Hiệu quả của cơ sở dữ liệu không chỉ dựa vào việc tinh chỉnh các tham số quan trọng nhất, mà còn đi xa hơn để trình bày dữ liệu thích hợp trong các bộ sưu tập liên quan. Gần đây, tôi đã làm việc trong một dự án phát triển ứng dụng trò chuyện xã hội và sau một vài ngày thử nghiệm, chúng tôi nhận thấy một số độ trễ khi tìm nạp dữ liệu từ cơ sở dữ liệu. Chúng tôi không có quá nhiều người dùng, vì vậy chúng tôi đã loại trừ việc điều chỉnh các thông số cơ sở dữ liệu và tập trung vào các truy vấn của chúng tôi để tìm ra nguyên nhân gốc rễ.
Trước sự ngạc nhiên của chúng tôi, chúng tôi nhận ra rằng cấu trúc dữ liệu của chúng tôi không hoàn toàn phù hợp vì chúng tôi có nhiều hơn 1 yêu cầu đọc để tìm nạp một số thông tin cụ thể.
Mô hình khái niệm về cách các phần ứng dụng được đưa vào vị trí phụ thuộc rất nhiều vào cấu trúc bộ sưu tập cơ sở dữ liệu. Ví dụ:nếu bạn đăng nhập vào một ứng dụng xã hội, dữ liệu sẽ được đưa vào các phần khác nhau theo thiết kế ứng dụng như được mô tả từ bản trình bày cơ sở dữ liệu.
Tóm lại, đối với một cơ sở dữ liệu được thiết kế tốt, cấu trúc lược đồ và các mối quan hệ tập hợp là những điều quan trọng để cải thiện tốc độ và tính toàn vẹn của nó như chúng ta sẽ thấy trong các phần sau.
Chúng tôi sẽ thảo luận về các yếu tố bạn nên xem xét khi lập mô hình dữ liệu của mình.
Mô hình hóa dữ liệu là gì
Mô hình hóa dữ liệu nói chung là phân tích các mục dữ liệu trong cơ sở dữ liệu và mức độ liên quan của chúng với các đối tượng khác trong cơ sở dữ liệu đó.
Trong MongoDB chẳng hạn, chúng ta có thể có một bộ sưu tập người dùng và một bộ sưu tập hồ sơ. Bộ sưu tập người dùng liệt kê tên của những người dùng cho một ứng dụng nhất định trong khi bộ sưu tập hồ sơ ghi lại cài đặt hồ sơ cho mỗi người dùng.
Trong mô hình hóa dữ liệu, chúng ta cần thiết kế một mối quan hệ để kết nối từng người dùng với hồ sơ đối tượng. Tóm lại, mô hình hóa dữ liệu là bước cơ bản trong thiết kế cơ sở dữ liệu bên cạnh việc hình thành cơ sở kiến trúc cho lập trình hướng đối tượng. Nó cũng cung cấp manh mối về việc ứng dụng vật lý sẽ trông như thế nào trong quá trình phát triển. Kiến trúc tích hợp cơ sở dữ liệu-ứng dụng có thể được minh họa như bên dưới.
