường hợp sử dụng kỹ thuật kết nối các thành phần khác nhau, không phải thực hiện phân tích sâu dữ liệu coronavirus.
Nhận môi trường Python, ví dụ:Jupyter
Tôi sẽ sử dụng Jupyter trong vùng chứa Docker cho việc đó. Hãy xem bài viết trước của tôi Tìm hiểu vùng chứa (phần 05):tệp được chia sẻ giữa máy chủ và vùng chứa nếu bạn chưa quen với cách khởi động nó. Ngoài ra, bạn có thể thực hiện tất cả các bước tương tự bên dưới từ bất kỳ môi trường Python nào khác.
Vì vậy, tôi có vùng chứa của mình myjupyter01 chạy bộ. Tôi được kết nối với giao diện người dùng Jupyter như được mô tả trong blog trước.
Cài đặt hana_ml
Hình ảnh Jupyter mà tôi đã sử dụng từ sổ đăng ký Docker Hub là jupyter/minimal-notebook . Nó đã chứa một số gói xử lý dữ liệu phổ biến, như pandas .
Nhưng ngoài ra, tôi cần cài đặt hana_ml , - trong phiên bản hiện tại 1.0.8 - có sẵn trên kho lưu trữ PyPI:https://pypi.org/project/hana-ml/.
