Đây là phần 2 trong loạt blog này. Bạn có thể đọc phần 1, tại đây: Chuyển đổi kỹ thuật số là một hành trình dữ liệu từ Edge to Insight
Loạt blog này theo dõi dữ liệu sản xuất, hoạt động và bán hàng của một nhà sản xuất xe được kết nối khi dữ liệu trải qua các giai đoạn và quá trình biến đổi thường xảy ra trong một công ty sản xuất lớn với công nghệ tiên tiến nhất hiện nay. Blog đầu tiên đã giới thiệu một công ty sản xuất xe được kết nối giả, The Electric Car Company (ECC), để minh họa đường dẫn dữ liệu sản xuất thông qua vòng đời dữ liệu. Để thực hiện điều này, ECC đang tận dụng Nền tảng dữ liệu Cloudera (CDP) để dự đoán các sự kiện và có cái nhìn từ trên xuống về quy trình sản xuất ô tô trong các nhà máy của mình trên toàn cầu.
Sau khi hoàn thành bước Thu thập dữ liệu trong blog trước, bước tiếp theo của ECC trong vòng đời dữ liệu là Làm giàu dữ liệu. ECC sẽ làm phong phú thêm dữ liệu thu thập được và sẽ cung cấp dữ liệu đó để sử dụng trong phân tích và tạo mô hình sau này trong vòng đời dữ liệu. Dưới đây là toàn bộ tập hợp các bước trong vòng đời dữ liệu và mỗi bước trong vòng đời sẽ được hỗ trợ bởi một bài đăng blog chuyên dụng (xem Hình 1):
- Thu thập Dữ liệu - nhập dữ liệu và giám sát ở rìa (cho dù rìa là cảm biến công nghiệp hay người trong phòng trưng bày xe)
- Tăng cường Dữ liệu - xử lý, tổng hợp và quản lý đường ống dữ liệu để sẵn sàng dữ liệu cho các phân tích sâu hơn
- Báo cáo - cung cấp thông tin chi tiết về doanh nghiệp (phân tích và dự báo bán hàng, lập ngân sách làm ví dụ)
- Phục vụ - kiểm soát và điều hành các hoạt động kinh doanh thiết yếu (hoạt động của đại lý, giám sát sản xuất)
- Phân tích Dự đoán - phân tích dự đoán dựa trên AI và học máy (bảo trì dự đoán, tối ưu hóa khoảng không quảng cáo dựa trên nhu cầu làm ví dụ)
- Bảo mật &Quản trị - một bộ công nghệ bảo mật, quản lý và quản trị tích hợp trong toàn bộ vòng đời dữ liệu

Hình 1 Vòng đời dữ liệu doanh nghiệp
Thử thách làm giàu dữ liệu
ECC cần một cái nhìn toàn diện và hiểu biết rõ ràng về tất cả các dữ liệu liên quan đến quá trình sản xuất, hoạt động của đại lý và việc vận chuyển xe của họ. Họ cũng sẽ cần nhanh chóng xác định các vấn đề với dữ liệu, chẳng hạn như cảm biến hoạt động quay ra dữ liệu có thể bao gồm tăng đột biến nhiệt độ do máy ngừng hoạt động ngoài kế hoạch hoặc khởi động đột ngột. Chẳng hạn, dữ liệu không liên quan đến quy trình khi công nhân bảo trì tháo cảm biến khỏi bể nhúng axit trong khi thực hiện kiểm tra định kỳ trong quá trình phân tích.
Ngoài ra, ECC phải đối mặt với những thách thức về dữ liệu sau đây cần được giải quyết để chuyển thành công việc sản xuất động cơ thông qua chuỗi cung ứng của mình. Những thách thức về dữ liệu này bao gồm những điều sau:
- Truy xuất dữ liệu ở các định dạng khác nhau từ các nguồn khác nhau: Đường ống kỹ thuật dữ liệu yêu cầu dữ liệu được đưa đến từ nhiều nguồn khác nhau và ở nhiều định dạng khác nhau. Cho dù dữ liệu được lấy từ các cảm biến trên dây chuyền sản xuất, hỗ trợ hoạt động sản xuất hay dữ liệu ERP kiểm soát chuỗi cung ứng, tất cả dữ liệu đó phải được tập hợp lại với nhau để phân tích thêm.
- Lọc ra dữ liệu thừa hoặc không liên quan: Xóa dữ liệu trùng lặp hoặc không hợp lệ và đảm bảo tính chính xác của dữ liệu còn lại là bước quan trọng trong việc chuẩn bị dữ liệu để sử dụng thêm trong phân tích dự đoán nâng cao.
- Khả năng xác định các quy trình không hiệu quả: ECC yêu cầu khả năng xem quy trình dữ liệu nào đang chiếm nhiều thời gian và tài nguyên nhất, giúp bạn dễ dàng nhắm mục tiêu các phần hoạt động kém hiệu quả của quy trình để tăng tốc quy trình tổng thể.
