Tự động chuyển đổi dự phòng cho MySQL Replication đã là chủ đề tranh luận trong nhiều năm.
Đó là điều tốt hay điều xấu?
Đối với những người có bộ nhớ lâu trong thế giới MySQL, họ có thể nhớ sự cố GitHub bị ngừng hoạt động vào năm 2012 mà nguyên nhân chủ yếu là do phần mềm đưa ra các quyết định sai lầm.
GitHub sau đó đã chuyển sang một tổ hợp của MySQL Replication, Corosync, Pacemaker và Percona Replication Manager. PRM quyết định thực hiện chuyển đổi dự phòng sau khi kiểm tra tình trạng không thành công trên bản chính, điều này đã bị quá tải trong quá trình di chuyển giản đồ. Một trang cái mới đã được chọn, nhưng nó hoạt động kém vì bộ đệm lạnh. Lưu lượng truy vấn cao từ trang web bận rộn khiến nhịp tim của PRM không hoạt động trở lại trên thiết bị chính và PRM sau đó kích hoạt chuyển đổi dự phòng khác sang thiết bị chính ban đầu. Và các vấn đề vẫn tiếp tục, như được tóm tắt bên dưới.
 Nguồn:Henrik Ingo &Massimo Brignoli’s tại Percona Live 2013
Nguồn:Henrik Ingo &Massimo Brignoli’s tại Percona Live 2013 Tua đi vài năm và GitHub đã trở lại với một khuôn khổ khá phức tạp để quản lý MySQL Replication và chuyển đổi dự phòng tự động! Như Shlomi Noach đã nói:
“Để đạt được hiệu quả đó, chúng tôi sử dụng chuyển đổi dự phòng chính tự động. Thời gian một con người đánh thức và sửa chữa một tổng thể bị lỗi nằm ngoài dự đoán của chúng tôi về khả năng sẵn có và việc vận hành một chuyển đổi dự phòng như vậy đôi khi không phải là chuyện nhỏ. Chúng tôi hy vọng các lỗi chính sẽ được tự động phát hiện và khôi phục trong vòng 30 giây hoặc ít hơn và chúng tôi hy vọng việc chuyển đổi dự phòng sẽ dẫn đến việc mất ít nhất các máy chủ khả dụng. ”
Hầu hết các công ty không phải là GitHub, nhưng người ta có thể tranh luận rằng không có công ty nào thích sự cố ngừng hoạt động. Việc ngừng hoạt động có thể làm gián đoạn bất kỳ hoạt động kinh doanh nào và chúng cũng gây tốn kém tiền bạc. Tôi đoán rằng hầu hết các công ty ngoài kia có thể ước họ có một số loại chuyển đổi dự phòng tự động và lý do không thực hiện nó có lẽ là sự phức tạp của các giải pháp hiện có, thiếu năng lực trong việc triển khai các giải pháp đó hoặc thiếu tin tưởng vào phần mềm để thực hiện một quyết định quan trọng như vậy.
Hiện có một số giải pháp chuyển đổi dự phòng tự động, bao gồm (và không giới hạn) MHA, MMM, MRM, mysqlfailover, Orchestrator và ClusterControl. Một số trong số họ đã có mặt trên thị trường trong một số năm, những người khác gần đây hơn. Đó là một dấu hiệu tốt, nhiều giải pháp có nghĩa là thị trường ở đó và mọi người đang cố gắng giải quyết vấn đề.
Khi chúng tôi thiết kế chuyển đổi dự phòng tự động trong ClusterControl, chúng tôi đã sử dụng một số nguyên tắc hướng dẫn:
-
Đảm bảo rằng chủ thực sự đã chết trước khi bạn chuyển đổi dự phòng
Trong trường hợp phân vùng mạng, nơi phần mềm chuyển đổi dự phòng mất liên lạc với phần mềm, nó sẽ không nhìn thấy nó. Nhưng cái chính có thể đang hoạt động tốt và có thể được nhìn thấy bởi phần còn lại của cấu trúc liên kết sao chép.
