Một trong những mối quan tâm lớn nhất khi xử lý và quản lý cơ sở dữ liệu là độ phức tạp về kích thước và dữ liệu của nó. Thông thường, các tổ chức quan tâm đến việc làm thế nào để đối phó với tăng trưởng và quản lý tác động của tăng trưởng vì việc quản lý cơ sở dữ liệu không thành công. Sự phức tạp đi kèm với những mối quan tâm không được giải quyết ban đầu và không được nhìn thấy, hoặc có thể bị bỏ qua vì công nghệ hiện đang được sử dụng sẽ có thể tự xử lý. Việc quản lý một cơ sở dữ liệu lớn và phức tạp phải được lập kế hoạch phù hợp, đặc biệt khi loại dữ liệu bạn đang quản lý hoặc xử lý dự kiến sẽ phát triển ồ ạt theo dự đoán hoặc theo cách không thể đoán trước. Mục tiêu chính của việc lập kế hoạch là để tránh những thảm họa không mong muốn, hay chúng ta có thể nói rằng hãy tránh xa khói lửa! Trong blog này, chúng tôi sẽ đề cập đến cách quản lý hiệu quả các cơ sở dữ liệu lớn.
Kích thước dữ liệu quan trọng
Kích thước của cơ sở dữ liệu rất quan trọng vì nó có tác động đến hiệu suất và phương pháp quản lý của nó. Cách dữ liệu được xử lý và lưu trữ sẽ góp phần vào cách cơ sở dữ liệu sẽ được quản lý, áp dụng cho cả dữ liệu đang chuyển và ở trạng thái nghỉ. Đối với nhiều tổ chức lớn, dữ liệu là vàng và sự tăng trưởng về dữ liệu có thể có một sự thay đổi mạnh mẽ trong quá trình này. Do đó, điều quan trọng là phải có kế hoạch trước để xử lý dữ liệu ngày càng tăng trong cơ sở dữ liệu.
Theo kinh nghiệm làm việc với cơ sở dữ liệu, tôi đã chứng kiến khách hàng gặp vấn đề với việc xử lý các hình phạt về hiệu suất và quản lý tốc độ tăng trưởng dữ liệu khắc nghiệt. Các câu hỏi đặt ra liệu có nên chuẩn hóa các bảng hay không chuẩn hóa các bảng.
Chuẩn hóa Bảng
Chuẩn hóa bảng duy trì tính toàn vẹn của dữ liệu, giảm dư thừa và giúp dễ dàng tổ chức dữ liệu theo cách hiệu quả hơn để quản lý, phân tích và trích xuất. Làm việc với các bảng chuẩn hóa mang lại hiệu quả, đặc biệt là khi phân tích luồng dữ liệu và truy xuất dữ liệu bằng câu lệnh SQL hoặc làm việc với các ngôn ngữ lập trình như C / C ++, Java, Go, Ruby, PHP hoặc giao diện Python với MySQL Connector.
Mặc dù mối quan tâm với các bảng chuẩn hóa có ảnh hưởng đến hiệu suất và có thể làm chậm các truy vấn do chuỗi liên kết khi truy xuất dữ liệu. Trong khi các bảng không chuẩn hóa, tất cả những gì bạn phải xem xét để tối ưu hóa đều dựa vào chỉ mục hoặc khóa chính để lưu trữ dữ liệu vào bộ đệm để truy xuất nhanh hơn so với thực hiện tìm kiếm nhiều đĩa. Các bảng không chuẩn hóa không yêu cầu liên kết, nhưng nó hy sinh tính toàn vẹn của dữ liệu và kích thước cơ sở dữ liệu có xu hướng ngày càng lớn hơn.
Khi cơ sở dữ liệu của bạn lớn, hãy cân nhắc sử dụng DDL (Ngôn ngữ Định nghĩa Dữ liệu) cho bảng cơ sở dữ liệu của bạn trong MySQL / MariaDB. Việc thêm khóa chính hoặc khóa duy nhất cho bảng của bạn yêu cầu xây dựng lại bảng. Thay đổi kiểu dữ liệu cột cũng yêu cầu xây dựng lại bảng vì thuật toán thích hợp được áp dụng chỉ là ALGORITHM =COPY.
Nếu bạn đang làm việc này trong môi trường sản xuất của mình, nó có thể là một thách thức. Nhân đôi thách thức nếu bàn của bạn lớn. Hãy tưởng tượng một triệu hoặc một tỷ số hàng. Bạn không thể áp dụng câu lệnh ALTER TABLE trực tiếp cho bảng của mình. Điều đó có thể chặn tất cả lưu lượng đến cần truy cập vào bảng hiện bạn đang áp dụng DDL. Tuy nhiên, điều này có thể được giảm thiểu bằng cách sử dụng pt-online-schema-change hoặc gh-ost tuyệt vời. Tuy nhiên, nó yêu cầu giám sát và bảo trì trong khi thực hiện quá trình DDL.