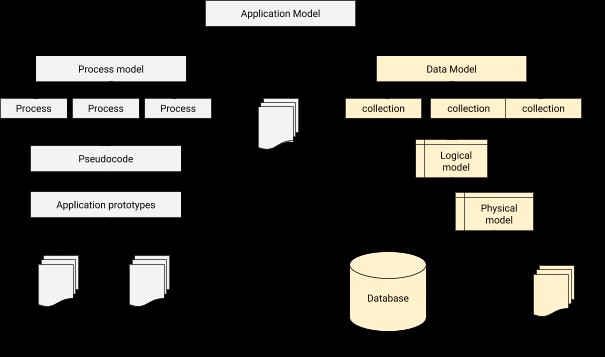
Quy trình lập mô hình dữ liệu trong MongoDB
Mô hình hóa dữ liệu đi kèm với cải thiện hiệu suất cơ sở dữ liệu, nhưng có một số cân nhắc bao gồm:
- Các mẫu truy xuất dữ liệu
- Cân bằng các nhu cầu của ứng dụng như:truy vấn, cập nhật và xử lý dữ liệu
- Các tính năng hiệu suất của công cụ cơ sở dữ liệu đã chọn
- Cấu trúc vốn có của chính dữ liệu
Cấu trúc tài liệu MongoDB
Các tài liệu trong MongoDB đóng một vai trò quan trọng trong việc đưa ra quyết định áp dụng kỹ thuật nào cho một bộ dữ liệu nhất định. Nhìn chung, có hai mối quan hệ giữa dữ liệu, đó là:
- Dữ liệu được nhúng
- Dữ liệu Tham chiếu
Dữ liệu được nhúng
Trong trường hợp này, dữ liệu liên quan được lưu trữ trong một tài liệu đơn lẻ dưới dạng giá trị trường hoặc một mảng trong chính tài liệu đó. Ưu điểm chính của cách tiếp cận này là dữ liệu không được chuẩn hóa và do đó tạo cơ hội để thao tác dữ liệu liên quan trong một thao tác cơ sở dữ liệu duy nhất. Do đó, điều này cải thiện tốc độ thực hiện các hoạt động CRUD, do đó cần ít truy vấn hơn. Hãy xem xét một ví dụ về tài liệu dưới đây:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"Settings" : {
"location" : "Embassy",
"ParentPhone" : 724765986
"bus" : "KAZ 450G",
"distance" : "4",
"placeLocation" : {
"lat" : -0.376252,
"lng" : 36.937389
}
}
}Trong tập dữ liệu này, chúng tôi có một học sinh với tên của anh ta và một số thông tin bổ sung khác. Trường Cài đặt đã được nhúng với một đối tượng và hơn nữa trường Vị trí cũng được nhúng với một đối tượng có cấu hình vĩ độ và kinh độ. Tất cả dữ liệu cho sinh viên này đã được chứa trong một tài liệu duy nhất. Nếu chúng tôi cần tìm nạp tất cả thông tin cho sinh viên này, chúng tôi chỉ chạy:
db.students.findOne({StudentName : "George Beckonn"})Điểm mạnh của Nhúng
- Tăng tốc độ truy cập dữ liệu:Để có tốc độ truy cập dữ liệu được cải thiện, nhúng là lựa chọn tốt nhất vì một thao tác truy vấn có thể thao tác dữ liệu trong tài liệu được chỉ định chỉ với một lần tra cứu cơ sở dữ liệu.
- Giảm tính nhất quán của dữ liệu:Trong quá trình hoạt động, nếu có sự cố (ví dụ:ngắt kết nối mạng hoặc mất điện), chỉ một số tài liệu có thể bị ảnh hưởng vì các tiêu chí thường chọn một tài liệu duy nhất.
- Giảm hoạt động CRUD. Điều này có nghĩa là, các thao tác đọc sẽ thực sự nhiều hơn các thao tác ghi. Bên cạnh đó, có thể cập nhật dữ liệu liên quan trong một thao tác ghi đơn nguyên tử. Tức là đối với dữ liệu trên, chúng tôi có thể cập nhật số điện thoại và cũng có thể tăng khoảng cách chỉ với một thao tác sau:
db.students.updateOne({StudentName : "George Beckonn"}, { $set: {"ParentPhone" : 72436986}, $inc: {"Settings.distance": 1} })
Điểm yếu của việc nhúng
- Kích thước tài liệu bị hạn chế. Tất cả các tài liệu trong MongoDB bị giới hạn ở kích thước BSON là 16 megabyte. Do đó, kích thước tài liệu tổng thể cùng với dữ liệu nhúng không được vượt quá giới hạn này. Nếu không, đối với một số công cụ lưu trữ như MMAPv1, dữ liệu có thể phát triển nhanh hơn và dẫn đến phân mảnh dữ liệu do hiệu suất ghi bị giảm sút.
- Sao chép dữ liệu:nhiều bản sao của cùng một dữ liệu khiến việc truy vấn dữ liệu được sao chép trở nên khó khăn hơn và có thể mất nhiều thời gian hơn để lọc các tài liệu nhúng, do đó làm mất đi lợi thế cốt lõi của việc nhúng.
