Nâng cao hiệu suất hệ thống, đặc biệt đối với cấu trúc máy tính, đòi hỏi một quá trình để có được cái nhìn tổng quan về hiệu suất. Quá trình này thường được gọi là giám sát. Giám sát là một phần thiết yếu của quản lý cơ sở dữ liệu và thông tin chi tiết về hiệu suất của MongoDB sẽ không chỉ giúp bạn đánh giá trạng thái chức năng của nó; mà còn đưa ra manh mối về sự bất thường, điều này rất hữu ích khi thực hiện bảo trì. Điều cần thiết là xác định các hành vi bất thường và sửa chữa chúng trước khi chúng leo thang thành những thất bại nghiêm trọng hơn.
Một số loại lỗi có thể phát sinh là ...
- Trễ hoặc chậm lại
- Sự thiếu hụt tài nguyên
- Hệ thống trục trặc
Giám sát thường tập trung vào việc phân tích các số liệu. Một số chỉ số chính mà bạn sẽ muốn theo dõi bao gồm ...
- Hiệu suất của cơ sở dữ liệu
- Sử dụng tài nguyên (mức sử dụng CPU, bộ nhớ khả dụng và mức sử dụng mạng)
- Những thất bại mới nổi
- Sự bão hòa và giới hạn của các nguồn tài nguyên
- Hoạt động thông lượng
Trong blog này, chúng tôi sẽ thảo luận chi tiết về các số liệu này và xem xét các công cụ có sẵn từ MongoDB (chẳng hạn như các tiện ích và lệnh.) Chúng tôi cũng sẽ xem xét các công cụ phần mềm khác như Pandora, FMS Open Source và Robo 3T. Để đơn giản hơn, chúng tôi sẽ sử dụng phần mềm Robo 3T trong bài viết này để chứng minh các số liệu.
Hiệu suất của Cơ sở dữ liệu
Điều đầu tiên và quan trọng nhất để kiểm tra cơ sở dữ liệu là hiệu suất chung của nó, chẳng hạn như máy chủ có đang hoạt động hay không. Nếu bạn chạy lệnh này db.serverStatus () trên cơ sở dữ liệu trong Robo 3T, bạn sẽ thấy thông tin hiển thị trạng thái máy chủ của bạn.
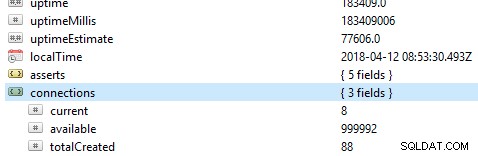

Bộ bản sao
Tập bản sao là một nhóm các quy trình mongod duy trì cùng một tập dữ liệu. Nếu bạn đang sử dụng bộ bản sao đặc biệt là trong chế độ sản xuất, nhật ký hoạt động sẽ cung cấp nền tảng cho quá trình sao chép. Tất cả các hoạt động ghi được theo dõi bằng cách sử dụng các nút, đó là nút chính và nút phụ, lưu trữ một bộ sưu tập có kích thước giới hạn. Trên nút chính, các thao tác ghi được áp dụng và xử lý. Tuy nhiên, nếu nút chính bị lỗi trước khi chúng được sao chép vào nhật ký hoạt động, thì việc ghi thứ cấp sẽ được thực hiện nhưng trong trường hợp này, dữ liệu có thể không được sao chép.
Các chỉ số chính cần theo dõi ...
Trễ sao chép
Điều này xác định khoảng cách mà nút phụ nằm sau nút chính. Một trạng thái tối ưu yêu cầu khoảng cách càng nhỏ càng tốt. Trên hệ điều hành bình thường, độ trễ này được ước tính là 0. Nếu khoảng cách quá rộng thì tính toàn vẹn của dữ liệu sẽ bị xâm phạm khi nút phụ được nâng cấp thành nút chính. Trong trường hợp này, bạn có thể đặt một ngưỡng, ví dụ như 1 phút và nếu vượt quá, một cảnh báo sẽ được đặt. Nguyên nhân phổ biến của độ trễ sao chép rộng bao gồm ...
