JOIN là một trong những tính năng khác biệt chính giữa cơ sở dữ liệu SQL và NoSQL. Trong cơ sở dữ liệu SQL, chúng ta có thể thực hiện phép tham gia giữa hai bảng trong cùng một cơ sở dữ liệu hoặc khác nhau. Tuy nhiên, đây không phải là trường hợp của MongoDB vì nó cho phép thực hiện phép JOIN giữa hai tập hợp trong cùng một cơ sở dữ liệu.
Cách dữ liệu được trình bày trong MongoDB khiến nó gần như không thể liên kết nó từ tập hợp này sang tập hợp khác ngoại trừ khi sử dụng các hàm truy vấn tập lệnh cơ bản. MongoDB hoặc hủy chuẩn hóa dữ liệu bằng cách lưu trữ các mục liên quan trong một tài liệu riêng biệt hoặc nó liên kết dữ liệu trong một số tài liệu riêng biệt khác.
Người ta có thể liên hệ dữ liệu này bằng cách sử dụng các tham chiếu thủ công như trường _id của một tài liệu được lưu trong một tài liệu khác dưới dạng tham chiếu. Tuy nhiên, một người cần thực hiện nhiều truy vấn để tìm nạp một số dữ liệu bắt buộc, khiến quá trình này hơi tẻ nhạt.
Do đó, chúng tôi quyết định sử dụng khái niệm JOIN để tạo điều kiện cho mối quan hệ của dữ liệu. Hoạt động JOIN trong MongoDB đạt được thông qua việc sử dụng toán tử $ lookup, được giới thiệu trong phiên bản 3.2.
$ lookup operator
Ý tưởng chính đằng sau khái niệm JOIN là để có được mối tương quan giữa dữ liệu trong bộ sưu tập này với bộ sưu tập khác. Cú pháp cơ bản của toán tử $ lookup là:
{
$lookup:
{
from: <collection to join>,
localField: <field from the input documents>,
foreignField: <field from the documents of the "from" collection>,
as: <output array field>
}
}Về kiến thức SQL, chúng ta luôn biết rằng kết quả của một phép toán JOIN là một hàng riêng biệt liên kết tất cả các trường từ bảng cục bộ và bảng ngoại. Đối với MongoDB, đây là một trường hợp khác trong đó các tài liệu kết quả được thêm vào dưới dạng một mảng tài liệu thu thập cục bộ. Ví dụ:hãy có hai bộ sưu tập; 'Sinh viên' và 'đơn vị'
sinh viên
{"_id" : 1,"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5}
{"_id" : 3,"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5}Đơn vị
{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}
{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}
{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}Chúng tôi có thể truy xuất các đơn vị sinh viên với các điểm tương ứng bằng cách sử dụng toán tử $ lookup với phương pháp JOIN .i.e
db.getCollection('students').aggregate([{
$lookup:
{
from: "units",
localField: "_id",
foreignField : "_id",
as: "studentUnits"
}
}])Điều này sẽ cho chúng ta kết quả bên dưới:
{"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5,
"studentUnits" : [{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}]}
{"_id" : 2,"name" : "Clinton Ariango","age" : 14,"grade" : "B","score" : 7.5,
"studentUnits" : [{"_id" : 2,"Maths" : "B","English" : "B","Science" : "A","History" : "B"}]}
{"_id" : 3,"name" : "Mary Muthoni","age" : 16,"grade" : "A","score" : 11.5,
"studentUnits" : [{"_id" : 3,"Maths" : "A","English" : "A","Science" : "A","History" : "A"}]}Giống như đã đề cập trước đây, nếu chúng ta thực hiện JOIN bằng cách sử dụng khái niệm SQL, chúng ta sẽ được trả về với các tài liệu riêng biệt trong nền tảng Studio3T .i.e
SELECT *
FROM students
INNER JOIN units
ON students._id = units._idTương đương với
db.getCollection("students").aggregate(
[
{
"$project" : {
"_id" : NumberInt(0),
"students" : "$$ROOT"
}
},
{
"$lookup" : {
"localField" : "students._id",
"from" : "units",
"foreignField" : "_id",
"as" : "units"
}
},
{
"$unwind" : {
"path" : "$units",
"preserveNullAndEmptyArrays" : false
}
}
]
);Truy vấn SQL ở trên sẽ trả về kết quả bên dưới:
{ "students" : {"_id" : NumberInt(1),"name" : "James Washington","age" : 15.0,"grade" : "A","score" : 10.5},
"units" : {"_id" : NumberInt(1),"Maths" : "A","English" : "A","Science" : "A","History" : "B"}}
{ "students" : {"_id" : NumberInt(2), "name" : "Clinton Ariango","age" : 14.0,"grade" : "B","score" : 7.5 },
"units" : {"_id" : NumberInt(2),"Maths" : "B","English" : "B","Science" : "A","History" : "B"}}
{ "students" : {"_id" : NumberInt(3),"name" : "Mary Muthoni","age" : 16.0,"grade" : "A","score" : 11.5},
"units" : {"_id" : NumberInt(3),"Maths" : "A","English" : "A","Science" : "A","History" : "A"}}Thời lượng hiệu suất rõ ràng sẽ phụ thuộc vào cấu trúc truy vấn của bạn. Ví dụ:nếu bạn có nhiều tài liệu trong bộ sưu tập này với bộ sưu tập khác, bạn nên tổng hợp từ bộ sưu tập với các tài liệu ít hơn và sau đó tra cứu trong bộ sưu tập có nhiều tài liệu hơn. Bằng cách này, việc tra cứu trường đã chọn từ bộ sưu tập ít tài liệu hơn là khá tối ưu và tốn ít thời gian hơn so với việc tra cứu nhiều trường cho một trường đã chọn trong bộ sưu tập có nhiều tài liệu hơn. Do đó, bạn nên đặt bộ sưu tập nhỏ hơn trước.