Làm sắc nét và phân vùng
Với tính năng phân vùng và phân vùng, nó giúp tách biệt hoặc phân đoạn dữ liệu theo nhận dạng logic của chúng. Ví dụ:bằng cách tách biệt dựa trên ngày, thứ tự bảng chữ cái, quốc gia, tiểu bang hoặc khóa chính dựa trên phạm vi nhất định. Điều này giúp kích thước cơ sở dữ liệu của bạn có thể quản lý được. Giữ cho kích thước cơ sở dữ liệu của bạn ở mức giới hạn mà tổ chức và nhóm của bạn có thể quản lý được. Dễ mở rộng quy mô nếu cần thiết hoặc dễ quản lý, đặc biệt khi xảy ra thiên tai.
Khi chúng tôi nói có thể quản lý được, hãy xem xét tài nguyên dung lượng của máy chủ và cả nhóm kỹ thuật của bạn. Bạn không thể làm việc với dữ liệu lớn và lớn với ít kỹ sư. Làm việc với dữ liệu lớn như 1000 cơ sở dữ liệu với số lượng lớn các tập dữ liệu đòi hỏi một nhu cầu lớn về thời gian. Kỹ năng khôn ngoan và chuyên môn là phải. Nếu chi phí là một vấn đề, đó là thời điểm bạn có thể tận dụng các dịch vụ của bên thứ ba cung cấp dịch vụ được quản lý hoặc tư vấn có trả tiền hoặc hỗ trợ cho bất kỳ công việc kỹ thuật nào như vậy được thực hiện.
Bộ ký tự và đối chiếu
Bộ ký tự và đối chiếu ảnh hưởng đến hiệu suất và lưu trữ dữ liệu, đặc biệt là đối với bộ ký tự nhất định và đối chiếu được chọn. Mỗi bộ ký tự và các ảnh ghép đều có mục đích của nó và hầu hết yêu cầu độ dài khác nhau. Nếu bạn có các bảng yêu cầu các bộ ký tự và đối chiếu khác do mã hóa ký tự, thì dữ liệu sẽ được lưu trữ và xử lý cho cơ sở dữ liệu và bảng của bạn hoặc thậm chí với các cột.
Điều này ảnh hưởng đến cách quản lý cơ sở dữ liệu của bạn một cách hiệu quả. Nó ảnh hưởng đến việc lưu trữ dữ liệu của bạn và cũng như hiệu suất như đã nêu trước đó. Nếu bạn đã hiểu các loại ký tự được ứng dụng của mình xử lý, hãy lưu ý đến bộ ký tự và các đối chiếu sẽ được sử dụng. Bộ ký tự kiểu LATIN phải đủ hầu hết cho loại ký tự chữ và số được lưu trữ và xử lý.
Nếu không thể tránh khỏi, việc phân vùng và phân vùng sẽ giúp ít nhất giảm thiểu và hạn chế dữ liệu để tránh làm đầy quá nhiều dữ liệu trong máy chủ cơ sở dữ liệu của bạn. Việc quản lý dữ liệu rất lớn trên một máy chủ cơ sở dữ liệu duy nhất có thể ảnh hưởng đến hiệu quả, đặc biệt là cho các mục đích sao lưu, thảm họa và khôi phục hoặc khôi phục dữ liệu cũng như trong trường hợp dữ liệu bị hỏng hoặc mất dữ liệu.
Độ phức tạp của Cơ sở dữ liệu ảnh hưởng đến hiệu suất
Cơ sở dữ liệu lớn và phức tạp có xu hướng ảnh hưởng đến hiệu suất. Trong trường hợp này, phức tạp có nghĩa là nội dung cơ sở dữ liệu của bạn bao gồm các phương trình toán học, tọa độ hoặc các bản ghi tài chính và số. Bây giờ trộn các bản ghi này với các truy vấn đang tích cực sử dụng các hàm toán học có nguồn gốc từ cơ sở dữ liệu của nó. Hãy xem truy vấn SQL mẫu (tương thích với MySQL / MariaDB) bên dưới,
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
Hãy xem xét rằng truy vấn này được áp dụng trên một bảng có từ một triệu hàng. Có một khả năng rất lớn là điều này có thể làm máy chủ bị đình trệ và nó có thể tốn nhiều tài nguyên gây nguy hiểm cho sự ổn định của cụm cơ sở dữ liệu sản xuất của bạn. Các cột có liên quan có xu hướng được lập chỉ mục để tối ưu hóa và làm cho truy vấn này hoạt động hiệu quả. Tuy nhiên, việc thêm chỉ mục vào các cột được tham chiếu để có hiệu suất tối ưu không đảm bảo hiệu quả quản lý cơ sở dữ liệu lớn của bạn.