Lệnh để chạy cài đặt là python -m pip install hana_ml , nhưng vì tôi đang chạy nó từ sổ ghi chép Jupyter với nhân Python3, tôi cần chạy nó với ! ở phần đầu:
!python -m pip install hana_ml
Rõ ràng, bước cài đặt này chỉ được thực hiện một lần. Không cần chạy lại nó trong cùng một vùng chứa, ví dụ:khi tải lại các tệp mới nhất.
Sử dụng pandas để nhập tệp có dữ liệu
Hãy nhập ba tệp giống nhau (confirmed , deaths , recovered ) từ https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_series khi Phà được sử dụng trong ví dụ của anh ấy.
import hana_ml, pandas
# Links updated on 2020-03-22
df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')
df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')
#Links from before March 22nd
#df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
#df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
#df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')
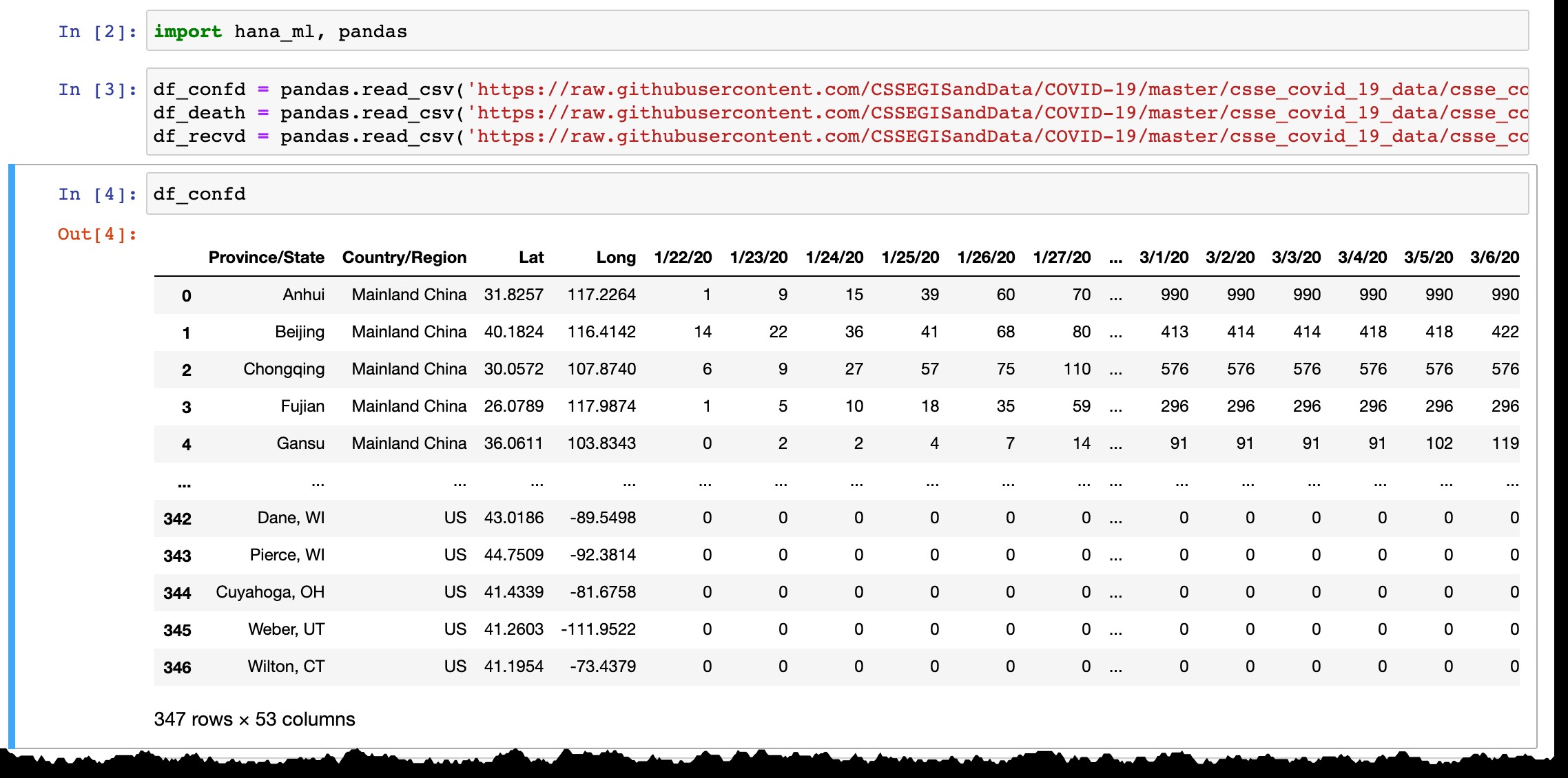