Đối với cơ sở dữ liệu quan hệ, thứ tự của cơ sở dữ liệu không quan trọng vì hầu hết các trình thông dịch SQL đều có trình tối ưu hóa, có quyền truy cập vào thông tin bổ sung để quyết định cái nào nên có trước.
Trong trường hợp MongoDB, chúng ta sẽ cần sử dụng một chỉ mục để hỗ trợ hoạt động JOIN. Tất cả chúng ta đều biết rằng tất cả các tài liệu MongoDB đều có khóa _id mà đối với DBM quan hệ có thể được coi là khóa chính. Chỉ mục cung cấp cơ hội tốt hơn để giảm lượng dữ liệu cần được truy cập bên cạnh việc hỗ trợ hoạt động khi được sử dụng trong khóa ngoại $ lookup.
Trong quy trình tổng hợp, để sử dụng một chỉ mục, chúng ta phải đảm bảo thực hiện khớp $ ở giai đoạn đầu tiên để lọc ra các tài liệu không phù hợp với tiêu chí. Ví dụ:nếu chúng ta muốn truy xuất kết quả cho sinh viên với giá trị trường _id bằng 1:
select *
from students
INNER JOIN units
ON students._id = units._id
WHERE students._id = 1;Mã MongoDB tương đương mà bạn sẽ nhận được trong trường hợp này là:
db.getCollection("students").aggregate(
[{"$project" : { "_id" : NumberInt(0), "students" : "$$ROOT" }},
{ "$lookup" : {"localField" : "students._id", "from" : "units", "foreignField" : "_id", "as" : "units"} },
{ "$unwind" : { "path" : "$units","preserveNullAndEmptyArrays" : false } },
{ "$match" : {"students._id" : NumberLong(1) }}
]);Kết quả trả về cho truy vấn trên sẽ là:
{"_id" : 1,"name" : "James Washington","age" : 15,"grade" : "A","score" : 10.5,
"studentUnits" : [{"_id" : 1,"Maths" : "A","English" : "A","Science" : "A","History" : "B"}]}Khi chúng tôi không sử dụng giai đoạn $ so khớp hoặc đúng hơn là không ở giai đoạn đầu tiên, nếu chúng tôi kiểm tra với chức năng giải thích, chúng tôi sẽ nhận được giai đoạn COLLSCAN cũng được bao gồm. Thực hiện COLLSCAN cho một bộ tài liệu lớn nói chung sẽ mất rất nhiều thời gian. Do đó, chúng tôi quyết định sử dụng trường chỉ mục mà trong hàm giải thích chỉ liên quan đến giai đoạn IXSCAN. Cái thứ hai có một lợi thế vì chúng tôi đang kiểm tra một chỉ mục trong các tài liệu và không phải quét qua tất cả các tài liệu; sẽ không mất nhiều thời gian để trả lại kết quả. Bạn có thể có một cấu trúc dữ liệu khác như:
{ "_id" : NumberInt(1),
"grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"
}
}Chúng tôi có thể muốn trả về điểm dưới dạng các thực thể khác nhau trong một mảng thay vì toàn bộ trường điểm được nhúng.