Ký hiệu dấu chấm
Ký hiệu dấu chấm là đặc điểm nhận dạng cho dữ liệu nhúng trong phần lập trình. Nó được sử dụng để truy cập các phần tử của một trường hoặc một mảng được nhúng. Trong dữ liệu mẫu ở trên, chúng tôi có thể trả về thông tin của sinh viên có vị trí là "Đại sứ quán" với truy vấn này bằng cách sử dụng ký hiệu dấu chấm.
db.users.find({'Settings.location': 'Embassy'})Dữ liệu Tham chiếu
Mối quan hệ dữ liệu trong trường hợp này là dữ liệu liên quan được lưu trữ trong các tài liệu khác nhau, nhưng một số liên kết tham chiếu được cấp cho các tài liệu liên quan này. Đối với dữ liệu mẫu ở trên, chúng tôi có thể tạo lại dữ liệu đó theo cách:
Tài liệu người dùng
{ "_id" : xyz,
"StudentName" : "George Beckonn",
"ParentPhone" : 075646344,
}Tài liệu cài đặt
{
"id" :xyz,
"location" : "Embassy",
"bus" : "KAZ 450G",
"distance" : "4",
"lat" : -0.376252,
"lng" : 36.937389
}Có 2 tài liệu khác nhau, nhưng chúng được liên kết bởi cùng một giá trị cho các trường _id và id. Do đó, mô hình dữ liệu được chuẩn hóa. Tuy nhiên, để chúng tôi truy cập thông tin từ một tài liệu liên quan, chúng tôi cần đưa ra các truy vấn bổ sung và do đó điều này dẫn đến tăng thời gian thực hiện. Ví dụ:nếu chúng tôi muốn cập nhật ParentPhone và các cài đặt khoảng cách liên quan, chúng tôi sẽ có ít nhất 3 truy vấn, tức là
//fetch the id of a matching student
var studentId = db.students.findOne({"StudentName" : "George Beckonn"})._id
//use the id of a matching student to update the ParentPhone in the Users document
db.students.updateOne({_id : studentId}, {
$set: {"ParentPhone" : 72436986},
})
//use the id of a matching student to update the distance in settings document
db.students.updateOne({id : studentId}, {
$inc: {"distance": 1}
})Điểm mạnh của việc tham khảo
- Tính nhất quán của dữ liệu. Đối với mọi tài liệu, một biểu mẫu chuẩn được duy trì, do đó khả năng dữ liệu không nhất quán là khá thấp.
- Cải thiện tính toàn vẹn của dữ liệu. Do quá trình chuẩn hóa, bạn có thể dễ dàng cập nhật dữ liệu bất kể độ dài thời lượng hoạt động và do đó đảm bảo dữ liệu chính xác cho mọi tài liệu mà không gây ra bất kỳ sự nhầm lẫn nào.
- Cải thiện việc sử dụng bộ nhớ cache. Các tài liệu chuẩn được truy cập thường xuyên được lưu trữ trong bộ nhớ cache thay vì các tài liệu nhúng được truy cập một vài lần.
- Sử dụng phần cứng hiệu quả. Trái ngược với việc nhúng có thể dẫn đến việc tài liệu bị tràn ra ngoài, việc tham chiếu không thúc đẩy sự phát triển của tài liệu, do đó làm giảm mức sử dụng đĩa và RAM.
- Cải thiện tính linh hoạt, đặc biệt là với một tập hợp lớn các tài liệu con.
- Viết nhanh hơn.
Điểm yếu của việc tham khảo
- Nhiều lần tra cứu:Vì chúng tôi phải tìm một số tài liệu phù hợp với tiêu chí nên thời gian đọc tăng lên khi truy xuất từ đĩa. Ngoài ra, điều này có thể dẫn đến lỗi bộ nhớ cache.
- Nhiều truy vấn được đưa ra để đạt được một số hoạt động, do đó, các mô hình dữ liệu chuẩn hóa yêu cầu nhiều vòng quay hơn đến máy chủ để hoàn thành một hoạt động cụ thể.