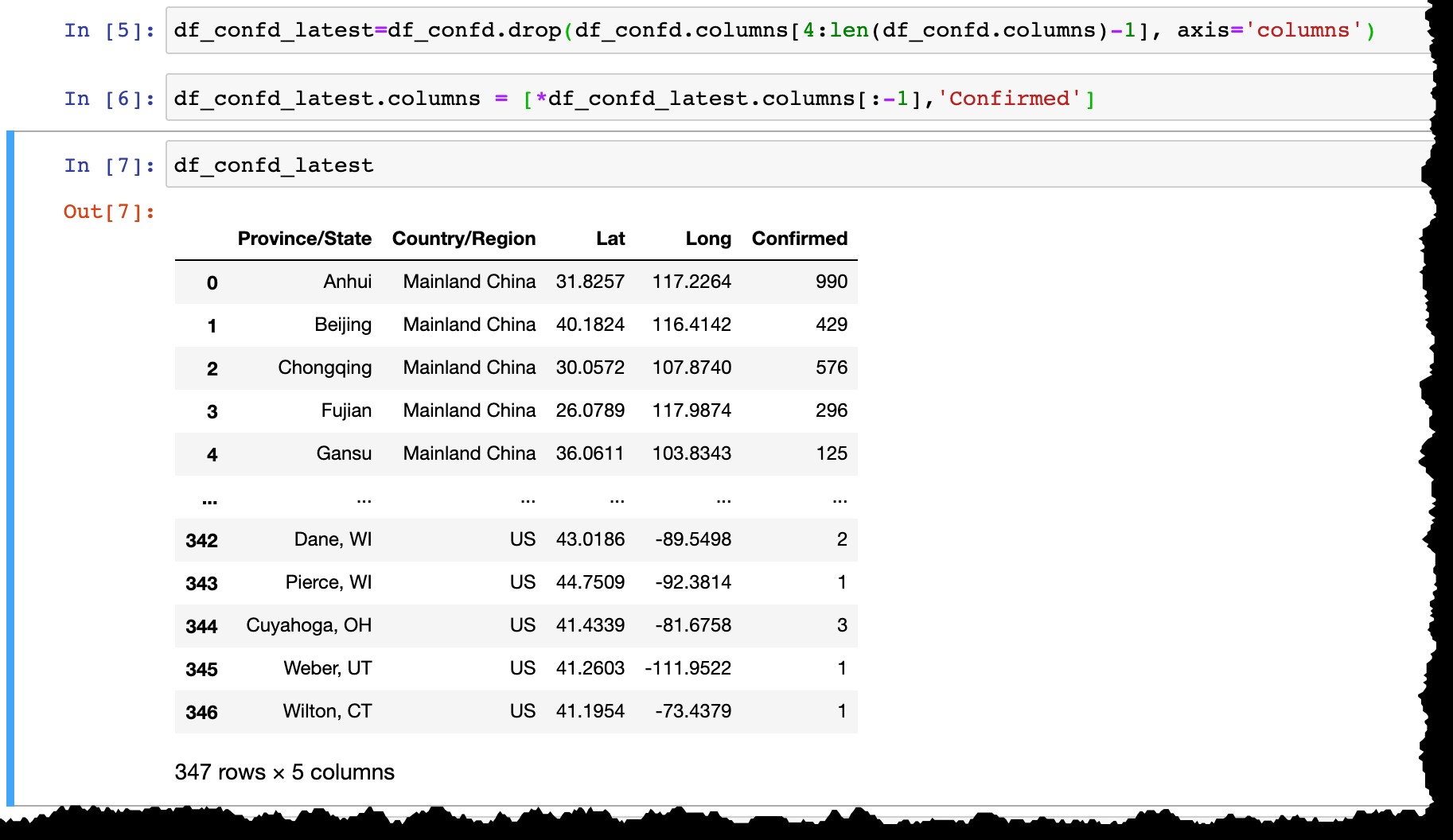
Như bạn có thể thấy từ bản xem trước của khung dữ liệu Pandas, khung dữ liệu này chỉ liệt kê các quốc gia hoặc tỉnh có các trường hợp được xác nhận và mỗi ngày cột mới được thêm vào với dữ liệu mới nhất từ ngày hôm trước. Các dòng được thêm vào khi (các) trường hợp đầu tiên được xác nhận trong vùng mới.
Sử dụng pandas để định dạng lại khung dữ liệu
Trước khi duy trì dữ liệu trong SAP HANA, hãy:
- Xóa tất cả các cột ngày ngoại trừ cột cuối cùng,
- Đổi tên cột cuối cùng từ ngày thực tế (như
3/10/20của ngày hôm nay đếnConfirmed).
df_confd_latest=df_confd.drop(df_confd.columns[4:len(df_confd.columns)-1], axis='columns')
df_confd_latest.columns = [*df_confd_latest.columns[:-1],'Confirmed']
Sử dụng hana_ml để duy trì dữ liệu trong bảng SAP HANA
Bây giờ, hãy để tôi kết nối với phiên bản SAP HANA Express của tôi với người dùng hanaml đã tồn tại ở đó…
cc=hana_ml.dataframe.ConnectionContext('12.34.567.890', 39015, 'hanaml', 'MyPasswordReusedEverywhere')