Sau khi viết truy vấn SQL ở trên, chúng ta cần sửa đổi mã MongoDB kết quả. Để làm như vậy, hãy nhấp vào biểu tượng sao chép ở bên phải như bên dưới để sao chép mã tổng hợp:
Tiếp theo, chuyển đến tab tổng hợp và trên ngăn được trình bày, có biểu tượng dán, hãy nhấp vào biểu tượng đó để dán mã.
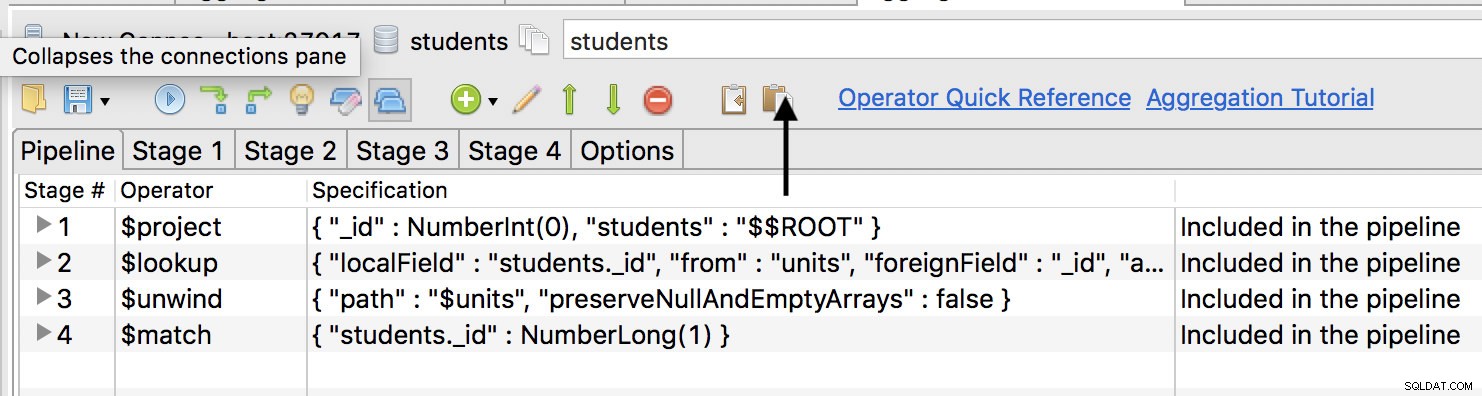
Nhấp vào hàng $ match, sau đó nhấp vào mũi tên lên màu xanh lục để chuyển vùng hiển thị lên trên cùng như màn hình đầu tiên. Tuy nhiên, trước tiên bạn cần tạo một chỉ mục trong bộ sưu tập của mình như:
db.students.createIndex(
{ _id: 1 },
{ name: studentId }
)Bạn sẽ nhận được mẫu mã bên dưới:
db.getCollection("students").aggregate(
[{ "$match" : {"_id" : 1.0}},
{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id","as" : "units"}},
{ "$unwind" : {"path" : "$units", "preserveNullAndEmptyArrays" : false}}
]Với đoạn mã này, chúng ta sẽ nhận được kết quả bên dưới:
{ "students" : {"_id" : NumberInt(1), "name" : "James Washington","age" : 15.0,"grade" : "A", "score" : 10.5},
"units" : {"_id" : NumberInt(1), "grades" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"}}}Nhưng tất cả những gì chúng ta cần là có các điểm như một thực thể tài liệu riêng biệt trong tài liệu trả về chứ không phải như ví dụ trên. Do đó, chúng tôi sẽ thêm giai đoạn $ addfields, do đó có mã như bên dưới.
db.getCollection("students").aggregate(
[{ "$match" : {"_id" : 1.0}},
{ "$project" : {"_id" : NumberInt(0),"students" : "$$ROOT"}},
{ "$lookup" : {"localField" : "students._id","from" : "units","foreignField" : "_id","as" : "units"}},
{ "$unwind" : {"path" : "$units", "preserveNullAndEmptyArrays" : false}},
{ "$addFields" : {"units" : "$units.grades"} }]Các tài liệu kết quả sau đó sẽ là:
{
"students" : {"_id" : NumberInt(1), "name" : "James Washington", "grade" : "A","score" : 10.5},
"units" : {"Maths" : "A", "English" : "A", "Science" : "A", "History" : "B"}
}Dữ liệu trả về khá gọn gàng, vì chúng tôi đã loại bỏ các tài liệu nhúng khỏi bộ sưu tập của đơn vị dưới dạng một trường riêng biệt.
Trong hướng dẫn tiếp theo của chúng tôi, chúng tôi sẽ xem xét các truy vấn với một số phép nối.