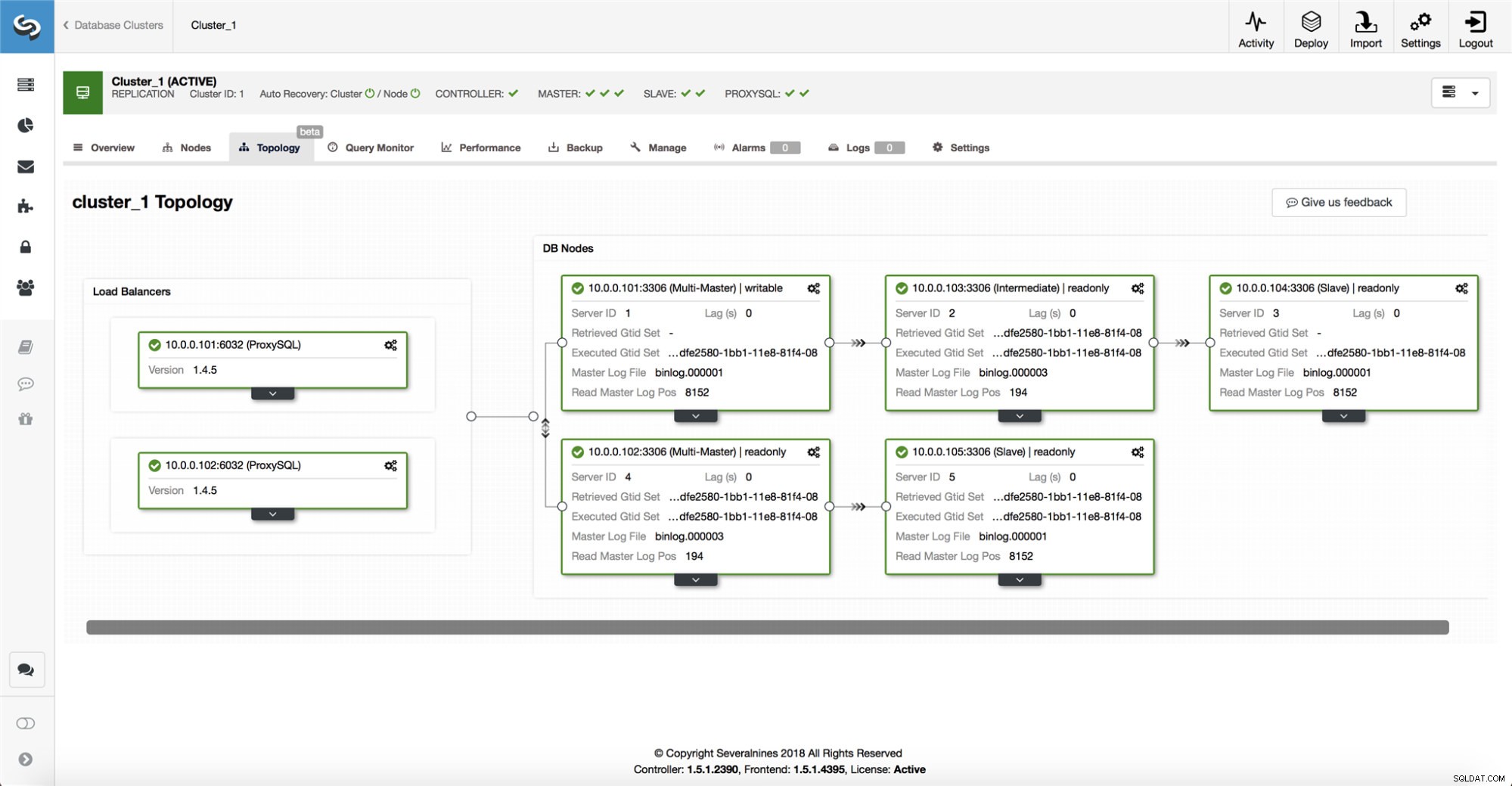
ClusterControl thu thập thông tin từ tất cả các nút cơ sở dữ liệu cũng như bất kỳ proxy cơ sở dữ liệu / bộ cân bằng tải nào được sử dụng, sau đó xây dựng một biểu diễn của cấu trúc liên kết. Nó sẽ không cố gắng chuyển đổi dự phòng nếu các nô lệ có thể nhìn thấy cái chính, cũng như nếu ClusterControl không chắc chắn 100% về trạng thái của cái chính.
ClusterControl cũng giúp bạn dễ dàng hình dung cấu trúc liên kết của thiết lập cũng như trạng thái của các nút khác nhau (đây là cách hiểu của ClusterControl về trạng thái của hệ thống, dựa trên thông tin mà nó thu thập được).
-
Chỉ chuyển đổi dự phòng một lần
Phần lớn đã được viết về vỗ. Nó có thể rất lộn xộn nếu công cụ khả dụng quyết định thực hiện nhiều chuyển đổi dự phòng. Đó là một tình huống nguy hiểm. Mỗi chủ nhân được bầu chọn, dù ngắn ngủi khoảng thời gian mà nó giữ vai trò chủ nhân, có thể có các bộ thay đổi của riêng họ mà không bao giờ được sao chép lại cho bất kỳ máy chủ nào. Vì vậy, bạn có thể dẫn đến sự mâu thuẫn giữa tất cả các trang cái được bầu chọn.