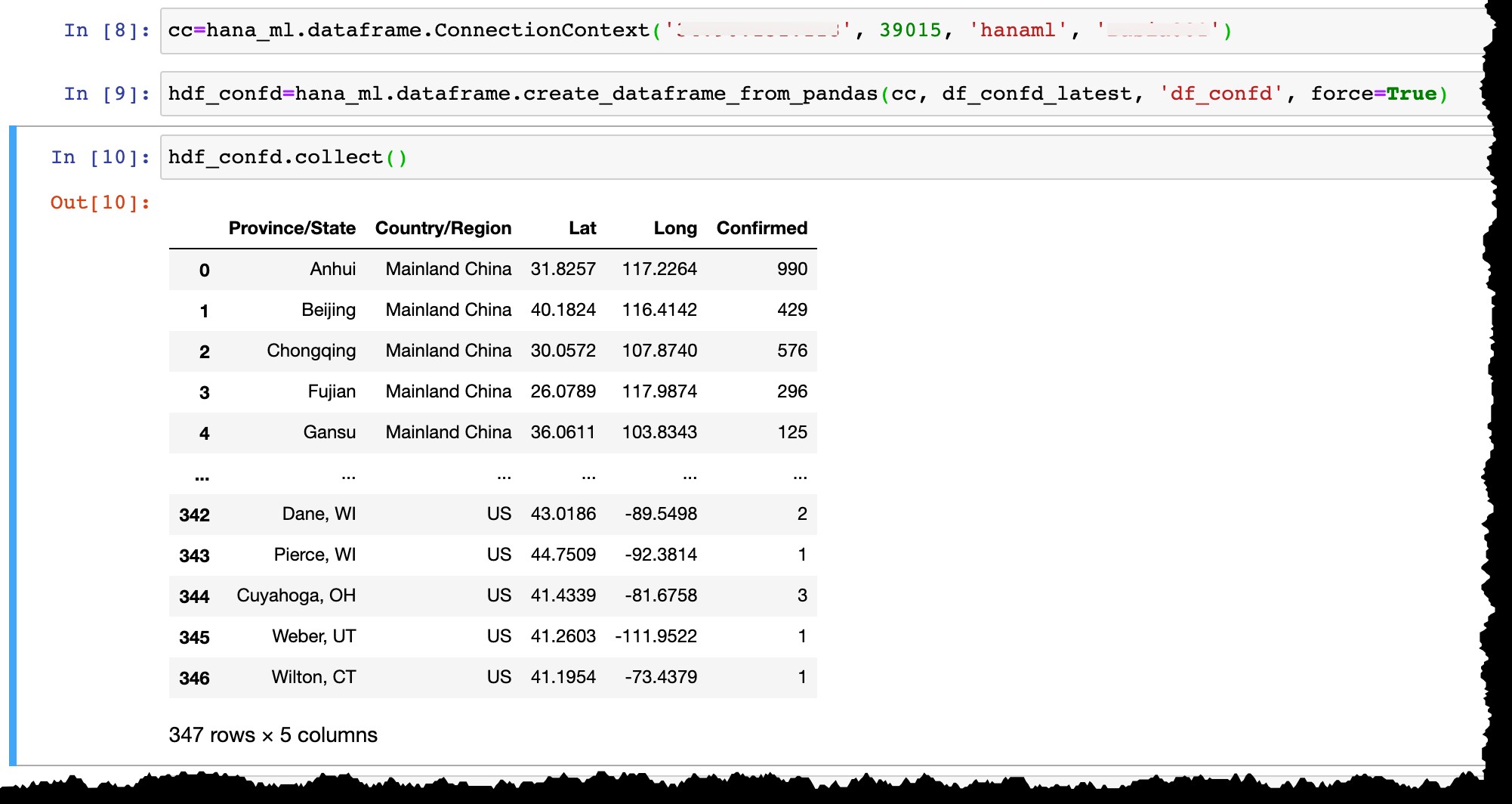
… Và chuyển đổi khung dữ liệu Pandas df_confd_latest vào khung dữ liệu HANA hdf_confd .
hdf_confd=hana_ml.dataframe.create_dataframe_from_pandas(cc, df_confd_latest, 'df_confd', force=True)
Khi khung dữ liệu HANA được tạo:
- Một bảng cột vật lý được tạo trong HANA và dữ liệu từ khung dữ liệu Pandas được chèn vào đó,
- Khung dữ liệu HANA
hdf_confdtrong Python không lưu trữ bất kỳ dữ liệu nào trong máy tính xách tay của bạn mà chỉ trỏ đến một bảngHANAML.df_confdtrong bộ nhớ máy chủ SAP HANA và tất cả các hoạt động Python trên khung dữ liệu HANA được thực hiện vật lý trong HANA db mà không cần di chuyển dữ liệu giữa máy chủ và máy khách, - Để hiển thị kết quả của bất kỳ thao tác nào, chúng tôi cần áp dụng
collect()phương pháp chuyển đổi khung dữ liệu HANA thành Pandas (và kết quả là đưa dữ liệu từ máy chủ HANA db đến máy khách cục bộ).
