Trong bài viết này, chúng tôi sẽ xây dựng một máy quét cho một thực tế hợp đồng biểu diễn tự do trong đó khách hàng muốn một chương trình Python lấy dữ liệu từ Stack Overflow để lấy các câu hỏi mới (tiêu đề câu hỏi và URL). Sau đó, dữ liệu cóp nhặt sẽ được lưu trữ trong MongoDB. Điều đáng chú ý là Stack Overflow có một API, có thể được sử dụng để truy cập vào chính xác dữ liệu giống nhau. Tuy nhiên, khách hàng muốn có một cái cạp, vì vậy một cái cạp chính là thứ mà anh ta nhận được.
Tiền thưởng miễn phí: Nhấp vào đây để tải xuống khung dự án Python + MongoDB với mã nguồn đầy đủ hướng dẫn bạn cách truy cập MongoDB từ Python.
Cập nhật:
- 01/03/2014 - Đã tái cấu trúc lại con nhện. Cảm ơn, @kissgyorgy.
- 18/02/2015 - Đã thêm Phần 2.
- 09/06/2015 - Đã cập nhật lên phiên bản Scrapy và PyMongo mới nhất - chúc mừng!
Như thường lệ, hãy nhớ xem lại các điều khoản sử dụng / dịch vụ của trang web và tôn trọng robots.txt nộp trước khi bắt đầu bất kỳ công việc cạo nào. Đảm bảo tuân thủ các quy tắc đạo đức bằng cách không làm ngập trang web với nhiều yêu cầu trong một khoảng thời gian ngắn. Đối xử với bất kỳ trang web nào bạn cóp nhặt như thể đó là của riêng bạn .
Cài đặt
Chúng tôi cần thư viện Scrapy (v1.0.3) cùng với PyMongo (v3.0.3) để lưu trữ dữ liệu trong MongoDB. Bạn cũng cần cài đặt MongoDB (không được bảo vệ).
Trị liệu
Nếu bạn đang chạy OSX hoặc phiên bản Linux, hãy cài đặt Scrapy bằng pip (đã kích hoạt virtualenv của bạn):
$ pip install Scrapy==1.0.3
$ pip freeze > requirements.txt
Nếu bạn đang sử dụng máy Windows, bạn sẽ cần phải cài đặt thủ công một số phần phụ thuộc. Vui lòng tham khảo tài liệu chính thức để biết hướng dẫn chi tiết cũng như video Youtube này mà tôi đã tạo.
Sau khi Scrapy được thiết lập, hãy xác minh cài đặt của bạn bằng cách chạy lệnh này trong Python shell:
>>>>>> import scrapy
>>>
Nếu bạn không gặp lỗi thì bạn có thể tiếp tục!
PyMongo
Tiếp theo, cài đặt PyMongo bằng pip:
$ pip install pymongo
$ pip freeze > requirements.txt
Bây giờ chúng ta có thể bắt đầu xây dựng trình thu thập thông tin.
Dự án trị liệu
Hãy bắt đầu một dự án Trị liệu mới:
$ scrapy startproject stack
2015-09-05 20:56:40 [scrapy] INFO: Scrapy 1.0.3 started (bot: scrapybot)
2015-09-05 20:56:40 [scrapy] INFO: Optional features available: ssl, http11
2015-09-05 20:56:40 [scrapy] INFO: Overridden settings: {}
New Scrapy project 'stack' created in:
/stack-spider/stack
You can start your first spider with:
cd stack
scrapy genspider example example.com
Điều này tạo ra một số tệp và thư mục bao gồm một bản soạn sẵn cơ bản để bạn bắt đầu nhanh chóng:
├── scrapy.cfg
└── stack
├── __init__.py
├── items.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
Chỉ định dữ liệu
items.py tệp được sử dụng để xác định "vùng chứa" lưu trữ cho dữ liệu mà chúng tôi định loại bỏ.