-
Không chuyển đổi dự phòng sang nô lệ không nhất quán
Khi chọn một nô lệ để thăng cấp làm chủ, chúng tôi đảm bảo nô lệ không có mâu thuẫn, ví dụ:các giao dịch sai lầm, vì điều này rất có thể phá vỡ việc sao chép.
-
Chỉ viết thư cho chính chủ
Sao chép đi từ chủ đến (các) nô lệ. Viết trực tiếp cho một nô lệ sẽ tạo ra một tập dữ liệu phân kỳ và đó có thể là một nguồn tiềm ẩn của vấn đề. Chúng tôi đặt nô lệ thành read_only và super_read_only trong các phiên bản MySQL hoặc MariaDB mới hơn. Chúng tôi cũng khuyên bạn nên sử dụng bộ cân bằng tải, ví dụ:ProxySQL hoặc MaxScale, để bảo vệ lớp ứng dụng khỏi cấu trúc liên kết cơ sở dữ liệu bên dưới và bất kỳ thay đổi nào đối với nó. Bộ cân bằng tải cũng thực thi ghi trên trang cái hiện tại.
-
Không tự động khôi phục trang cái bị lỗi
Nếu cái chính bị lỗi và một cái mới đã được chọn, ClusterControl sẽ không cố gắng khôi phục cái bị lỗi. Tại sao? Máy chủ đó có thể có dữ liệu chưa được sao chép và quản trị viên sẽ cần thực hiện một số điều tra về lỗi. Được rồi, bạn vẫn có thể định cấu hình ClusterControl để xóa sạch dữ liệu trên cái chính bị lỗi và để nó tham gia làm nô lệ cho cái chính mới - nếu bạn đồng ý với việc mất một số dữ liệu. Nhưng theo mặc định, ClusterControl sẽ để chế độ chính bị lỗi, cho đến khi ai đó xem xét nó và quyết định đưa nó vào cấu trúc liên kết.
Vì vậy, bạn có nên tự động chuyển đổi dự phòng? Nó phụ thuộc vào cách bạn đã cấu hình sao chép. Các thiết lập sao chép vòng tròn với nhiều bản gốc có thể ghi hoặc các cấu trúc liên kết phức tạp có lẽ không phải là ứng cử viên tốt cho chuyển đổi dự phòng tự động. Chúng tôi sẽ tuân theo các nguyên tắc trên khi thiết kế một giải pháp nhân rộng.
Trên PostgreSQL
Khi nói đến sao chép luồng PostgreSQL, ClusterControl sử dụng các nguyên tắc tương tự để tự động chuyển đổi dự phòng. Đối với PostgreSQL, ClusterControl hỗ trợ cả mô hình sao chép không đồng bộ và đồng bộ giữa chủ và nô lệ. Trong cả hai trường hợp và trong trường hợp không thành công, nô lệ có dữ liệu cập nhật nhất được bầu làm chủ mới. Bản gốc không thành công không được tự động khôi phục / sửa để tham gia lại thiết lập bản sao.
Có một số biện pháp bảo vệ được thực hiện để đảm bảo rằng bản chính bị lỗi vẫn hoạt động và không hoạt động, ví dụ:nó bị xóa khỏi bộ cân bằng tải trong proxy và nó bị giết nếu ví dụ:người dùng sẽ khởi động lại nó theo cách thủ công. Ở đó khó khăn hơn một chút để phát hiện sự phân chia mạng giữa ClusterControl và master, vì các nô lệ không cung cấp bất kỳ thông tin nào về trạng thái của master mà chúng đang sao chép từ đó. Vì vậy, một proxy phía trước thiết lập cơ sở dữ liệu rất quan trọng vì nó có thể cung cấp một đường dẫn khác đến trang chủ.
Trên MongoDB
Sao chép MongoDB trong một bản sao thông qua oplog rất giống với sao chép binlog, vậy tại sao MongoDB lại tự động khôi phục một bản chính bị lỗi? Vấn đề vẫn còn đó và MongoDB giải quyết vấn đề đó bằng cách khôi phục bất kỳ thay đổi nào không được sao chép cho nô lệ tại thời điểm không thành công. Dữ liệu đó bị xóa và được đặt trong thư mục "khôi phục", do đó, quản trị viên có thể khôi phục dữ liệu đó hay không.
Để tìm hiểu thêm, hãy xem ClusterControl; và đừng ngại bình luận hoặc đặt câu hỏi bên dưới.