Sử dụng DBeaver để kiểm tra dữ liệu trong SAP HANA…
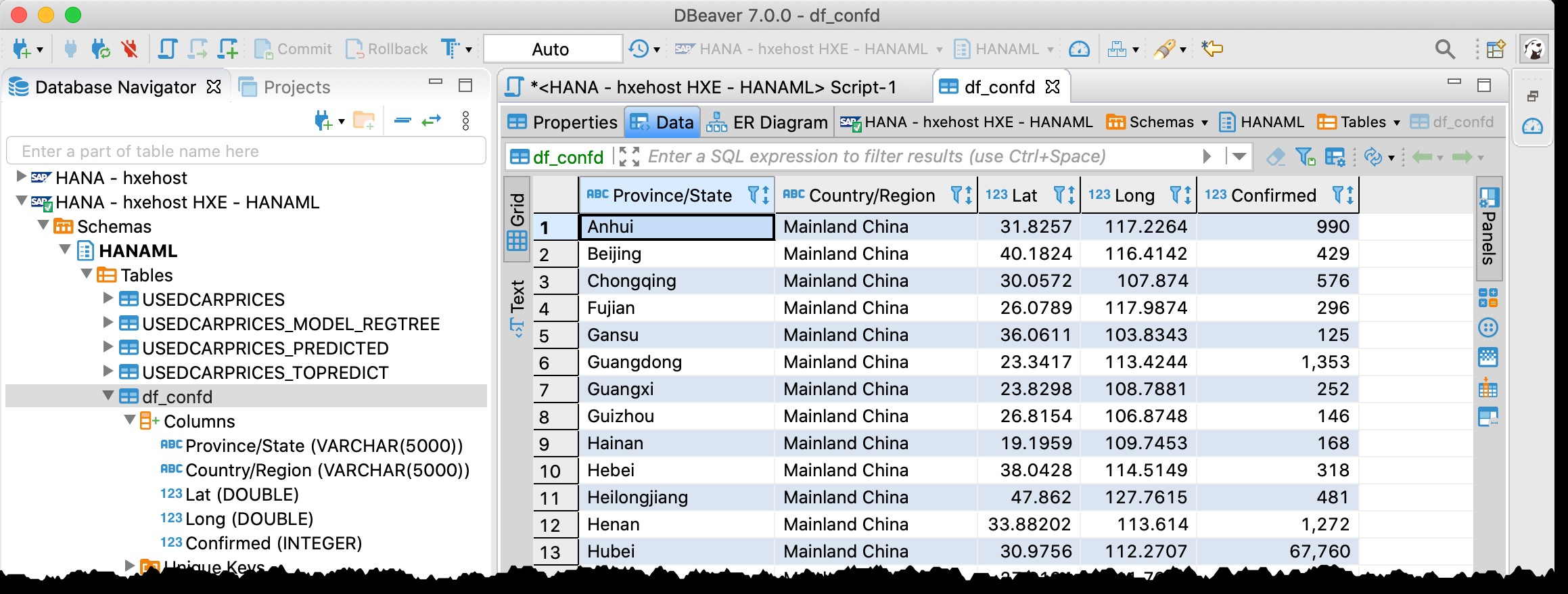
Bạn có thể nhớ tôi đã sử dụng DBeaver - công cụ cơ sở dữ liệu miễn phí hỗ trợ SAP HANA - trong bài đăng trước của tôi “GeoArt với SAP HANA và DBeaver”.
Bây giờ tôi đang sử dụng lại nó và thực sự tôi có thể tìm thấy bảng df_confd trong lược đồ HANAML với tất cả dữ liệu từ khung dữ liệu Pandas nguồn.
… và xem trước không gian
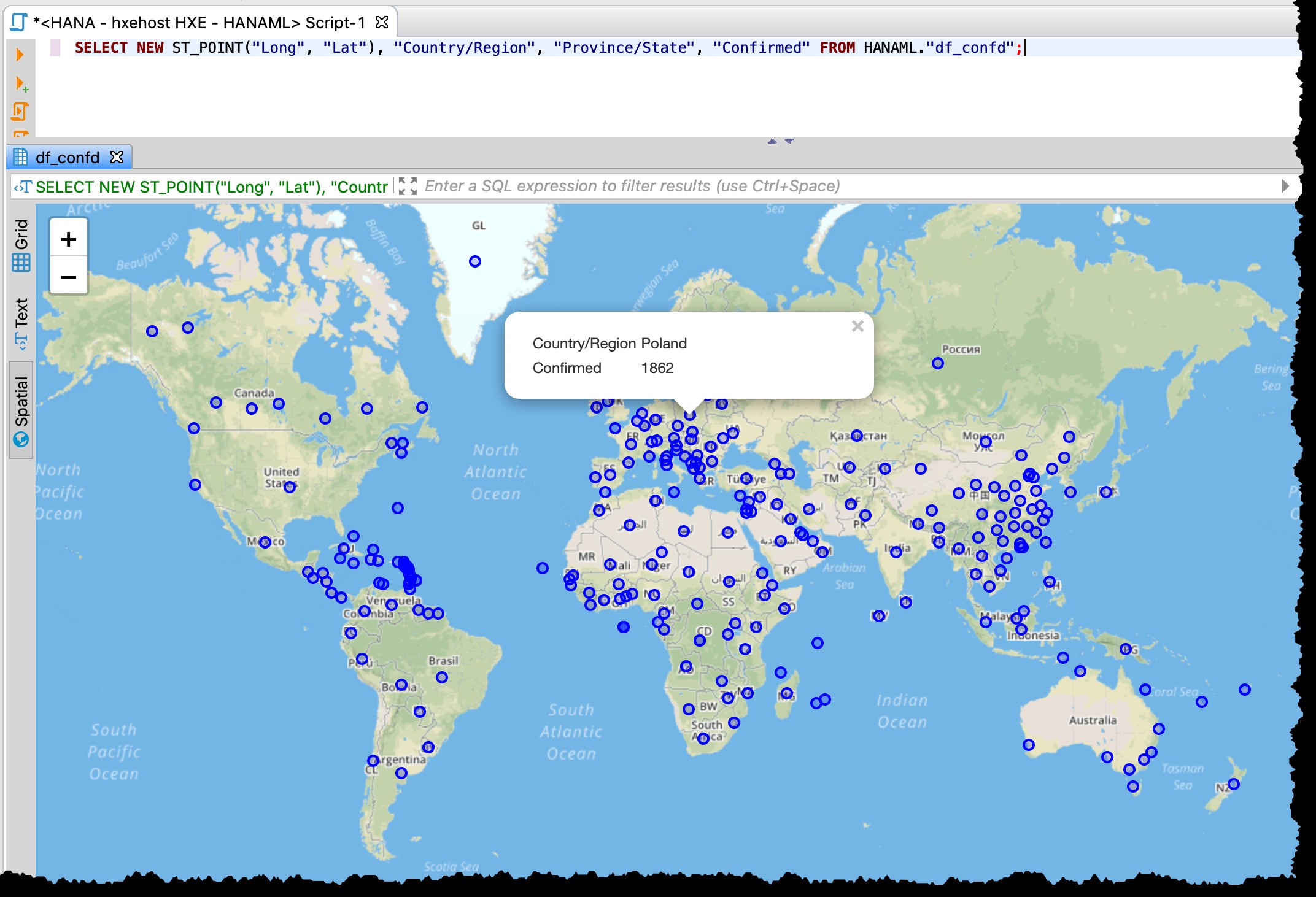
Vì bảng chứa các cột vĩ độ và kinh độ, tôi có thể hình dung các quốc gia / tiểu bang bị ảnh hưởng ngay từ DBeaver với SQL sau bằng cách sử dụng bản xem trước dữ liệu Không gian.
SELECT NEW ST_POINT("Long", "Lat"), "Country/Region", "Province/State", "Confirmed" FROM HANAML."df_confd";
Tôi cần thay đổi phép chiếu bản đồ thành EPSG:4326 để có được những điểm này trên bản đồ. Và DBeaver hiển thị cho tôi phần còn lại của dữ liệu bản ghi khi tôi nhấp vào bất kỳ điểm nào.