Chuẩn hóa dữ liệu
Chuẩn hóa dữ liệu đề cập đến việc cơ cấu lại cơ sở dữ liệu theo một số dạng thông thường để cải thiện tính toàn vẹn của dữ liệu và giảm các sự kiện dư thừa dữ liệu.
Mô hình hóa dữ liệu xoay quanh 2 kỹ thuật chuẩn hóa chính đó là:
-
Mô hình dữ liệu chuẩn hóa
Như được áp dụng trong dữ liệu tham chiếu, chuẩn hóa chia dữ liệu thành nhiều tập hợp với các tham chiếu giữa các tập hợp mới. Một bản cập nhật tài liệu duy nhất sẽ được cấp cho bộ sưu tập khác và được áp dụng tương ứng cho tài liệu phù hợp. Điều này cung cấp một biểu diễn cập nhật dữ liệu hiệu quả và thường được sử dụng cho dữ liệu thay đổi khá thường xuyên.
-
Mô hình dữ liệu chuẩn hóa
Dữ liệu chứa các tài liệu nhúng do đó làm cho hoạt động đọc khá hiệu quả. Tuy nhiên, nó có liên quan đến việc sử dụng nhiều dung lượng đĩa hơn và cũng có những khó khăn để giữ đồng bộ. Khái niệm bất chuẩn hóa có thể được áp dụng tốt cho các tài liệu con có dữ liệu không thay đổi thường xuyên.
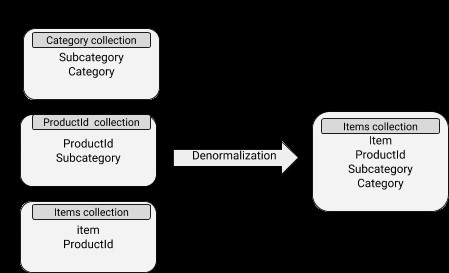
Lược đồ MongoDB
Về cơ bản, một lược đồ là một khung bao gồm các trường và kiểu dữ liệu mà mỗi trường phải chứa cho một tập dữ liệu nhất định. Xét theo quan điểm SQL, tất cả các hàng được thiết kế để có các cột giống nhau và mỗi cột phải chứa kiểu dữ liệu đã xác định. Tuy nhiên, trong MongoDB, chúng tôi có một Lược đồ linh hoạt theo mặc định không giữ cùng một sự phù hợp cho tất cả các tài liệu.
Lược đồ linh hoạt
Một lược đồ linh hoạt trong MongoDB xác định rằng các tài liệu không nhất thiết phải có các trường hoặc kiểu dữ liệu giống nhau, vì một trường có thể khác nhau giữa các tài liệu trong một bộ sưu tập. Ưu điểm cốt lõi của khái niệm này là người ta có thể thêm các trường mới, xóa các trường hiện có hoặc thay đổi các giá trị trường thành một kiểu mới và do đó cập nhật tài liệu thành một cấu trúc mới.
Ví dụ, chúng ta có thể có 2 tài liệu này trong cùng một bộ sưu tập:
{ "_id" : ObjectId("5b98bfe7e8b9ab9875e4c80c"),
"StudentName" : "George Beckonn",
"ParentPhone" : 75646344,
"age" : 10
}
{ "_id" : ObjectId("5b98bfe7e8b9ab98757e8b9a"),
"StudentName" : "Fredrick Wesonga",
"ParentPhone" : false,
}Trong tài liệu đầu tiên, chúng tôi có trường tuổi trong khi trong tài liệu thứ hai không có trường tuổi. Hơn nữa, kiểu dữ liệu cho trường ParentPhone là một số trong khi trong tài liệu thứ hai, nó đã được đặt thành false, là kiểu boolean.
Tính linh hoạt của lược đồ tạo điều kiện thuận lợi cho việc ánh xạ các tài liệu tới một đối tượng và mỗi tài liệu có thể khớp với các trường dữ liệu của thực thể được đại diện.