StackItem() lớp kế thừa từ Item (docs), về cơ bản có một số đối tượng được xác định trước mà Scrapy đã xây dựng cho chúng tôi:
import scrapy
class StackItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
Hãy thêm một số mục mà chúng tôi thực sự muốn thu thập. Đối với mỗi câu hỏi, khách hàng cần có tiêu đề và URL. Vì vậy, hãy cập nhật items.py như vậy:
from scrapy.item import Item, Field
class StackItem(Item):
title = Field()
url = Field()
Tạo con nhện
Tạo một tệp có tên là stack_spider.py trong thư mục "spiders". Đây là nơi điều kỳ diệu xảy ra - ví dụ:nơi chúng tôi sẽ nói với Scrapy cách tìm ra chính xác dữ liệu chúng tôi đang tìm kiếm. Như bạn có thể tưởng tượng, đây là cụ thể đến từng trang web riêng lẻ mà bạn muốn cóp nhặt.
Bắt đầu bằng cách xác định một lớp kế thừa từ Spider của Scrapy và sau đó thêm các thuộc tính nếu cần:
from scrapy import Spider
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
Một số biến đầu tiên là tự giải thích (tài liệu):
-
namexác định tên của Nhện. -
allowed_domainschứa các URL cơ sở cho các miền được phép để trình thu thập thông tin thu thập thông tin. -