[ Bên dưới là ảnh chụp màn hình cũ từ 2020-03-11, cũng như chứng minh mức độ chi tiết khác nhau của v.d. Dữ liệu của Hoa Kỳ được sử dụng tại thời điểm đó]
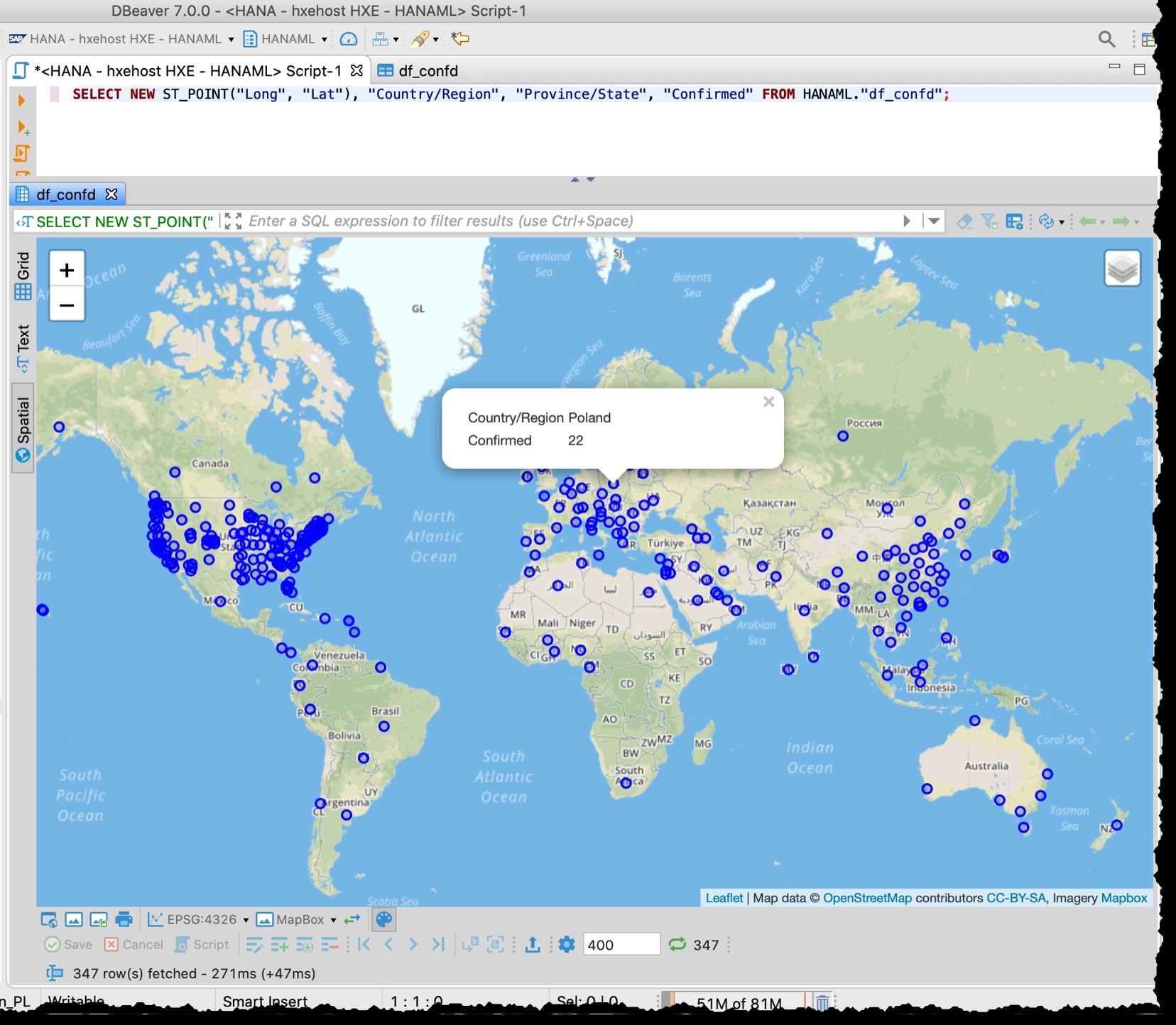
Bản xem trước không gian DBeaver không phải là một công cụ khám phá trực quan không gian địa lý toàn diện. Tuy nhiên, đủ tốt để xem các quốc gia / khu vực bị ảnh hưởng (tùy thuộc vào mức độ chi tiết trong các tệp nguồn).
Bạn có muốn tìm hiểu thêm về hana_ml …
… Thì tôi chắc chắn khuyên bạn nên xem Hướng dẫn thực hành:Học máy đẩy xuống SAP HANA với Python của Andreas Forster.
HANA ML là một phần của chủ đề “Phân tích nâng cao với SAP HANA” mới cho các sự kiện CodeJam. Thật không may vì tình trạng coronavirus, chúng tôi đã phải hủy bỏ sự kiện đầu tiên do Jakob Flaman tổ chức ở Bern trong tháng này. Một sự kiện khác được tổ chức bởi Ewelina Pękała vào ngày 27 tháng 5 tại Katowice:https://www.eventbrite.com/e/sap-codejam-katowice-registration-99016299417. Hy vọng rằng tình hình sẽ trở nên bình thường vào thời điểm đó và chúng tôi cũng sẽ không cần phải hủy điều này nữa.