- Khả năng giám sát tất cả các quy trình từ một ngăn duy nhất: ECC yêu cầu một hệ thống tập trung cho phép họ giám sát tất cả các quy trình dữ liệu đang diễn ra cũng như một con đường để mở rộng cơ sở hạ tầng hiện tại của họ trong khi duy trì tính minh bạch.
Bộ dữ liệu chất lượng, được tuyển chọn là xương sống của bất kỳ sáng kiến phân tích nâng cao nào. Để đạt được điều này, một khuôn khổ kỹ thuật dữ liệu phải được sử dụng để cho phép xây dựng tất cả các đường ống và đường ống dẫn nước cần thiết để di chuyển, thao tác và quản lý dữ liệu của các bộ phận xe khác nhau trong vòng đời dữ liệu.
Xây dựng đường ống bằng Kỹ thuật dữ liệu Cloudera
Trước khi dữ liệu được bổ sung và thảo luận trong blog đầu tiên, các luồng dữ liệu CNTT và OT được thu thập từ nhà máy sẽ được làm sạch, xử lý và sửa đổi. ID nhà máy, ID máy, dấu thời gian, số bộ phận và số sê-ri có thể được chụp từ mã QR in trên động cơ điện. Khi động cơ được lắp ráp vào phương tiện được kết nối, dữ liệu sẽ được thu thập, chẳng hạn như loại mô hình, số VIN và chi phí cơ sở của phương tiện.
Sau khi xe được bán, các thông tin bán hàng như tên khách hàng, thông tin liên hệ, giá bán cuối cùng và vị trí của khách hàng được ghi lại riêng biệt. Dữ liệu này sẽ rất quan trọng để liên hệ với khách hàng về bất kỳ khả năng thu hồi hoặc bảo trì phòng ngừa có mục tiêu. Dữ liệu vị trí địa lý cũng được lưu trữ, giúp lập bản đồ vị trí của khách hàng theo vĩ độ và kinh độ để hiểu rõ hơn vị trí của những động cơ này sau khi được bán trên xe.
ECC sẽ sử dụng Kỹ thuật Dữ liệu Cloudera (CDE) để giải quyết các thách thức về dữ liệu ở trên (xem Hình 2). Sau đó, CDE sẽ cung cấp dữ liệu cho Kho dữ liệu Cloudera (CDW), nơi dữ liệu sẽ được cung cấp cho các báo cáo phân tích nâng cao và thông tin kinh doanh. Các bước CDE được trình bày bên dưới.
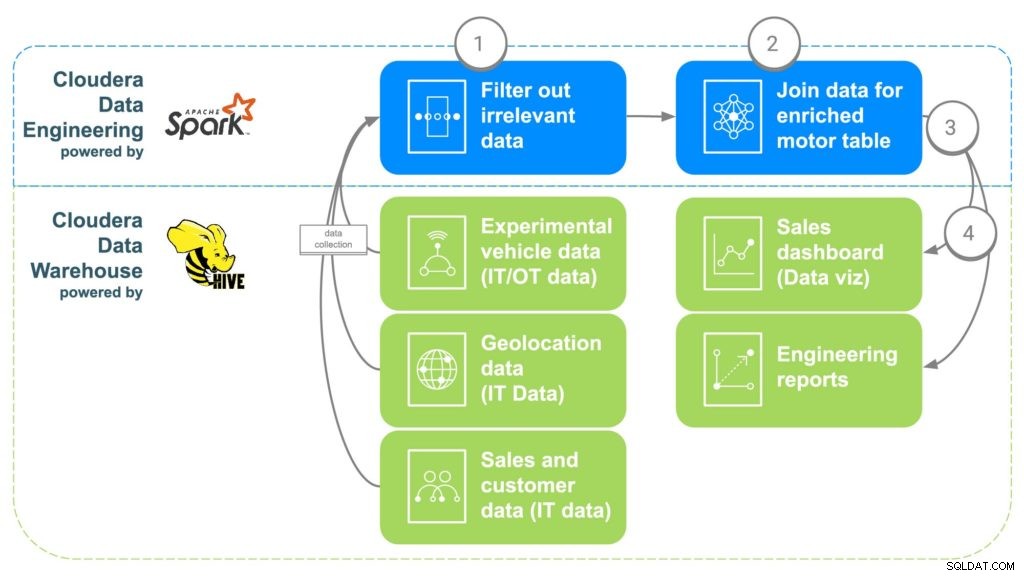
Hình 2 Đường ống làm giàu dữ liệu ECC
BƯỚC 1:Lọc và tách dữ liệu
Bước đầu tiên trong việc sử dụng CDE là tạo một công việc PySpark đưa dữ liệu từ các nguồn “thô” khác nhau này từ bước 1. Đây là cơ hội để lọc mọi dữ liệu không liên quan, chẳng hạn như khách hàng dưới 16 tuổi chẳng hạn, kể từ đó thường là độ tuổi lái xe tối thiểu. Dữ liệu trùng lặp và dữ liệu không liên quan khác cũng có thể được lọc hoặc tách ra.