start_urlslà danh sách các URL để trình thu thập thông tin bắt đầu thu thập thông tin. Tất cả các URL tiếp theo sẽ bắt đầu từ dữ liệu mà spider tải xuống từ URLS trongstart_urls.
Bộ chọn XPath
Tiếp theo, Scrapy sử dụng bộ chọn XPath để trích xuất dữ liệu từ một trang web. Nói cách khác, chúng ta có thể chọn một số phần nhất định của dữ liệu HTML dựa trên một XPath nhất định. Như đã nêu trong tài liệu của Scrapy, “XPath là ngôn ngữ để chọn các nút trong tài liệu XML, ngôn ngữ này cũng có thể được sử dụng với HTML.”
Bạn có thể dễ dàng tìm thấy một Xpath cụ thể bằng Công cụ dành cho nhà phát triển của Chrome. Chỉ cần kiểm tra một phần tử HTML cụ thể, sao chép XPath, sau đó chỉnh sửa (nếu cần):
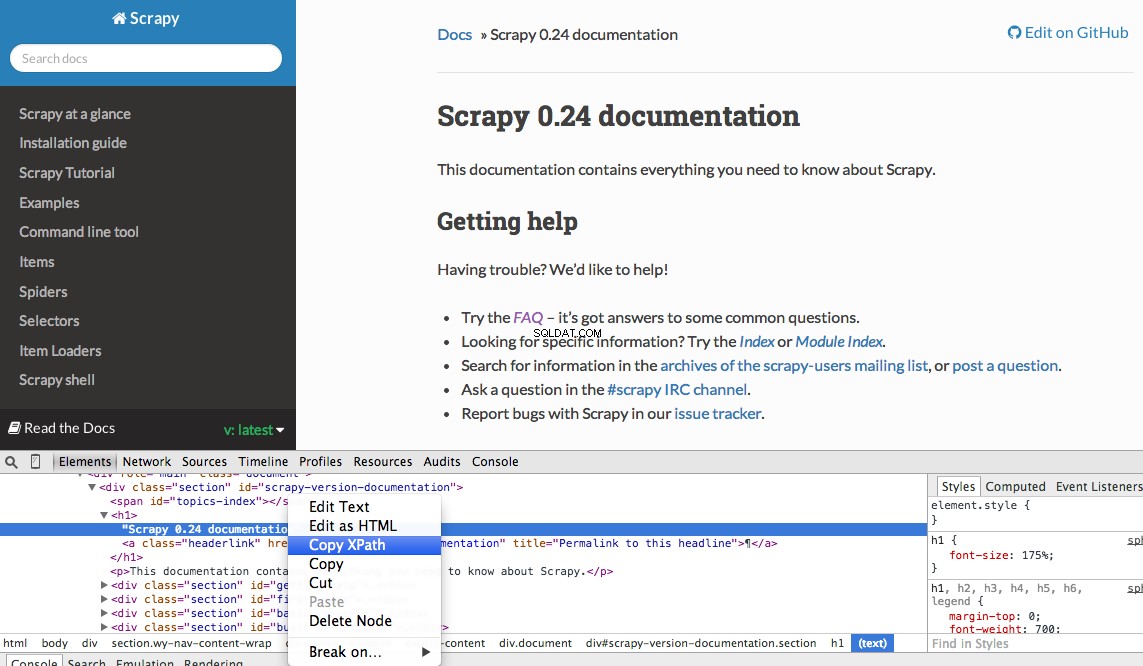
Công cụ dành cho nhà phát triển cũng cung cấp cho bạn khả năng kiểm tra bộ chọn XPath trong Bảng điều khiển JavaScript bằng cách sử dụng $x - tức là $x("//img") :
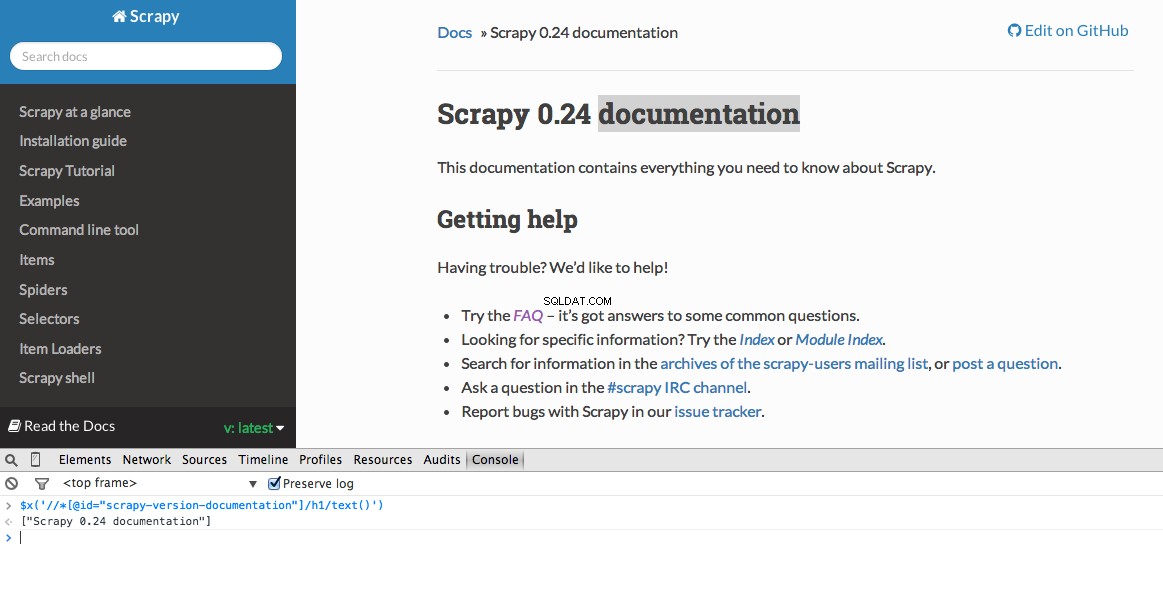
Một lần nữa, về cơ bản chúng ta sẽ cho Scrapy biết nơi bắt đầu tìm kiếm thông tin dựa trên XPath đã xác định. Hãy điều hướng đến trang Stack Overflow trong Chrome và tìm các bộ chọn XPath.