- Các phân đoạn có thể có khả năng ghi không đủ thường liên quan đến tình trạng bão hòa tài nguyên.
- Nút phụ đang cung cấp dữ liệu với tốc độ chậm hơn so với nút chính.
- Các nút cũng có thể bị cản trở giao tiếp theo một cách nào đó, có thể do mạng kém.
- Các hoạt động trên nút chính cũng có thể chậm hơn, do đó chặn việc sao chép. Nếu điều này xảy ra, bạn có thể chạy các lệnh sau:
- db.getProfilingLevel ():nếu bạn nhận giá trị 0, thì các hoạt động db của bạn là tối ưu.
Nếu giá trị là 1, thì nó tương ứng với các hoạt động chậm do truy vấn chậm. - db.getProfilingStatus ():trong trường hợp này chúng tôi kiểm tra giá trị của slowms, theo mặc định là 100ms. Nếu giá trị lớn hơn giá trị này, thì bạn có thể đang thực hiện nhiều thao tác ghi trên tài nguyên chính hoặc không đủ tài nguyên trên tài nguyên thứ cấp. Để giải quyết vấn đề này, bạn có thể mở rộng quy mô phụ để nó có nhiều tài nguyên như chính.
- db.getProfilingLevel ():nếu bạn nhận giá trị 0, thì các hoạt động db của bạn là tối ưu.
Con trỏ
Nếu bạn thực hiện một yêu cầu đọc, chẳng hạn như tìm, bạn sẽ được cung cấp một con trỏ là một con trỏ đến tập dữ liệu của kết quả. Nếu bạn chạy lệnh này db.serverStatus () và điều hướng đến đối tượng số liệu rồi đến con trỏ, bạn sẽ thấy điều này…

Trong trường hợp này, thuộc tính cursor.timeOut được cập nhật tăng dần lên 9 vì có 9 kết nối bị chết mà không đóng con trỏ. Hậu quả là nó sẽ vẫn mở trên máy chủ và do đó tiêu tốn bộ nhớ, trừ khi nó được thu thập bởi cài đặt MongoDB mặc định. Một cảnh báo cho bạn nên xác định các con trỏ không hoạt động và loại bỏ chúng để lưu vào bộ nhớ. Bạn cũng có thể tránh các con trỏ không hết thời gian chờ vì chúng thường giữ tài nguyên, do đó làm chậm hiệu suất hệ thống nội bộ. Điều này có thể đạt được bằng cách đặt giá trị của thuộc tính cursor.open.noTimeout thành giá trị bằng 0.
Viết nhật ký
Xem xét Công cụ lưu trữ WiredTiger, trước khi dữ liệu được ghi, trước tiên nó sẽ được ghi vào tệp đĩa. Đây được gọi là viết nhật ký. Việc ghi nhật ký đảm bảo tính khả dụng và độ bền của dữ liệu khi có sự cố mà từ đó có thể tiến hành khôi phục.
Với mục đích khôi phục, chúng tôi thường sử dụng các điểm kiểm tra (đặc biệt đối với hệ thống lưu trữ WiredTiger) để khôi phục từ điểm kiểm tra cuối cùng. Tuy nhiên, nếu MongoDB tắt đột ngột, thì chúng tôi sử dụng kỹ thuật ghi nhật ký để khôi phục mọi dữ liệu đã được xử lý hoặc cung cấp sau điểm kiểm tra cuối cùng.
Không nên tắt tính năng ghi nhật ký trong trường hợp đầu tiên, vì chỉ mất khoảng 60 giây để tạo một trạm kiểm soát mới. Do đó, nếu xảy ra lỗi, MongoDB có thể phát lại nhật ký để khôi phục dữ liệu bị mất trong vòng vài giây.
Việc ghi nhật ký thường thu hẹp khoảng thời gian từ khi dữ liệu được đưa vào bộ nhớ cho đến khi dữ liệu bền trên đĩa. Đối tượng storage.journal có một thuộc tính mô tả tần số giới hạn, nghĩa là, commitIntervalMs thường được đặt thành giá trị 100ms cho WiredTiger. Điều chỉnh nó thành một giá trị thấp hơn sẽ tăng cường khả năng ghi lại các lần ghi thường xuyên, do đó giảm các trường hợp mất dữ liệu.