Lược đồ cứng nhắc
Nhiều như chúng tôi đã nói rằng những tài liệu này có thể khác nhau, đôi khi bạn có thể quyết định tạo một lược đồ cứng nhắc. Một lược đồ cứng nhắc sẽ xác định rằng tất cả các tài liệu trong một bộ sưu tập sẽ chia sẻ cùng một cấu trúc và điều này sẽ cho bạn cơ hội tốt hơn để đặt một số quy tắc xác thực tài liệu như một cách cải thiện tính toàn vẹn của dữ liệu trong quá trình chèn và cập nhật.
Các kiểu dữ liệu lược đồ
Khi sử dụng một số trình điều khiển máy chủ cho MongoDB chẳng hạn như mongoose, có một số kiểu dữ liệu được cung cấp cho phép bạn xác thực dữ liệu. Các kiểu dữ liệu cơ bản là:
- Chuỗi
- Số
- Boolean
- Ngày tháng
- Bộ đệm
- ObjectId
- Mảng
- Hỗn hợp
- Decimal128
- Bản đồ
Hãy xem lược đồ mẫu bên dưới
var userSchema = new mongoose.Schema({
userId: Number,
Email: String,
Birthday: Date,
Adult: Boolean,
Binary: Buffer,
height: Schema.Types.Decimal128,
units: []
});Trường hợp sử dụng mẫu
var user = mongoose.model(‘Users’, userSchema )
var newUser = new user;
newUser.userId = 1;
newUser.Email = “example@sqldat.com”;
newUser.Birthday = new Date;
newUser.Adult = false;
newUser.Binary = Buffer.alloc(0);
newUser.height = 12.45;
newUser.units = [‘Circuit network Theory’, ‘Algerbra’, ‘Calculus’];
newUser.save(callbackfunction);Xác thực giản đồ
Bạn có thể thực hiện xác thực dữ liệu từ phía ứng dụng nhiều nhất có thể, bạn cũng nên thực hiện xác thực từ phía máy chủ. Chúng tôi đạt được điều này bằng cách sử dụng các quy tắc xác thực giản đồ.
Các quy tắc này được áp dụng trong các hoạt động chèn và cập nhật. Chúng được khai báo trên cơ sở tập hợp trong quá trình tạo một cách bình thường. Tuy nhiên, bạn cũng có thể thêm các quy tắc xác thực tài liệu vào bộ sưu tập hiện có bằng cách sử dụng lệnh collMod với các tùy chọn trình xác thực nhưng các quy tắc này không được áp dụng cho các tài liệu hiện có cho đến khi áp dụng bản cập nhật cho chúng.
Tương tự như vậy, khi tạo một bộ sưu tập mới bằng lệnh db.createCollection (), bạn có thể đưa ra tùy chọn trình xác nhận. Hãy xem ví dụ này khi tạo một bộ sưu tập cho học sinh. Từ phiên bản 3.6, MongoDB hỗ trợ xác thực Lược đồ JSON, do đó tất cả những gì bạn cần là sử dụng toán tử $ jsonSchema.
db.createCollection("students", {
validator: {$jsonSchema: {
bsonType: "object",
required: [ "name", "year", "major", "gpa" ],
properties: {
name: {
bsonType: "string",
description: "must be a string and is required"
},
gender: {
bsonType: "string",
description: "must be a string and is not required"
},
year: {
bsonType: "int",
minimum: 2017,
maximum: 3017,
exclusiveMaximum: false,
description: "must be an integer in [ 2017, 2020 ] and is required"
},
major: {
enum: [ "Math", "English", "Computer Science", "History", null ],
description: "can only be one of the enum values and is required"
},
gpa: {
bsonType: [ "double" ],
minimum: 0,
description: "must be a double and is required"
}
}
}})Trong thiết kế giản đồ này, nếu chúng ta cố gắng chèn một tài liệu mới như:
db.students.insert({
name: "James Karanja",
year: NumberInt(2016),
major: "History",
gpa: NumberInt(3)
})Hàm gọi lại sẽ trả về lỗi bên dưới do một số quy tắc xác thực bị vi phạm chẳng hạn như giá trị năm được cung cấp không nằm trong giới hạn đã chỉ định.