Nhấp chuột phải vào câu hỏi đầu tiên và chọn “Kiểm tra phần tử”:
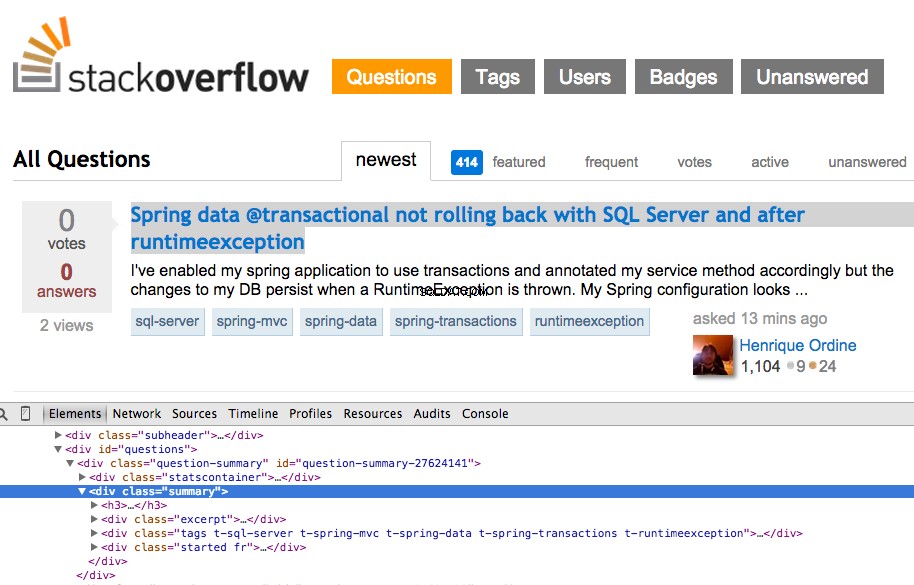
Bây giờ lấy XPath cho <div class="summary"> , //*[@id="question-summary-27624141"]/div[2] , và sau đó kiểm tra nó trong Bảng điều khiển JavaScript:
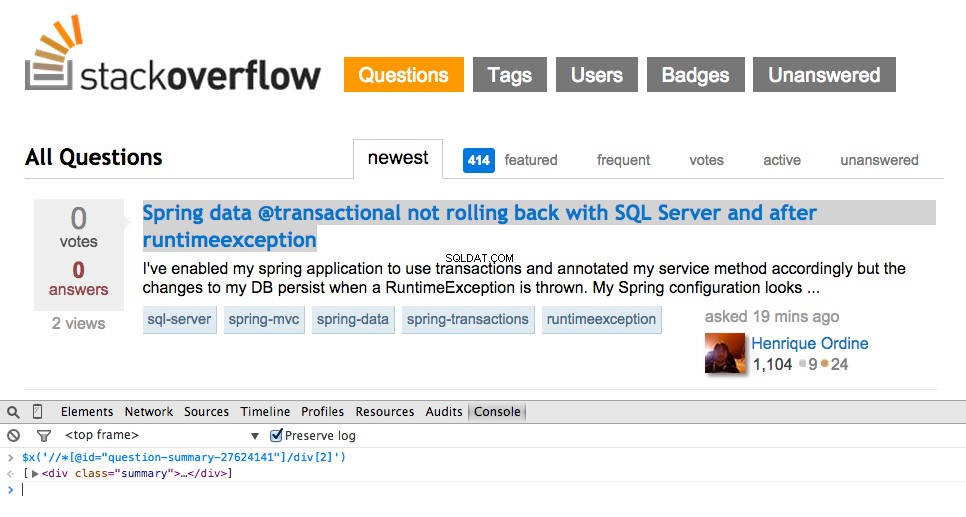
Như bạn có thể nói, nó chỉ chọn một câu hỏi. Vì vậy, chúng tôi cần thay đổi XPath để lấy tất cả các câu hỏi. Có ý kiến gì không? Thật đơn giản://div[@class="summary"]/h3 . Điều đó có nghĩa là gì? Về cơ bản, XPath này cho biết: Lấy tất cả <h3> các phần tử là con của <div> có một lớp summary . Kiểm tra XPath này trong Bảng điều khiển JavaScript.
Lưu ý cách chúng tôi không sử dụng đầu ra XPath thực tế từ Công cụ dành cho nhà phát triển Chrome. Trong hầu hết các trường hợp, đầu ra chỉ là một phần hữu ích sang một bên, thường chỉ bạn đi đúng hướng để tìm XPath hoạt động.