Hiệu suất khóa
Điều này có thể do nhiều yêu cầu đọc và ghi từ nhiều máy khách. Khi điều này xảy ra, cần phải giữ sự nhất quán và tránh xung đột khi viết. Để đạt được điều này MongoDB sử dụng khóa đa chi tiết cho phép các hoạt động khóa diễn ra ở các cấp độ khác nhau, chẳng hạn như cấp độ chung, cơ sở dữ liệu hoặc bộ sưu tập.
Nếu bạn có các mẫu thiết kế giản đồ kém, thì bạn sẽ dễ bị khóa trong thời gian dài. Điều này thường xảy ra khi thực hiện hai hoặc nhiều thao tác ghi khác nhau vào một tài liệu trong cùng một bộ sưu tập, với kết quả là chặn lẫn nhau. Đối với công cụ lưu trữ WiredTiger, chúng tôi có thể sử dụng hệ thống vé trong đó các yêu cầu đọc hoặc ghi đến từ thứ gì đó như hàng đợi hoặc luồng.
Theo mặc định, số lượng hoạt động đọc và ghi đồng thời được xác định bởi các tham số wiredTigerConcurrentWriteTransactions và wiredTigerConcurrentReadTransactions đều được đặt thành giá trị 128.
Nếu bạn chia tỷ lệ giá trị này quá cao thì bạn sẽ bị giới hạn bởi tài nguyên CPU. Để tăng các hoạt động thông lượng, bạn nên mở rộng quy mô theo chiều ngang bằng cách cung cấp nhiều phân đoạn hơn.
Vài người trở thành MongoDB DBA - Đưa MongoDB vào Sản xuất Tìm hiểu về những điều bạn cần biết để triển khai, giám sát, quản lý và mở rộng MongoDBDownload miễn phíSử dụng tài nguyên
Điều này thường mô tả việc sử dụng các tài nguyên có sẵn như dung lượng CPU / tốc độ xử lý và RAM. Hiệu suất, đặc biệt là đối với CPU có thể thay đổi đáng kể phù hợp với tải lưu lượng bất thường. Những điều cần kiểm tra bao gồm ...
- Số lượng kết nối
- Bộ nhớ
- Bộ nhớ đệm
Số lượng kết nối
Nếu số lượng kết nối cao hơn những gì hệ thống cơ sở dữ liệu có thể xử lý thì sẽ có rất nhiều xếp hàng. Do đó, điều này sẽ lấn át hiệu suất của cơ sở dữ liệu và làm cho thiết lập của bạn chạy chậm. Con số này có thể dẫn đến các vấn đề về trình điều khiển hoặc thậm chí phức tạp với ứng dụng của bạn.
Nếu bạn theo dõi một số lượng kết nối nhất định trong một khoảng thời gian nào đó và sau đó nhận thấy rằng giá trị đó đã đạt đến đỉnh điểm, bạn nên đặt cảnh báo nếu kết nối vượt quá con số này.
Nếu con số tăng quá cao thì bạn có thể mở rộng quy mô để phục vụ cho sự gia tăng này. Để làm được điều này, bạn phải biết số lượng kết nối có sẵn trong một khoảng thời gian nhất định, nếu không, nếu các kết nối khả dụng không đủ, thì các yêu cầu sẽ không được xử lý kịp thời.
Theo mặc định, MongoDB cung cấp hỗ trợ lên đến 1 triệu kết nối. Với sự giám sát của bạn, hãy luôn đảm bảo các kết nối hiện tại không bao giờ quá gần giá trị này. Bạn có thể kiểm tra giá trị trong đối tượng kết nối.

Bộ nhớ
Mọi hàng và bản ghi dữ liệu trong MongoDB được coi là một tài liệu. Dữ liệu tài liệu ở định dạng BSON. Trên một cơ sở dữ liệu nhất định, nếu bạn chạy lệnh db.stats (), bạn sẽ thấy dữ liệu này.