Khi xử lý độ phức tạp, cách hiệu quả hơn là tránh sử dụng nghiêm ngặt các phương trình toán học phức tạp và sử dụng tích cực khả năng tính toán phức tạp tích hợp sẵn này. Điều này có thể được vận hành và vận chuyển thông qua các tính toán phức tạp bằng cách sử dụng các ngôn ngữ lập trình phụ trợ thay vì sử dụng cơ sở dữ liệu. Nếu bạn có các phép tính phức tạp, vậy tại sao không lưu trữ các phương trình này trong cơ sở dữ liệu, truy xuất các truy vấn, sắp xếp nó thành một công cụ dễ phân tích hơn hoặc gỡ lỗi khi cần thiết.
Bạn có đang sử dụng công cụ cơ sở dữ liệu phù hợp không?
Cấu trúc dữ liệu ảnh hưởng đến hiệu suất của máy chủ cơ sở dữ liệu dựa trên sự kết hợp của truy vấn đã cho và các bản ghi được đọc hoặc truy xuất từ bảng. Các công cụ cơ sở dữ liệu trong MySQL / MariaDB hỗ trợ InnoDB và MyISAM sử dụng B-Trees, trong khi công cụ cơ sở dữ liệu NDB hoặc Bộ nhớ sử dụng Hash Mapping. Các cấu trúc dữ liệu này có ký hiệu tiệm cận, ký hiệu sau biểu thị hiệu suất của các thuật toán được sử dụng bởi các cấu trúc dữ liệu này. Chúng tôi gọi chúng trong Khoa học Máy tính là ký hiệu Big O mô tả hiệu suất hoặc độ phức tạp của một thuật toán. Cho rằng InnoDB và MyISAM sử dụng B-Trees, nó sử dụng O (log n) để tìm kiếm. Trong khi, Bảng băm hoặc Bản đồ băm sử dụng O (n). Cả hai đều chia sẻ trường hợp trung bình và trường hợp xấu nhất cho hiệu suất của nó với ký hiệu của nó.
Bây giờ trở lại công cụ cụ thể, với cấu trúc dữ liệu của công cụ, truy vấn được áp dụng dựa trên dữ liệu đích sẽ được truy xuất tất nhiên sẽ ảnh hưởng đến hiệu suất của máy chủ cơ sở dữ liệu của bạn. Bảng băm không thể thực hiện truy xuất phạm vi, trong khi B-Trees rất hiệu quả để thực hiện các loại tìm kiếm này và nó cũng có thể xử lý lượng lớn dữ liệu.
Sử dụng công cụ phù hợp cho dữ liệu bạn lưu trữ, bạn cần xác định loại truy vấn bạn áp dụng cho những dữ liệu cụ thể mà bạn lưu trữ. Loại logic nào mà những dữ liệu này sẽ hình thành khi nó chuyển đổi thành logic nghiệp vụ.
Xử lý hàng nghìn hoặc hàng nghìn cơ sở dữ liệu, sử dụng công cụ phù hợp kết hợp các truy vấn và dữ liệu mà bạn muốn truy xuất và lưu trữ sẽ mang lại hiệu suất tốt. Cho rằng bạn đã xác định trước và phân tích các yêu cầu của mình cho mục đích của nó cho môi trường cơ sở dữ liệu phù hợp.
Công cụ phù hợp để quản lý cơ sở dữ liệu lớn
Rất khó và khó quản lý một cơ sở dữ liệu rất lớn mà không có một nền tảng vững chắc mà bạn có thể dựa vào. Ngay cả với các kỹ sư cơ sở dữ liệu giỏi và có tay nghề cao, về mặt kỹ thuật, máy chủ cơ sở dữ liệu bạn đang sử dụng vẫn dễ bị lỗi do con người. Một sai sót trong bất kỳ thay đổi nào đối với các thông số và biến cấu hình của bạn có thể dẫn đến thay đổi lớn làm giảm hiệu suất của máy chủ.
Thực hiện sao lưu vào cơ sở dữ liệu của bạn trên một cơ sở dữ liệu rất lớn đôi khi có thể là một thách thức. Có những trường hợp sao lưu có thể không thành công vì một số lý do kỳ lạ. Thông thường, các truy vấn có thể làm ngưng trệ máy chủ nơi bản sao lưu đang chạy gây ra lỗi. Nếu không, bạn phải điều tra nguyên nhân của nó.