Bây giờ, hãy cập nhật stack_spider.py script:
from scrapy import Spider
from scrapy.selector import Selector
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
Trích xuất dữ liệu
Chúng tôi vẫn cần phân tích cú pháp và cắt dữ liệu chúng tôi muốn, dữ liệu này nằm trong <div class="summary"><h3> . Một lần nữa, hãy cập nhật stack_spider.py như vậy:
from scrapy import Spider
from scrapy.selector import Selector
from stack.items import StackItem
class StackSpider(Spider):
name = "stack"
allowed_domains = ["stackoverflow.com"]
start_urls = [
"https://stackoverflow.com/questions?pagesize=50&sort=newest",
]
def parse(self, response):
questions = Selector(response).xpath('//div[@class="summary"]/h3')
for question in questions:
item = StackItem()
item['title'] = question.xpath(
'a[@class="question-hyperlink"]/text()').extract()[0]
item['url'] = question.xpath(
'a[@class="question-hyperlink"]/@href').extract()[0]
yield item
````
We are iterating through the `questions` and assigning the `title` and `url` values from the scraped data. Be sure to test out the XPath selectors in the JavaScript Console within Chrome Developer Tools - e.g., `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/text()')` and `$x('//div[@class="summary"]/h3/a[@class="question-hyperlink"]/@href')`.
## Test
Ready for the first test? Simply run the following command within the "stack" directory:
```console
$ scrapy crawl stack
Cùng với dấu vết ngăn xếp Scrapy, bạn sẽ thấy 50 tiêu đề câu hỏi và URL được xuất ra. Bạn có thể kết xuất đầu ra thành tệp JSON bằng lệnh nhỏ sau:
$ scrapy crawl stack -o items.json -t json
Hiện chúng tôi đã triển khai Spider của mình dựa trên dữ liệu mà chúng tôi đang tìm kiếm. Bây giờ chúng ta cần lưu trữ dữ liệu đã được cạo trong MongoDB.
Lưu trữ dữ liệu trong MongoDB
Mỗi khi một mặt hàng được trả lại, chúng tôi muốn xác thực dữ liệu và sau đó thêm nó vào bộ sưu tập Mongo.
Bước đầu tiên là tạo cơ sở dữ liệu mà chúng tôi định sử dụng để lưu tất cả dữ liệu đã thu thập thông tin của chúng tôi. Mở settings.py và chỉ định đường dẫn và thêm cài đặt cơ sở dữ liệu:
ITEM_PIPELINES = ['stack.pipelines.MongoDBPipeline', ]
MONGODB_SERVER = "localhost"
MONGODB_PORT = 27017
MONGODB_DB = "stackoverflow"
MONGODB_COLLECTION = "questions"
Quản lý đường ống
Chúng tôi đã thiết lập trình thu thập thông tin để thu thập thông tin và phân tích cú pháp HTML, đồng thời chúng tôi đã thiết lập cài đặt cơ sở dữ liệu của mình. Bây giờ chúng ta phải kết nối cả hai với nhau thông qua một đường dẫn trong pipelines.py .
Kết nối với cơ sở dữ liệu
Trước tiên, hãy xác định một phương thức để thực sự kết nối với cơ sở dữ liệu:
import pymongo
from scrapy.conf import settings
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
Ở đây, chúng tôi tạo một lớp, MongoDBPipeline() và chúng tôi có một hàm khởi tạo để khởi tạo lớp bằng cách xác định cài đặt Mongo và sau đó kết nối với cơ sở dữ liệu.
Xử lý dữ liệu
Tiếp theo, chúng ta cần xác định một phương thức để xử lý dữ liệu đã phân tích cú pháp:
import pymongo
from scrapy.conf import settings
from scrapy.exceptions import DropItem
from scrapy import log
class MongoDBPipeline(object):
def __init__(self):
connection = pymongo.MongoClient(
settings['MONGODB_SERVER'],
settings['MONGODB_PORT']
)
db = connection[settings['MONGODB_DB']]
self.collection = db[settings['MONGODB_COLLECTION']]
def process_item(self, item, spider):
valid = True
for data in item:
if not data:
valid = False
raise DropItem("Missing {0}!".format(data))
if valid:
self.collection.insert(dict(item))
log.msg("Question added to MongoDB database!",
level=log.DEBUG, spider=spider)
return item
Chúng tôi thiết lập kết nối với cơ sở dữ liệu, giải nén dữ liệu và sau đó lưu vào cơ sở dữ liệu. Bây giờ chúng ta có thể kiểm tra lại!
Kiểm tra
Một lần nữa, hãy chạy lệnh sau trong thư mục "ngăn xếp":
$ scrapy crawl stack
LƯU Ý :Đảm bảo bạn có daemon Mongo -
mongod- chạy trong một cửa sổ đầu cuối khác.