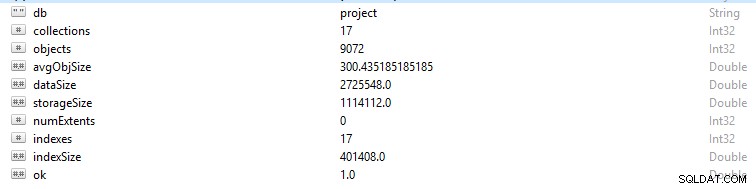
- StorageSize xác định kích thước của tất cả các phạm vi dữ liệu trong cơ sở dữ liệu.
- IndexSize phác thảo kích thước của tất cả các chỉ mục được tạo trong cơ sở dữ liệu đó.
- dataSize là thước đo tổng dung lượng mà các tài liệu trong cơ sở dữ liệu sử dụng.
Đôi khi bạn có thể thấy sự thay đổi trong bộ nhớ, đặc biệt nếu nhiều dữ liệu đã bị xóa. Trong trường hợp này, bạn nên thiết lập cảnh báo để đảm bảo đó không phải là do hoạt động độc hại.
Đôi khi, kích thước bộ nhớ tổng thể có thể tăng lên trong khi biểu đồ lưu lượng cơ sở dữ liệu không đổi và trong trường hợp này, bạn nên kiểm tra ứng dụng hoặc cấu trúc cơ sở dữ liệu của mình để tránh có bản sao nếu không cần thiết.
Giống như bộ nhớ chung của máy tính, MongoDB cũng có bộ nhớ đệm trong đó dữ liệu hoạt động được lưu trữ tạm thời. Tuy nhiên, một hoạt động có thể yêu cầu dữ liệu không có trong bộ nhớ hoạt động này, do đó thực hiện yêu cầu từ bộ nhớ đĩa chính. Yêu cầu hoặc tình huống này được gọi là lỗi trang. Yêu cầu lỗi trang đi kèm với hạn chế là mất nhiều thời gian hơn để thực thi và có thể gây bất lợi khi chúng xảy ra thường xuyên. Để tránh trường hợp này, hãy đảm bảo kích thước RAM của bạn luôn đủ để phục vụ cho các tập dữ liệu mà bạn đang làm việc. Bạn cũng nên đảm bảo rằng bạn không có dư thừa lược đồ hoặc các chỉ số không cần thiết.
Bộ nhớ đệm
Bộ nhớ đệm là một mục lưu trữ dữ liệu tạm thời cho dữ liệu được truy cập thường xuyên. Trong WiredTiger, bộ đệm ẩn của hệ thống tệp và bộ đệm của công cụ lưu trữ thường được sử dụng. Luôn đảm bảo rằng tập hợp làm việc của bạn không bị phình ra ngoài bộ nhớ cache có sẵn, nếu không, các lỗi trang sẽ tăng về số lượng gây ra một số vấn đề về hiệu suất.
Tại một số thời điểm, bạn có thể quyết định sửa đổi các hoạt động thường xuyên của mình, nhưng những thay đổi này đôi khi không được phản ánh trong bộ nhớ cache. Dữ liệu chưa được sửa đổi này được gọi là “Dữ liệu bẩn”. Nó tồn tại bởi vì nó vẫn chưa được xóa vào đĩa. Tắc nghẽn cổ chai sẽ xảy ra nếu lượng “Dữ liệu bẩn” tăng lên đến một giá trị trung bình nào đó được xác định bằng cách ghi chậm vào đĩa. Thêm nhiều phân đoạn hơn sẽ giúp giảm con số này.
Sử dụng CPU
Lập chỉ mục không đúng, cấu trúc lược đồ kém và các truy vấn được thiết kế không thân thiện sẽ đòi hỏi nhiều sự chú ý của CPU hơn, do đó rõ ràng sẽ làm tăng hiệu suất sử dụng của nó.