BƯỚC 2:Kết hợp dữ liệu
Để kết hợp tất cả dữ liệu, CDE sẽ tương quan các liên kết chung với nhau. Đầu tiên, dữ liệu bán xe sẽ được gắn với khách hàng đã mua xe để lấy siêu dữ liệu của khách hàng, chẳng hạn như thông tin liên hệ, tuổi, lương, v.v. Sau đó, dữ liệu vị trí sẽ được sử dụng để lấy thông tin vị trí chính xác hơn cho khách hàng. , điều này sẽ giúp lập bản đồ các động cơ sau này. Dữ liệu lắp đặt bộ phận sẽ được sử dụng để xác định số sê-ri cho từng động cơ đã được lắp đặt trên ô tô của khách hàng. Cuối cùng, dữ liệu nhà máy sẽ được căn chỉnh để khớp với số sê-ri của động cơ sẽ xác định nhà máy, máy móc và thời điểm từng động cơ cụ thể được tạo ra.
BƯỚC 3:Gửi dữ liệu đến Kho dữ liệu Cloudera
Khi tất cả dữ liệu được tập hợp lại với nhau trong một bảng được bổ sung chi tiết, một lệnh Apache Spark đơn giản sẽ ghi dữ liệu vào một bảng mới trong Cloudera Data Warehouse. Điều này sẽ giúp cho bất kỳ nhà khoa học dữ liệu nào có thể muốn truy cập dữ liệu đó để thực hiện một số phân tích bổ sung.
BƯỚC 4:Tạo báo cáo và trang tổng quan trực quan hóa dữ liệu
Với dữ liệu tất cả ở một nơi, giờ đây có thể tạo báo cáo cho phép nhân viên đưa ra quyết định sáng suốt hơn và mở ra các khả năng không tồn tại. Bản đồ nhiệt có thể được thực hiện để theo dõi vị trí động cơ và tương quan bất kỳ vấn đề nào với vị trí địa lý tiềm ẩn, chẳng hạn như hỏng hóc do quá lạnh hoặc quá nóng. Dữ liệu này cũng có thể được sử dụng để theo dõi chính xác những gì khách hàng có thể bị ảnh hưởng nếu có sự cố xảy ra tại một nhà máy nhất định trong một khoảng thời gian, giúp dễ dàng theo dõi những khách hàng có thể cần thu hồi hoặc bảo trì phòng ngừa.
Kết luận
Cloudera Data Engineering cho phép ECC xây dựng một đường ống có thể tương quan với dữ liệu sản xuất và phụ tùng, loại hình sử dụng của khách hàng, điều kiện môi trường, thông tin bán hàng, v.v. để cải thiện sự hài lòng của khách hàng và độ tin cậy của phương tiện. ECC đã đạt được các mục tiêu và giải quyết những thách thức của họ bằng cách theo dõi dữ liệu liên quan đến việc sản xuất động cơ của mình và thu lợi theo những cách sau:
- ECC đã tăng thời gian để định giá bằng cách sắp xếp và tự động hóa các đường ống dữ liệu để cung cấp các bộ dữ liệu chất lượng, được quản lý một cách an toàn và minh bạch từ các nguồn dữ liệu khác nhau.
- ECC có thể xác định dữ liệu có liên quan và lọc ra mọi dữ liệu thừa và trùng lặp.
- ECC có thể giám sát đường ống dữ liệu từ một ngăn duy nhất, đồng thời ở vị trí được cảnh báo để phát hiện sớm các vấn đề thông qua xử lý sự cố trực quan để nhanh chóng giải quyết các vấn đề trước khi hoạt động kinh doanh bị ảnh hưởng.
Hãy tìm blog tiếp theo sẽ đi sâu vào Báo cáo sẽ hiển thị cách các kỹ sư ECC chạy các truy vấn đặc biệt trong CDW dựa trên dữ liệu được quản lý này cũng như kết hợp dữ liệu với các nguồn có liên quan khác trong kho dữ liệu doanh nghiệp. CDW tạo điều kiện để kết hợp tất cả dữ liệu lại với nhau và cung cấp công cụ trực quan hóa dữ liệu tích hợp để chuyển từ kết quả được truy vấn đến trang tổng quan. Hãy theo dõi phần tiếp theo!
Tài nguyên thu thập dữ liệu khác
Để xem tất cả những điều này đang hoạt động, vui lòng nhấp vào các liên kết có liên quan bên dưới để tìm hiểu thêm về cách làm giàu dữ liệu:
- Video - Nếu bạn muốn xem và nghe cách xây dựng video này, hãy xem video tại liên kết.
- Hướng dẫn - Nếu bạn muốn làm việc này theo tốc độ của riêng mình, hãy xem hướng dẫn chi tiết với ảnh chụp màn hình và hướng dẫn từng dòng về cách thiết lập và thực thi.
- Meetup - Nếu bạn muốn trò chuyện trực tiếp với các chuyên gia từ Cloudera, vui lòng tham gia buổi gặp mặt ảo để xem bản trình bày phát trực tiếp. Sẽ có thời gian cho phần Hỏi và Đáp trực tiếp khi kết thúc.
- Người dùng - Để xem thêm nội dung kỹ thuật cụ thể cho người dùng, hãy nhấp vào liên kết.