Hoan hô! Chúng tôi đã lưu trữ thành công dữ liệu được thu thập thông tin của mình vào cơ sở dữ liệu:
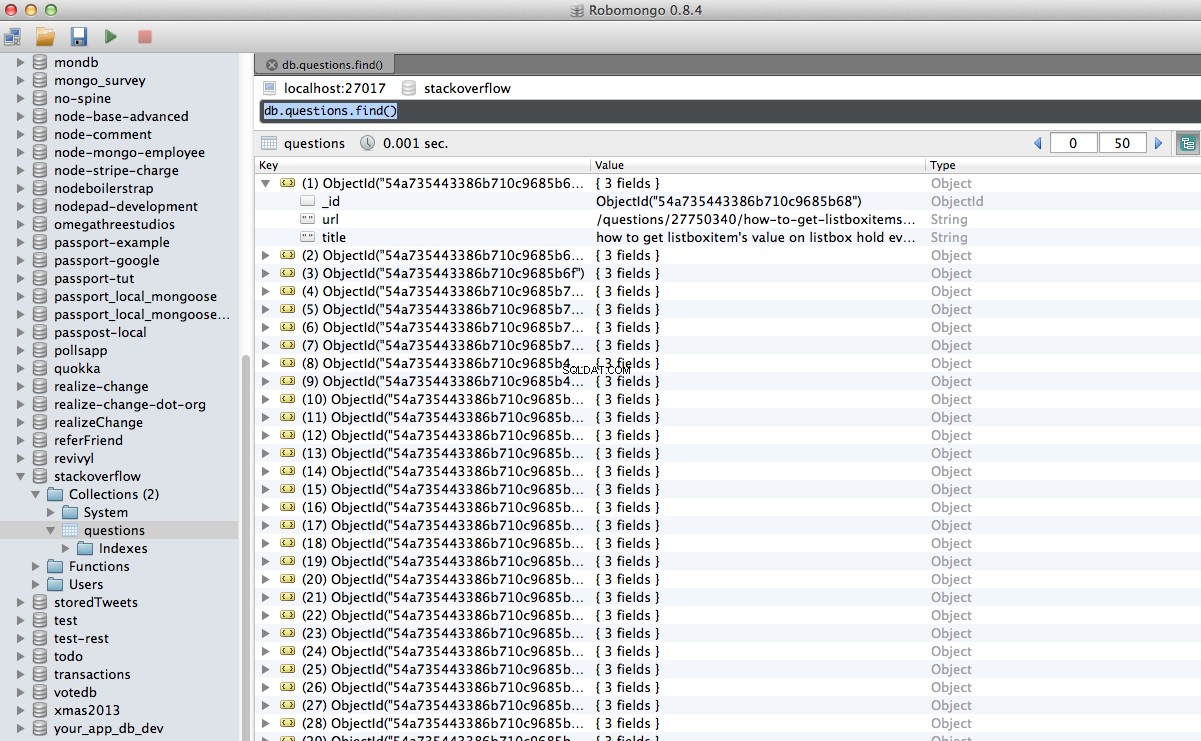
Kết luận
Đây là một ví dụ khá đơn giản về việc sử dụng Scrapy để thu thập thông tin và quét một trang web. Dự án tự do thực tế yêu cầu tập lệnh đi theo các liên kết phân trang và quét từng trang bằng cách sử dụng CrawlSpider (tài liệu), rất dễ thực hiện. Hãy thử tự thực hiện điều này và để lại nhận xét bên dưới cùng với liên kết đến kho lưu trữ Github để xem lại mã nhanh.
Cần giúp đỡ? Bắt đầu với tập lệnh này, gần như hoàn thành. Sau đó, hãy xem Phần 2 để biết giải pháp đầy đủ!
Tiền thưởng miễn phí: Nhấp vào đây để tải xuống khung dự án Python + MongoDB với mã nguồn đầy đủ hướng dẫn bạn cách truy cập MongoDB từ Python.
Bạn có thể tải xuống toàn bộ mã nguồn từ kho Github. Bình luận bên dưới nếu có câu hỏi. Cảm ơn bạn đã đọc!