WriteResult({
"nInserted" : 0,
"writeError" : {
"code" : 121,
"errmsg" : "Document failed validation"
}
})Hơn nữa, bạn có thể thêm các biểu thức truy vấn vào tùy chọn xác thực của mình bằng cách sử dụng các toán tử truy vấn ngoại trừ $ where, $ text, near và $ nearSphere, tức là:
db.createCollection( "contacts",
{ validator: { $or:
[
{ phone: { $type: "string" } },
{ email: { $regex: /@mongodb\.com$/ } },
{ status: { $in: [ "Unknown", "Incomplete" ] } }
]
}
} )Các cấp độ xác thực giản đồ
Như đã đề cập trước đây, thông thường, xác thực được cấp cho các hoạt động ghi.
Tuy nhiên, xác thực cũng có thể được áp dụng cho các tài liệu đã có.
Có 3 cấp độ xác nhận:
- Nghiêm ngặt:đây là mức xác thực MongoDB mặc định và nó áp dụng các quy tắc xác thực cho tất cả các lần chèn và bản cập nhật.
- Trung bình:Các quy tắc xác thực được áp dụng trong quá trình chèn, cập nhật và cho các tài liệu hiện có chỉ đáp ứng các tiêu chí xác thực.
- Tắt:mức này đặt các quy tắc xác thực cho một lược đồ nhất định thành rỗng, do đó sẽ không có xác thực nào được thực hiện đối với các tài liệu.
Ví dụ:
Hãy chèn dữ liệu bên dưới vào bộ sưu tập khách hàng.
db.clients.insert([
{
"_id" : 1,
"name" : "Brillian",
"phone" : "+1 778 574 666",
"city" : "Beijing",
"status" : "Married"
},
{
"_id" : 2,
"name" : "James",
"city" : "Peninsula"
}
]Nếu chúng tôi áp dụng mức xác thực vừa phải bằng cách sử dụng:
db.runCommand( {
collMod: "test",
validator: { $jsonSchema: {
bsonType: "object",
required: [ "phone", "name" ],
properties: {
phone: {
bsonType: "string",
description: "must be a string and is required"
},
name: {
bsonType: "string",
description: "must be a string and is required"
}
}
} },
validationLevel: "moderate"
} )Các quy tắc xác thực sẽ chỉ được áp dụng cho tài liệu có _id là 1 vì nó sẽ phù hợp với tất cả các tiêu chí.
Đối với tài liệu thứ hai, vì các quy tắc xác thực không được đáp ứng với các tiêu chí đã ban hành, nên tài liệu sẽ không được xác thực.
Hành động xác thực giản đồ
Sau khi thực hiện xác thực trên các tài liệu, có thể có một số tài liệu có thể vi phạm các quy tắc xác thực. Luôn luôn cần phải cung cấp một hành động khi điều này xảy ra.
MongoDB cung cấp hai hành động có thể được cấp cho các tài liệu không tuân theo quy tắc xác thực:
- Lỗi:đây là hành động MongoDB mặc định, từ chối mọi chèn hoặc cập nhật trong trường hợp vi phạm tiêu chí xác thực.
-
Cảnh báo:Hành động này sẽ ghi lại vi phạm trong nhật ký MongoDB, nhưng cho phép hoàn thành thao tác chèn hoặc cập nhật. Ví dụ:
db.createCollection("students", { validator: {$jsonSchema: { bsonType: "object", required: [ "name", "gpa" ], properties: { name: { bsonType: "string", description: "must be a string and is required" }, gpa: { bsonType: [ "double" ], minimum: 0, description: "must be a double and is required" } } }, validationAction: “warn” })Nếu chúng tôi cố gắng chèn một tài liệu như thế này:
db.students.insert( { name: "Amanda", status: "Updated" } );Gpa bị thiếu bất kể thực tế là nó là trường bắt buộc trong thiết kế giản đồ, nhưng vì hành động xác thực đã được đặt thành cảnh báo, tài liệu sẽ được lưu và thông báo lỗi sẽ được ghi lại trong nhật ký MongoDB.