Hoạt động thông lượng
Ở mức độ lớn, việc thu thập đủ thông tin về các hoạt động này có thể giúp người ta tránh được những thất bại do hậu quả như lỗi, bão hòa tài nguyên và các biến chứng về chức năng.
Bạn phải luôn ghi nhớ số lượng các thao tác đọc và ghi vào cơ sở dữ liệu, tức là chế độ xem cấp cao về các hoạt động của cụm. Biết số lượng hoạt động được tạo cho các yêu cầu sẽ cho phép bạn tính toán tải mà cơ sở dữ liệu dự kiến sẽ xử lý. Sau đó, tải có thể được xử lý hoặc mở rộng cơ sở dữ liệu của bạn hoặc mở rộng quy mô; tùy thuộc vào loại tài nguyên bạn có. Điều này cho phép bạn dễ dàng đánh giá tỷ lệ thương số mà các yêu cầu đang tích lũy với tốc độ mà chúng đang được xử lý. Hơn nữa, bạn có thể tối ưu hóa các truy vấn của mình một cách thích hợp để cải thiện hiệu suất.
Để kiểm tra số lượng thao tác đọc và ghi, hãy chạy lệnh này db.serverStatus (), sau đó điều hướng đến đối tượng lock.global, giá trị cho thuộc tính r đại diện cho số lượng yêu cầu đọc và w số lần ghi.
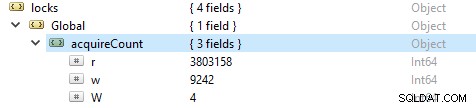
Thường thì các thao tác đọc nhiều hơn các thao tác ghi. Các chỉ số khách hàng đang hoạt động được báo cáo trong globalLock.
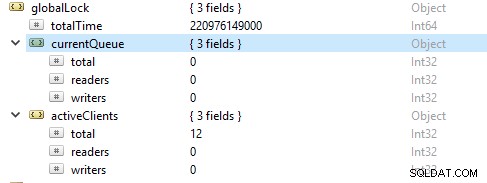
Bão hòa và giới hạn tài nguyên
Đôi khi cơ sở dữ liệu có thể không theo kịp tốc độ ghi và đọc, như được mô tả bởi số lượng yêu cầu xếp hàng ngày càng tăng. Trong trường hợp này, bạn phải mở rộng cơ sở dữ liệu của mình bằng cách cung cấp nhiều phân đoạn hơn để cho phép MongoDB giải quyết các yêu cầu đủ nhanh.
Những trở ngại mới nổi
Các tệp nhật ký MongoDB luôn cung cấp tổng quan chung về các ngoại lệ xác nhận được trả về. Kết quả này sẽ cung cấp cho bạn manh mối về các nguyên nhân có thể gây ra lỗi. Nếu bạn chạy lệnh, db.serverStatus (), một số cảnh báo lỗi mà bạn sẽ lưu ý bao gồm:

- Xác nhận thông thường:đây là kết quả của sự cố hoạt động. Ví dụ:trong một lược đồ nếu một giá trị chuỗi được cung cấp cho một trường số nguyên do đó dẫn đến không thể đọc tài liệu BSON.
- Cảnh báo khẳng định:đây thường là những cảnh báo về một số vấn đề nhưng không ảnh hưởng nhiều đến hoạt động của nó. Ví dụ:khi nâng cấp MongoDB, bạn có thể nhận được thông báo về việc sử dụng các chức năng không dùng nữa.
- Msg khẳng định:chúng là kết quả của các trường hợp ngoại lệ của máy chủ nội bộ, chẳng hạn như mạng chậm hoặc nếu máy chủ không hoạt động.
- Xác nhận của người dùng:giống như các xác nhận thông thường, những lỗi này phát sinh khi thực hiện một lệnh nhưng chúng thường được trả lại cho máy khách. Ví dụ:nếu có các khóa trùng lặp, không gian đĩa không đủ hoặc không có quyền truy cập để ghi vào cơ sở dữ liệu. Bạn sẽ chọn kiểm tra ứng dụng của mình để sửa những lỗi này.