Sử dụng tự động hóa như Chef, Puppet, Ansible, Terraform hoặc SaltStack có thể được sử dụng làm IaC của bạn để cung cấp các tác vụ nhanh hơn để thực hiện. Đồng thời sử dụng các công cụ của bên thứ ba khác để giúp bạn giám sát và cung cấp hình ảnh đồ thị chất lượng cao. Hệ thống thông báo cảnh báo và cảnh báo cũng rất quan trọng để thông báo cho bạn về các vấn đề có thể xảy ra từ mức cảnh báo đến mức trạng thái quan trọng. Đây là lúc ClusterControl rất hữu ích trong tình huống này.
ClusterControl giúp dễ dàng quản lý một số lượng lớn cơ sở dữ liệu hoặc thậm chí với các loại môi trường được phân nhỏ. Nó đã được thử nghiệm và cài đặt hàng nghìn lần và đang chạy trong quá trình sản xuất cung cấp các cảnh báo và thông báo cho DBA, kỹ sư hoặc DevOps vận hành môi trường cơ sở dữ liệu. Từ giai đoạn tổ chức hoặc phát triển, QAs, đến môi trường sản xuất.
ClusterControl cũng có thể thực hiện sao lưu và khôi phục. Ngay cả với cơ sở dữ liệu lớn, nó có thể hiệu quả và dễ quản lý vì giao diện người dùng cung cấp tính năng lập lịch và cũng có các tùy chọn để tải nó lên đám mây (AWS, Google Cloud và Azure).
Ngoài ra còn có xác minh dự phòng và nhiều tùy chọn như mã hóa và nén. Xem ảnh chụp màn hình bên dưới chẳng hạn (tạo Bản sao lưu cho MySQL bằng Xtrabackup):
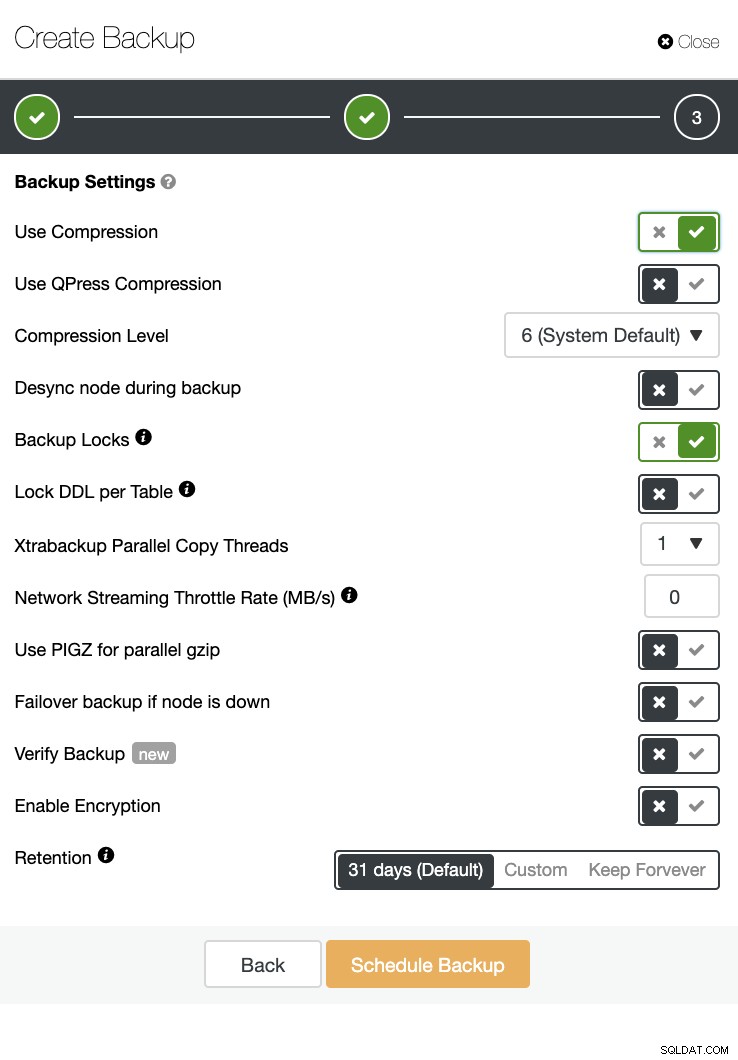
Kết luận
Quản lý cơ sở dữ liệu lớn như hàng nghìn hoặc nhiều hơn có thể được thực hiện một cách hiệu quả, nhưng nó phải được xác định và chuẩn bị trước. Việc sử dụng các công cụ phù hợp như tự động hóa hoặc thậm chí đăng ký các dịch vụ được quản lý sẽ giúp ích rất nhiều. Mặc dù phải trả chi phí, nhưng sự thay đổi của dịch vụ và ngân sách được rót để có được các kỹ sư lành nghề có thể giảm xuống miễn là có sẵn các công cụ phù hợp.



